

Webul crește într-un ritm greu de imaginat. În fiecare zi apar miliarde de pagini noi, produse, recenzii și seturi de date — alimentând totul, de la research de piață și antrenarea modelelor AI până la următoarea ta sesiune de cumpărături pe Amazon. Ca persoană care a lucrat ani buni în SaaS și automatizare, am văzut pe pielea mea cât de mult poate schimba o decizie bună, luată pe baza datelor. Dar aici e problema: colectarea, actualizarea și interpretarea tuturor acestor date de pe web devin tot mai grele, nu mai ușoare. Web scrapers tradiționale abia mai fac față, iar companiile caută o metodă mai inteligentă și mai rapidă de a transforma internetul în insight-uri utile. Aici intră în scenă cloud crawler-ul — un instrument care schimbă discret, dar profund, felul în care organizațiile descoperă și folosesc datele web la scară mare.
Așadar, ce este mai exact un cloud crawler? Cu ce se deosebește de web scraper-ele pe care probabil deja le cunoști? Și de ce echipele, de la vânzări la operațiuni, mizează pe această tehnologie ca să rămână în față într-o lume condusă de date? Hai să lămurim termenii și să vedem cum cloud crawler-ele (în special soluția Thunderbit) schimbă regulile jocului pentru companiile moderne.
Ce este un cloud crawler? Următorul pas în descoperirea datelor
Extrage date de pe orice site folosind AI Get Started Free
Să-l definim simplu: un cloud crawler nu este doar un web scraper care rulează în cloud. Este mai degrabă un motor de descoperire a datelor — un sistem inteligent, bazat pe cloud, creat să găsească, să extragă și să analizeze automat seturi uriașe de date de pe internet. Dacă un web scraper tradițional ia informații de pe câteva pagini (de obicei una câte una și, în general, de pe un singur dispozitiv), un cloud crawler operează la cu totul alt nivel. Rulează în centre de date cloud puternice, parcurge mii sau chiar milioane de pagini în paralel și poate procesa totul, de la text la imagini și PDF-uri — indiferent cât de complex sau întins este site-ul țintă.
Gândește-te așa: dacă un web scraper este ca un singur bibliotecar care copiază fragmente dintr-o carte, un cloud crawler este o echipă de supercomputere care scanează în același timp toate cărțile din bibliotecă, etichetând, organizând și analizând conținutul pe măsură ce avansează. Rezultatul? Companiile obțin date mai bogate, mai proaspete și mai utile — fără blocajele impuse de hardware-ul local sau de munca manuală (Sitebulb, Octoparse).
Cloud crawler vs. web scraper tradițional: care e diferența reală?
Dacă ai folosit vreodată un web scraper, știi pașii de bază: îl direcționezi către o pagină, definești ce vrei și îl lași să extragă datele. Dar pe măsură ce webul devine mai mare și mai complicat, abordarea clasică începe să-și arate limitele. Așa se compară cloud crawler-ele cu web scraper-ele tradiționale:
| Caracteristică/Aspect | Web Scraper tradițional | Cloud Crawler |
|---|---|---|
| Implementare | Rulează pe dispozitivul sau serverul tău local | Rulează în cloud (centre de date la distanță) |
| Scară | Limitat de puterea calculatorului tău | Procesare masiv paralelă — mii de pagini simultan |
| Viteză | Mai lent, mai ales la sarcini mari | Procesare rapidă în loturi |
| Întreținere | Necesită actualizări frecvente, se strică la schimbări ale site-ului | Bazat pe cloud, se actualizează automat, mai puțin fragil |
| Tipuri de date | De obicei text, uneori imagini | Text, imagini, PDF-uri, layout-uri complexe |
| Acces | Legat de dispozitivul/rețeaua ta | Accesibil de oriunde, de pe orice dispozitiv |
| Programare | Manual sau automatizare de bază | Programare avansată, rulări recurente |
| Cel mai potrivit pentru | Proiecte mici, site-uri simple | Nevoi de date la scară mare, frecvente sau complexe |
Cloud crawler-ele sunt construite pentru webul modern — unde datele sunt peste tot, iar viteza și scara sunt obligatorii, nu opționale (GPTBots, Octoparse).
Cum accelerează cloud crawler-ele colectarea datelor
Aici lucrurile devin cu adevărat interesante. Cloud crawler-ele folosesc puterea cloud computing-ului ca să proceseze mii de pagini web în paralel. Asta înseamnă că poți extrage întregul catalog al unui magazin online, poți urmări prețurile concurenței pe zeci de site-uri sau poți aduna anunțuri imobiliare de pe toate marile portaluri — și toate acestea într-un timp mult mai scurt decât cu un scraper tradițional.
De ce contează asta? Pentru că în domenii precum ecommerce, finanțe și imobiliare, prospețimea datelor este esențială. Prețurile, stocurile și tendințele pieței se pot schimba de la minut la minut. Să aștepți ore sau zile până când un scraper local termină pur și simplu nu este o opțiune. Cloud crawler-ele nu sunt limitate de memoria laptopului tău sau de Wi‑Fi-ul de la birou — se scalează când ai nevoie, ca să poți gestiona sarcini uriașe fără stres (Zyte, Octoparse).
Printre industriile care profită cel mai mult de această eficiență se numără:
- Ecommerce: monitorizarea prețurilor, agregarea cataloagelor de produse, analiza recenziilor
- Imobiliare: agregarea anunțurilor, urmărirea tendințelor pieței, compararea proprietăților
- Finanțe: analiză de știri și sentiment, monitorizarea acțiunilor/criptomonedelor, urmărirea reglementărilor
- Vânzări și marketing: generarea de lead-uri, research competitiv, identificarea tendințelor
Și, sincer, asta e doar începutul. Dacă ai nevoie de date web la scară mare, un cloud crawler devine foarte repede cel mai bun aliat al tău.
Soluția cloud crawler de la Thunderbit: rapidă, flexibilă și puternică
Lasă-mă să-mi pun pentru o clipă pălăria de Thunderbit (ok, de fapt n-o dau niciodată jos). Modul de cloud scraping de la Thunderbit este răspunsul nostru la provocările moderne legate de date — un cloud crawler creat pentru utilizatorii de business care vor rezultate, nu bătăi de cap.
Iată ce face ca cloud crawler-ul Thunderbit să iasă în evidență:
- Extragere în loturi, de mare viteză: extrage până la 50 de pagini simultan, folosind servere cloud din SUA, UE și Asia pentru acoperire globală. Gata cu așteptatul ca laptopul tău să „tragă” după o listă lungă.
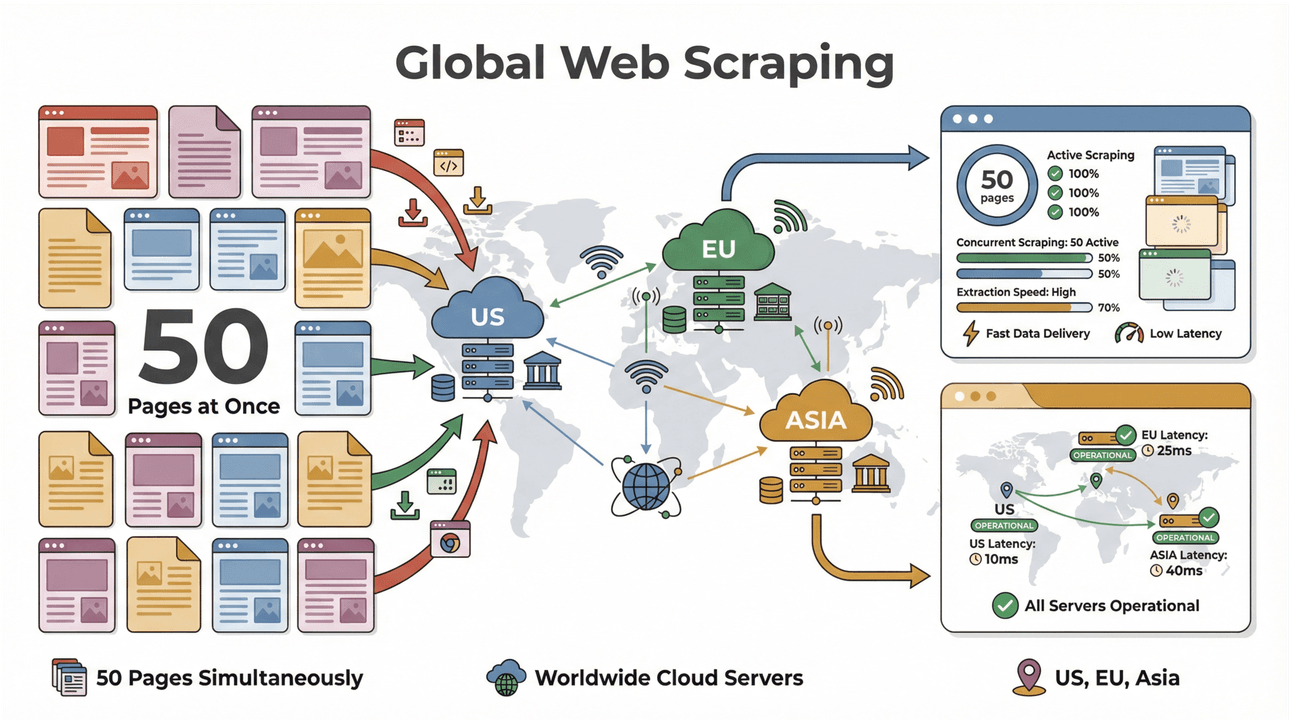
- Suport pentru pagini complexe: AI-ul Thunderbit poate gestiona totul, de la site-uri ecommerce dinamice la PDF-uri complicate și chiar extragerea de imagini. Dacă există pe web, Thunderbit probabil poate să-l extragă (Thunderbit).
- Parcurgere de subpagini: Ai nevoie să îmbogățești datele cu informații din subpagini (cum ar fi specificații de produs sau biografii de autori)? AI-ul Thunderbit poate vizita fiecare subpagină și poate combina rezultatele în setul tău principal de date (Thunderbit).
- Structurare inteligentă a datelor: folosește „AI Suggest Fields” ca Thunderbit să citească site-ul și să recomande cele mai bune coloane — fără cod și fără să construiești template-uri.
- Export oriunde: trimite datele direct în Excel, Google Sheets, Airtable sau Notion. Sau descarcă-le ca CSV/JSON — exact cum se potrivește fluxului tău de lucru (Thunderbit).
- Fără întreținere: AI-ul Thunderbit se adaptează la modificările site-urilor, așa că nu mai pierzi timp reparând constant scrapers care se strică (Thunderbit).
Și da, poți încerca toate acestea cu un plan gratuit — deci nu trebuie să mă crezi pe cuvânt.
Încearcă gratuit Thunderbit Cloud Scraper
Implementarea cloud crawler-ului: cloud sau local — care ți se potrivește?
Unul dintre cele mai mari avantaje ale cloud crawler-elor este flexibilitatea implementării. Cu un crawler tradițional (local), ești legat de un anumit dispozitiv, de o anumită rețea și, de multe ori, de o mulțime de bătăi de cap la configurare. Dacă laptopul intră în sleep sau pică internetul, procesul se oprește. Iar dacă vrei să scalezi, ai nevoie de hardware suplimentar sau de mai multe scripturi care rulează în paralel.
Cloud crawler-ele schimbă complet abordarea:
- Nu ai nevoie de hardware special: toată munca grea se face în cloud. Poți porni extrageri masive de pe un Chromebook, un Mac sau chiar de pe telefon.
- Acces de oriunde: ești în deplasare sau lucrezi remote? Nicio problemă — cloud crawler-ul este mereu disponibil.
- Scalare ușoară: ai nevoie să extragi 10.000 de pagini în loc de 100? Mărești pur și simplu dimensiunea jobului — fără intervenția IT.
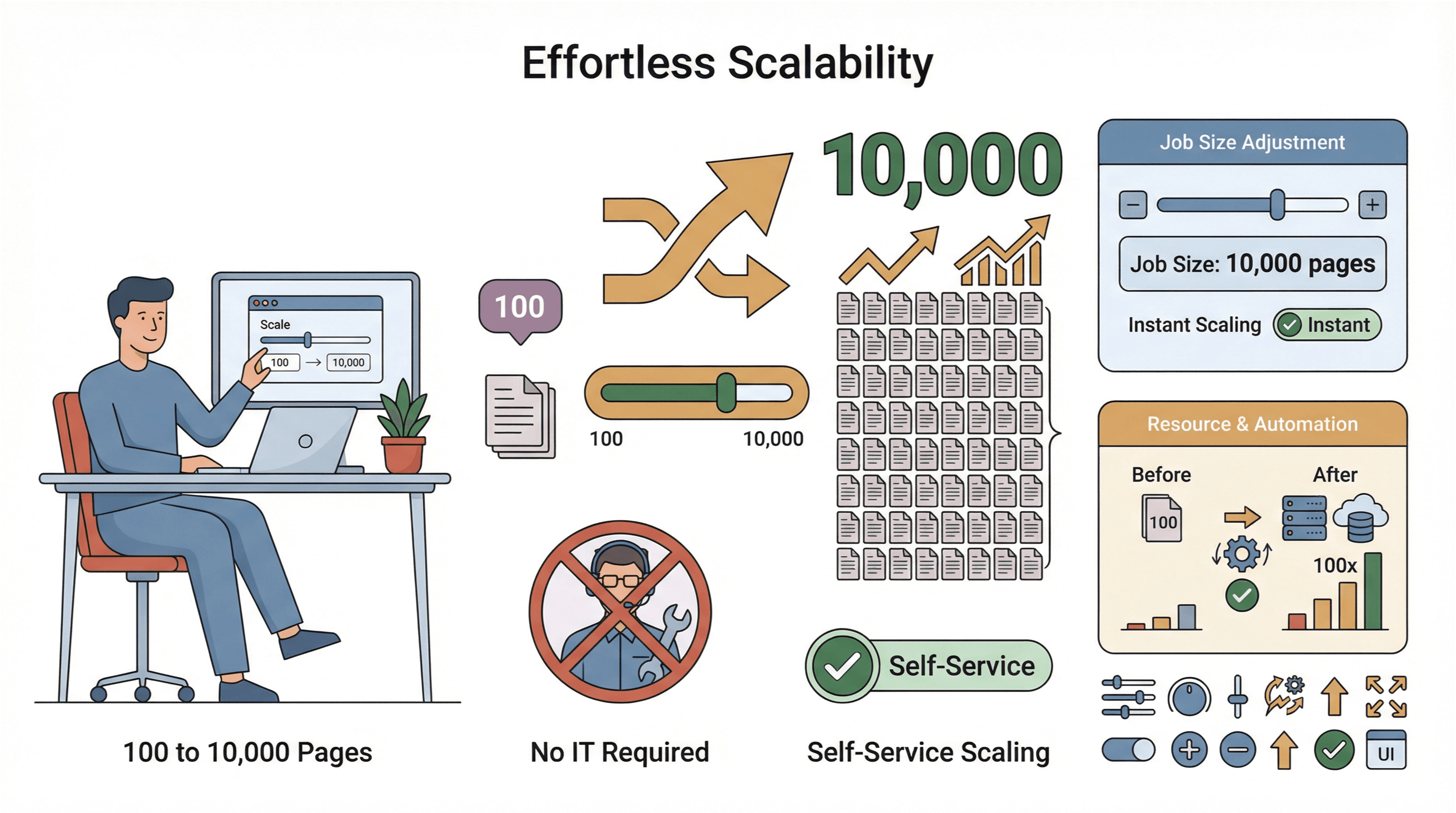
- Colectare globală de date: cu servere cloud în mai multe regiuni, poți accesa conținut restricționat geografic și poți gestiona mai ușor cerințele de conformitate (PromptCloud).
Desigur, securitatea și conformitatea rămân mereu priorități majore. Cele mai bune cloud crawler-e (inclusiv Thunderbit) folosesc conexiuni criptate, respectă termenii site-urilor și oferă funcții care te ajută să gestionezi responsabil datele sensibile.
Impact în lumea reală: cum transformă cloud crawler-ele strategiile bazate pe date
Să trecem la concret. De ce trec companiile la cloud crawler-e? Pentru că văd rezultate reale și măsurabile:
- Analiză de piață în timp real: retailerii folosesc cloud crawler-e pentru a monitoriza în timp real prețurile și stocurile concurenței, ceea ce permite prețuri dinamice și reacții mai rapide la schimbările pieței (Zyte).
- Previzionarea tendințelor de consum: brandurile agregă recenzii, postări din social media și discuții de pe forumuri pentru a identifica trenduri emergente și a ajusta campaniile din mers.
- Vânzări și generare de lead-uri: echipele de vânzări construiesc liste actualizate de lead-uri din directoare, site-uri de evenimente și chiar PDF-uri — alimentând CRM-urile cu contacte noi și calificate (Thunderbit).
- Operațiuni și conformitate: firmele financiare folosesc cloud crawler-e pentru a urmări actualizări de reglementare, știri și depuneri în mai multe jurisdicții — reducând riscurile și anticipând schimbările.
Ideea comună? Cloud crawler-ele ajută echipele să se miște mai repede, să ia decizii mai bune și să depășească rivalii care încă merg în ritm lent.
Caracteristici esențiale de urmărit la un cloud crawler
Vezi prețurile și funcțiile Thunderbit Get Started Free
Nu toate cloud crawler-ele sunt la fel. Dacă evaluezi opțiuni, iată ce contează cel mai mult (și unde excelează Thunderbit):
- Scalabilitate: poate gestiona mii de pagini simultan? Încetinește pe măsură ce joburile devin mai mari?
- Ușurință în utilizare: interfața este prietenoasă pentru utilizatorii non-tehnici? Poți configura o extragere în câteva clicuri?
- Suport pentru mai multe tipuri de date: text, imagini, PDF-uri, subpagini — le poate gestiona pe toate?
- Integrări: exportă către instrumentele tale preferate (Excel, Sheets, Notion, Airtable)?
- Programare: poți seta rulări recurente pentru date mereu proaspete?
- Asistență AI: oferă sugestii inteligente pentru câmpuri, îmbogățirea datelor și adaptare automată la schimbările site-ului?
- Securitate și conformitate: datele și credențialele tale sunt protejate? Te ajută să respecți legile privind confidențialitatea?
Thunderbit bifează toate aceste puncte, ceea ce îl transformă într-o alegere excelentă pentru echipele care vor putere fără complicații.
Cum începi: folosirea unui cloud crawler pentru afacerea ta
Ești gata să începi? Iată cum poate porni un utilizator de business cu un cloud crawler precum Thunderbit:
- Instalează extensia Chrome Thunderbit: configurare rapidă, fără IT.
- Alege ținta: deschide site-ul, lista sau documentul din care vrei să extragi date.
- Apasă „AI Suggest Fields”: lasă AI-ul Thunderbit să scaneze pagina și să recomande cele mai bune coloane de extras.
- Personalizează după nevoie: adaugă, elimină sau redenumește câmpurile ca să se potrivească cerințelor tale.
- Selectează modul Cloud Scraping: pentru joburi mari sau site-uri complexe, treci pe modul cloud pentru viteză maximă.
- Pornește extragerea: Thunderbit va procesa până la 50 de pagini simultan în cloud.
- Verifică și exportă: previzualizează rezultatele, apoi exportă-le în Excel, Google Sheets, Notion sau Airtable.
- Programează rulări recurente: pentru nevoi continue, setează extrageri programate — datele se vor actualiza automat (Thunderbit Docs).
Sfat util: începe cu un job mic, ca să te obișnuiești, apoi crește treptat pe măsură ce capeți încredere. Și nu ezita să folosești suportul sau documentația Thunderbit — sunt acolo ca să te ajute.
Începe să faci crawling în cloud cu Thunderbit
Viitorul colectării de date: ce urmează pentru cloud crawler-e?
Revoluția cloud crawler-elor abia a început. Iată la ce mă uit eu în următorii ani:
- Extragere AI mai inteligentă: cloud crawler-ele devin tot mai bune la înțelegerea contextului, relațiilor și chiar a sentimentului — ceea ce face datele colectate mult mai valoroase (GPTBots).
- Suport pentru tipuri noi de date: ne putem aștepta la o gestionare mai bună a conținutului video, audio și interactiv — nu doar text static și imagini.
- Automatizare mai profundă: de la programare automată la alerte în timp real, cloud crawler-ele vor deveni și mai „hands-off” pentru utilizatorii de business.
- Conformitate îmbunătățită: pe măsură ce legislația privind confidențialitatea evoluează, cloud crawler-ele vor integra mai multe instrumente care să ajute echipele să rămână în limitele regulilor.
- Integrare cu instrumente BI și AI: fluxuri directe de la cloud crawler-e către platforme de analiză, dashboard-uri și machine learning.
Pe scurt, cloud crawler-ele sunt pe cale să devină coloana vertebrală a strategiei digitale de business — alimentând totul, de la lansări de produse la prognoze bazate pe AI (Thunderbit Blog).
Concluzie: de ce cloud crawler-ele sunt esențiale pentru companiile moderne
Pe scurt: webul explodează de date, iar vechile metode de colectare pur și simplu nu mai țin pasul. Cloud crawler-ele reprezintă următoarea evoluție — oferind viteză, scală și inteligență pe care web scraper-ele tradiționale nu le pot egala. Instrumente precum Thunderbit fac posibil ca orice echipă, tehnică sau nu, să valorifice întregul potențial al datelor de pe web — luând decizii mai inteligente, reacționând mai rapid și câștigând un avantaj competitiv real.
Dacă ești gata să renunți la extragerea manuală și la colectarea lentă a datelor, acum e momentul să vezi ce poate face un cloud crawler pentru afacerea ta. Încearcă modul de cloud scraping din Thunderbit și descoperă cât de ușoară — și de puternică — poate fi descoperirea modernă a datelor. Iar dacă vrei să aprofundezi, consultă Thunderbit Blog pentru mai multe ghiduri, sfaturi și exemple reale.
Întrebări frecvente
1. Ce este, pe scurt, un cloud crawler?
Un cloud crawler este un instrument bazat pe cloud care descoperă, extrage și analizează automat cantități mari de date de pe web. Spre deosebire de scraper-ele tradiționale care rulează pe dispozitivul tău local, cloud crawler-ele funcționează în centre de date puternice, ceea ce le permite să lucreze la scară mare și cu viteză foarte bună.
2. Cu ce este diferit un cloud crawler de un web scraper obișnuit?
Cloud crawler-ele rulează în cloud, pot gestiona mii de pagini simultan, acceptă tipuri complexe de date (cum ar fi imagini și PDF-uri) și nu necesită întreținere sau hardware local. Web scraper-ele tradiționale sunt limitate de puterea dispozitivului și sunt mai potrivite pentru sarcini mai mici și mai simple.
3. Care sunt principalele beneficii ale folosirii unui cloud crawler?
Cloud crawler-ele oferă colectare de date rapidă, la scară mare, suport pentru site-uri complexe, acces facil de oriunde și funcții avansate precum programare și extragere asistată de AI. Sunt ideale pentru companiile care au nevoie rapid de date proaspete și utile.
4. Cum funcționează cloud crawler-ul Thunderbit pentru utilizatorii de business?
Cloud crawler-ul Thunderbit îți permite să configurezi o extragere în doar câteva clicuri — fără cod. Poți extrage date din site-uri web, PDF-uri și imagini, le poți îmbogăți cu AI și le poți exporta direct în Excel, Google Sheets, Notion sau Airtable. Este creat pentru utilizatorii non-tehnici care vor rezultate, nu complexitate.
5. Este cloud crawling-ul sigur și conform cu legile privind protecția datelor?
Da, cloud crawler-ele de top precum Thunderbit folosesc conexiuni criptate și bune practici de securitate a datelor. Asigură-te întotdeauna că extragi doar date publice și că respecți termenii site-urilor și reglementările privind confidențialitatea.
Vrei să vezi ce poate face un cloud crawler? Descarcă Thunderbit și începe chiar azi să explorezi lumea colectării de date la scară mare, alimentată de cloud.
Încearcă astăzi Thunderbit Cloud Crawler Get Started Free
Află mai multe




