Substack scraper

Ales de profesioniști din companii de top














Deblochează datele Substack cu Thunderbit
Trimite datele Substack direct în aplicațiile tale
Nu mai copia și lipi manual detalii despre publicațiile Substack, precum numele autorului, titlul articolului și numărul de abonați. Cu Thunderbit, un singur clic trimite datele extrase direct în Google Sheets, Notion sau Airtable. Analizează tendințele publicațiilor și performanța conținutului fără munca manuală plictisitoare.
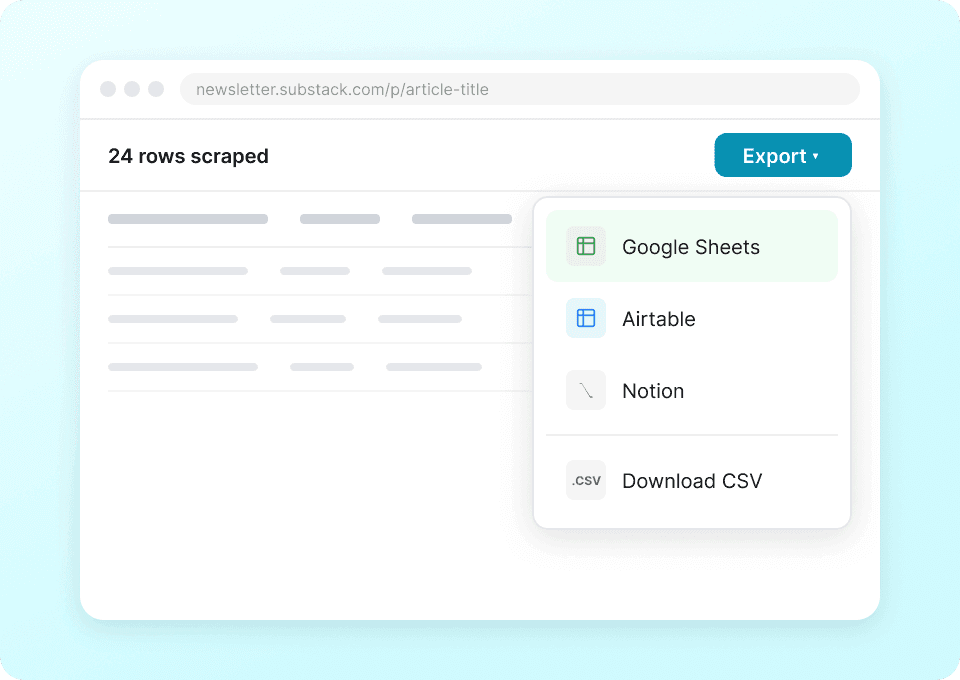
Un singur scraper pentru Substack și nu numai
Nu te bloca folosind un scraper diferit pentru fiecare site. Thunderbit funcționează pe Substack imediat, iar în plus include peste 50 de template-uri predefinite pentru alte platforme populare. Extrage descrieri de publicații, conținut de articole și multe altele, apoi folosește același instrument pentru a colecta date de oriunde.
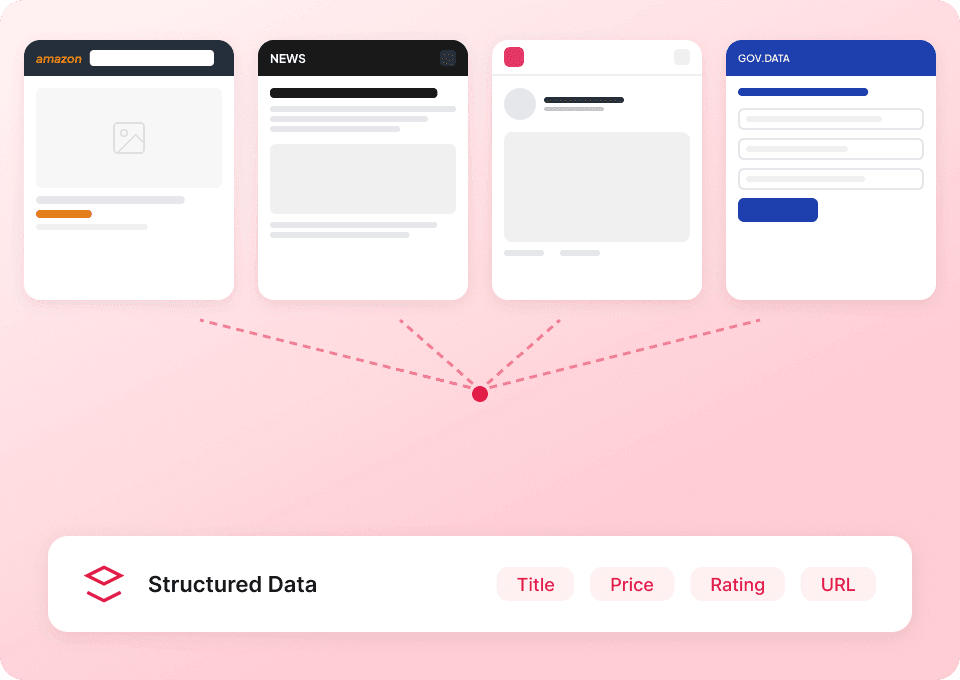
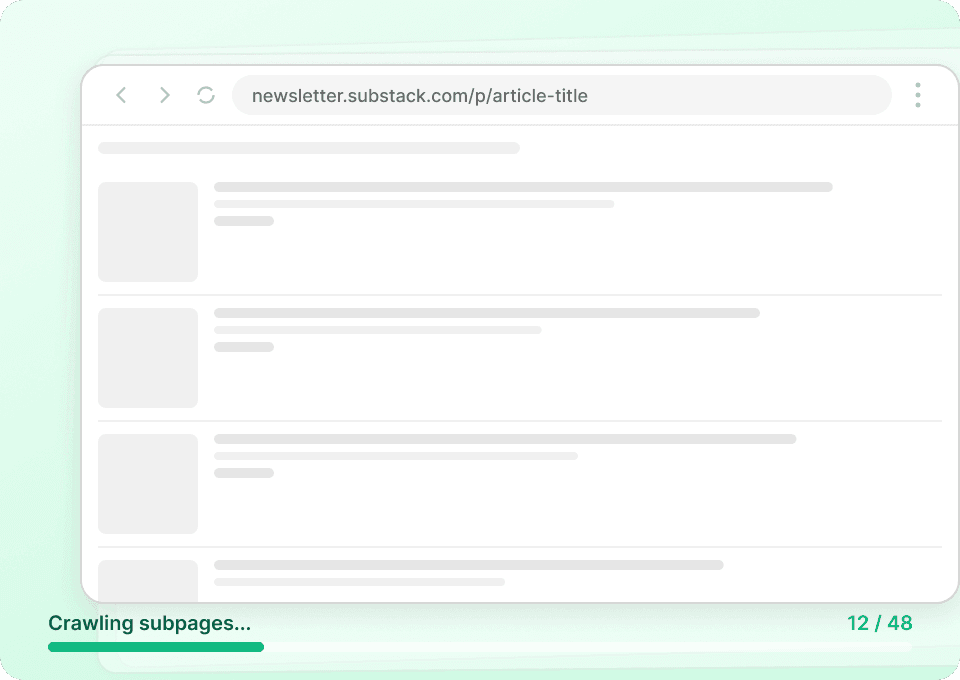
Obține povestea completă din Substack
Paginile de listare ale publicațiilor Substack afișează doar rezumate. Thunderbit vizitează automat fiecare subpagină de articol pentru a extrage conținutul complet, oferindu-ți un set de date complet. Obține dintr-un singur pas titlul întreg al articolului, numele autorului, numele publicației și conținutul articolului.
Îți este greu să extragi eficient date din Substack?
Vezi de ce Thunderbit depășește scraper-ele tradiționale pentru datele Substack.
Scraper-e tradiționale
Metoda clasicăThunderbit
Abordarea mai inteligentăNu ne crede doar pe cuvânt
Vezi ce spun utilizatorii noștri despre Thunderbit.





Întrebări frecvente
Asemănător cazuri de utilizare
Explorează mai multe cazuri de utilizare pentru scraperul web Thunderbit.
Elgiganten Scraper
Obține numele produselor, prețurile și datele despre disponibilitate de pe Elgiganten în doar două clicuri — Thunderbit se ocupă de partea grea cu AI-ul său.
Află mai multe ->
Sports Direct Scraper
Extrage numele produselor, prețurile și procentele de reducere de pe Sports Direct cu AI-ul Thunderbit — fără configurări complicate și fără cod.
Află mai multe ->
PubMed Scraper
PubMed Scraper de la Thunderbit te ajută să extragi, cu ajutorul AI, date structurate din rezultatele de căutare PubMed și din paginile articolelor. Poți colecta rapid cercetări medicale în trend, dovezi din studii clinice, rezumate, autori, afilieri, date de publicare și linkuri, apoi exporta totul în Excel, Google Sheets, Airtable sau Notion.
Află mai multe ->
UNIQLO Scraper
Extrage date despre produsele Uniqlo, precum numele, prețurile și mărimile disponibile, cu doar 2 clicuri, datorită extensiei Chrome Thunderbit.
Află mai multe ->
Extractor de numere de telefon Craigslist
Extractorul de numere de telefon Craigslist de la Thunderbit te ajută să obții numere de telefon și detalii despre anunțuri din rezultatele de căutare Craigslist cu ajutorul AI. Poți colecta anunțuri, iar apoi să deschizi automat fiecare postare (scraping pe subpagini) pentru a captura date de contact și câmpuri suplimentare, după care exporți în Excel, Google Sheets, Airtable, Notion, CSV sau JSON.
Află mai multe ->
HKTVmall Scraper
Colectează nume de produse, prețuri și chiar evaluările clienților din listările HKTVmall în doar câteva clicuri — fără configurări complicate.
Află mai multe ->Ești gata să-ți accelerezi extragerea datelor?
Alătură-te celor peste 100.000 de profesioniști care folosesc deja Thunderbit pentru a-și automatiza fluxurile de web scraping.
Proba gratuită oferă credite nelimitate pentru 8 pagini web.