Wikipedia Search Result Scraper
Vrei să extragi date în masă? Încearcă Thunderbit gratuit.








Collect Wikipedia Search Results Fast
How to Extract Wikipedia Results Using Thunderbit



Learn how to extract structured data from Wikipedia search results
Collect Topic Data from Wikipedia Search Pages

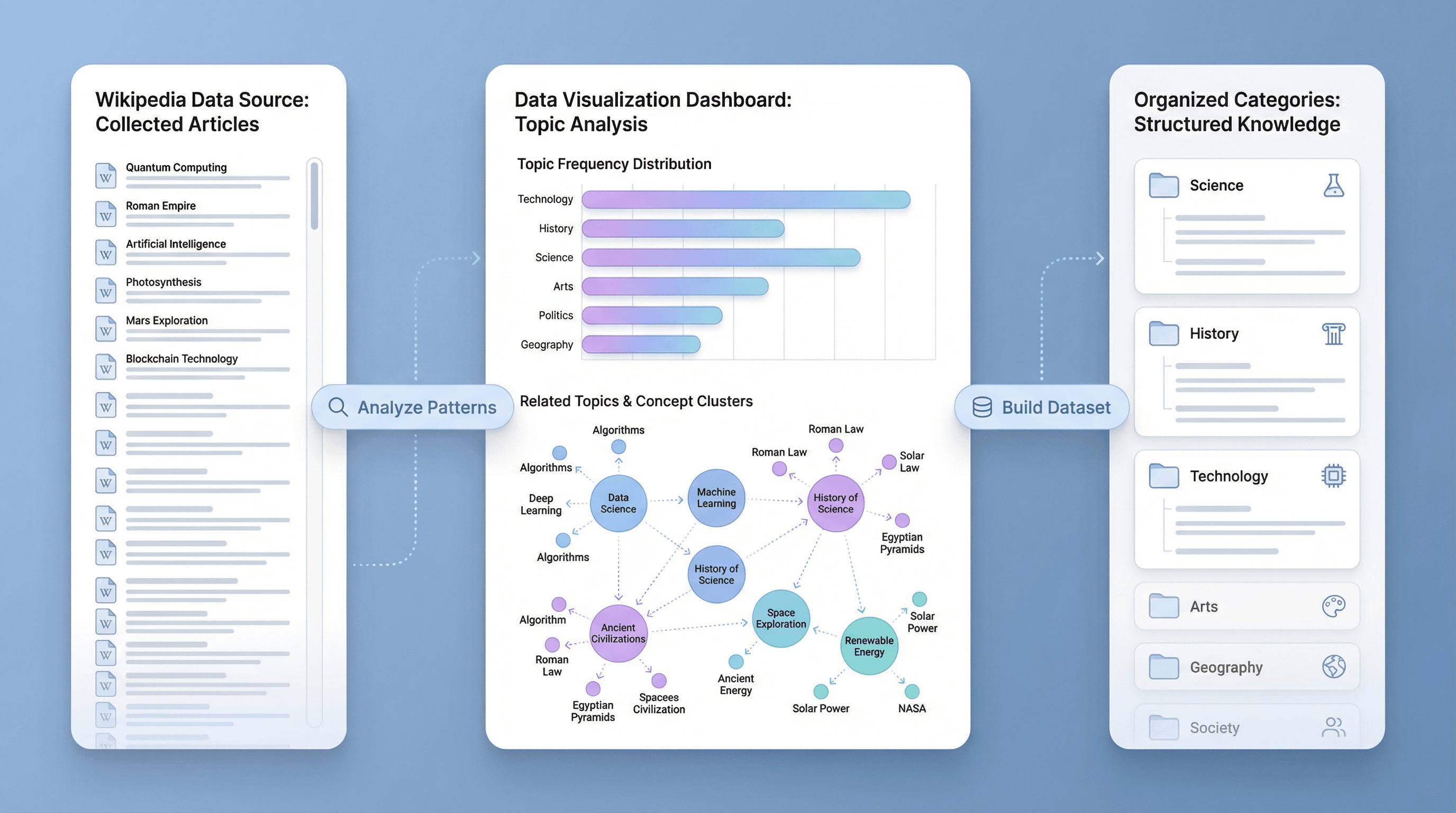
Analyze and Organize Large Sets of Wikipedia Results
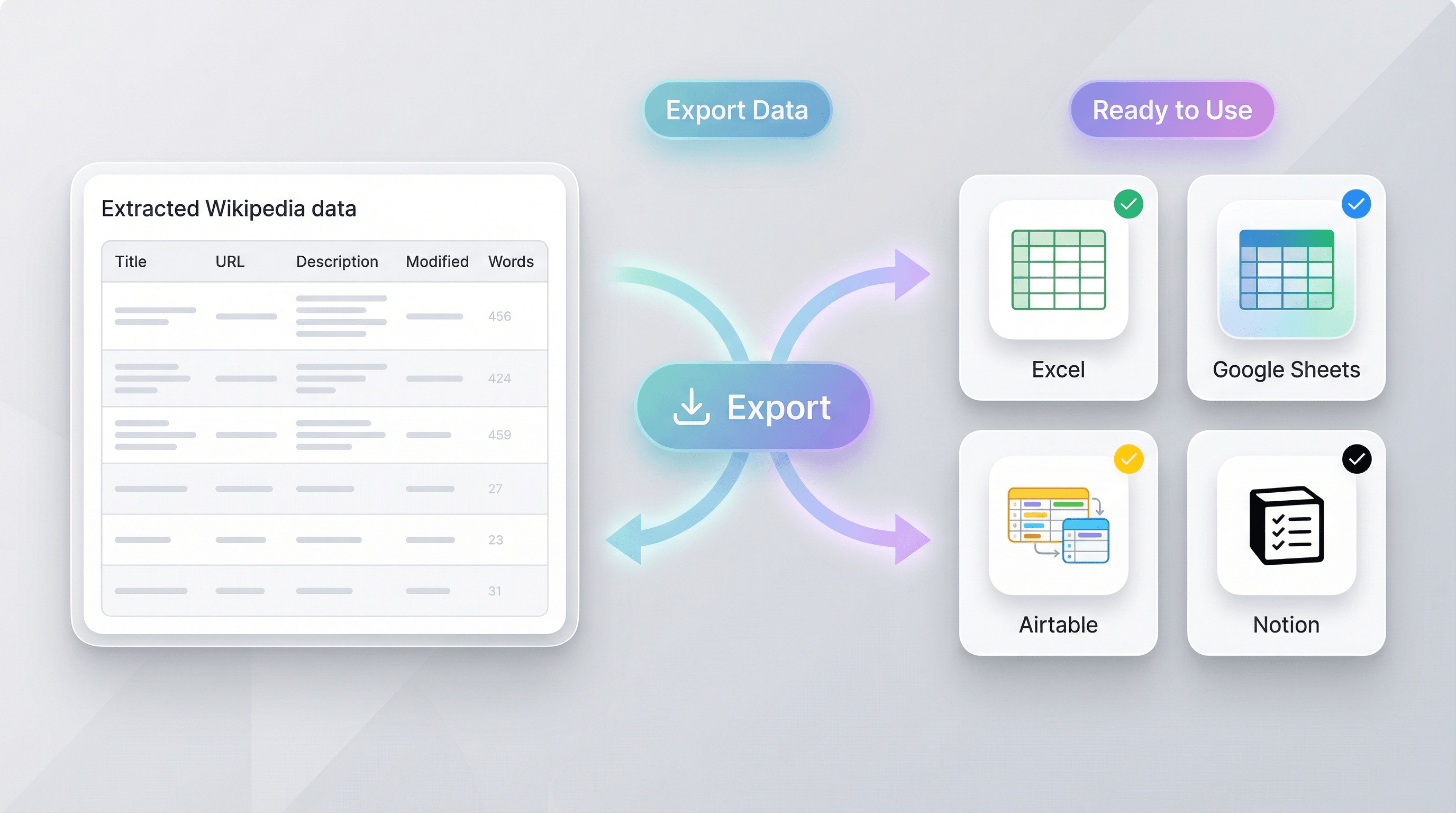
Export Wikipedia Data to Spreadsheets and Databases
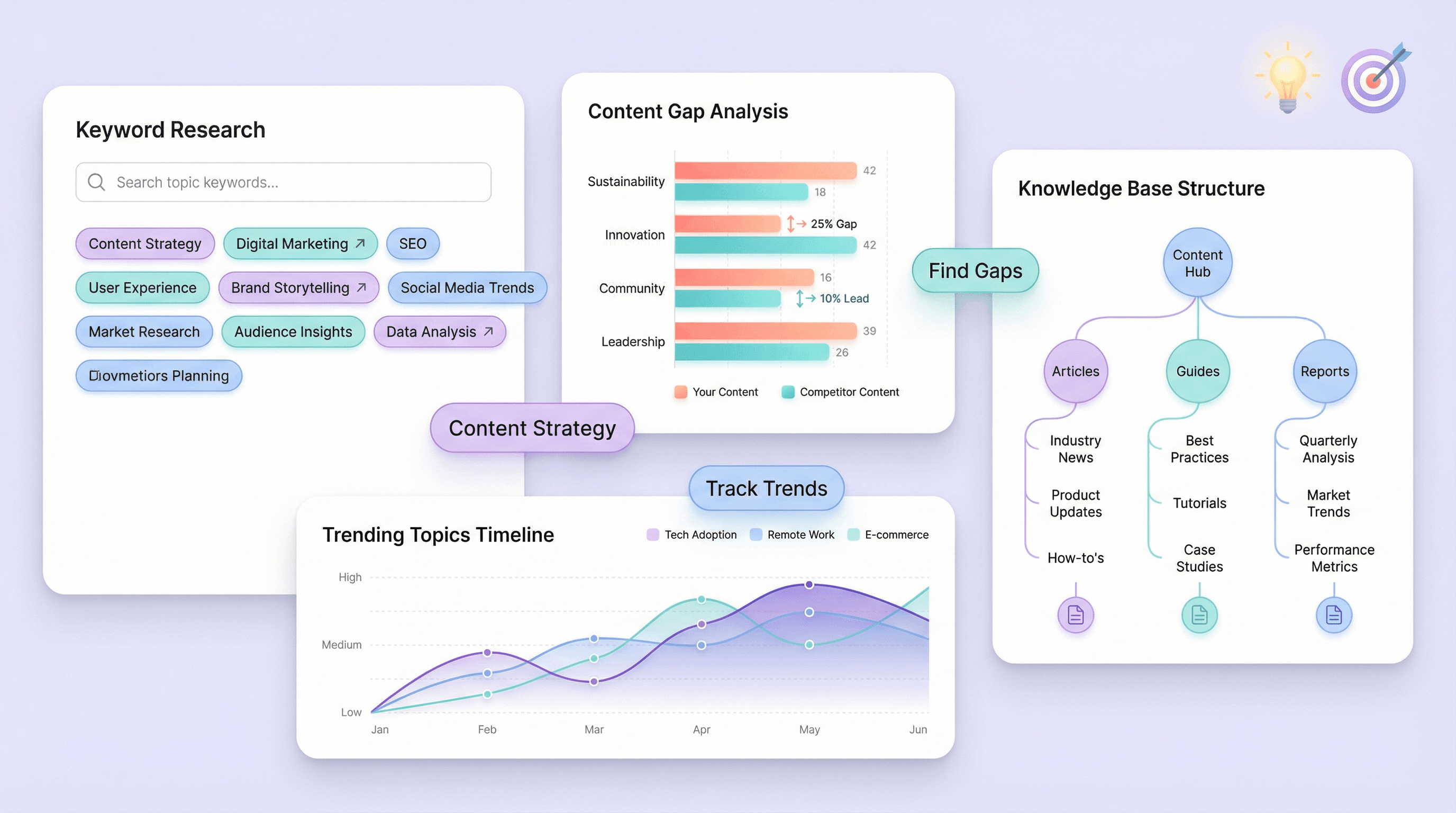
Support Content Strategy and SEO Research
Descoperă mai multe instrumente gratuite
Extrage e-mailuri din text online
Lipește orice text și extrage adresele de e-mail valide într-o listă ordonată. Economisește timp la curățarea notițelor, mesajelor și documentelor.
Extragere imagini de pe un site web
Extrage instant toate imaginile din orice pagină web și descarcă-le imediat. Complet gratuit, rapid și foarte ușor de exportat.
List crawler
Extrage elemente din liste ordonate și neordonate de pe orice URL de pagină web. Revizuiește listele grupate în text simplu pentru a surprinde rapid punctele-cheie.
Google Scholar scraper
Extrage rezultate academice dintr-o pagină Google Scholar și exportă titluri de lucrări, citări, autori și detalii de publicare în CSV pentru o cercetare mai rapidă.
G2 Software Product Scraper
Extract structured insights from any G2 software page, including ratings, reviews, and product details, to streamline competitor analysis and market research.
Extractor de URL-uri și descărcător în serie
Extrage toate linkurile unui site de pe orice pagină și descarcă-le ca CSV. Colectează rapid URL-uri pentru cercetare, analiză sau sarcini de colectare a datelor.
Extractor de sitemap
Parcurge o adresă URL de sitemap XML și listează fiecare link de pagină într-un tabel curat. Auditează rapid structura site-ului și găsește URL-uri lipsă sau neașteptate pentru SEO și QA.
Text Extractor
Extracts text from images and lets you download the results. Quickly convert scanned documents or pictures into editable text for easy use.
Amazon Products Scraper
Extrage informații despre produse din Amazon lipind URL-urile produselor. Obține titluri, prețuri, evaluări și multe altele într-un tabel structurat, gata pentru export rapid și analiză.
AI Sales Email Generator
Create personalized sales emails in seconds with the free AI Sales Email Generator. Perfect for sales teams and entrepreneurs. Try it now and boost your outreach with Thunderbit’s suite of AI tools.
Extractor și verificator de emailuri
Găsește și extrage adrese de email cu Email Extractor din pagini web, PDF-uri sau text. Rapid, precis și gata de export oricând.
Generator de subiecte pentru emailuri cu AI
Generează rapid subiecte convingătoare pentru emailuri, pornind de la o scurtă descriere. Crește rata de deschidere cu sugestii generate de AI. Rapid, simplu și fără înregistrare.
Extractor de numere de telefon
Scanează rapid pagini web, fișiere sau text pentru a găsi numere de telefon. Obține în câteva secunde o listă curată, exportabilă — ideală pentru construirea listelor de contacte sau verificarea datelor.
Convertor imagine în Excel
Transformă imaginile cu tabele, chitanțe sau liste în array-uri JSON structurate, ușor de exportat în Excel. Economisește timp la introducerea manuală a datelor și asigură acuratețea.
Tester pentru linia de subiect a emailului
Evaluează o linie de subiect după lungime, claritate, urgență, personalizare și risc de spam. Primește sfaturi concrete pentru a crește rata de deschidere.