

Давайте будем честны: Amazon — это по сути и торговый центр, и супермаркет, и магазин электроники для всего интернета. Если вы работаете в продажах, e-commerce или операциях, вы и так знаете: всё, что происходит на Amazon, не остаётся только на Amazon — это влияет на ваши цены, запасы и даже на следующий крупный запуск продукта. Но есть одна проблема: все эти вкусные данные о товарах, ценах, рейтингах и отзывах спрятаны за веб-интерфейсом, который сделан для покупателей, а не для команд, которым нужны данные. Так как же получить доступ к этим данным, не проводя выходные за копированием и вставкой, будто на дворе 1999 год?
Именно здесь на помощь приходит web scraping. В этом руководстве я покажу два способа извлечь данные о товарах Amazon: классический подход «засучить рукава и написать код на Python» и современный путь «пусть AI сделает тяжёлую работу» с no-code web scraper вроде Thunderbit. Я разберу реальный Python-код (со всеми подводными камнями и обходными путями), а затем покажу, как Thunderbit может получить для вас те же данные всего за пару кликов — без программирования. Неважно, разработчик вы, бизнес-аналитик или просто человек, которому надоела ручная работа с данными, — здесь вы найдёте нужный вариант.
Зачем извлекать данные о товарах Amazon? (amazon scraper python, web scraping with python)
Amazon — это не просто крупнейший онлайн-ритейлер в мире. Это ещё и крупнейшая в мире открытая площадка для конкурентной разведки. При более чем 600 миллионах товаров и почти 2 миллионах активных продавцов Amazon — настоящая золотая жила для всех, кто хочет:

- Отслеживать цены и корректировать свои в реальном времени
- Анализировать конкурентов и следить за их новыми запусками, рейтингами и отзывами
- Генерировать лиды — находить продавцов, поставщиков или даже потенциальных партнёров
- Прогнозировать спрос — следить за уровнем запасов и рейтингами продаж
- Замечать рыночные тренды — анализируя отзывы и результаты поиска
И это не просто теория: реальные компании получают реальную отдачу. Например, один продавец электроники использовал данные о ценах Amazon, собранные с сайта, чтобы увеличить маржу прибыли на 15%, а другой бренд получил рост продаж на 4% и сокращение времени аналитиков на 30% после автоматизации отслеживания цен конкурентов.
Вот краткая таблица сценариев использования и того, какого ROI вы можете ожидать:
| Сценарий | Кто использует | Типичный ROI / эффект |
|---|---|---|
| Мониторинг цен | E-commerce, операции | Рост маржи прибыли на 15%+, увеличение продаж на 4%, на 30% меньше времени аналитика |
| Анализ конкурентов | Продажи, продукт, операции | Более быстрая корректировка цен, повышение конкурентоспособности |
| Исследование рынка (отзывы) | Продукт, маркетинг | Быстрее итерации продукта, более сильные рекламные тексты, SEO-инсайты |
| Генерация лидов | Продажи | 3000+ лидов в месяц, экономия более 8 часов на каждого менеджера в неделю |
| Прогноз запасов и спроса | Операции, цепочка поставок | Снижение избыточных запасов на 20%, меньше дефицита товара |
| Поиск трендов | Маркетинг, руководители | Раннее обнаружение популярных товаров и категорий |
И вот ещё важный момент: более 90% организаций уже сообщают о измеримой пользе от аналитики данных. Если вы не извлекаете данные с Amazon, вы оставляете инсайты и деньги на столе.
Обзор: Amazon Scraper Python vs. No Code Web Scraper Tools
Есть два основных способа вытащить данные с Amazon из браузера и перенести их в таблицы или дашборды:
-
Amazon Scraper Python (web scraping with python):
Пишите собственный скрипт на Python с библиотеками вроде Requests и BeautifulSoup. Это даёт полный контроль, но вам нужно уметь программировать, обходить антибот-защиту и поддерживать скрипт, когда Amazon меняет сайт.
-
No Code Web Scraper Tools (например, Thunderbit):
Используйте инструмент, где можно указывать, кликать и извлекать данные — без программирования. Современные решения вроде Thunderbit даже используют AI, чтобы определить, какие данные нужно собрать, обрабатывать подстраницы и пагинацию, а затем экспортировать всё прямо в Excel или Google Sheets.
Вот как они выглядят в сравнении:
| Критерий | Python Scraper | No Code (Thunderbit) |
|---|---|---|
| Время настройки | Высокое (установка, код, отладка) | Низкое (установка расширения) |
| Необходимые навыки | Нужен кодинг | Не нужны (point & click) |
| Гибкость | Без ограничений | Высокая для типовых задач |
| Поддержка | Код исправляете вы | Инструмент обновляется сам |
| Работа с антиботом | Прокси и заголовки на вашей стороне | Встроено, всё делает за вас |
| Масштабируемость | Вручную (потоки, прокси) | Cloud scraping, параллельная обработка |
| Экспорт данных | Настраиваемый (CSV, Excel, БД) | В Excel и Sheets в один клик |
| Стоимость | Бесплатно (ваше время + прокси) | Freemium, оплата за масштаб |
| Лучше всего для | Разработчиков, кастомных задач | Бизнес-пользователей, быстрых результатов |
В следующих разделах я проведу вас по обоим подходам — сначала покажу, как собрать Amazon scraper на Python (с реальным кодом), а затем — как сделать то же самое с помощью AI web scraper от Thunderbit.
Начинаем с Amazon Scraper Python: требования и настройка
Прежде чем переходить к коду, давайте подготовим окружение.
Вам понадобятся:
- Python 3.x (скачайте с python.org)
- Редактор кода (я люблю VS Code, но подойдёт любой)
- Следующие библиотеки:
requests(для HTTP-запросов)beautifulsoup4(для разбора HTML)lxml(быстрый HTML-парсер)pandas(для таблиц и экспорта данных)re(регулярные выражения, встроенный модуль)
Установите библиотеки:
pip install requests beautifulsoup4 lxml pandas
Настройка проекта:
- Создайте новую папку для проекта.
- Откройте редактор, создайте новый Python-файл, например
amazon_scraper.py. - Можно начинать!
Пошагово: web scraping с Python для данных о товарах Amazon
Давайте разберём, как собрать данные с одной страницы товара Amazon. (Не переживайте, к парсингу нескольких товаров и страниц мы ещё перейдём.)
1. Отправка запроса и получение HTML
Сначала получим HTML страницы товара. (Замените URL на любой товар Amazon.)
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
Внимание: такой простой запрос Amazon, скорее всего, заблокирует. Вместо страницы товара вы можете увидеть ошибку 503 или CAPTCHA. Почему? Потому что Amazon понимает, что вы не настоящий браузер.
Как обходить антибот-защиту Amazon
Amazon не любит ботов. Чтобы не получить блокировку, вам нужно:
- Задать заголовок User-Agent — притвориться Chrome или Firefox
- Ротация User-Agent — не использовать один и тот же каждый раз
- Ограничивать частоту запросов — добавлять случайные задержки
- Использовать прокси — если нужно собирать данные в большом масштабе
Вот как задать заголовки:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
Хотите сделать всё чуть более продвинуто? Используйте список User-Agent и меняйте их для каждого запроса. Для крупных задач вам пригодится прокси-сервис (их сейчас много), но для небольших объёмов обычно достаточно заголовков и пауз.
Извлечение ключевых полей товара
Когда HTML получен, пора разобрать его с помощью BeautifulSoup.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
Теперь достанем главное:
Название товара
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
Цена
Цена на Amazon может быть в нескольких местах. Попробуйте так:
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
Рейтинг и количество отзывов
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # например, "1,554 ratings"
URL главного изображения
Иногда Amazon прячет изображения высокого разрешения в JSON внутри HTML. Вот быстрый вариант через регулярное выражение:
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
Или можно взять основной тег изображения:
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
Данные о товаре
Характеристики вроде бренда, веса и размеров обычно находятся в таблице:
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
Или, если Amazon использует формат “detailBullets”:
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
Выведите результаты:
print("Title:", product_title)
print("Price:", price)
print("Rating:", rating, "based on", reviews_count, "reviews")
print("Main image URL:", main_image_url)
print("Details:", details)
Парсинг нескольких товаров и обработка пагинации
Один товар — это хорошо, но вам, скорее всего, нужен целый список. Вот как парсить результаты поиска и несколько страниц.
Получаем ссылки на товары со страницы поиска
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
Обработка пагинации
В поисковых URL Amazon используется &page=2, &page=3 и так далее.
for page in range(1, 6): # собираем первые 5 страниц
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... извлекаем ссылки на товары, как выше ...
Проходим по страницам товаров и экспортируем в CSV
Соберите данные о товарах в список словарей, затем используйте pandas:
import pandas as pd
df = pd.DataFrame(product_data_list) # список словарей
# сохраняем в CSV
df.to_csv("amazon_products.csv", index=False)
Или в Excel:
df.to_excel("amazon_products.xlsx", index=False)
Лучшие практики для проектов на Amazon Scraper Python
Если честно, Amazon постоянно меняет сайт и борется со скрейперами. Вот как сохранить проект рабочим:
- Меняйте заголовки и User-Agent — используйте, например,
fake-useragent - Используйте прокси для больших объёмов
- Ограничивайте частоту запросов — случайные
time.sleep()между запросами - Обрабатывайте ошибки корректно — повторяйте запросы при 503, делайте паузу, если получили блокировку
- Пишите гибкую логику парсинга — проверяйте несколько селекторов для каждого поля
- Следите за изменениями HTML — если скрипт вдруг начинает возвращать
Noneдля всего, проверьте страницу - Соблюдайте robots.txt — Amazon запрещает скрейпинг многих разделов, действуйте ответственно
- Очищайте данные по ходу — убирайте символы валюты, запятые и пробелы
- Оставайтесь на связи с сообществом — форумы, Stack Overflow, Reddit r/webscraping
Чек-лист для поддержки скрейпера:
- Менять User-Agent и заголовки
- Использовать прокси при сборе в масштабе
- Добавлять случайные задержки
- Структурировать код, чтобы было проще обновлять
- Следить за банами и CAPTCHA
- Регулярно экспортировать данные
- Документировать селекторы и логику
Для более глубокого разбора загляните в мой гайд по web scraping с Python.
No Code-альтернатива: scraping Amazon с Thunderbit AI Web Scraper
Собирайте данные о товарах Amazon с помощью AI Get Started Free
Итак, вы увидели путь через Python. Но что, если вы не хотите программировать — или просто хотите получить данные за два клика и заняться своими делами? Тут и приходит на помощь Thunderbit.
Thunderbit — это AI web scraper в виде расширения Chrome, который позволяет извлекать данные о товарах Amazon (и почти с любого другого сайта) вообще без кода. Вот почему мне он нравится:
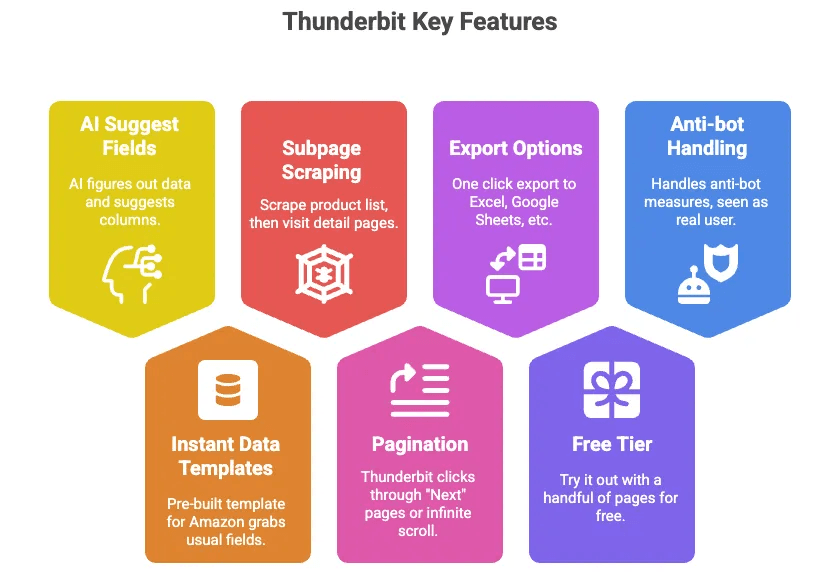
- AI Suggest Fields: просто нажимаете кнопку, и AI Thunderbit сам понимает, какие данные есть на странице, предлагая колонки, например Title, Price, Rating и т. д.
- Готовые шаблоны данных: для Amazon есть заранее настроенный шаблон, который собирает все обычные поля без настройки.
- Scraping подстраниц: соберите список товаров, а затем Thunderbit автоматически откроет страницу каждого товара и извлечёт больше информации.
- Пагинация: Thunderbit может переходить по страницам “Next” или прокручивать бесконечную ленту вместо вас.
- Экспорт в Excel, Google Sheets, Airtable, Notion: один клик — и данные готовы к работе.
- Бесплатный тариф: можно попробовать на нескольких страницах бесплатно.
- Антибот-защита частично берётся на себя: так как инструмент работает в браузере или в облаке, Amazon видит в нём обычного пользователя.
Пошагово: как использовать Thunderbit для сбора данных о товарах Amazon
Вот насколько это просто:
-
Установите Thunderbit:
Скачайте расширение Thunderbit для Chrome и войдите в аккаунт.
-
Откройте Amazon:
Перейдите на страницу Amazon, которую хотите собрать: результаты поиска, карточку товара — что угодно.
-
Нажмите “AI Suggest Fields” или используйте шаблон:
Thunderbit предложит колонки для извлечения данных, либо вы можете выбрать шаблон Amazon Product.
-
Проверьте колонки:
При необходимости настройте их: добавьте или удалите поля, переименуйте и т. д.
-
Нажмите “Scrape”:
Thunderbit соберёт данные со страницы и покажет их в таблице.
-
Обработайте подстраницы и пагинацию:
Если вы собрали список, нажмите “Scrape Subpages”, чтобы Thunderbit посетил страницу каждого товара и извлёк дополнительную информацию. Он также может автоматически переходить по страницам “Next”.
-
Экспортируйте данные:
Нажмите “Export to Excel” или “Export to Google Sheets”. Готово.
-
(Опционально) Настройте расписание:
Нужны эти данные каждый день? Используйте планировщик Thunderbit, чтобы автоматизировать процесс.
Вот и всё. Без кода, без отладки, без прокси, без головной боли. Для наглядного обзора посмотрите YouTube-канал Thunderbit или страницу шаблона Amazon Product Scraper.
Попробовать шаблон Amazon Product Scraper
Amazon Scraper Python vs. No Code Web Scraper: сравнение бок о бок
Сведём всё вместе:
| Критерий | Python Scraper | Thunderbit (No Code) |
|---|---|---|
| Время настройки | Высокое (установка, код, отладка) | Низкое (установка расширения) |
| Необходимые навыки | Нужен кодинг | Не нужны (point & click) |
| Гибкость | Без ограничений | Высокая для типовых задач |
| Поддержка | Код исправляете вы | Инструмент обновляется сам |
| Работа с антиботом | Прокси и заголовки на вашей стороне | Встроено, всё делает за вас |
| Масштабируемость | Вручную (потоки, прокси) | Cloud scraping, параллельная обработка |
| Экспорт данных | Настраиваемый (CSV, Excel, БД) | В Excel и Sheets в один клик |
| Стоимость | Бесплатно (ваше время + прокси) | Freemium, оплата за масштаб |
| Лучше всего для | Разработчиков, кастомных задач | Бизнес-пользователей, быстрых результатов |
Если вы разработчик, который любит копаться в деталях и ему нужен суперкастомный инструмент, Python — ваш союзник. Если вам важны скорость, простота и ноль кода, лучше выбрать Thunderbit.
Когда выбирать Python, no-code или AI web scraper для данных Amazon
Выбирайте Python, если:
- Вам нужна собственная логика или вы хотите встроить scraping в backend-системы
- Вы собираете данные в очень большом масштабе (десятки тысяч товаров)
- Вы хотите понять, как устроен scraping изнутри
Выбирайте Thunderbit (no-code, AI web scraper), если:
- Вам нужны данные быстро и без программирования
- Вы бизнес-пользователь, аналитик или маркетолог
- Вы хотите дать команде возможность получать данные самостоятельно
- Вы хотите избежать возни с прокси, антиботом и поддержкой
Используйте оба варианта, если:
- Вы хотите быстро сделать прототип в Thunderbit, а затем собрать кастомное Python-решение для продакшена
- Вы хотите использовать Thunderbit для сбора данных, а Python — для их очистки и анализа
Для большинства бизнес-пользователей Thunderbit закроет 90% потребностей в сборе данных с Amazon в разы быстрее. Для оставшихся 10% — сверхкастомных, крупномасштабных или глубоко интегрированных задач — Python по-прежнему остаётся королём.
Заключение и ключевые выводы
Как собирать данные о товарах и отзывах Amazon в 2025 году с помощью AI Get Started Free
Сбор данных о товарах Amazon — это суперсила для любой команды продаж, e-commerce или операций. Отслеживаете ли вы цены, анализируете конкурентов или просто хотите избавить команду от бесконечного копипаста — решение есть.
- Сбор на Python даёт полный контроль, но требует времени на обучение и постоянного обслуживания.
- No-code web scraper вроде Thunderbit делает извлечение данных с Amazon доступным каждому — без кода, без головной боли, просто результат.
- Лучший подход? Используйте инструмент, который соответствует вашим навыкам, срокам и бизнес-целям.
Если вам интересно, попробуйте Thunderbit — старт бесплатный, и вы удивитесь, как быстро можно получить нужные данные. А если вы разработчик, не бойтесь сочетать подходы: иногда самый быстрый путь к готовому решению — поручить AI скучную часть работы.
Получить расширение Thunderbit для Chrome
FAQ
1. Зачем бизнесу извлекать данные о товарах Amazon?
Сбор данных с Amazon позволяет компаниям отслеживать цены, анализировать конкурентов, собирать отзывы для исследования продукта, прогнозировать спрос и генерировать лиды. При более чем 600 миллионах товаров и почти 2 миллионах продавцов Amazon — богатый источник конкурентной разведки.
2. В чём основные различия между Python и no-code-инструментами вроде Thunderbit для сбора данных с Amazon?
Python-скрейперы дают максимальную гибкость, но требуют навыков кодирования, времени на настройку и постоянной поддержки. Thunderbit, no-code AI web scraper, позволяет мгновенно извлекать данные Amazon через расширение Chrome — без кода, со встроенной защитой от ботов и возможностью экспорта в Excel или Sheets.
3. Законно ли собирать данные с Amazon?
Условия использования Amazon обычно запрещают scraping, и компания активно применяет антибот-механизмы. Однако многие компании всё равно собирают публично доступные данные, действуя ответственно — например, соблюдая лимиты запросов и избегая чрезмерной нагрузки.
4. Какие данные можно извлечь с Amazon с помощью web scraping-инструментов?
Обычно это названия товаров, цены, рейтинги, количество отзывов, изображения, характеристики, наличие товара и даже информация о продавце. Thunderbit также поддерживает scraping подстраниц и пагинацию, чтобы собирать данные по нескольким карточкам и страницам.
5. Когда лучше выбрать Python scraping вместо инструмента вроде Thunderbit и наоборот?
Используйте Python, если вам нужен полный контроль, собственная логика или интеграция в backend-системы. Используйте Thunderbit, если вам нужен быстрый результат без кода, простое масштабирование или low-maintenance-решение для бизнеса.
Хотите углубиться? Вот несколько ресурсов:
- Блог Thunderbit
- Что такое data scraping и как делать это в 2025 году
- Как собирать данные о товарах и отзывах Amazon в 2025 году с помощью AI
- Руководство по web scraping с Python
Удачного scraping — и пусть ваши таблицы всегда будут актуальными.
Попробовать AI Web Scraper Thunderbit для Amazon Get Started Free




