Xiaohongshu scraper

De încredere pentru profesioniști din companii de top














Deblochează datele Xiaohongshu în două clicuri
Extragere de date fără efort, în două clicuri
Obosit de cod complicat și configurare interminabilă doar ca să obții date Xiaohongshu? Thunderbit îți permite să extragi câmpuri esențiale precum note_id, author_id, author_nickname, note_title, note_content și like_count fără să scrii nici măcar o linie de cod. Doar indică datele de care ai nevoie, iar Thunderbit detectează automat câmpurile și le extrage cu un clic.
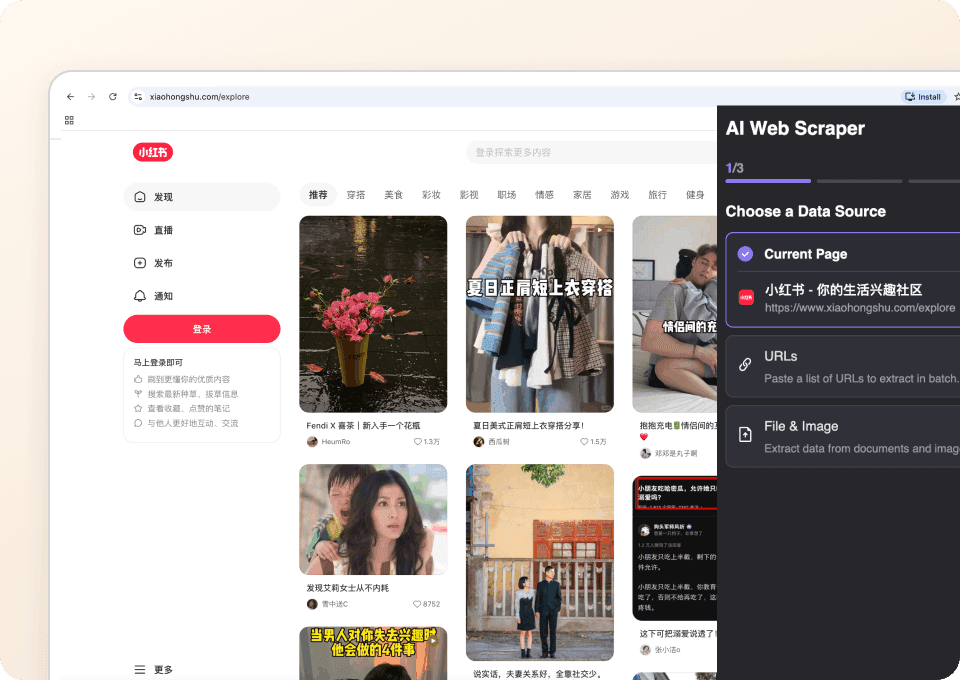
Obține imaginea completă, automat
Paginile de listare Xiaohongshu oferă doar o privire de ansamblu. Cu Thunderbit, poți vizita automat subpagina fiecărei notițe pentru a extrage direct informații detaliate. Descoperă insight-uri ascunse și obține imaginea completă prin extragerea fiecărui detaliu relevant, toate adăugate ca noi coloane în destinația aleasă.
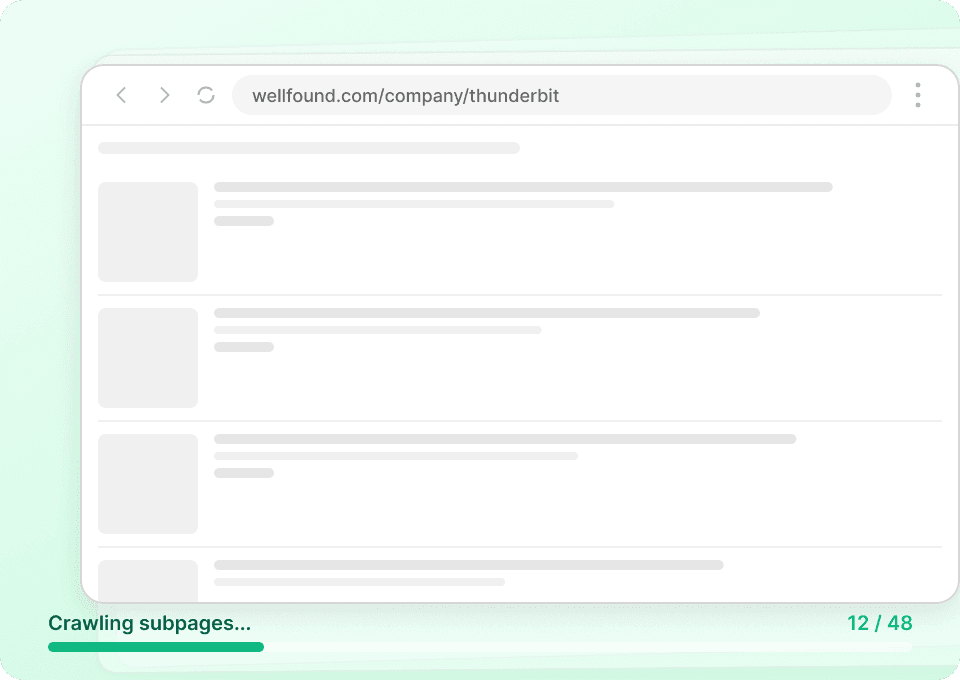
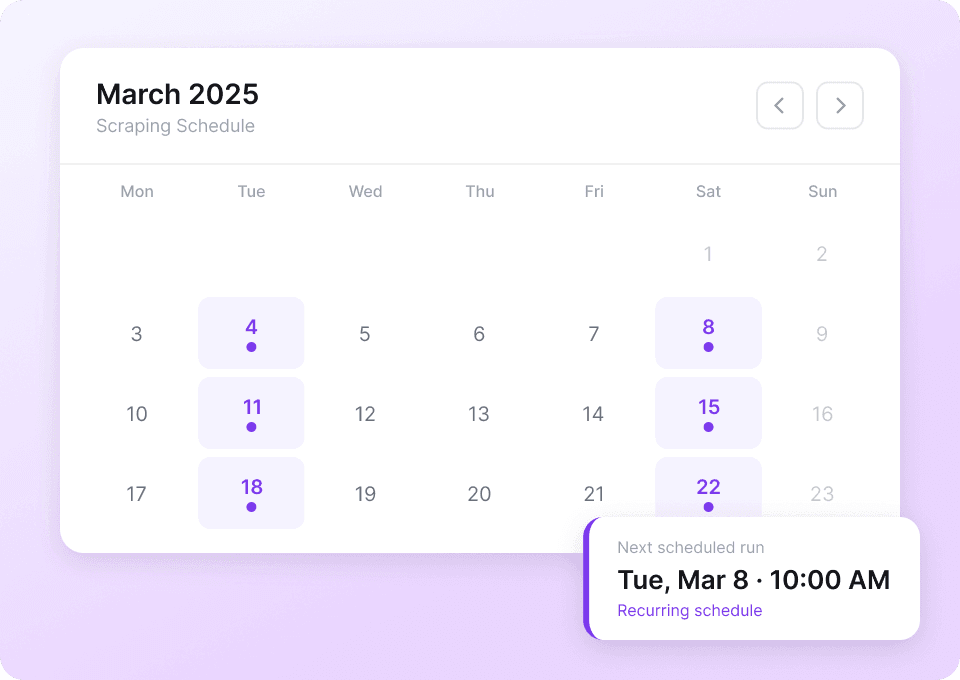
Automatizează monitorizarea datelor Xiaohongshu
Datele Xiaohongshu se schimbă constant. Extragerea manuală în fiecare zi e o corvoadă. Extragerea programată din Thunderbit îți permite să configurezi sarcini recurente pentru a extrage automat date precum like_count pe pilot automat. Primești insight-uri proaspete direct în Google Sheets, Notion sau Airtable, fără să ridici un deget.
Te chinui să extragi eficient date din Xiaohongshu?
Vezi de ce Thunderbit este metoda mai inteligentă de a extrage date din Xiaohongshu.
Traditional Scrapers
The old way of doing thingsThunderbit AI
The smarter approachNu ne crede doar pe cuvânt
Vezi ce spun utilizatorii noștri despre Thunderbit.






Întrebări frecvente
Similare cazuri de utilizare
Explorează mai multe cazuri de utilizare pentru scraperul web Thunderbit.

UNIQLO Scraper
Extrage date despre produsele Uniqlo, precum numele, prețurile și mărimile disponibile, cu doar 2 clicuri, datorită extensiei Chrome Thunderbit.
Află mai multe ->
United Airlines Scraper
Selectează și colectează, cu un simplu click, date despre zborurile United Airlines — precum numărul zborului, ora sosirii și aeroportul de plecare — iar Thunderbit AI se ocupă de restul.
Află mai multe ->PeopleWhiz scraper
Thunderbit PeopleWhiz Scraper îți permite să extragi date din rezultatele căutărilor și din profilurile PeopleWhiz cu sugestii de câmpuri bazate pe AI. Colectează nume, date de contact, locații și multe altele pentru cercetare, marketing sau generare de lead-uri. Transformă rapid și eficient datele PeopleWhiz în seturi de date structurate.
Află mai multe ->Elgiganten Scraper
Obține numele produselor, prețurile și datele despre disponibilitate de pe Elgiganten în doar două clicuri — Thunderbit se ocupă de partea grea cu AI-ul său.
Află mai multe ->
Scraper Trustpilot
Transformă paginile Trustpilot într-un tabel clar cu recenzii, evaluări și numele recenzenților. Noi citim fiecare pagină pentru tine, așa că nu ai nevoie de cod sau copy-paste.
Află mai multe ->
Sports Direct Scraper
Extrage numele produselor, prețurile și procentele de reducere de pe Sports Direct cu AI-ul Thunderbit — fără configurări complicate și fără cod.
Află mai multe ->Ești gata să-ți accelerezi extragerea de date?
Alătură-te celor peste 100.000 de profesioniști care folosesc deja Thunderbit pentru a-și automatiza fluxurile de web scraping.
Perioada de probă gratuită oferă credite nelimitate pentru 8 pagini web.