
В 2015 году парсинг означал либо уговаривать разработчика написать Python-скрипт, либо тратить выходные на изучение XPath. В 2026 году вы пишете: «собери все названия и цены товаров», и остальное делает ИИ.
Это изменение произошло очень быстро. Сейчас на веб-скрейпинг полагаются . Объем рынка превысил и, по прогнозам, к 2030 году удвоится.
Главный драйвер? AI web crawler. Они адаптируются к изменениям в макете страниц. Они понимают содержимое страницы, а не только HTML-теги. И они работают для людей, которые ни разу не написали ни строчки кода.
Я провел месяцы, тестируя 15 таких инструментов. Вот что я выяснил — включая то, почему Thunderbit (да, компания, которую я соосновал) занял первое место.
Почему ИИ меняет парсинг веб-страниц: новая эра инструментов web scraper
Давайте честно: классический веб-скрейпинг никогда не был создан для обычного бизнес-пользователя. Все сводилось к коду, селекторам и надежде, что скрипт не сломается при следующем изменении дизайна сайта. Но ИИ и LLM полностью перевернули эту логику.
Вот как это работает:
- Инструкции на естественном языке: Вместо возни с кодом вы просто говорите ИИ, что вам нужно. Инструменты вроде понимают ваши обычные английские инструкции и настраивают извлечение данных за вас ().
- Адаптивное обучение: AI scraper умеют на сайтах, снижая головную боль с поддержкой.
- Работа с динамическим контентом: Современные сайты любят JavaScript и бесконечную прокрутку. Инструменты на базе ИИ взаимодействуют с этими элементами и забирают данные, которые старые скрейперы пропустили бы.
- Структурированный вывод с AI parsing: Скрейперы на базе LLM действительно и выводят чистые, структурированные данные.
- Автоматическое обходное прохождение антибот-защиты: AI scraper могут и использовать прокси/headless-браузеры, чтобы избежать блокировки IP.
- Интегрированные рабочие процессы с данными: Лучшие инструменты не просто собирают данные — они доставляют их туда, где они нужны, с экспортом в один клик в Google Sheets, Airtable, Notion и другие сервисы ().
Итог? Веб-скрейпинг теперь ощущается как работа по принципу «нажал и получил» — а местами даже как чат. Это открывает доступ к веб-данным не только разработчикам, но и командам продаж, маркетинга и операционных подразделений.
15 AI web crawler, на которые стоит обратить внимание в 2026 году
Разберем 15 лучших AI web crawler, начиная с Thunderbit. Я расскажу о ключевых возможностях каждого инструмента, целевой аудитории, ценах и о том, чем он выделяется. И да — честно отмечу, где каждый особенно хорош, а где может не подойти.
1. Thunderbit: AI Web Scraper для всех
Здесь я, очевидно, немного предвзят, но Thunderbit — это AI web scraper, который мне хотелось бы иметь много лет назад. Вот почему он №1 в этом списке:
- Извлечение на естественном языке: Вы как будто «общаетесь» с Thunderbit. Просто опишите, какие данные нужны — например: «собери со страницы все названия и цены товаров» — и ИИ сделает остальное (). Никакого кода, никаких селекторов, никакой головной боли.
- Краулинг подстраниц и многоуровневый краулинг: Thunderbit может . Например, можно собрать список товаров, а затем перейти в карточку каждого товара за деталями — и все это за один проход.
- Мгновенный структурированный результат: ИИ , предлагает релевантные поля, приводит форматы к единому виду и даже суммирует или классифицирует текст.
- Широкая поддержка источников: Thunderbit работает не только с HTML — он может извлекать данные из PDF и изображений с помощью встроенных OCR и vision AI ().
- Бизнес-интеграции: Экспорт в один клик в Google Sheets, Airtable, Notion или Excel (). Настраивайте расписание скрейпов и отправляйте данные прямо в рабочий процесс команды.
- Готовые шаблоны: Для таких сайтов, как Amazon, LinkedIn, Zillow и других, Thunderbit предлагает для извлечения данных в один клик.
- Удобство и доступность: Интерфейс работает по принципу point-and-click и включает интуитивного помощника. Пользователи пишут, что запускаются за считанные минуты.

Thunderbit доверяют , включая команды Accenture, Grammarly и Puma. Команды продаж используют его, чтобы , риелторы агрегируют объявления о недвижимости, а маркетологи отслеживают конкурентов — и все это без единой строчки кода.
Цена: Есть (до 100 шагов скрейпа в месяц), а платные планы начинаются от $14,99 в месяц. Даже профессиональные тарифы доступны для частных пользователей и небольших команд.
Thunderbit — это самое близкое к «превратить веб в базу данных», что я видел, и он создан для всех, а не только для инженеров.
2. Crawl4AI
Для кого: Разработчики и технические команды, строящие кастомные пайплайны.
Crawl4AI — это open-source фреймворк на Python, оптимизированный для скорости и крупномасштабного краулинга, с . Он очень быстрый, поддерживает headless-браузеры для динамического контента и умеет структурировать собранные данные, чтобы их было удобно передавать в AI workflows.
- Лучше всего подходит для: Разработчиков, которым нужен мощный и настраиваемый краулинг-движок.
- Цена: Бесплатно (лицензия MIT). Хостинг и запуск — на вашей стороне.
3. ScrapeGraphAI
Для кого: Разработчики и аналитики, создающие AI-агентов или сложные data pipeline.
ScrapeGraphAI — это основанная на запросах open-source Python-библиотека, которая превращает сайты в структурированные data graph с помощью LLM. Можно писать запросы вроде «извлеки все названия товаров, цены и рейтинги с первых 5 страниц», и она построит для вас workflow скрейпинга ().
- Лучше всего подходит для: Технически подкованных пользователей, которым нужен гибкий скрейпинг на основе prompts.
- Цена: Библиотека open-source — бесплатно; cloud API начинается от $20 в месяц.
4. Firecrawl
Для кого: Разработчики, строящие AI-агентов или крупные data pipeline.
Firecrawl — это AI-ориентированная краулинг-платформа и API, которая превращает целые сайты в данные, готовые для LLM (). Она выводит Markdown или JSON, умеет работать с динамическим контентом и интегрируется с такими фреймворками, как LangChain и LlamaIndex.
- Лучше всего подходит для: Разработчиков, которым нужно подавать живые веб-данные в AI-модели.
- Цена: Open-source-ядро бесплатно; cloud-планы начинаются от $19 в месяц.
5. Browse AI
Для кого: Бизнес-пользователи, growth hackers и аналитики.
Browse AI — это no-code платформа с . Вы «обучаете» робота, нажимая на нужные данные, а ИИ потом обобщает шаблон для будущих скрейпов. Он работает с логинами, бесконечной прокруткой и может отслеживать изменения на сайтах.
- Лучше всего подходит для: Пользователей без технического бэкграунда, которым нужно автоматизировать сбор и мониторинг данных.
- Цена: Бесплатный план (50 кредитов в месяц); платные планы начинаются от $19 в месяц.
6. LLM Scraper
Для кого: Разработчики, которые хотят поручить парсинг ИИ.
LLM Scraper — это open-source библиотека на JavaScript/TypeScript, которая позволяет , а затем поручить LLM извлечь эти данные с любой веб-страницы. Она построена на Playwright, поддерживает нескольких провайдеров LLM и даже может генерировать переиспользуемый код.
- Лучше всего подходит для: Разработчиков, которые хотят превращать любую веб-страницу в структурированные данные с помощью LLM.
- Цена: Бесплатно (лицензия MIT).
7. Reader (Jina Reader)
Для кого: Разработчики, создающие LLM-приложения, чат-ботов или summarizer.
Jina Reader — это API, которое извлекает , возвращая Markdown или JSON, готовые для LLM. Оно работает на кастомной AI-модели и даже умеет описывать изображения.
- Лучше всего подходит для: Получения чистого, удобочитаемого контента для LLM или систем вопросов и ответов.
- Цена: Бесплатный API (для базового использования ключ не нужен).
8. Bright Data
Для кого: Крупные компании и профессиональные пользователи, которым нужны масштаб, compliance и надежность.
Bright Data — один из тяжеловесов индустрии веб-данных, с огромной proxy-сетью и . Он предлагает готовые скрейперы, универсальный Web Scraper API и потоки данных, готовые для LLM.
- Лучше всего подходит для: Организаций, которым нужны надежные веб-данные в большом объеме.
- Цена: По использованию, премиум-сегмент. Есть пробные версии.
9. Octoparse
Для кого: Пользователи без технической подготовки и с минимальной технической подготовкой.
Octoparse — давно известный no-code инструмент с и автоматическим определением на базе ИИ. Он работает с логинами, бесконечной прокруткой и умеет экспортировать данные в разные форматы.
- Лучше всего подходит для: Аналитиков, владельцев малого бизнеса и исследователей.
- Цена: Есть бесплатный тариф; платные планы начинаются от $119 в месяц.
10. Apify
Для кого: Разработчики и техкоманды, которым нужен кастомный скрейпинг/автоматизация.
Apify — это cloud-платформа для запуска скрейпинг-скриптов («actors») и магазин с . Она масштабируется, интегрируется с ИИ и поддерживает управление прокси.
- Лучше всего подходит для: Разработчиков, которые хотят запускать собственные скрипты в облаке.
- Цена: Есть бесплатный тариф; платные планы по модели pay-as-you-go начинаются от $49 в месяц.
11. Zyte (Scrapy Cloud)
Для кого: Разработчики и компании, которым нужен enterprise-level скрейпинг.
Zyte — компания, стоящая за Scrapy, которая предлагает cloud-платформу и . Она умеет управлять расписанием, прокси и крупными проектами.
- Лучше всего подходит для: Dev-команд, ведущих долгосрочные скрейпинг-проекты.
- Цена: От пробных версий до кастомных enterprise-планов.
12. Webscraper.io
Для кого: Новички, журналисты и исследователи.
— это для извлечения данных в формате point-and-click. Оно простое, бесплатно для локального использования и предлагает cloud-сервис для более крупных задач.
- Лучше всего подходит для: Быстрых разовых задач по скрейпингу.
- Цена: Бесплатное расширение; cloud-планы начинаются примерно от $50 в месяц.
13. ParseHub
Для кого: Пользователи без технической подготовки, которым нужно больше возможностей, чем у базовых инструментов.
ParseHub — это desktop-приложение с визуальным workflow для скрейпинга динамического контента, включая карты и формы. Оно может запускать проекты в облаке и предлагает API.
- Лучше всего подходит для: Digital-маркетологов, аналитиков и журналистов.
- Цена: Есть бесплатный тариф (200 страниц за запуск); платные планы начинаются от $189 в месяц.
14. Diffbot
Для кого: Крупные компании и AI-компании, которым нужны большие объемы структурированных веб-данных.
Diffbot использует компьютерное зрение и NLP, чтобы с любой веб-страницы, предлагая API для статей, товаров и огромного knowledge graph.
- Лучше всего подходит для: Market intelligence, финансов и обучающих данных для ИИ.
- Цена: Премиум, от примерно $299 в месяц.
15. DataMiner
Для кого: Пользователи без технической подготовки, особенно в продажах, маркетинге и журналистике.
DataMiner — это для быстрого извлечения веб-данных по принципу point-and-click. У него есть библиотека готовых «рецептов», и он может экспортировать данные прямо в Google Sheets.
- Лучше всего подходит для: Быстрых задач, например экспорта таблиц или списков в электронные таблицы.
- Цена: Есть бесплатный тариф (500 страниц в день); Pro начинается примерно от $19 в месяц.
Сравнение лучших AI web scraper: какой подойдет именно вам?
Вот краткое сравнение, которое поможет сориентироваться:
| Инструмент | Использование ИИ/LLM | Простота использования | Вывод/интеграции | Кому подходит | Цена |
|---|---|---|---|---|---|
| Thunderbit | Интерфейс на естественном языке; ИИ предлагает поля | Самый простой (чат без кода) | Экспорт в Sheets, Airtable, Notion | Команды без техподготовки | Бесплатный тариф; Pro ~ $30/мес |
| Crawl4AI | Краулинг, готовый для ИИ; интеграция с LLM | Сложно (код на Python) | Библиотека/CLI; интеграция через код | Разработчики, которым нужны быстрые AI data pipeline | Бесплатно |
| ScrapeGraphAI | Prompt-пайплайны LLM для скрейпинга | Средне (некоторый код или API) | API/SDK; вывод JSON | Разработчики/аналитики, создающие AI-агентов | Бесплатный OSS; API от $20/мес |
| Firecrawl | Краулинг в Markdown/JSON, готовые для LLM | Средне (использование API/SDK) | SDK (Py, Node и т. д.); интеграция с LangChain | Разработчики, подключающие живые веб-данные к ИИ | Бесплатно + платное облако |
| Browse AI | AI-поддержка point & click | Легко (no-code) | Более 7000 интеграций приложений (Zapier) | Пользователи без техподготовки для мониторинга сайтов | Бесплатно 50 запусков; платно от $19/мес |
| LLM Scraper | Использует LLM для парсинга страницы по схеме | Сложно (код TS/JS) | Библиотека кода; вывод JSON | Разработчики, которым нужен парсинг через ИИ | Бесплатно (с собственным LLM API) |
| Reader (Jina) | AI-модель извлекает текст/JSON | Легко (простой API-вызов) | REST API возвращает Markdown/JSON | Разработчики, добавляющие веб-поиск/контент в LLM | Бесплатный API |
| Bright Data | AI-enhanced scraping API; большая proxy-сеть | Сложно (API, технически) | API/SDK; потоки данных или датасеты | Enterprise-масштаб | По использованию |
| Octoparse | AI auto-detect списков | Средне (no-code приложение) | CSV/Excel, API для результатов | Пользователи с минимальной технической подготовкой | Бесплатно с ограничениями; $59–$166/мес |
| Apify | Некоторые AI-функции (Actors, AI tutorials) | Сложно (код скриптов) | Полный API; интеграция с LangChain | Разработчики, которым нужен кастомный cloud-скрейпинг | Бесплатный тариф; pay-as-you-go |
| Zyte (Scrapy) | ML-автоматическое извлечение; фреймворк Scrapy | Сложно (код на Python) | API, интерфейс Scrapy Cloud; JSON/CSV | Dev-команды, долгосрочные проекты | Индивидуальная цена |
| Webscraper.io | Без ИИ (ручные шаблоны) | Легко (расширение браузера) | CSV-загрузка, Cloud API | Новички, быстрые разовые скрейпы | Бесплатное расширение; Cloud ~ $50/мес |
| ParseHub | Без явного LLM; визуальный конструктор | Средне (no-code приложение) | JSON/CSV; API для cloud-запусков | Неразработчики, скрейпинг сложных сайтов | Бесплатно 200 страниц; платно от $189/мес |
| Diffbot | AI vision/NLP для любой страницы; knowledge graph | Легко (достаточно API-вызовов) | API (Article/Prod/...) + запросы к Knowledge Graph | Enterprise, структурированные веб-данные | От ~$299/мес |
| DataMiner | Без LLM; community recipes | Самый простой (интерфейс браузера) | Экспорт в Excel/CSV; Google Sheets | Пользователи без техподготовки для выгрузки в таблицы | Бесплатно с ограничениями; Pro ~ $19/мес |
Категории инструментов: от мощных решений для разработчиков до удобных для бизнеса web scraper
Чтобы было проще разобраться в этом списке, разделим инструменты на несколько категорий:
1. Мощные решения для разработчиков и open-source
- Примеры: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Сильные стороны: Высокая гибкость, масштабируемость и возможность глубокой настройки. Отлично подходят для построения кастомных пайплайнов или интеграции с AI-моделями.
- Компромиссы: Требуют навыков программирования и большей настройки.
- Сценарии использования: Создание кастомного data pipeline, скрейпинг сложных сайтов или интеграция с внутренними системами.
2. AI-интегрированные scraping agents
- Примеры: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Сильные стороны: Сокращают разрыв между сбором данных и их пониманием. Интерфейсы на естественном языке делают их доступными.
- Компромиссы: Некоторые все еще развиваются; может не хватать тонкого контроля.
- Сценарии использования: Быстрые ответы или наборы данных, создание автономных агентов или подача живых данных в LLM.
3. No-code/low-code инструменты для бизнеса
- Примеры: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Сильные стороны: Удобны, почти не требуют кода, хорошо подходят для регулярных бизнес-задач.
- Компромиссы: Могут испытывать трудности на очень сложных сайтах или при огромных объемах.
- Сценарии использования: Генерация лидов, мониторинг конкурентов, исследовательские проекты и разовые выгрузки данных.
4. Корпоративные data platforms и сервисы
- Примеры: Bright Data, Diffbot, Zyte
- Сильные стороны: Полнофункциональные решения, управляемые сервисы, compliance и надежность на масштабе.
- Компромиссы: Более высокая стоимость, более сложное внедрение.
- Сценарии использования: Крупномасштабные, постоянно работающие data pipeline, market intelligence и обучающие данные для ИИ.
Как выбрать подходящий AI web crawler для задач парсинга веб-страниц
Выбрать подходящий инструмент бывает непросто, поэтому вот мой пошаговый совет:
- Четко определите цели и требования к данным: Какие сайты и какие данные вам нужны? Как часто? В каком объеме? Что вы будете с ними делать?
- Оцените свою техническую подготовку: Не пишете код? Попробуйте Thunderbit, Browse AI или Octoparse. Есть немного скриптинга? LLM Scraper или DataMiner. Сильные навыки разработки? Crawl4AI, Apify или Zyte.
- Учитывайте частоту и масштаб: Разовая задача? Используйте бесплатные инструменты. Регулярная? Ищите функции планирования. Крупный масштаб? Корпоративные инструменты или open-source на масштабе.
- Бюджет и модель оплаты: Бесплатные планы отлично подходят для тестирования. Подписка или оплата по использованию — зависит от ваших задач.
- Тестирование и proof of concept: Проверьте несколько инструментов на реальных данных. У большинства есть бесплатные тарифы.
- Поддержка и сопровождение: Кто будет исправлять проблемы, если сайт изменится? No-code-инструменты с ИИ могут автоматически исправлять небольшие изменения; open-source — это уже ваша задача или сообщество.
- Привяжите инструменты к сценариям: Команда продаж собирает лиды? Thunderbit или Browse AI. Исследователь собирает твиты? DataMiner или . AI-модели нужны новостные статьи? Jina Reader или Zyte. Строите сайт-сравнение? Apify или Zyte.
- Подготовьте запасной вариант: Иногда один инструмент не сработает на конкретном сайте. Нужен fallback.
«Правильный» инструмент — это тот, который дает нужные данные с минимальным сопротивлением и укладывается в бюджет. Иногда это даже комбинация нескольких решений.
Thunderbit против традиционных web scraper: в чем его преимущество?
Теперь подробнее о том, чем Thunderbit отличается:
- Интерфейс на естественном языке: Никакого кода и никакой акробатики point-and-click. Просто опишите, что вам нужно ().
- Нулевая настройка и предложения шаблонов: Thunderbit автоматически определяет пагинацию, подстраницы и даже предлагает шаблоны для популярных сайтов ().
- Очистка и обогащение данных на базе ИИ: Суммируйте, классифицируйте, переводите и обогащайте данные прямо во время скрейпа ().
- Меньше проблем с поддержкой: ИИ Thunderbit устойчив к небольшим изменениям сайта, поэтому ломается реже.
- Интеграция с бизнес-инструментами: Прямой экспорт в Google Sheets, Airtable, Notion — больше не нужно возиться с CSV ().
- Быстрый путь к результату: От идеи до данных — за минуты, а не дни.
- Порог входа: Если вы умеете пользоваться вебом и можете описать, что вам нужно, вы справитесь с Thunderbit.
- Гибкость: Скрейпинг сайтов, PDF, изображений и многого другого — все одним и тем же инструментом.
Thunderbit — это не просто скрейпер. Это data assistant, который встраивается в ваш workflow, будь то продажи, маркетинг, ecommerce или недвижимость.
Лучшие практики парсинга веб-страниц с AI web scraper tools
Чтобы выжать максимум из AI web scraper, вот мои главные советы:
- Четко определите, какие данные вам нужны: Знайте, какие поля нужны, сколько страниц нужно обработать и в каком формате вы хотите результат.
- Используйте предложения ИИ: Применяйте функции определения полей и подсказки ИИ, чтобы не пропустить важные данные ().
- Начинайте с малого и проверяйте: Протестируйте на небольшом примере, проверьте результат и при необходимости скорректируйте.
- Учитывайте динамический контент: Убедитесь, что ваш инструмент поддерживает динамический контент и взаимодействия (пагинацию, бесконечную прокрутку и т. д.).
- Соблюдайте правила сайта: Проверяйте robots.txt, не скрейпьте чувствительные данные и соблюдайте rate limits.
- Интегрируйте для автоматизации: Используйте экспорт и webhooks, чтобы встраивать собранные данные прямо в ваш workflow.
- Следите за качеством данных: Проводите sanity check, используйте post-processing и отслеживайте ошибки.
- Формулируйте prompts кратко: При работе с ИИ-инструментами четкие и конкретные инструкции дают лучший результат.
- Учитесь у сообщества: Присоединяйтесь к форумам и сообществам за советами и помощью в troubleshooting.
- Следите за обновлениями: AI-инструменты быстро развиваются — держите руку на пульсе новых функций и улучшений.
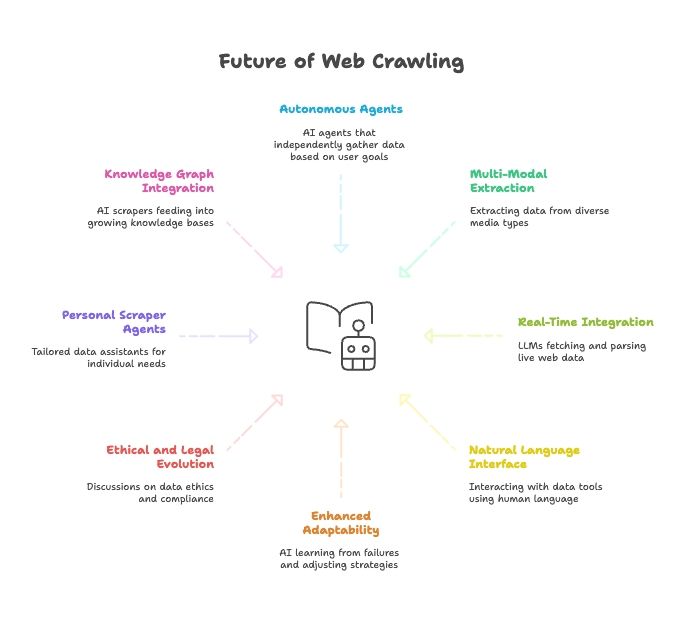
Будущее веб-скрейпинга: ИИ, LLM и рост natural language web scraper agents
Если смотреть вперед, слияние ИИ и веб-скрейпинга только ускоряется:
- Полностью автономные scraper agents: Скоро вы будете просто говорить AI-агенту конечную цель, а он сам разберется, как получить данные.
- Мультимодальное извлечение данных: Скрейперы будут вытаскивать данные из текста, изображений, PDF и даже видео.
- Интеграция в реальном времени с AI-моделями: У LLM появятся встроенные модули для получения и парсинга живых веб-данных.
- Всё на естественном языке: Мы будем разговаривать с инструментами для данных так же, как с людьми, и это сделает сбор и преобразование данных доступным всем.
- Повышенная адаптивность: AI scraper будут учиться на неудачах и автоматически подстраивать стратегии.
- Этическая и правовая эволюция: Будет все больше обсуждений вокруг этики данных, compliance и fair use.
- Персональные scraper agents: Представьте себе персонального data assistant, который собирает новости, вакансии и многое другое под ваши задачи.
- Интеграция с knowledge graph: AI scraper будут непрерывно пополнять все более крупные базы знаний, усиливая более умный ИИ.
Вывод? Будущее веб-скрейпинга неотделимо от будущего ИИ. Инструменты становятся умнее, автономнее и доступнее с каждым днем.
Заключение: как раскрыть бизнес-ценность с помощью правильного AI web crawler
Веб-скрейпинг из узкоспециализированного технического навыка превратился в базовую бизнес-возможность — благодаря ИИ. 15 инструментов, которые я рассмотрел здесь, показывают лучшее из того, что возможно в 2026 году: от мощных решений для разработчиков до удобных бизнес-помощников.
Главный секрет? Правильный выбор инструмента может резко увеличить ценность, которую вы получаете из веб-данных. Для нетехнических команд Thunderbit — самый простой способ превратить веб в структурированную базу данных, готовую к анализу: без кода, без лишней возни, только результат.
Так что, собираете ли вы лиды, отслеживаете конкурентов или подаете данные в свою AI-модель следующего поколения, уделите время оценке своих задач, попробуйте несколько инструментов и посмотрите, что подойдет вам лучше всего. А если хотите уже сегодня увидеть будущее веб-скрейпинга, . Нужные инсайты — всего в одном prompt.
Хотите узнать больше? Загляните в за подробными разборками, руководствами и свежими новостями об извлечении данных с помощью ИИ.
Дополнительное чтение:
Часто задаваемые вопросы
1. Что такое AI web crawler и чем он отличается от традиционных web scraper?
AI web crawler использует обработку естественного языка и машинное обучение, чтобы понимать, извлекать и структурировать веб-данные. В отличие от традиционных скрейперов, которым нужен ручной код и XPath-селекторы, AI-инструменты умеют работать с динамическим контентом, адаптироваться к изменениям макета и понимать инструкции пользователя на обычном английском языке.
2. Кому стоит использовать AI web scraping tools вроде Thunderbit?
Thunderbit создан как для нетехнических, так и для технических пользователей. Он идеально подходит для специалистов по продажам, маркетингу, операциям, исследованиям и ecommerce, которым нужно извлекать структурированные данные с сайтов, из PDF или изображений — без написания кода.
3. Какие функции выделяют Thunderbit среди других AI web crawler?
Thunderbit предлагает интерфейс на естественном языке, многоуровневый краулинг, автоматическое структурирование данных, поддержку OCR и бесшовный экспорт в такие платформы, как Google Sheets и Airtable. Кроме того, он включает AI-подсказки полей и готовые шаблоны для популярных сайтов.
4. Есть ли бесплатные варианты AI web scraping в 2026 году?
Да. Многие инструменты, такие как Thunderbit, Browse AI и DataMiner, предлагают бесплатные тарифы с ограниченным использованием. Для разработчиков open-source варианты вроде Crawl4AI и ScrapeGraphAI дают полный функционал бесплатно, хотя и требуют технической настройки.
5. Как выбрать подходящий AI web crawler под мои задачи?
Начните с определения целей по данным, технической подготовки, бюджета и требований к масштабу. Если вам нужно no-code и простое в использовании решение, отличным выбором будут Thunderbit или Browse AI. Для крупных или кастомных задач лучше подойдут инструменты вроде Apify или Bright Data.