News Scraper

Ales de profesioniști din companii de top














Date despre știri, capturate mai rapid
Extrage date curate din articole, listări și surse fără munca manuală obositoare.
Obține detaliile complete ale articolului
Paginile de listare a știrilor îți oferă doar un teaser. Thunderbit vizitează fiecare subpagină a articolului și recuperează tabloul complet, inclusiv titlul, rezumatul articolului, autorul, data publicării, sursa de știri și secțiunea. Asta înseamnă că poți trece de la o simplă listă de articole la un set de date complet în mai puțini pași.
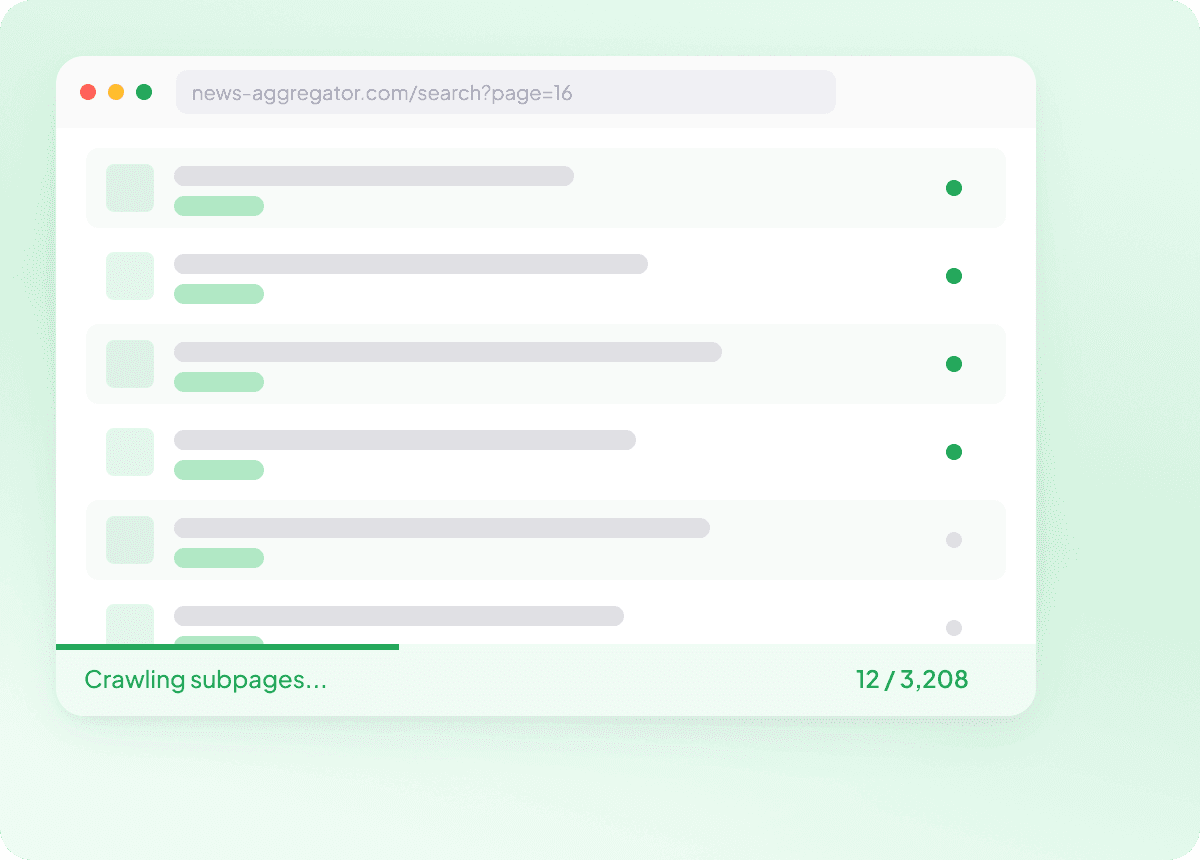
Extrage în masă liste de URL-uri News
Extragerea știrilor pagină cu pagină devine repede lentă. Cu Thunderbit, poți introduce o listă de URL-uri de articole și poți extrage în masă sute de pagini dintr-o singură dată, astfel încât fiecare articol să fie capturat cu câmpurile de care ai nevoie. Este o metodă practică de a colecta seturi mari de date despre știri fără să repeți aceeași muncă.

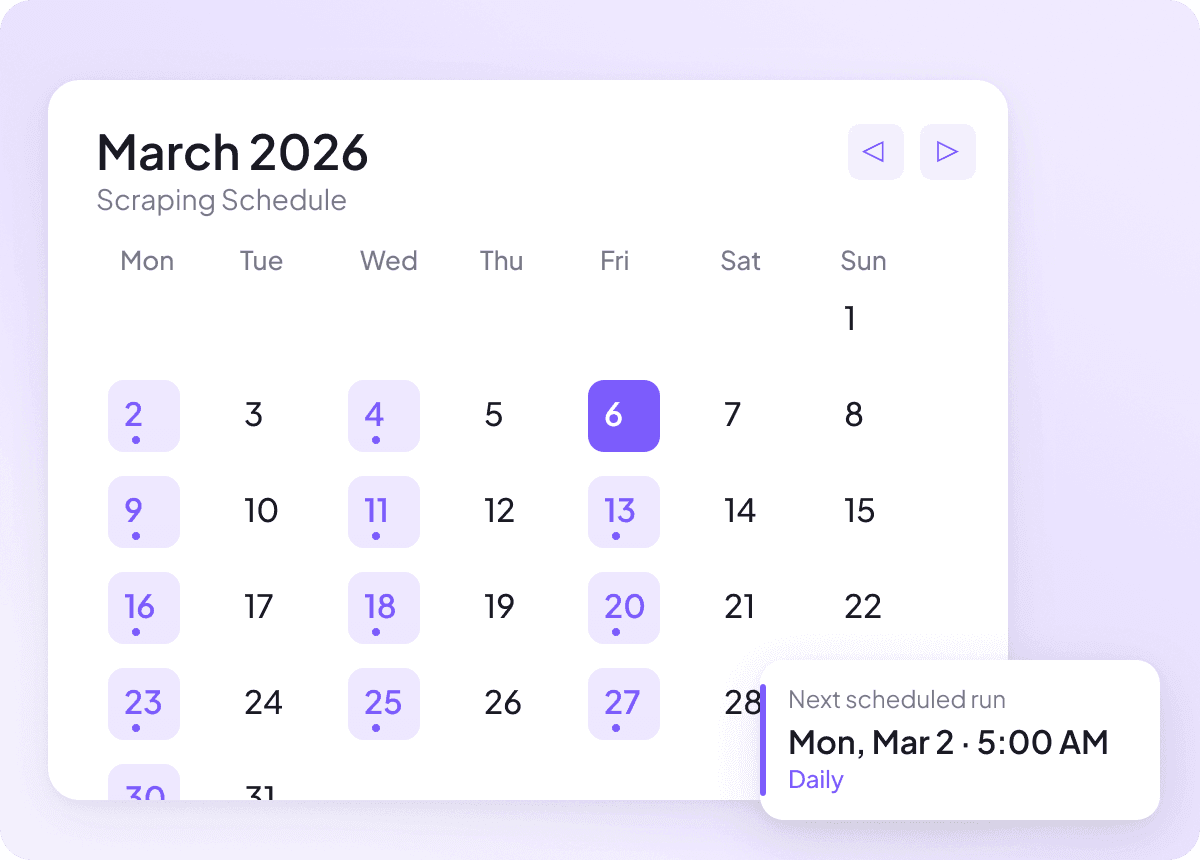
Păstrează datele News actualizate
Știrile se schimbă zilnic, iar datele învechite nu ajută. Setează extragerea programată, astfel încât Thunderbit să ruleze automat și să îți mențină foaia de calcul actualizată cu titluri noi, rezumate, autori, date de publicare, surse de știri și secțiuni. Primești actualizări recurente fără să trebuiască să îți amintești tu de sarcină.
De ce este Thunderbit diferit de news scrapers tradiționali?
O metodă mai rapidă de a colecta date dezordonate despre știri, fără întreruperi constante.
Scraper-e tradiționale
Metoda veche de a face lucrurileThunderbit AI
Abordarea mai inteligentăNu ne crede doar pe cuvânt
Vezi ce spun utilizatorii noștri despre Thunderbit.






Întrebări frecvente
Asemănător cazuri de utilizare
Explorează mai multe cazuri de utilizare pentru scraperul web Thunderbit.

Steam Scraper
Extrage numele aplicațiilor, prețurile și procentele de recenzii ale utilizatorilor din Steam în doar câteva clicuri — fără să scrii cod.
Află mai multe ->
PubMed Scraper
PubMed Scraper de la Thunderbit te ajută să extragi, cu ajutorul AI, date structurate din rezultatele de căutare PubMed și din paginile articolelor. Poți colecta rapid cercetări medicale în trend, dovezi din studii clinice, rezumate, autori, afilieri, date de publicare și linkuri, apoi exporta totul în Excel, Google Sheets, Airtable sau Notion.
Află mai multe ->PeopleWhiz scraper
Thunderbit PeopleWhiz Scraper îți permite să extragi date din rezultatele căutărilor și din profilurile PeopleWhiz cu sugestii de câmpuri bazate pe AI. Colectează nume, date de contact, locații și multe altele pentru cercetare, marketing sau generare de lead-uri. Transformă rapid și eficient datele PeopleWhiz în seturi de date structurate.
Află mai multe ->
Coupang scraper
Obține numele produselor, prețurile și ratele de reducere din Coupang în doar două clicuri — fără să fie nevoie de programare.
Află mai multe ->
Wikipedia scraper
Obține datele din infocaseta Wikipedia, referințele și textul articolului într-un tabel curat — fără cod, AI-ul se ocupă de structurare pentru tine.
Află mai multe ->
Scraper Trustpilot
Transformă paginile Trustpilot într-un tabel clar cu recenzii, evaluări și numele recenzenților. Noi citim fiecare pagină pentru tine, așa că nu ai nevoie de cod sau copy-paste.
Află mai multe ->Ești gata să-ți accelerezi extragerea datelor?
Alătură-te celor peste 100.000 de profesioniști care folosesc deja Thunderbit pentru a-și automatiza fluxurile de web scraping.
Proba gratuită oferă credite nelimitate pentru 8 pagini web.