Краткое резюме
Мы собрали файл robots.txt для каждого домена из списка Tranco top 10,000 самых посещаемых сайтов мира. Затем мы разобрали каждый файл парсером, совместимым с RFC 9309, классифицировали его по тому, какую политику в отношении AI-ботов сайт принял (если принял), и посчитали, сколько из самых посещаемых сайтов мира действительно пытаются блокировать ChatGPT, Claude, Perplexity, Gemini, Common Crawl, Bytespider, Apple Intelligence и другие краулеры, которые в 2026 году обучают и обслуживают большие языковые модели.
Главные цифры по выборке из 7 248 сайтов, чей robots.txt удалось корректно прочитать:
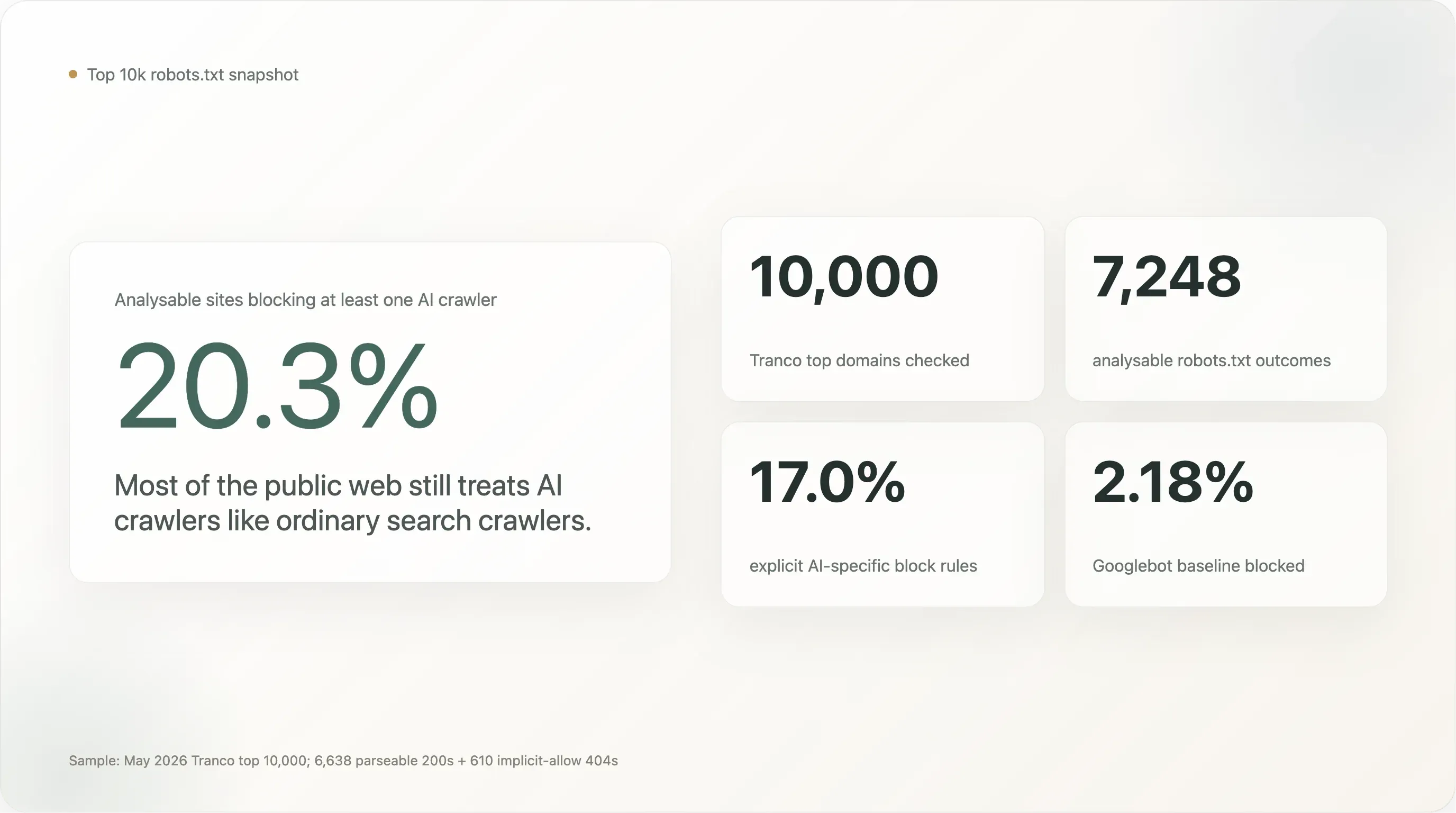
20,3% сайтов из мирового топ-10 000 блокируют как минимум одного AI-краулера. 17,0% сознательно прописали явное правило именно для AI. Остальные 80% встречают AI-краулеры так же гостеприимно, как Googlebot.
Шесть выводов, которые меняют картину:
- Новости блокируют в 47% случаев — это самый высокий показатель среди всех отраслей. В Германии — 88%, во Франции — 80%, в России — 0%. Главный драйвер — не технология и не экономика отрасли, а правовой режим.
CCBot(Common Crawl) — самый часто блокируемый бот: 16,3% — впередиGPTBot(15,8%) иBytespider(14,9%). Издатели нацеливаются на корпус обучения, а не на бренд модели. Самое популярное селективное правило — «блокироватьCCBot, разрешитьGooglebot» (14,1% сайтов).- Франция лидирует среди всех стран: 50,6% AI-блокировки на сайтах в зоне
.fr; кластер ЕС на 16 пунктов выше глобальной базы. В 275 файлахrobots.txtпрямо упоминается Директива ЕС 2019/790. Статья 4 — единственный правовой режим, который заметно сдвигает цифры. - 17,8% написали собственные AI-правила; 4,5% используют шаблон Cloudflare; 75,7% вообще ничего не говорят. Крупные сайты пишут правила сами; длинный хвост пользуется переключателем. The Atlantic и сам
cloudflare.comвходят в список Cloudflare Managed. - 108 сайтов явно разрешают
GPTBot— WordPress.org, Kaspersky, Norton, Avast, Sophos, The Verge, The Atlantic, NBA.com, The Sun, Branch.io. Сектор security и dev tooling представлен непропорционально сильно. - AI-политика не становится агрессивнее на верхушке рейтинга. Топ-100, 101–1000, 1001–5000 и 5001–10000 находятся в диапазоне 19–23%. Главная цифра — свойство публичного веба 2026 года, а не показатель размера отдельного сайта.
История уже не о том, «сопротивляется ли веб». Она о том, какие отрасли, страны, правовые режимы и AI-вендоры становятся целью активной политики — и какие нет.
I. Контекст: как robots.txt стал артефактом AI-политики
С тех пор как OpenAI выпустила GPTBot в августе 2023 года, три силы изменили смысл robots.txt.
AI-вендоров стало больше. За ним последовали Google-Extended от Google, ClaudeBot от Anthropic, Bytespider от ByteDance, Applebot-Extended от Apple, Amazonbot от Amazon, Meta-ExternalAgent от Meta. Существующий CCBot от Common Crawl стал самым сильным по влиянию объектом блокировки, потому что его архив питает большинство open-weight моделей. Появились и не вендорские боты: AI2Bot, cohere-ai, PerplexityBot, YouBot, DuckAssistBot, Diffbot, Omgili. Полный список блокировок в 2026 году насчитывает около 25 имен.
Статья 4 Директивы ЕС об авторском праве 2019/790 ввела исключение для text and data mining, которое не применяется, если правообладатель «явно зарезервировал» свои права в машиночитаемой форме. В 2024–2025 годах издатели ЕС и их юристы сошлись на robots.txt как на каноническом способе выражать такой отказ. В нашей выборке 275 сайтов явно ссылаются на Директиву 2019/790, а 87 упоминают «TDM» — в основном на европейских новостных сайтах, где это выглядит как правовая преамбула на 4–8 строк.
Cloudflare превратил переключатель в продукт. В 2024–2025 годах Cloudflare выпустил дашборд «AI Audit», переключатель «Block AI Bots» и шаблон Managed robots.txt с лексикой Content-Signal: search=yes,ai-train=no и стандартной оговоркой про EU 2019/790. К маю 2026 года этот шаблон используется на 4,5% разбираемых сайтов из топ-10k. В открытой дорожной карте Cloudflare обсуждается включение переключателя по умолчанию для новых аккаунтов — это подняло бы глобальный уровень блокировки на 5–8 пунктов без какого-либо решения со стороны отдельного издателя.
В 2026 году robots.txt — уже не скучный конфигурационный файл, каким он был в 2022-м. Это механизм закрепления прав в авторском праве с опорой на договор в ЕС, артефакт политики, сформированный вендором, в длинном хвосте и линия фронта медленных переговоров между владельцами сайтов и теми, кто обучает модели.
II. Методология
Мы постарались сделать исследование максимально скучным и воспроизводимым. Полный пайплайн (Python-скрипты, обработанные CSV, архив сырых robots.txt, графики) опубликован вместе с этим отчетом.
Выборка
Мы начали со списка Tranco на май 2026 года, скачанного как top-1m.csv.zip, и взяли первые 10 000 строк. Tranco агрегирует четыре исходных рейтинга (Cisco Umbrella, Majestic, Farsight и Cloudflare Radar), фильтрует их по стабильности за 30-дневное окно и убирает очевидный шум от краулеров и CDN. Получившийся список — самое близкое к каноническому «топ-10k глобального веб-трафика», что есть в открытом доступе, и стандартная выборка для академических веб-исследований (используется в 600+ рецензируемых работах с момента запуска проекта KU Leuven в 2018 году).
В списке есть смесь: (a) основных сайтов, куда заходят люди, (b) инфраструктурных / API / DNS / CDN-доменов, у которых нет содержимого на /, и (c) доменов, которые большие платформы используют внутри своих систем (например, gvt1.com, apple-dns.net, googleusercontent.com). Мы не отфильтровывали их заранее, а оставили все и пометили как категорию infrastructure на уровне анализа. Они естественным образом выпадают, когда мы ограничиваемся «сайтами, которые вернули разбираемый robots.txt».
Получение данных
Для каждого из 10 000 доменов мы делали асинхронный GET /robots.txt по HTTPS с fallback на HTTP, редиректами до четырех переходов, общим таймаутом 12 секунд, лимитом тела 500 КБ и User-Agent, похожим на браузер, с Accept-Language: en-US. Параллелизм был ограничен 80 запросами одновременно. Задача выполнялась с одного residential IP в Сан-Франциско.
Результат получения:
| Статус | Количество | Интерпретация |
|---|---|---|
200 OK | 6 638 | Тело robots.txt получено и можно разобрать. |
404 Not Found | 610 | robots.txt отсутствует. RFC 9309 трактует это как неявное «разрешить всё». |
403 Forbidden | 563 | Источник активно отклоняет запросы к robots.txt. Исключено из анализа. |
429 Too Many Requests | 7 | Почти нет CDN-ограничений на этом уровне рейтинга. |
fetch_failed (ошибка TLS / DNS / TCP) | 2 065 | В основном apex-домены CDN (akamai.net, cloudfront.net, fastly.net, gtld-servers.net, apple-dns.net), которые не обслуживают веб-сервер на /. Это не «блокировка» — у них просто нет robots.txt. |
| Прочие 4xx/5xx | 117 | Смешанный набор — ошибки сервера, геофенсинг, некорректные ответы. |
Итого 7 248 сайтов в анализируемой выборке (6 638 200 + 610 404). 2 065 fetch_failed — реальные домены, но это apex-точки CDN/DNS, а не сайты, куда заходят люди, и считать их имеющими «AI-политику» бессмысленно. В датасете они остаются как отдельная статистика доступности.
Парсинг
Каждое тело со статусом 200 мы разбирали с помощью protego, Python-реализации RFC 9309, используемой в продакшене Scrapy. Для каждой пары (сайт, бот) мы вычисляли три вещи:
can_fetch_root— разрешено ли боту обращаться к/, с учетом семантики групп записей стандарта, приоритета самого длинного совпадения и правила, по которомуUser-agent: *отступает перед более конкретной блокировкой бота, если обе существуют.has_specific_rule— содержит ли файл строкуUser-agent:, в которой указан именно этот бот (без учета регистра).disallow_count— сколько директивDisallow:находится в совпавшем блоке; это помогает отличать полный запрет на весь сайт от ограничений на уровне отдельных путей.
Комбинация этих метрик важна, потому что верхнеуровневая «доля блокировок» скрывает два совершенно разных явления: бренды, которые осознанно написали User-agent: GPTBot \n Disallow: /, потому что решили сопротивляться, и бренды, у которых старое общее правило User-agent: * \n Disallow: / (когда-то сделанное для staging или maintenance) случайно запрещает и всем AI-ботам, которых тогда еще не существовало. В этом отчете число «любой AI-блокировки» включает оба случая; число «явной AI-блокировки» — только сознательно написанную подвыборку.
Боты в зоне охвата
Мы отслеживали 25 ботов, разделенных на три категории:
- AI-краулеры для обучения (16):
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Meta-ExternalAgent,Bytespider,Applebot-Extended,Diffbot,Amazonbot,ImagesiftBot,FacebookBot,cohere-ai,AI2Bot,Omgili,Omgilibot. - Боты для AI-инференса / live retrieval (7):
PerplexityBot,Perplexity-User,ChatGPT-User,OAI-SearchBot,ClaudeBot(используется и для обучения, и для инференса),YouBot,DuckAssistBot. - Базовые поисковые боты (6):
Googlebot,Bingbot,DuckDuckBot,Slurp(Yahoo),Baiduspider,YandexBot.
Некоторые боты находятся на границе между обучением и инференсом. Самый заметный — ClaudeBot: Anthropic в 2024 году отказалась от старого UA anthropic-ai и теперь использует ClaudeBot и для обучения, и для live retrieval, так что правило Disallow: ClaudeBot больше не соответствует чистому смыслу «заблокировать обучение, но оставить видимость». Мы оставили эту классификацию как есть и позже отдельно указали следствие.
Классификация отраслей
Мы отнесли каждый домен к одному из 16 отраслевых бакетов (news, social, streaming, ecommerce, search, finance, infrastructure, saas, academia, dev, gov, adult, gambling, travel, telecom, unknown) с помощью многоуровневого подхода:
- Словарь известных доменов — вручную составленная карта примерно 500 высокотрафиковых доменов по отраслям.
- Шаблоны TLD / суффиксов —
.gov→gov,.eduи.ac.*→academia, распознанные CDN-суффиксы →infrastructure. - Ключевые слова в имени домена — news, post, shop, bank, porn, casino и т. п. как запасные сигналы.
- Скрап главной страницы — для сайтов, которые не распознались на первых трех слоях и вернули
200дляrobots.txt, мы забирали HTML главной страницы, извлекали<title>,<meta name="description">,<meta property="og:type">и прогоняли ключевые слова через scoring по подсказкам, похожим на те, что используют языковые модели для категорий.
В итоге получилось 3 407 сайтов (34%) с уверенно определенной отраслью и 6 593, оставшихся в unknown. Бакет unknown в основном состоит из неанглоязычных региональных порталов, корпоративных сайтов на .com, которые не вписываются в один бакет, и традиционных издателей на малых языках, для которых у нас не было словарных записей. Когда в этом отчете приводится процент по отрасли, знаменатель — это классифицированная выборка по данной отрасли, а не все 10 000 сайтов.
III. Выводы
Вывод 1 — Каждый пятый сайт из топа по трафику блокирует хотя бы одного AI-бота
Среди 7 248 сайтов, которые удалось анализировать, 1 472 (20,31%) блокируют как минимум одного AI-бота. 1 230 (16,97%) имеют осознанное правило именно для AI. Базовый показатель для Googlebot — 2,18% (158 сайтов; в большинстве случаев это либо блокировка всего сайта по умолчанию для обслуживания, либо, в трех случаях, поисковики, блокирующие конкурентов).
Главные 20% — это в 9 раз выше базовой линии Googlebot. Это реальный сигнал: сайты с высоким трафиком примерно на порядок чаще блокируют AI-краулер, чем поисковый краулер. Но это также заметно меньшая цифра, чем нарратив о том, что «AI-блокировки уже почти везде», который с 2024 года кочует по прессе. Даже среди 10 000 самых посещаемых сайтов веба большая часть — 5 из 6 — молчит об AI.
Разрыв между «любой AI-блокировкой» (20,3%) и «явной AI-блокировкой» (17,0%) невелик в абсолютных величинах, но концептуально важен. Разница в 3,3 пункта — это доля сайтов, которые блокируют AI-ботов только потому, что их старое общее правило User-agent: * \n Disallow: / ловит все подряд, включая ботов, которых на момент написания правила еще не существовало. Число 17,0% — более чистый показатель того, «сколько крупнейших сайтов мира приняли именно AI-решение».
Если сравнивать с предыдущими исследованиями:
| Источник | Дата | Выборка | Доля блокировок |
|---|---|---|---|
| Originality.ai | март 2025 | 1 000 самых популярных новостных сайтов (англ.) | 35,7% блокируют GPTBot |
| Palewire | авг. 2024 | 1 500 новостных организаций | 36,0% блокируют любого AI-краулера |
| Reuters Institute | весна 2025 | 50 ведущих новостных брендов, 10 стран | 78% блокируют любого AI-краулера |
| WIRED / NYT | конец 2023 | Топ-50 новостей США | 26% блокируют GPTBot |
| Этот отчет (Thunderbit) | май 2026 | Tranco top 10,000 (все отрасли) | 20,3% / 17,0% явных |
Наши 17,0% явных блокировок ниже, чем в любом исследовании только по новостям, потому что две трети нашей выборки — не новости. Если ограничиться 650 новостными сайтами, получаем 47% — в том же диапазоне, что и прежние исследования, если учитывать состав выборки. Структурная картина совпадает: новостной сегмент блокирует AI в 3–4 раза чаще, чем остальной веб.
Вывод 2 — Глубокий разрез по отраслям: разброс от новостей до телекома в 12 раз
Самый часто цитируемый вывод двух лет разговоров об «AI scraping» — это цифра 80% новостных сайтов блокируют GPTBot из Originality.ai и Palewire. Наш срез дает меньшую, но все еще отчетливо выраженную цифру: 47,2% новостных сайтов в топ-10 000 блокируют хотя бы одного AI-бота, а 45,2% пишут явное AI-правило.
Но деление «новости против всего остального» слишком грубое. Полная разбивка (отрасли с n ≥ 10 в выборке) показывает гораздо более богатую картину:
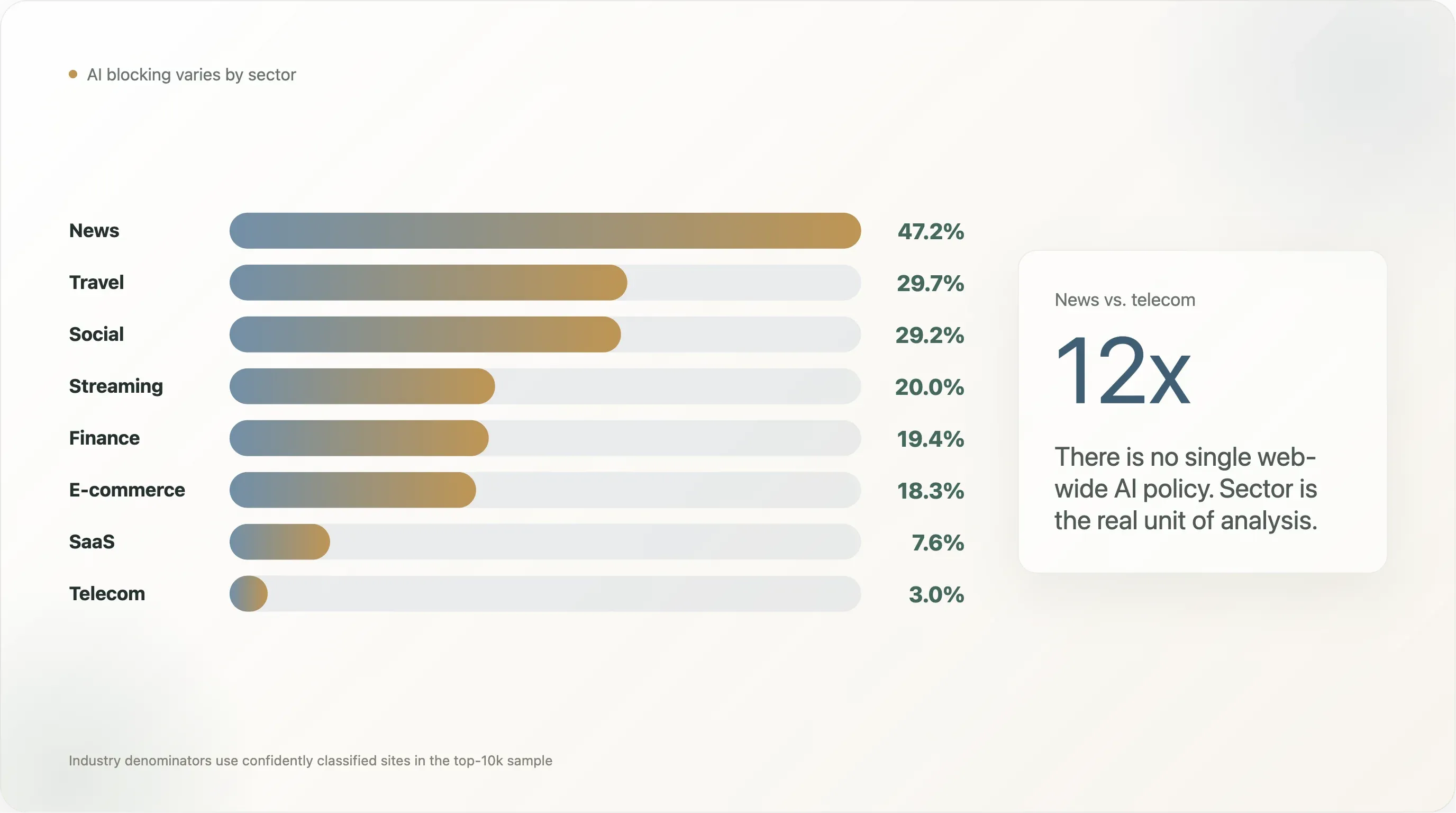
| Отрасль | n | Любая AI-блокировка | Явная | Googlebot заблокирован | Собственные правила | Cloudflare Managed | Молчат |
|---|---|---|---|---|---|---|---|
| Новости | 650 | 47,2% | 45,2% | 1,5% | 46,9% | 1,5% | 48,5% |
| Путешествия | 64 | 29,7% | 29,7% | 0,0% | 35,9% | 3,1% | 54,7% |
| Социальные сети | 65 | 29,2% | 23,1% | 4,6% | 23,1% | 6,2% | 66,2% |
| Стриминг | 440 | 20,0% | 17,7% | 0,7% | 16,8% | 3,6% | 75,5% |
| Финансы | 129 | 19,4% | 12,4% | 0,8% | 14,7% | 2,3% | 75,2% |
| E-commerce | 224 | 18,3% | 17,4% | 0,4% | 24,1% | 1,3% | 66,1% |
| Adult | 254 | 17,3% | 14,6% | 0,4% | 10,2% | 7,9% | 79,5% |
| Поиск | 12 | 16,7% | 0,0% | 0,0% | 0,0% | 0,0% | 100,0% |
| Академия | 268 | 14,6% | 13,8% | 0,4% | 13,4% | 3,4% | 77,2% |
| Азартные игры | 100 | 14,0% | 13,0% | 0,0% | 18,0% | 4,0% | 77,0% |
| Dev tools | 129 | 10,1% | 7,8% | 0,0% | 8,5% | 5,4% | 77,5% |
| SaaS | 369 | 7,6% | 6,2% | 0,3% | 9,5% | 0,8% | 87,5% |
| Государственные сайты | 172 | 5,2% | 3,5% | 0,0% | 4,1% | 0,6% | 83,1% |
| Инфраструктура | 47 | 4,3% | 0,0% | 0,0% | 4,3% | 2,1% | 72,3% |
| Телеком | 33 | 3,0% | 3,0% | 0,0% | 12,1% | 0,0% | 78,8% |
Разброс в 12 раз между новостями и телекомом и показывает, почему фраза «политика AI у веба» — неправильная единица анализа. Нет одной цифры; есть отраслевые цифры, расходящиеся на порядок. Ниже — четыре самых характерных наблюдения.
Новости: 47% блокируют, 47% пишут правила сами. Новости — это сегмент, который написал playbook. Cloudflare Managed в новостях встречается лишь в 1,5% случаев — эти издатели не отдают правило на аутсорс. Тексты необычайно насыщенные: у NYT это 14-строчная юридическая преамбула со ссылкой на «Art. 4 of the EU Directive»; у BBC — «Please use our site like a human, not a robot... TL;DR: Browse, read, watch, enjoy — like a human.»; у The Sun — «The Sun does not permit the unlicensed use of our content for large language models.» Это robots.txt как политическое заявление, а не как конфигурация.
Путешествия — 30%, и это сюрприз. Booking, Expedia, TripAdvisor, Kayak и крупные авиакомпании блокируют AI вдвое реже, чем новости. Паттерн выборочного разрешения стабилен: средний блокировщик в travel запрещает 5–7 training UA, но оставляет inference UA (PerplexityBot, ChatGPT-User, OAI-SearchBot) нетронутыми. Агрегированные цены и отзывы — это moat; цитирование назад на сайт — upside. Это самый чистый паттерн «training out, inference in» в любой отдельной отрасли.
Adult — 17%, тоже сюрприз. Раньше на меньших выборках было 0%. На полной выборке 1 из 6 adult-сайтов запрещает хотя бы одного AI-бота, при этом здесь самая высокая доля Cloudflare Managed среди всех отраслей (7,9%). Более половины AI-блокировок у adult-сайтов приходятся на переключатель Cloudflare, а не на решение издателя. Склонный к угрозе сценарий здесь — обучение генерации изображений: модели класса Stable Diffusion быстрее учатся визуальному стилю, чем текстовые модели — стилю письма.
SaaS на уровне 7,6% — это против интуиции. Продавцы ПО чаще всех громко говорят об AI-политике, но их robots.txt в основном открыт. Правильное чтение: маркетинговые команды SaaS уже поняли, что AI-поиск — это канал дистрибуции. Те вендоры, кто действительно подумал об этом, чаще разрешают, а не запрещают — список явных Allow для GPTBot (см. Вывод 12) в основном состоит из компаний из security и dev tooling.
Госсайты 5,2%, телеком 3,0%, инфраструктура 4,3%, dev 10,1%. Обязанности по public records делают Disallow: / юридически рискованным для .gov. Маркетинговые сайты телеком-операторов хотят быть находимыми. Apex-домены CDN не защищают ничего. Dev tooling явно делает opt-in: ценность его контента растет, когда LLM на него ссылаются.
Вывод: не существует единой цифры «веб блокирует / не блокирует AI», которая не теряла бы больше смысла, чем передает. Говорить об этом честно можно только через отраслевой разрез.
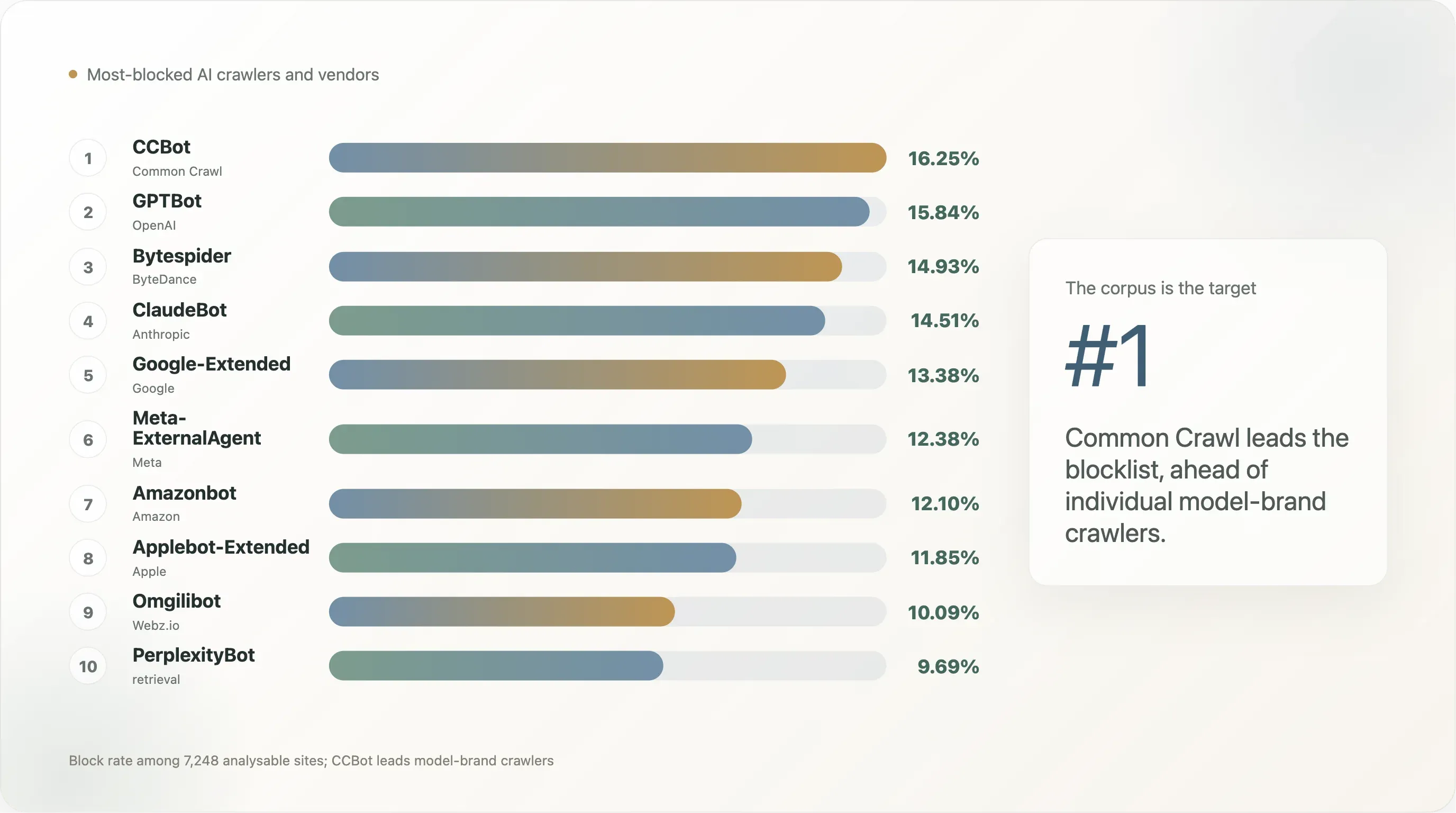
Вывод 3 — По AI-вендорам: кого блокируют чаще всего?
Еще один естественный разрез данных — не по ботам, а по AI-компаниям. У нескольких вендоров несколько ботов (OpenAI запускает три: GPTBot, ChatGPT-User, OAI-SearchBot; Anthropic — два: ClaudeBot, anthropic-ai; Meta — два: Meta-ExternalAgent, FacebookBot). Если агрегировать по вендору, мы ближе всего подходим к вопросу «что публичный веб думает о каждой AI-компании».
| AI-вендор | Агрегированные боты | Сайты, блокирующие ≥ 1 бота | % от анализируемых |
|---|---|---|---|
| Common Crawl | CCBot | 1 178 | 16,25% |
| OpenAI | GPTBot, ChatGPT-User, OAI-SearchBot | 1 172 | 16,17% |
| Anthropic | ClaudeBot, anthropic-ai | 1 111 | 15,33% |
| ByteDance | Bytespider | 1 082 | 14,93% |
| Meta | Meta-ExternalAgent, FacebookBot | 989 | 13,65% |
Google-Extended | 970 | 13,38% | |
| Amazon | Amazonbot | 877 | 12,10% |
| Apple | Applebot-Extended | 859 | 11,85% |
| Webz.io (Omgili) | Omgili, Omgilibot | 731 | 10,09% |
| Cohere | cohere-ai | 717 | 9,89% |
| Perplexity | PerplexityBot, Perplexity-User | 715 | 9,86% |
| Diffbot | Diffbot | 684 | 9,44% |
| You.com | YouBot | 563 | 7,77% |
| AI2 (Allen AI) | AI2Bot | 487 | 6,72% |
| DuckDuckGo | DuckAssistBot | 482 | 6,65% |
Common Crawl — самый часто целевой объект, хотя это не LLM-оператор, а некоммерческий веб-архив. Причина — в рычаге влияния: CCBot питает почти все open-weight модели и существенную долю закрытых. Блокировка CCBot в первую очередь — правило с наибольшим охватом, которое может написать издатель.
OpenAI, Anthropic и ByteDance сгруппированы в диапазоне 14–16%. Лидерство OpenAI отчасти артефакт подсчета (три OpenAI-бота против одного у ByteDance). 14,9% у Bytespider — это эффект поведения Bytespider: с 2024 года документировалось, что он игнорирует robots.txt, и издатели блокируют его как публичный сигнал, а не потому, что боятся TikTok.
Meta, Google, Amazon, Apple на уровне 12–14% — это вторая группа, блокируемая скорее в оборонительном режиме, чем как политическое заявление. Небольшие вендоры (Webz.io, Cohere, Perplexity, Diffbot, You.com, AI2, DuckDuckGo) на уровне 6–10% в основном поднимаются из-за базового floor в 3,8%; явные правила для них находятся в диапазоне 1–4%.
xAI (Grok), Mistral и большинство европейских / китайских лабораторий в таблице отсутствуют — они не публиковали документированные UA для training-crawler. Текущая экосистема robots.txt — это диалог между американскими/китайскими вендорами, которые выпустили UA, и американскими/европейскими издателями, которые написали правила; те, кто UA не выпустил, в переговорах невидимы.
Вывод 4 — CCBot стал новой точкой напряжения, а не GPTBot
Если упорядочить ботов по top-10k, получится так:
| Место | Бот | Доля блокировок | Доля явных правил |
|---|---|---|---|
| 1 | CCBot (Common Crawl) | 16,25% | 12,90% |
| 2 | GPTBot (OpenAI) | 15,84% | 12,72% |
| 3 | Bytespider (ByteDance) | 14,93% | 11,35% |
| 4 | ClaudeBot (Anthropic) | 14,51% | 11,13% |
| 5 | Google-Extended | 13,38% | 10,18% |
| 6 | Meta-ExternalAgent | 12,38% | 8,95% |
| 7 | Amazonbot | 12,10% | 8,66% |
| 8 | Applebot-Extended | 11,85% | 8,72% |
| 9 | Omgilibot | 10,09% | 5,31% |
| 10 | anthropic-ai (устаревший) | 9,99% | 6,55% |
| 11 | cohere-ai | 9,89% | 6,42% |
| 12 | PerplexityBot | 9,69% | 6,40% |
| 13 | Diffbot | 9,44% | 5,95% |
| 14 | ChatGPT-User (inference) | 8,90% | 5,73% |
| 15 | YouBot (inference) | 7,77% | 4,29% |
| 16 | OAI-SearchBot (inference) | 6,83% | 3,66% |
| baseline | Googlebot | 2,18% | — |
| baseline | Bingbot | 2,27% | — |
Смысл этой таблицы в том, что первым публичный веб блокирует не бренд модели, а корпус. Архив Common Crawl на 250 миллиардов страниц — это крупнейший источник обучения для GPT-3, GPT-4, Llama 1 / 2 / 3, Falcon, Mistral, BLOOM и большинства open-weight моделей, выпущенных с 2020 года. Сайт, который хочет выйти из режима «быть в следующей frontier-модели», оптимизирует задачу, запрещая CCBot первым: если вас нет в Common Crawl, вы по сути бесплатно исключены из open-source пайплайна обучения. GPTBot и ClaudeBot идут вторыми и третьими, потому что это видимые фронтенды двух конкретных коммерческих продуктов; UA на уровне корпуса — структурная цель.
Менее высоко стоящие AI-боты тоже информативны. Omgilibot на уровне 10% — необычно высокий показатель для бота, о котором большинство читателей даже не слышали: его запускает Webz.io, брокер контент-данных, продающий веб-архивы операторам LLM, и заметный кластер новостных организаций уже начал явно называть его в своих файлах. AI2Bot на уровне 6,7% (и соответствующее правило Ai2Bot-Dolma на сайтах Squarespace) говорит о том, что академическое LLM-сообщество тоже попадает под флаги у издателей, которые не обязательно различают «некоммерческий исследовательский краулер» и «коммерческий краулер».
Кластер инференса — ChatGPT-User, OAI-SearchBot, YouBot, Perplexity-User — находится на 4–8 пунктов ниже training-кластера. Этот разрыв и есть ответ на давний политический вопрос: да, сайты с большим трафиком различают бота, который собирает данные для будущего обучения модели, и бота, который делает live retrieval, чтобы прямо сейчас ответить на вопрос пользователя. Не всегда различают (общие правила этого не делают), но заметная доля пишет правила, адресованные именно training-стороне.
Вывод 5 — 14% блокируют CCBot, но оставляют Googlebot приветствуемым — паттерн «блокировать корпус, сохранять поиск»
Самое распространенное селективное правило в топ-10k:
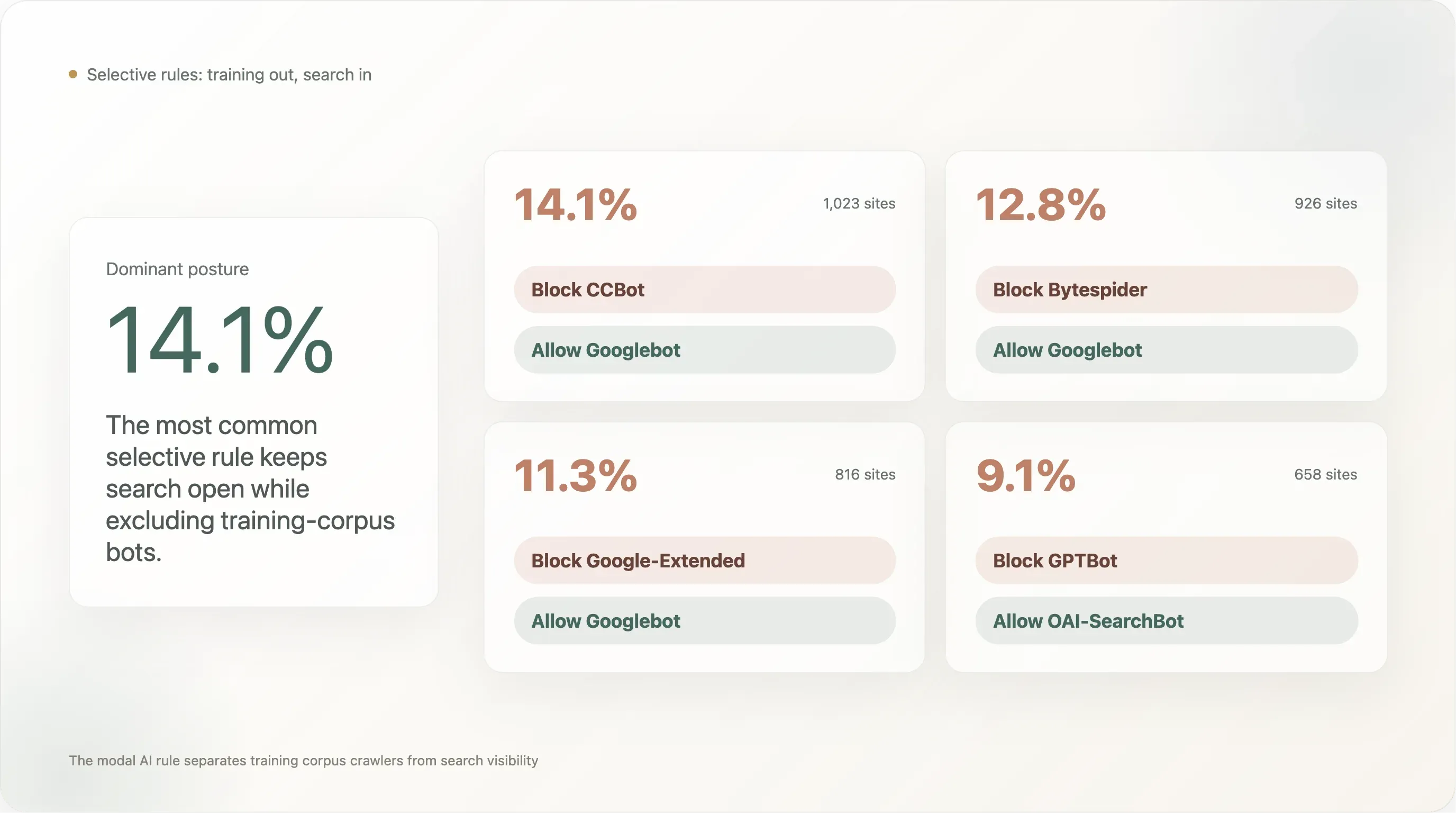
| Шаблон правила | Сайты | % от анализируемых |
|---|---|---|
Блокировать CCBot, разрешить Googlebot | 1 023 | 14,11% |
Блокировать Bytespider, разрешить Googlebot | 926 | 12,78% |
Блокировать Google-Extended, разрешить Googlebot | 816 | 11,26% |
Блокировать GPTBot, разрешить OAI-SearchBot | 658 | 9,08% |
Блокировать GPTBot, разрешить ChatGPT-User | 525 | 7,24% |
Блокировать CCBot, разрешить PerplexityBot | 519 | 7,16% |
Блокировать anthropic-ai, разрешить ClaudeBot | 59 | 0,81% |
Самый распространенный паттерн (14,1%) — «блокировать Common Crawl, сохранять видимость в Google Search». Второй по популярности (12,8%) — «блокировать Bytespider, сохранять видимость в Google Search», то есть блокировать краулер ByteDance с проблемной репутацией, но оставлять легитимный поисковый baseline нетронутым. Третий (11,3%) — «блокировать собственный AI-training UA Google, но оставить поисковый UA Google», именно для этого Google и создавал Google-Extended: издатель отказывается от обучения Bard / Gemini, не теряя поисковый рейтинг.
Эти три цифры вместе описывают доминирующую позицию на top-10k вебе: запретить ботов корпуса обучения, оставить поисковых и inference-ботов нетронутыми. Миноритарный паттерн «запретить обучение, но разрешить конкретный live-retrieval UA этой LLM» — GPTBot ✗ / ChatGPT-User ✓ на уровне 7,2% — существует, но он меньше, чем отрезы на уровне корпуса.
Строка anthropic-ai / ClaudeBot на уровне 0,81% отражает устаревание UA у Anthropic в 2024 году: ClaudeBot теперь обслуживает и обучение, и инференс, из-за чего исчезло чистое выражение «блокировать обучение, разрешить цитирование» для Claude, которое раньше обеспечивал anthropic-ai. Это, пожалуй, самое недооцененное решение по дизайну UA в 2024–2025 годах — оно убрало из robots.txt целый класс выражений политики.
Вывод 6 — Новости по странам и языкам
Если разрезать новостную категорию по страновому TLD — помня, что это означает .de для немецких новостей, .fr для французских и т. д., а не язык контента, — внутри новостей разброс оказывается больше, чем между новостями и остальным вебом:
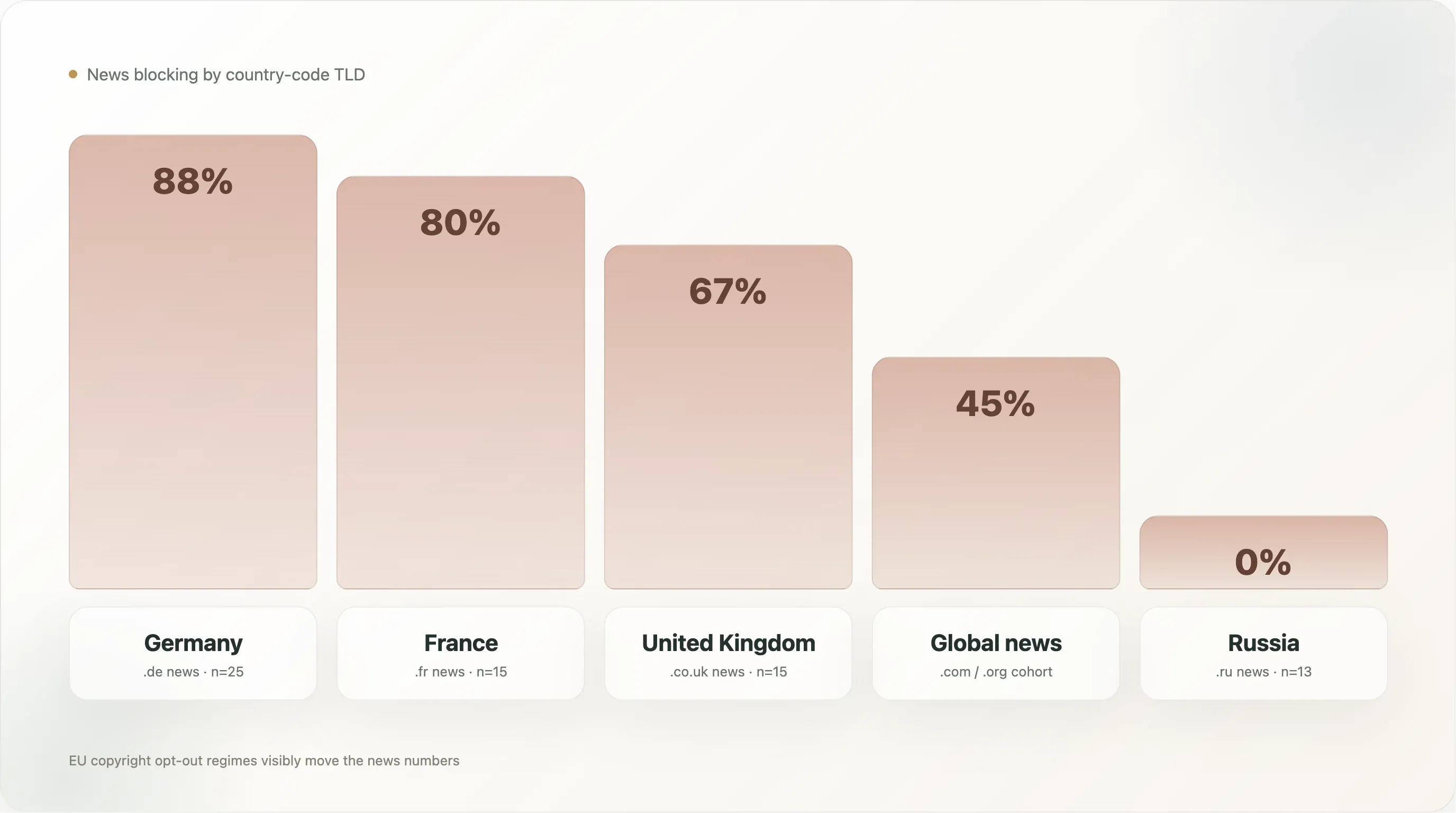
| Страна (только новости) | n | Любая AI-блокировка | Явная |
|---|---|---|---|
🇩🇪 Германия (.de) | 25 | 88,0% | 88,0% |
🇫🇷 Франция (.fr) | 15 | 80,0% | 80,0% |
🇬🇧 Великобритания (.co.uk) | 15 | 66,7% | 53,3% |
🇪🇸 Испания (.es) | 5 | 60,0% | 60,0% |
🇮🇹 Италия (.it) | 13 | 53,8% | 53,8% |
Глобальные новости (.com/.org/etc) | 500 | 45,0% | 42,8% |
🇵🇱 Польша (.pl) | 7 | 42,9% | 42,9% |
🇯🇵 Япония (.jp) | 12 | 25,0% | 25,0% |
🇷🇺 Россия (.ru) | 13 | 0,0% | 0,0% |
🇬🇷 Греция (.gr) | 6 | 0,0% | 0,0% |
Немецкие новости — самый блокирующий подсегмент во всем датасете, 88%, и это 88% явных блокировок: по сути, в топ-10k нет немецкого новостного сайта, который бы позволял AI-training-краулерам добраться до своего архива. В этот кластер входят Spiegel, Bild, Welt, Zeit, FAZ, Süddeutsche, Heise, Golem, Stern, Focus — весь мейнстрим немецкого издательского мира плюс tech-издатели, которые написали свои правила сами. Под этим стоит плотная политическая инфраструктура: VG Media, коллективная организация прав издателей в Германии, была самым агрессивным истцом в европейских судебных разбирательствах по AI-копирайту, а статья 4 Директивы ЕС имплементирована в немецкое право как §44b UrhG с явной машиночитаемой формулировкой отказа. К моменту появления AI-вендоров немецкие издатели были лучше всех готовы перевести эту правовую позицию в правила robots.txt.
Франция с 80% — чуть ниже. Правовая среда похожа (Директива 2019/790 перенесена во французское право), и поведение кластера похоже — lemonde.fr, lefigaro.fr, liberation.fr, lequipe.fr, 20minutes.fr, ouest-france.fr все блокируют, а файл Le Monde дополнительно ссылается на французское droit du producteur de base de données (статья L 342-1 Кодекса интеллектуальной собственности) как на параллельное внутреннее правовое основание. У Франции есть дополнительная особенность: в 2024 году коммерческий суд Парижа постановил, что отказ через robots.txt достаточен как уведомление по статье 4; это прямое прецедентное основание, которого пока не имеет ни одна другая юрисдикция.
Великобритания на уровне 67% ниже, и причина в том, что несколько крупных британских издателей (thesun.co.uk, dailymail.co.uk, mirror.co.uk) используют общие deny-all блоки User-agent: * вместо AI-специфических правил, что тянет явную долю вниз до 53%. Суммарный эффект тот же — эти сайты не разрешают AI-краулинг, — но политика выражена как «никаких ботов, кроме этого конкретного allowlist поисковиков», а не как запрет по именованным AI-ботам. Правовая база тоже слабее: после Brexit Великобритания унаследовала логику статьи 4, но соответствующая внутренняя судебная практика менее плотная.
Российские новости на уровне 0% — самая неожиданная строка. Тринадцать новостных сайтов на российских доменах в выборке (dzen.ru, rbc.ru, ria.ru, kommersant.ru, tass.ru, lenta.ru, gazeta.ru, interfax.ru, kp.ru, tass.com и др.) — ни один не блокирует никакого AI-краулера. Вероятное объяснение: обучение LLM на русском языке в основном идет через собственные GPT-модели Яндекса (которые используют внутренние краулеры Яндекса, а не Common Crawl), российский режим авторского права пока не получил аналога статьи 4, а крупные российские издатели воспринимают западные LLM как несущественный фактор (экспортные ограничения США и так ограничивают сервисы OpenAI / Anthropic в России), а Яндекс — как внутреннего участника, а не противника. Позиция по политике здесь просто другая.
Японские новости на уровне 25% — это третий паттерн. В Японии в законе об авторском праве есть явные исключения для text and data mining (статья 30-4, изменена в 2018 году), которые более либеральны, чем статья 4 Директивы ЕС: они разрешают TDM для целей «не потребления» — включая обучение AI — без согласия правообладателя. У японских издателей меньше юридических оснований для opt-out, и соответствующие показатели в robots.txt ниже. Те 25%, что блокируют, — это в основном крупнейшие, наиболее глобальные издатели (asahi.com, nikkei.com), ориентированные на международный, а не только внутренний рынок.
Сравнение по странам — самое чистое доказательство в отчете, что главный драйвер AI-блокировки — правовой режим, а не технология и не экономика отрасли. Новостные кластеры ЕС лежат в диапазоне 54–88%; не-ЕС кластеры (Россия, Япония, глобальный .com) — от 0 до 45%. Пик 88% — в стране с самым развитым внедрением статьи 4; пол 0% — в стране, где по сути нет никакого закона о AI-политике.
Вывод 7 — ЕС против остальных: разрыв в 16 пунктов
Если поднять страновой взгляд на уровень выше, разрез ЕС против остального мира резкий:
| Регион | n | Любая AI-блокировка | Явная |
|---|---|---|---|
ccTLD ЕС (.fr, .de, .es, .it, .nl, .pl, .se, .dk, .fi, .be, .at, .cz, .hu, .ro, .gr, .pt, .ie, .sk, .bg) | 617 | 35,2% | 33,9% |
Национальные ccTLD вне ЕС (.uk, .jp, .kr, .cn, .ru, .br, .in, .au, .mx, .ca, .tr, .ar, .cl, .co, .pe) | 897 | 17,2% | 13,6% |
Глобальные (.com, .net, .org и др.) | 5 734 | 19,2% | 15,7% |
Сайты на ccTLD ЕС блокируют AI вдвое чаще, чем национальный не-ЕС-кластер, и почти вдвое чаще, чем глобальная база .com. Разница стабильна для всех стран ЕС (среднее не определяется одной страной) и по отраслям (.de новости — 88%, .de SaaS — около 12%, .de e-commerce — около 25% — везде выше, чем у глобальных аналогов).
Мы нашли 275 файлов robots.txt в top-10k, которые явно ссылаются на Директиву 2019/790 в комментариях — примерно 3,8% разбираемой выборки. Этот кластер в основном состоит из европейских издателей, но не ограничивается ими: несколько американских новостных брендов (в частности NYT, который прямо цитирует «Art. 4 of the EU Directive»), некоторые британские сайты и несколько крупных европейских e-commerce-площадок тоже воспроизводят правовую формулировку. В 87 файлах упоминается «TDM» или «text and data mining» по названию. 460 файлов содержат какую-либо форму языка про резервирование прав («explicitly opts out», «all rights reserved», «no commercial use», «no machine learning»), даже если не ссылаются на конкретный закон.
Два более тонких наблюдения из этого среза:
Эффект ЕС — не только про новости. Если зафиксировать новости, не-новостные сайты ЕС все равно блокируют AI чаще, чем не-новостные сайты вне ЕС (примерно 28% против 14%). Небольшая, но реальная доля EU SaaS, e-commerce и academia уже интернализировала рамку статьи 4 и для своих секторов.
Язык в стиле ЕС становится де-факто шаблоном даже за пределами ЕС. Шаблон Managed robots.txt от Cloudflare — глобально распространяемый — в boilerplate прямо ссылается на «ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790». Сайт в США, который включает у Cloudflare настройку «Block AI Bots», без всякого осознания может фактически заявлять резервирование прав по норме ЕС. Это один из самых интересных артефактов дрейфа политики, которые мы нашли: европейская правовая концепция глобализируется через UI продукта американского инфраструктурного провайдера.
Вывод 8 — Шаблоны и их происхождение
Распределение по происхождению шаблонов у 6 638 сайтов, вернувших разбираемый robots.txt:
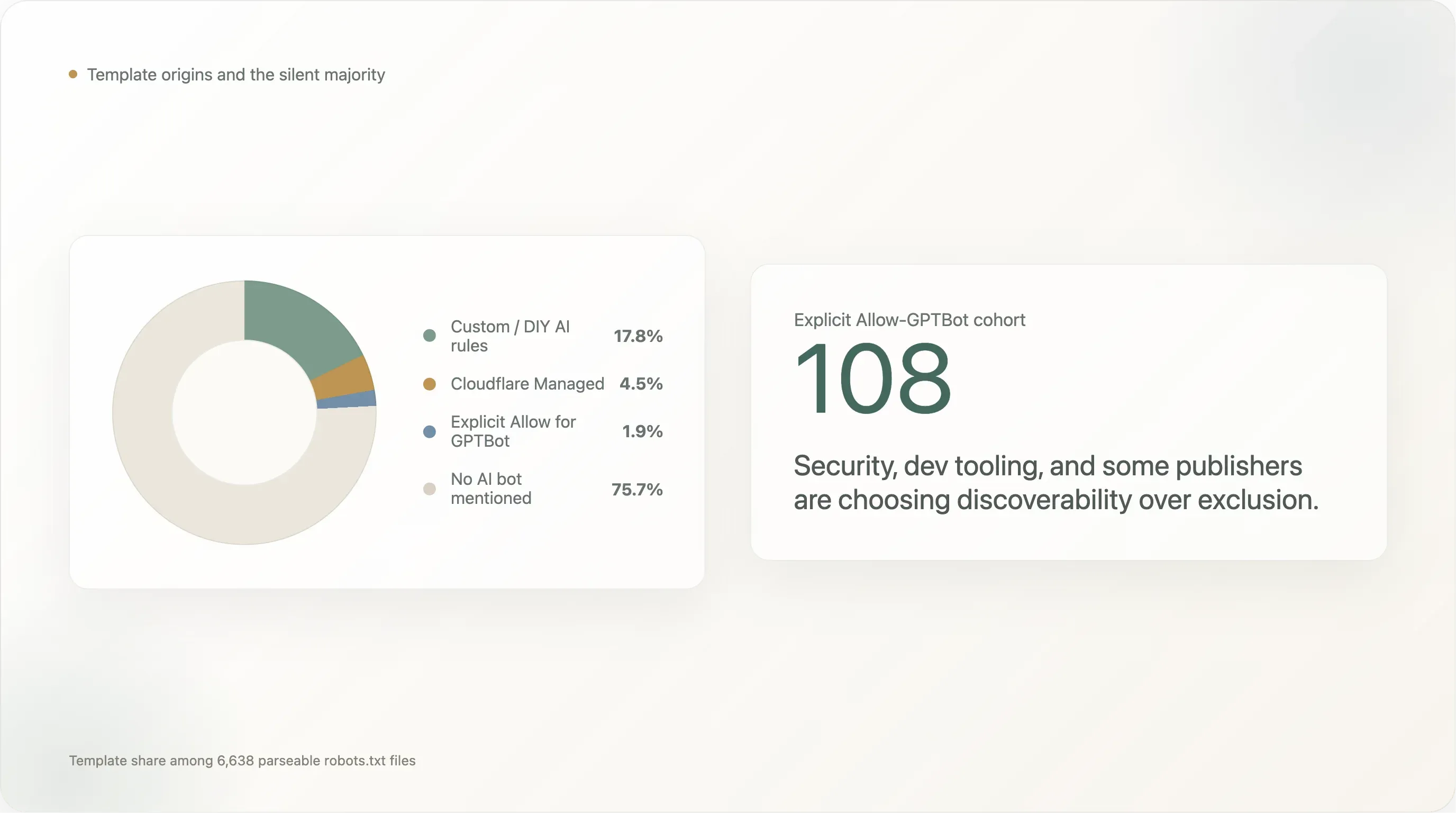
| Шаблон | Сайты | Доля |
|---|---|---|
| Ни одного AI-бота не упомянуто (default Shopify-style, Yoast, вручную написано без учета AI) | 5 024 | 75,7% |
| Собственные / DIY AI-правила | 1 183 | 17,8% |
Cloudflare Managed (Content-Signal: search=yes,ai-train=no) | 302 | 4,5% |
Явный Allow: / для GPTBot | 124 | 1,9% |
| Дефолт Squarespace (28 AI UA в блоке с ограничением по путям) | 5 | 0,1% |
DIY-правила доминируют на уровне 17,8%. Кластер самописных блокировщиков возглавляют все социальные платформы (facebook.com, twitter.com, linkedin.com, whatsapp.com, tiktok.com, snapchat.com, pinterest.com, x.com, chatgpt.com), крупнейшие e-commerce-площадки (amazon.com, amazonvideo.com), крупные новостные бренды (nytimes.com, cnn.com, bbc.com, theguardian.com, forbes.com, reuters.com, bbc.co.uk, t-online.de, weather.com), ключевые media / streaming-сайты (netflix.com, vimeo.com, soundcloud.com, imdb.com) и длинный хвост профессиональных сервисов (canva.com, medium.com).
Cloudflare Managed на уровне 4,5% — намного выше, чем проникновение этого же шаблона в самой верхушке распределения, и ниже, чем его проникновение в длинном хвосте за пределами окна этого отчета. Шаблон чаще всего встречается в сегменте рангов 1001–10 000 (4–5%) и почти отсутствует в самой вершине кривой (Top 100: 1 сайт использует его; Top 101–1000: 5 сайтов). Крупные глобальные свойства пишут правила сами; длинный хвост пользуется переключателем.
Несколько конкретных сайтов Cloudflare Managed заслуживают упоминания. cloudflare.com сам использует этот шаблон, что логично: Cloudflare dogfoods свой продукт на собственном домене. theatlantic.com тоже использует шаблон — это единственный крупный новостной бренд США, у которого мы не нашли собственного правила. spankbang.com использует шаблон — это самый высоко ранжированный adult-сайт, принявший AI-блокировку, внедренную Cloudflare. linktr.ee использует шаблон, блокируя AI-training сразу во всей креаторской экономике на платформе Linktree одним решением вендора. launchpad.net, nexusmods.com, vinted.fr, cookielaw.org, rustdesk.com и длинный список более мелких медиа-активов дополняют видимый кластер Cloudflare Managed.
Паттерн adoption у Cloudflare — самое конкретное доказательство, что значительная часть «AI-политики веба» определяется инфраструктурными провайдерами. Абсолютная доля невелика (4,5%), но структурно это важно: шаблон — дефолт, который поставляет Cloudflare, и траектория «включено по умолчанию» на следующие 12 месяцев направлена вверх. Если Cloudflare переведет блок AI Bots в режим по умолчанию для новых аккаунтов, глобальная доля блокировки заметно вырастет без какого-либо решения со стороны издателей.
Дефолт Squarespace (5 сайтов в top-10k, но гораздо больше вне нашей выборки) — это другой паттерн: Squarespace поставляет robots.txt, который называет 28 AI-ботов в одном блоке, но эти боты наследуют ограничения по путям от User-agent: *, а не получают sitewide ban. AI-краулеры могут забирать /, главную страницу, страницы продуктов, блог. Просто не могут забирать /config или /account. Ранее мы уже указывали на это как на источник ложноположительных «AI block» чтений в сторонних сканах сайтов на Squarespace; здесь оговорка та же.
Вывод 9 — AI-политика ровно распределена по ранговой шкале
Обычная интуиция для такого исследования — самые посещаемые сайты должны иметь самую жесткую AI-политику: им больше терять от вытеснения обучения, у них больше юридических возможностей, на них сильнее публичное внимание. Данные этого не подтверждают.
| Пакет рангов | n | Любая AI-блокировка | Явная | Cloudflare Managed |
|---|---|---|---|---|
| Top 100 | 67 | 22,4% | 17,9% | 1 сайт |
| Top 101–1 000 | 598 | 22,9% | 19,2% | 5 сайтов |
| Top 1 001–5 000 | 2 810 | 19,0% | 15,3% | 99 сайтов |
| Top 5 001–10 000 | 3 773 | 20,8% | 17,8% | 197 сайтов |
Четыре группы лежат в диапазоне 19–23%. Top 100 не более агрессивен, чем длинный хвост с рангами 5001–10000. Главная цифра выглядит как свойство публичного веба 2026 года, а не как показатель того, насколько велик или заметен отдельный сайт.
Два фактора этому способствуют. Во-первых, верхушка кривой состоит из инфраструктурных / SaaS / search / portal-доменов (Microsoft, Apple, Google и т. д.), у которых собственные AI-блокировки и так невысоки. Во-вторых, длинный хвост включает большую долю региональных новостных издателей и сайтов под юрисдикцией ЕС, которые — как показали Выводы 6 и 7 — блокируют AI агрессивнее глобального среднего. Эти два эффекта примерно взаимно компенсируются, и на выходе получается ровная headline-цифра.
Колонка Cloudflare Managed все же меняется по кривой. В Top 1000 — 6 сайтов под Cloudflare (1,0%); в Top 1001–10000 — 296 (5,7%). Крупные сайты пишут правила сами; длинный хвост пользуется переключателем вендора. Это единственный значимый сигнал, зависящий от ранга, в датасете, и он показывает, что по мере спуска по трафик-кривой от вершины веба к длинному хвосту доля AI-политики, заданной вендором, а не издателем, неуклонно растет. Мы ожидаем, что этот градиент продолжится за пределы top-10k в top-100k и дальше.
Вывод 10 — Пять анатомий: как выглядит robots.txt, когда это действительно политика
Цифры описывают форму датасета; а реальный характер «AI-политики публичного веба» лучше всего виден на конкретных файлах. Вот пять, на которых стоит задержаться, подобранных так, чтобы охватить все пространство политики.
Анатомия 1 — The New York Times (nytimes.com)
Первые 14 строк nytimes.com/robots.txt:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.Это robots.txt как юридическое доказательство. Файл написан так, чтобы его можно было использовать в качестве доказательства в деле NYT v. OpenAI, к которому он относится. Ссылки на «Art. 4 of the EU Directive» — со стороны американского издателя — иллюстрируют наблюдение из Вывода 7 о том, что правовые рамки ЕС просачиваются в глобальный дискурс. Явный запрет на «creating or providing archived or cached data sets» направлен прямо против Common Crawl. Файл длиннее 60 строк, с именованными блоками User-agent для GPTBot, OAI-SearchBot, ChatGPT-User, anthropic-ai, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Bytespider, Diffbot, Meta-ExternalAgent, Amazonbot, Omgili, Omgilibot и еще нескольких — у каждого названного бота свой Disallow: /.
Анатомия 2 — Der Spiegel (spiegel.de) — разрешение на уровне секций
robots.txt у Der Spiegel — самый операционно сложный во всем датасете. Соответствующий блок:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /Комментарий переводится как «Тестовое разрешение search-краулеров OpenAI для отдельных разделов». Spiegel whitelist-нул семь конкретных категорий контента — международные новости, отношения / партнерства, здоровье, семья, путешествия, психология и стиль — для inference-UA OpenAI, а все остальное заблокировал. Политические разделы, немецкие национальные новости и расследовательская журналистика явно исключены. Common Crawl, Bytespider, Cohere, Webzio-Extended и другие training-UA получают полный Disallow: / ниже по файлу.
Это robots.txt как редакционная политика на уровне секций. Неявная теория: lifestyle-контент имеет меньший риск вытеснения обучения и более высокий потенциал для цитирования в инференсе, поэтому Spiegel разрешает AI показывать именно эти разделы; политика и расследования — это moat, поэтому AI туда не допускается. Мы не видели этого паттерна больше нигде. Он подразумевает уровень внутренней координации между редакцией, юристами и инфраструктурой, которого большинство новостных редакций еще не достигли. Мы ожидаем, что такой гранулярный уровень политики распространится в 2026–2027 годах — файл Spiegel уже сейчас выглядит как ранний индикатор.
Анатомия 3 — BBC (bbc.com) — форма политического заявления
robots.txt у BBC начинается так:
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.BBC versionирует свой robots.txt (строка # version: ec59bd... — это git commit hash), запрещает восемь конкретных видов использования AI, которые отслеживают юристы BBC, и заканчивает однострочным резюме в том же разговорном тоне, на котором строится бренд BBC. Фраза «expressly opts out of any statutory exceptions in any jurisdiction» — это сознательный глобальный отказ: мы не доверяем ни одному отдельному правовому режиму защитить нас так, как нам нужно, поэтому мы одновременно заявляем отказ везде. Это самый «юридически выверенный» robots.txt в датасете; он читается скорее как пресс-релиз, чем как конфигурационный файл.
Анатомия 4 — WordPress.org — явное приветствие
Сравните все вышеперечисленное с wordpress.org:
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org явно разрешает девяти AI-training-краулерам, включая три (Bytespider, CCBot, anthropic-ai), которые чаще всего блокируют в других местах. Неявная теория тут такая: документация и экосистема плагинов WordPress — это общественное благо, чья ценность растет, когда AI-ассистенты могут отвечать на вопросы по нему. Каждый раз, когда кто-то спрашивает Claude «как настроить permalinks в WordPress?», а Claude обучен на wordpress.org/documentation/, миссия WordPress достигается. Фонд, похоже, решил, что быть внутри тренировочного корпуса каждой модели — стратегический плюс, и использовал выразительную грамматику файла, чтобы это заявить.
Анатомия 5 — The Verge (theverge.com) — спонсорский гибрид
Еще один паттерн, который стоит показать. У The Verge AI-правила структурированы как Disallow: / \ Allow: /sp/:
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp/Путь /sp/ — это раздел The Verge со спонсируемым / партнерским контентом. Редакционный контент заблокирован от AI-training; спонсируемый — разрешен. Экономическая логика проста: спонсоры платят за то, чтобы их контент был находимым, в том числе через AI; редакционный флагман — это moat. GPTBot полностью открыт (вероятно, как результат прямых отношений с OpenAI), Applebot тоже полностью открыт как поисковый baseline, а остальные получают гибридный режим. Это единственная найденная нами структура с «tiered AI access» такого рода.
Эти пять файлов описывают текущий диапазон AI-политики в robots.txt. Большинство файлов в top-10k не похожи ни на один из них — они либо молчат, либо используют шаблон вендора. Те, что похожи на один из этих, написаны людьми, которые решили, что файл стоит прочитать очень внимательно.
Примечание о размере файла: медианный размер тела robots.txt в нашей выборке — 858 байт — слишком мало, чтобы выразить осмысленную AI-политику. Настоящие правила живут в правом хвосте: 1 005 сайтов (15,3%) имеют файл больше 5 КБ, 273 — больше 20 КБ, а максимум составил 248 КБ. 460 файлов содержат язык о резервировании прав; 275 прямо называют EU 2019/790. В 2026 году robots.txt все чаще становится версионируемым документом, проверенным юристами, а не одной строкой конфигурации.
Вывод 11 — 108 сайтов явно приветствуют GPTBot
Небольшой, но заметный кластер пишет правило User-agent: GPTBot \n Allow: / — то есть делает обратное тому, что чаще обсуждают, когда говорят «заблокировать GPTBot». В нашей выборке таких сайтов 108 с явным Allow для GPTBot на корневом пути. Первые 25 по рангу Tranco:
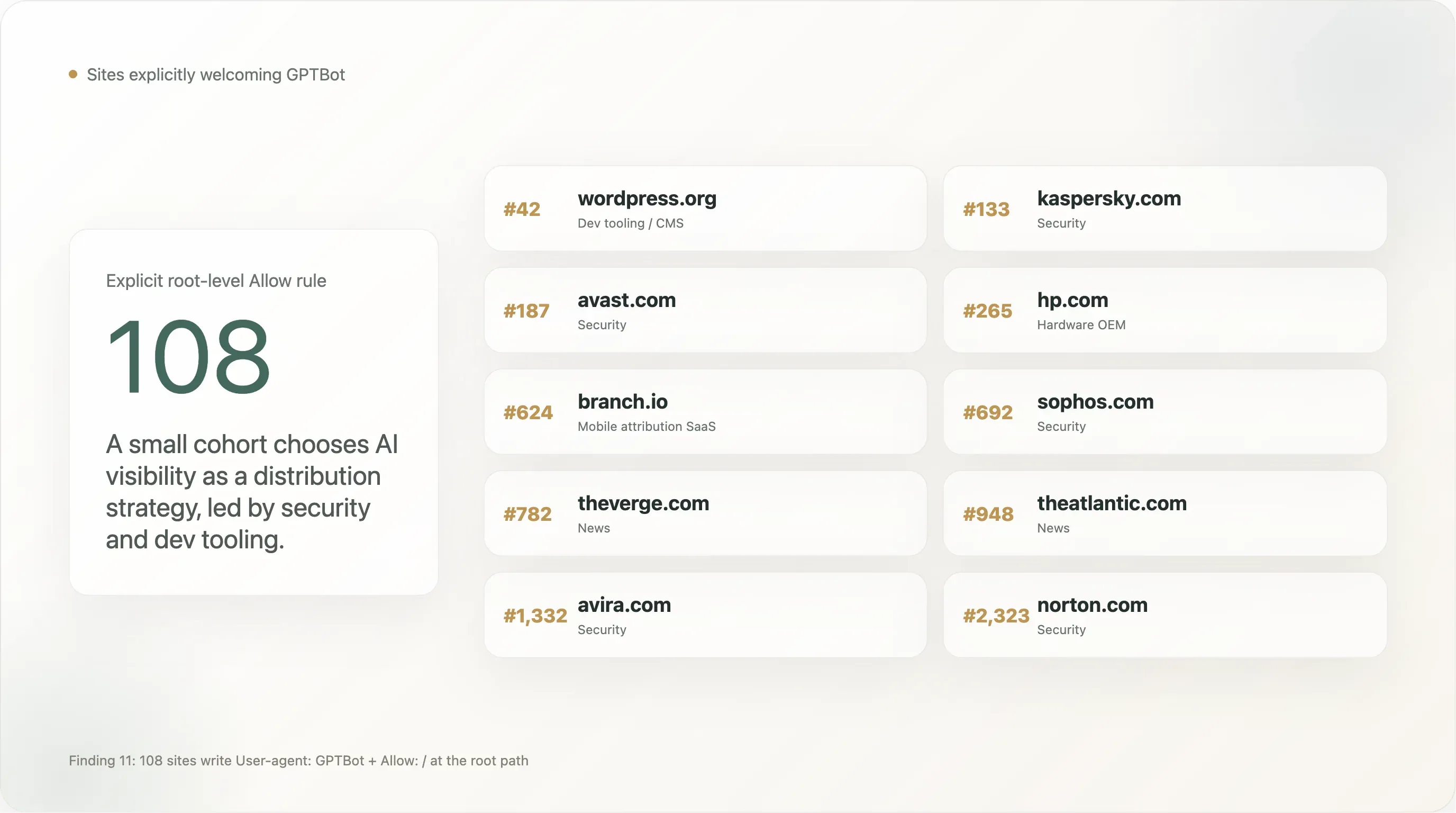
| Ранг | Домен | Сектор |
|---|---|---|
| 42 | wordpress.org | Dev tooling / CMS |
| 133 | kaspersky.com | Security |
| 187 | avast.com | Security |
| 265 | hp.com | Hardware OEM |
| 624 | branch.io | Mobile attribution SaaS |
| 692 | sophos.com | Security |
| 782 | theverge.com | News |
| 905 | rambler.ru | Российский портал |
| 945 | kleinanzeigen.de | Немецкий маркетплейс |
| 948 | theatlantic.com | News |
| 1 092 | lge.com | LG Electronics |
| 1 300 | justdial.com | Индийский локальный поиск |
| 1 332 | avira.com | Security |
| 1 412 | youm7.com | Египетские новости |
| 1 530 | goodreturns.in | Индийские финансы |
| 1 621 | publi24.ro | Румынские объявления |
| 1 807 | geocomply.com | Compliance SaaS |
| 1 908 | nba.com | Спорт |
| 1 956 | oneindia.com | Индийские новости |
| 1 974 | mindbox.ru | Российский SaaS |
| 2 009 | thesun.co.uk | News |
| 2 126 | vox.com | News |
| 2 140 | mgid.com | Native advertising |
| 2 314 | ninjarmm.com | IT management SaaS |
| 2 323 | norton.com | Security |
Несколько закономерностей:
Security-компании заметно перепредставлены. Kaspersky, Avast, Sophos, Avira, Norton, NinjaRMM явно разрешают GPTBot. Это осознанная стратегия дистрибуции: когда пользователь спрашивает ChatGPT «какой антивирус лучше для Windows?», наличие бренда внутри тренировочного корпуса напрямую влияет на рекомендацию. Security — одна из немногих B2C-категорий, где AI-поиск уже вытесняет SEO как основной канал привлечения, и эти бренды двинулись первыми. Мы ожидаем, что остальной сектор security последует в течение 12 месяцев.
Некоторые крупные новостные бренды находятся в этом списке, а не в списке блокировок. The Verge, The Atlantic, Vox, The Sun, NBA.com. Это не противоречие: похоже, эти издатели решили, что быть цитируемыми внутри поиска ChatGPT ценнее, чем быть защищенными от обучения, и написали явный Allow, чтобы защититься от будущей чрезмерной блокировки со стороны CDN или CMS. Сравните это с позицией NYT / Reuters / BBC / Forbes / Guardian, которые пишут явный Disallow. Оба подхода разумны; новостная индустрия не монолитна.
Присутствие The Sun особенно важно, потому что этот же сайт в другом месте файла использует deny-all User-agent: *. Лучшее чтение политики The Sun такое: «AI-training запрещен, AI-search разрешен, а GPTBot мы отдельно внесли в исключения из deny-all, чтобы ChatGPT мог отвечать на вопросы, ссылаясь на The Sun». Это самый юридически изощренный из правил с Allow для GPTBot — здесь есть и отказ, и точечный opt-in от одного вендора.
Присутствие WordPress.org — самое значимое отдельное упоминание в списке. Существенная часть глобальной open-source CMS-экосистемы либо ссылается на WordPress.org за документацией, либо хостит оттуда плагины. Явно разрешив GPTBot в wordpress.org/robots.txt, WordPress Foundation фактически сказала, что экосистема документации WordPress открыта для обучения — и это имеет побочные эффекты для того, насколько хорошо Claude, Gemini и ChatGPT могут отвечать на вопросы «как мне...?» про WordPress.
Оставшиеся 83 сайта в полном списке Allow-GPTBot — это длинный хвост региональных новостей, небольших security-вендоров, классифайдов на неанглоязычных рынках и B2B SaaS. Насколько мы можем судить, никакой отраслевой координации вида «Allow-GPTBot» нет — правило появляется по одному сайту за раз, у операторов, которые решили, что быть в корпусе — стратегическая позиция.
Вывод 12 — llms.txt на этом масштабе почти не существует
llms.txt, предлагаемый альтернативный формат файла для обнаружения контента, удобного для LLM (его продвигают Mintlify, Anthropic, Vercel и несколько dev-tooling-вендоров с конца 2024 года), почти нигде в нашей выборке не встречается.
Из 6 638 сайтов, вернувших разбираемый robots.txt, лишь 83 (1,15%) упоминают llms.txt — обычно в виде строки Sitemap: https://example.com/llms.txt. Это на два порядка ниже, чем тот же показатель на коммерческих выборках, насыщенных dev tooling, где дефолты Vercel и Mintlify искусственно завышают adoption.
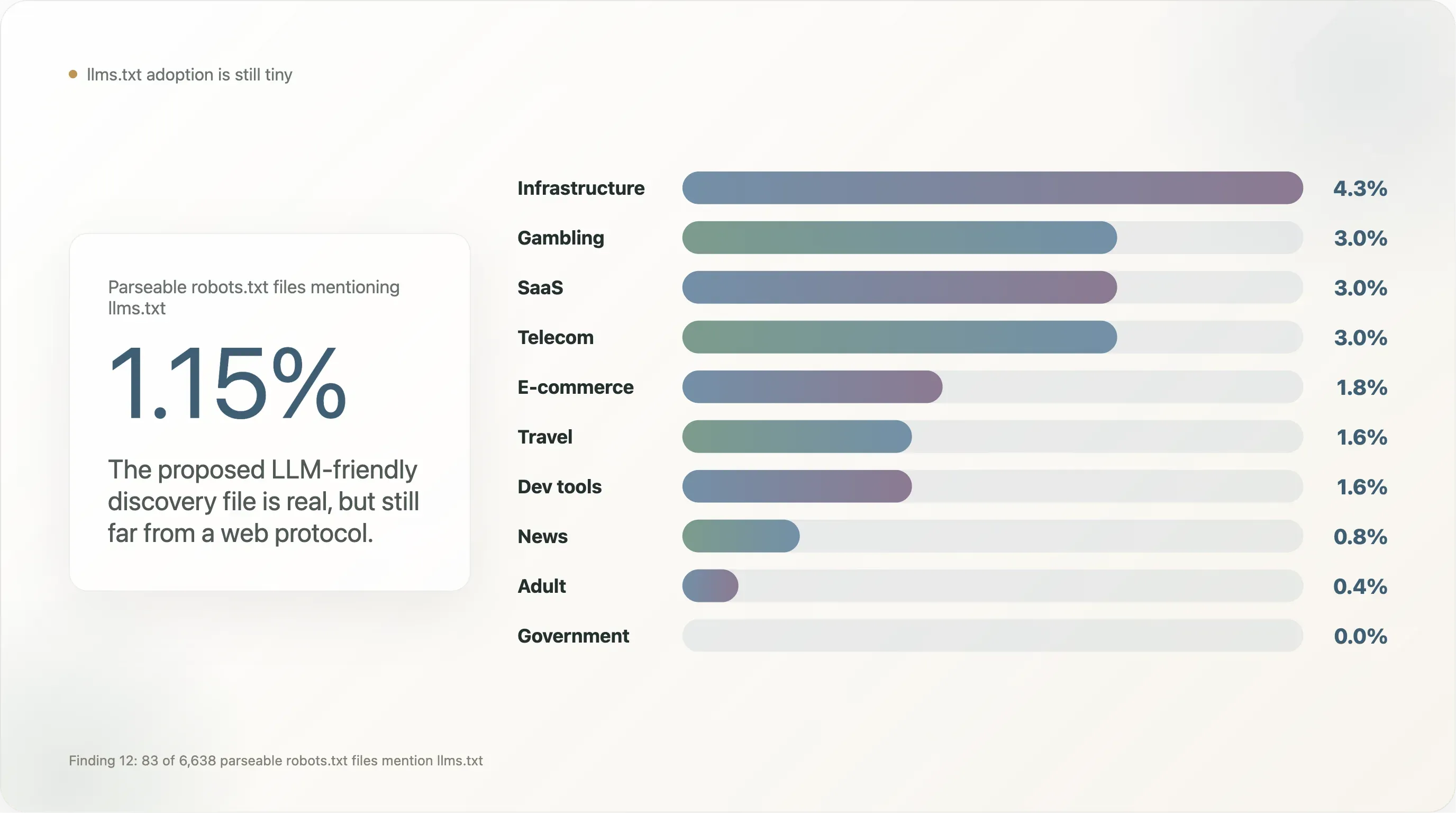
Разбивка по категориям:
| Отрасль | n | % упоминаний llms.txt |
|---|---|---|
| Инфраструктура | 47 | 4,3% |
| Азартные игры | 100 | 3,0% |
| SaaS | 369 | 3,0% |
| Телеком | 33 | 3,0% |
| E-commerce | 224 | 1,8% |
| Путешествия | 64 | 1,6% |
| Dev tools | 129 | 1,6% |
| Новости | 650 | 0,8% |
| Adult | 254 | 0,4% |
| Государственные сайты | 172 | 0,0% |
| Академия | 268 | 0,0% |
| Поиск | 12 | 0,0% |
llms.txt концентрируется в близком к dev-tooling SaaS, азартных играх (эта отрасль быстрее других регулируемых отраслей внедряет новые словарные возможности robots.txt, потому что у нее есть compliance-команды, привыкшие накладывать дополнительные метаданные) и B2B e-commerce. Его заметно нет в новостях и на госресурсах — двух сегментах, наиболее вовлеченных в AI-политику и необходимых, чтобы стандарт вырос из «эксперимента вендора» до «веб-протокола». Пока что llms.txt реален, но мал, и повторный аудит в конце 2026 года будет полезной проверкой.
Структурная проблема llms.txt в том, что он не стандартизован никаким процессом IETF, и крупные AI-вендоры не обещали его поддерживать. У правила robots.txt за плечами 30 лет инфраструктуры краулеров; у llms.txt этого нет. Пока хотя бы один крупный вендор (OpenAI, Anthropic, Google, Cloudflare) не заявит формальную поддержку, файл остается по сути маркетинговым артефактом экосистемы Mintlify / Vercel. В 2026 году мы не ожидаем, что это изменится.
Вывод 13 — Доступность: robots.txt по-прежнему читается на двух третях топового веба
Побочное наблюдение, которое и не должно было стать выводом: 66% сайтов из топ-10 000 вернули разбираемый robots.txt на один исследовательский IP, и только 7 из 10 000 (0,07%) ответили 429 Too Many Requests. Для robots.txt как публичного протокола это хорошая новость.
Для сравнения: тот же пайплайн, запущенный два месяца ранее на выборке из 1 008 доменов коммерческого mid-market, получил 429 от 52% разрешенных доменов — Shopify и Cloudflare CDNs жестко ограничивали частоту для любого UA, не принадлежащего крупным поисковикам. Топовый веб гораздо дружелюбнее: крупные сайты либо (а) используют менее агрессивные уровни bot-management, либо (б) имеют явные allowlist для известных исследовательских краулеров, либо и то и другое.
21% fetch_failed на top-10k в основном приходится на apex-домены CDN (akamai.net, cloudfront.net, fastly.net, apple-dns.net, gtld-servers.net), которые не обслуживают веб-сервер на /. Они нас не блокируют; им нечего отдавать. Если их исключить, реальная доля сбоев вида «пытались прочитать, но не смогли» — в пределах низких однозначных процентов.
Это означает, что будущие версии этого отчета — квартальные срезы, сравнения год к году — можно будет дешево и воспроизводимо запускать на одной машине. Окно аудита остается открытым на верхушке кривой. Асимметричный случай — длинный хвост и коммерческий сегмент, где CDN-level throttling уже фактически приватизировал robots.txt. Мы ожидаем, что это расхождение будет расти: top sites останутся читаемыми, потому что их индексируют поисковики, которым читаемость нужна; коммерческий длинный хвост станет менее читаемым по мере того, как Cloudflare агрессивнее выкатывает уровни bot-fight. Публичная аудируемость robots.txt расходится по той же линии, что разделяет «видимый веб» и «операционно защищенный веб».
IV. Что все это значит
Четыре утверждения — по убыванию силы поддержки данными.
1. У интернета нет одной глобальной AI-политики; она зависит от отрасли. Разброс в 12 раз между новостями и телекомом доминирует над всеми агрегатными цифрами. Сообщать «X% веба блокирует AI» без отраслевого разреза — значит завышать SaaS / гос / dev и занижать новости / travel / social. Честное описание возможно только по секторам.
2. Статья 4 Директивы ЕС об авторском праве — единственный правовой режим, который заметно двигает цифры. Сайты на ccTLD ЕС блокируют AI на уровне 35% против глобальной базы 19%. Судебные процессы в США (NYT против OpenAI, отчет Copyright Office за январь 2025 года) изменили новостной сегмент США, но не весь американский веб. ЕС-рамка также просачивается глобально через шаблон Cloudflare, который в boilerplate ссылается на Directive 2019/790 независимо от юрисдикции клиента.
3. Формируются две параллельные «AI-политики», и они не совпадают. Осознанная, написанная вручную политика (17,8%, в основном новости / social / travel / e-commerce) и унаследованная политика Cloudflare Managed (4,5%) пересекаются по сути, но расходятся по легитимности. В мире, где AI-операторы ищут юридическую опору, чтобы игнорировать robots.txt, защита в духе «мы это написали и проверили» структурно сильнее, чем «я просто включил переключатель». Стимул судебных споров — перевести политику из второй категории в первую.
4. Издатели блокируют корпус, а не модель. CCBot на уровне 16,3% — выше, чем любой бот с брендом модели, — это самое ясное свидетельство. Запрет OpenAI не освобождает издателя от обучения на его данных; запрет CCBot — освобождает. 14,1% топ-10k веба блокируют CCBot, но оставляют Googlebot приветствуемым. Паттерн «блокировать обучение, сохранять поиск» — модальная AI-правила 2026 года.
Для сайтов, которые думают о своей позиции: медианная позиция — молчание: 80% top-10k вообще ничего не говорят об AI. Те 17%, что пишут правила, в основном тяготеют к Disallow, но небольшой и растущий кластер (список с явным Allow для GPTBot на 1,5%, во главе с security-вендорами) публично выбирает противоположный вариант. Отраслевого консенсуса нет и в ближайшие 12 месяцев не будет.
Для AI-операторов: все труднее утверждать, что robots.txt — это устаревший протокол с неясной семантикой, когда 17% крупнейших сайтов мира написали явные осознанные правила с ручным указанием ботов и 3,8% файлов ссылаются на конкретную норму ЕС по номеру статьи. Игнорировать ли эти правила — бизнес-решение; существуют ли они — теперь эмпирический факт.
V. Прогноз: чего мы ожидаем к концу 2026 года
Три траектории, уже видимые в датасете:
Cloudflare Managed более чем удвоит свою долю, вероятно достигнув 10%+ от разбираемого top-10k. В дорожной карте Cloudflare публично обсуждается включение Block AI Bots по умолчанию для новых аккаунтов. Если переключатель выйдет с дефолтом on, глобальная доля блокировок сдвинется на 5–8 процентных пунктов без какого-либо решения со стороны издателей. Мы поймем, что это происходит, когда доля Cloudflare Managed в пакете 5001–10000 поднимется выше текущих 5,7%.
Секционно-уровневые AI-политики в стиле Spiegel будут распространяться среди крупных новостных флагманов. Экономическая логика — разрешить AI цитировать контент с низким риском, защитить контент-моат — достаточно убедительна, и мы ожидаем, что к концу 2026 года еще как минимум 10 крупных редакций выпустят правила по секциям. Сначала смотрите на немецкую и французскую прессу среднего уровня; правовая рамка там поощряет эксперименты.
Кластер явного Allow для GPTBot вырастет, прежде всего за счет B2B SaaS и dev tooling. Когда AI-поиск станет измеримым каналом привлечения для софтверных вендоров (как это уже произошло в security), следующий CMO напишет User-agent: GPTBot \n Allow: /, чтобы защититься от случайной чрезмерной блокировки. Мы ожидаем, что список из 108 сайтов примерно удвоится к концу года.
Чего мы не ожидаем: заметного изменения доли молчаливого большинства. Те 80% веба, которые ничего не говорят об AI, включают отрасли (gov, telecom, infrastructure, B2B SaaS), у которых нет экономических причин писать правило и нет юридического давления для этого. Универсальная AI-политика не появится.
VI. Ограничения
- Смещение одного снимка. Получение данных заняло 36 часов в начале мая 2026 года. На top-100 файл меняется ежедневно; на главных цифрах ожидайте дрейф 1–2 процентных пункта в квартал.
- Пробелы в отраслевой классификации. 6 593 из 10 000 сайтов остались
unknownпосле четырехуровневого классификатора. Проценты по отраслям надежны там, где n велико (news: 650, streaming: 440, saas: 369, academia: 268, adult: 254, ecommerce: 224, gov: 172, finance: 129, dev: 129), и шумнее при n<30. Страновой срез новостей ограничен аналогично — DE/FR/UK имеют n≥15, а Korea/Sweden/Czechia держатся на n=20–25. robots.txtдоброволен.Disallow— это просьба, а не барьер.Bytespider,PerplexityBotи другие, как документировалось, иногда игнорируют правила. Мы измеряли декларации политики, а не ее исполнение.- Аудит с одного IP в США. Мы не смогли прочитать 21% разрешенных доменов. Большинство — apex-точки CDN, у которых нет веб-сервера; часть — сайты, которые CDN отфильтровал раньше, чем мы дошли до origin. Это слегка смещает выборку в сторону более старой инфраструктуры и против сайтов, геофенсинг которых завязан на страну происхождения.
- Семантика списка Tranco. Tranco фильтрует по стабильности; это не истинный рейтинг пользовательского поведения. Агрегированные цифры устойчивы к выбору списка; конкретные места в ранге — нет.
- Нет данных о трафике. Мы измеряли политику
robots.txt, а не фактический объем трафика AI-ботов. Политика и трафик не всегда совпадают.
VII. Как воспроизвести
Все, что использовалось для подготовки этого отчета, лежит в папке с результатами.
- tranco_top10k.csv — входной список
- out/sites.csv — домен × ранг × отрасль × язык × статус robots.txt (10 000 строк)
- out/fetch_meta.csv — результат получения по каждому домену (статус, схема, байты, ошибка)
- out/bot_status.csv — матрица домен × бот (250 000 строк: blocked, has_rule, fetch_status)
- out/site_meta.csv — одна аналитическая запись на сайт (шаблон, сводные булевы показатели)
- out/analysis.json — все метрики, процитированные в отчете
- 01_fetch_robots.py, 02_classify.py, 03_parse_and_analyze.py — полный Python-пайплайн
Замечания по методологии, проблемы с датасетом и предложения по дальнейшему анализу можно отправлять на support@thunderbit.com. Этот отчет опубликован независимо от какой-либо коммерческой позиции Thunderbit; мы делаем AI-powered web scraper и заинтересованы в том, чтобы robots.txt оставался значимым машиночитаемым контрактом в публичном вебе. Данные в этом отчете говорят сами за себя. — Исследовательская команда Thunderbit, май 2026.