

PubMed Scraper de la Thunderbit te ajută să transformi paginile PubMed în seturi de date curate și structurate, folosind AI. Poți extrage cercetări medicale în trend, dovezi din studii clinice, rezumate, autori, afilieri, date de publicare, PMID-uri și linkuri către articole, apoi exporta în Excel, Google Sheets, Airtable sau Notion. Tot ce ai de făcut este să deschizi PubMed în Chrome, să lași AI-ul să propună cele mai potrivite coloane și să rulezi extragerea.
🧬 Ce este PubMed Scraper
PubMed Scraper este un AI Web Scraper creat pentru . Cu (o extensie Chrome de tip AI web scraper), poți intra pe orice pagină de rezultate PubMed, apeși AI Suggest Columns, apoi Scrape și obții date structurate fără să scrii cod.
🔎 Ce poți extrage din PubMed
PubMed conține o mulțime de metadate biomedicale valoroase, însă nu sunt întotdeauna gata pentru analiză. AI Web Scraper de la Thunderbit (https://thunderbit.com/) te ajută să colectezi și să structurezi listele PubMed și să le îmbogățești cu detalii de la nivel de articol prin Subpage Scraping (deschide fiecare pagină de articol și adaugă câmpuri precum rezumatul, afilierile, DOI și altele).
Mai jos sunt două fluxuri de lucru frecvente, pe care le poți rula în câteva minute.
📈 Extragere din PubMed pentru monitorizarea cercetărilor medicale în trend
Folosește acest flux ca să urmărești ce este în trend în cercetarea medicală pe pagina de trending PubMed. Este util pentru a rămâne la curent, pentru a crea rezumate interne, pentru a urmări publicațiile competitorilor sau pentru a alimenta un pipeline de monitorizare a literaturii.
Exemplu de pagină:
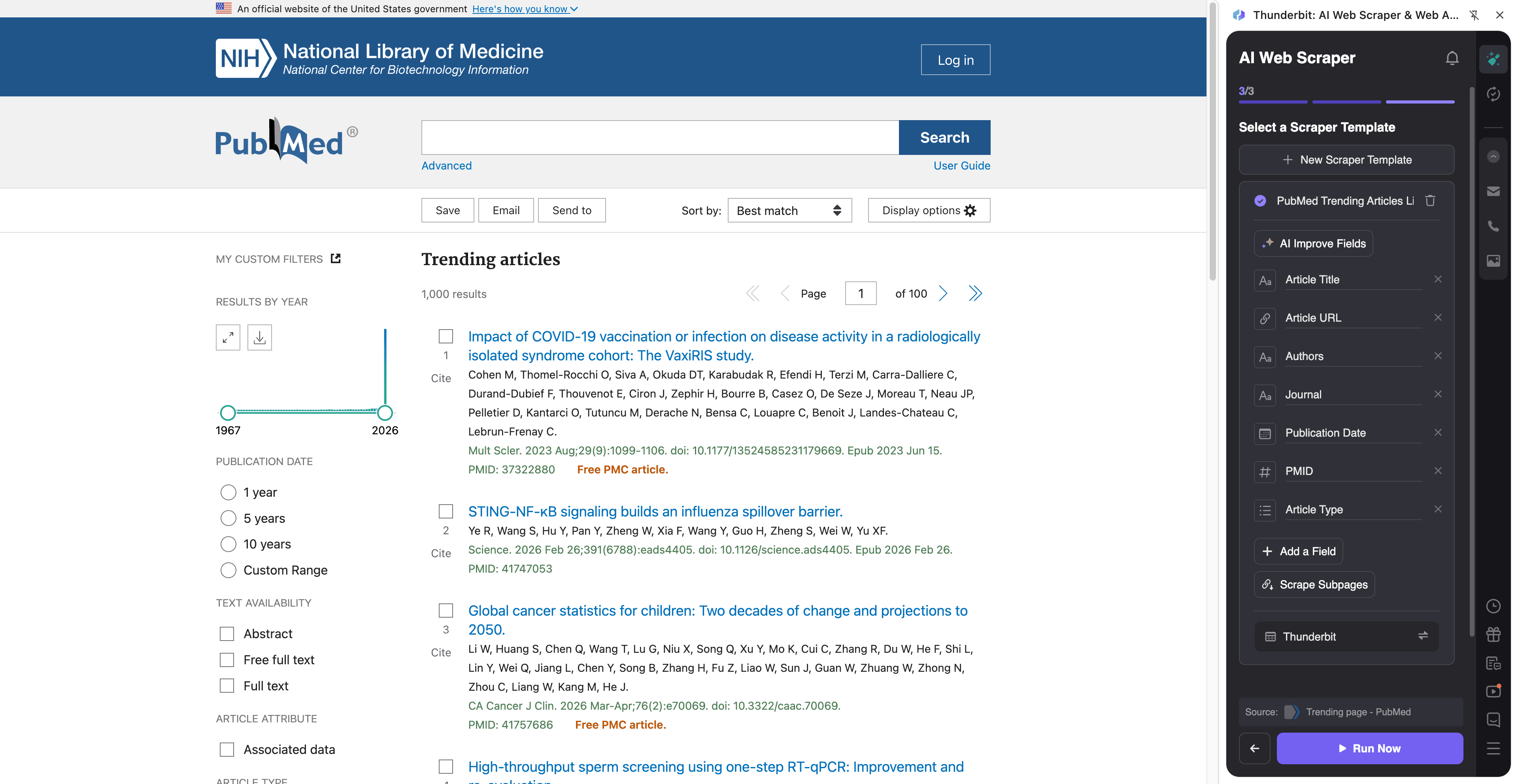
Pași:
- Instalează și creează un cont.
- Accesează pagina țintă, de exemplu: .
- Apasă AI Suggest Columns pentru ca AI-ul să recomande cele mai bune denumiri de coloane și tipuri de date.
- Apasă Scrape pentru a extrage datele, apoi exportă în Excel, Google Sheets, Airtable sau Notion.
Nume de coloane
| Coloană | Descriere |
|---|---|
| 🧾 Titlul articolului | Titlul articolului PubMed aflat în trend. |
| 🔗 URL articol | Link direct către pagina înregistrării PubMed. |
| 🆔 PMID | Identificatorul PubMed al înregistrării (util ca cheie stabilă). |
| 🏛️ Revistă | Numele revistei în care este publicat articolul. |
| 📅 Data publicării | Data publicării afișată în listare. |
| ✍️ Autori | Lista/șirul de autori afișat pe cardul rezultatului. |
| 🧪 Tipul articolului | Tipul publicației când este disponibil (ex.: Review, Clinical Trial). |
| 🏷️ Cuvinte-cheie / Subiecte | Etichete de subiect sau cuvinte-cheie vizibile în listare (dacă există). |
| 📝 Fragment / Rezumat scurt | Text scurt afișat în listare (dacă există). |
| 🧷 DOI | DOI când este disponibil (de obicei se capturează mai bine prin subpage scraping). |
| 🧑🔬 Afilieri | Afilierile autorilor (de regulă extrase prin subpage scraping). |
| 📄 Rezumat (Abstract) | Textul rezumatului (de regulă extras prin subpage scraping). |
🧫 Extragere din PubMed pentru dovezi din studii clinice
Folosește acest flux pentru a colecta dovezi legate de studii clinice din rezultatele de căutare PubMed, apoi îmbogățește fiecare rând vizitând pagina articolului ca să capturezi rezumatul, semnale specifice studiilor și metadatele necesare pentru evaluare.
Exemplu de pagină:
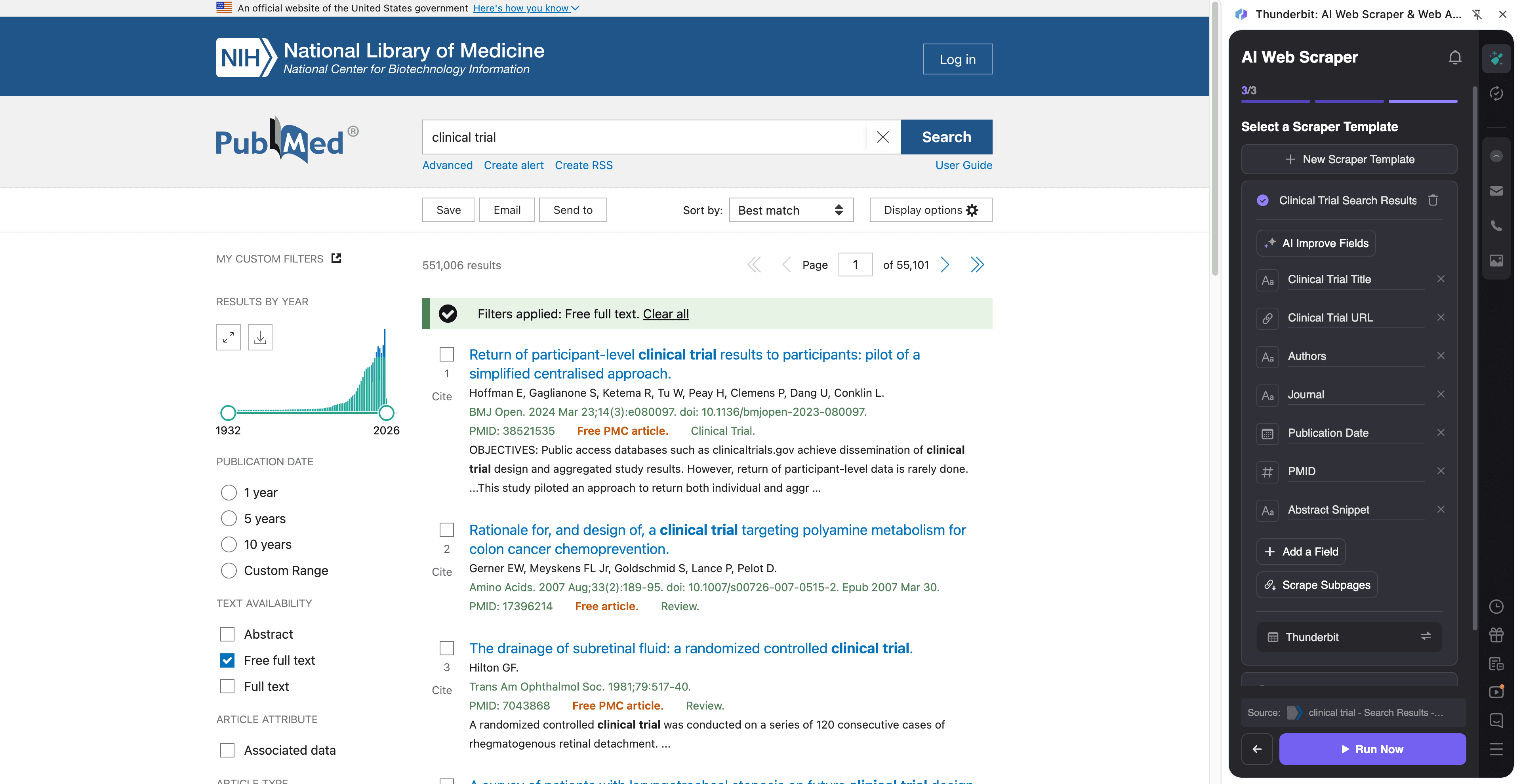
Pași:
- Instalează și creează un cont.
- Accesează pagina țintă, de exemplu: .
- Apasă AI Suggest Columns pentru a genera câmpuri recomandate (le poți redenumi sau poți adăuga altele).
- Apasă Scrape pentru a colecta rezultatele, apoi folosește Scrape Subpages ca să îmbogățești fiecare rând cu rezumat, afilieri, DOI și altele.
Nume de coloane
| Coloană | Descriere |
|---|---|
| 🧾 Titlu | Titlul articolului din rezultatele căutării. |
| 🔗 URL PubMed | Link către pagina articolului PubMed pentru îmbogățire prin subpage. |
| 🆔 PMID | Identificator PubMed pentru deduplicare și referințe. |
| 🧑⚕️ Autori | Autorii listați în fragmentul rezultatului. |
| 🏛️ Revistă | Numele revistei și informațiile de citare afișate în rezultate. |
| 📅 Dată | Data publicării (sau data ePub) afișată în listare. |
| 🧪 Tipul publicației | Indicii precum Clinical Trial, Randomized Controlled Trial, Meta-Analysis (adesea mai clar pe pagina articolului). |
| 🧾 Rezumat (Abstract) | Textul complet al rezumatului (cel mai bine prin subpage scraping). |
| 🧬 Termeni MeSH | Medical Subject Headings când sunt disponibili (adesea pe pagina articolului). |
| 🧷 DOI | DOI pentru legături către paginile editorilor și manageri de referințe. |
| 🏥 Afilieri | Afilierile autorilor pentru analiză instituțională (subpage scraping). |
| 🌍 Țară / Instituție | Derivat din afilieri folosind Field AI Prompts (opțional). |
| 🔍 Cuvinte-cheie pentru studii clinice | Etichete generate de AI precum „randomized”, „double-blind”, „placebo” (opțional prin Field AI Prompt). |
| 📎 Linkuri către text integral | Linkuri externe către editor sau către text integral gratuit, când există. |
🎯 De ce să folosești instrumentul PubMed
Extragerea din PubMed înseamnă viteză, consecvență și transformarea datelor de cercetare în informații ușor de folosit în fluxul tău de lucru. În loc să copiezi citări una câte una, poți construi un set de date structurat pe care îl filtrezi, etichetezi și îl distribui.
Motive frecvente pentru care echipele extrag date din PubMed:
- Echipe medical affairs & pharma: urmăresc publicații noi într-o arie terapeutică, monitorizează studiile competitorilor și construiesc tabele de dovezi pentru evaluări interne.
- Biotech & operațiuni clinice: colectează publicații legate de studii, cartografiază instituții și investigatori și mențin o bibliografie „vie”.
- Echipe de marketing în sănătate & content: identifică subiecte în trend, reviste cu impact ridicat și cuvinte-cheie emergente pentru planificarea conținutului.
- Cercetători academici & bibliotecari: creează seturi de date pentru review-uri de literatură, deduplicate după PMID și exportă în foi de calcul pentru screening.
- Echipe de date: generează intrări structurate pentru analize ulterioare, dashboard-uri sau baze interne de cunoștințe.
Thunderbit este deosebit de util când ai nevoie de mai mult decât pagina de listare. Cu Subpage Scraping, poți extrage la scară rezumate, afilieri, DOI, termeni MeSH și linkuri către text integral.
🧩 Cum folosești extensia Chrome pentru PubMed
- Instalează Thunderbit Chrome Extension: o găsești în și îți creezi contul.
- Intră pe o pagină PubMed: deschide , o pagină de trending precum sau o interogare precum .
- Activează scraperul cu AI: apasă AI Suggest Columns pentru a genera câmpuri, ajustează tipurile de date (text/datǎ/url) și adaugă opțional Field AI Prompts (pentru etichetare, formatare sau extragerea semnalelor de studiu).
- Extrage și exportă: apasă Scrape. Dacă ai nevoie de rezumate/afilieri/MeSH, rulează Scrape Subpages pentru a îmbogăți fiecare rând, apoi exportă în Excel, Google Sheets, Airtable sau Notion.
Lecturi utile dacă vrei un flux repetabil:
💳 Prețuri pentru PubMed
Thunderbit folosește un sistem simplu de credite:
- 1 credit = 1 rând de ieșire în tabelul de rezultate (de exemplu, o înregistrare PubMed).
- Exportul datelor este gratuit: descarci CSV/JSON sau trimiți în Excel, Google Sheets, Airtable ori Notion.
Poți începe cu:
- Plan gratuit: extragi 6 pagini pe lună (alocare pe pagini în planul Free).
- Trial gratuit: extragi 10 pagini gratuit, ideal pentru a testa pagini de trending și câteva pagini de rezultate pentru studii clinice.
Dacă extragi regulat (monitorizare săptămânală, actualizări de dovezi sau interogări mari), planurile plătite îți oferă mai multe credite. Planul anual este, de obicei, mai avantajos deoarece include o reducere față de plata lunară.
Poți vedea opțiunile pe .
❓ Întrebări frecvente
-
Ce este PubMed Scraper cu AI?
PubMed Scraper cu AI este un flux de lucru în Thunderbit care extrage date structurate din rezultatele de căutare PubMed și din paginile articolelor. Poți folosi AI pentru a propune coloane, a extrage listările și a îmbogăți fiecare rând vizitând subpaginile articolelor pentru rezumate, afilieri, DOI și altele. -
Ce este Thunderbit?
este o extensie Chrome de tip AI web scraper, gândită pentru fluxuri de lucru de business și cercetare în care ai nevoie de date structurate din site-uri. Te ajută să extragi, să etichetezi și să exporți date rapid, fără să construiești sau să întreții scripturi de scraping. -
Pot extrage atât paginile PubMed Trending, cât și rezultatele obișnuite de căutare?
Da. Poți extrage pagina , căutări standard după cuvinte-cheie și pagini filtrate (de exemplu, interogări axate pe studii clinice). AI-ul Thunderbit se adaptează la layout-uri diferite, citind pagina și propunând câmpuri relevante. -
Poate Thunderbit să extragă rezumate, afilieri și termeni MeSH?
Da, iar aici Subpage Scraping este cel mai util. Poți extrage mai întâi lista de rezultate, apoi Thunderbit deschide fiecare pagină de înregistrare PubMed pentru a colecta rezumatul, afilierile, termenii MeSH, DOI și alte metadate în același tabel. -
Cum funcționează paginarea și scroll-ul infinit pe PubMed?
Thunderbit suportă extragerea cu paginare, inclusiv navigarea de tip „next page”. Dacă PubMed schimbă modul de încărcare a rezultatelor, extragerea bazată pe AI este, în general, mai robustă decât selectoarele rigide, deoarece recitește structura paginii la fiecare rulare. -
În ce formate pot exporta datele din PubMed?
Poți exporta în CSV sau JSON, ori poți trimite setul de date în Excel, Google Sheets, Airtable sau Notion. Este util pentru screening, tabele de dovezi, dashboard-uri și partajare cu colaboratori. -
Câte înregistrări PubMed pot extrage gratuit?
În planul Free, poți extrage 6 pagini pe lună, de obicei suficient pentru sarcini mici de monitorizare. Cu trial-ul gratuit, poți extrage 10 pagini fără cost pentru a valida setarea coloanelor și strategia de îmbogățire prin subpagini. -
Pot personaliza coloanele pentru nevoi specifice de extragere a dovezilor?
Da. Poți redenumi coloane, seta tipuri de date (text/datǎ/url) și adăuga Field AI Prompts pentru a extrage sau eticheta informații precum cuvinte-cheie despre designul studiului, populație, intervenție, comparator, rezultate sau țara din afilieri. Astfel treci de la scraping brut la pregătirea structurată a dovezilor. -
Este în regulă să extragi date din PubMed?
PubMed este o resursă publică, iar multe echipe colectează metadate bibliografice pentru cercetare și analiză. Totuși, ar trebui să respecți legislația aplicabilă, termenii site-ului și bunele practici de scraping responsabil, mai ales dacă rulezi joburi mari și frecvente.
📚 Află mai multe
- Descarcă extensia:
- Explorează ghidurile din
- Bazele:
- Fluxuri pentru liste:
- Export în foi de calcul:
- Dacă extragi și PDF-uri în research ops: