
Web-ul e plin de date valoroase — fie că lucrezi în vânzări, ecommerce sau cercetare de piață, web scraping-ul este arma secretă pentru generarea de lead-uri, monitorizarea prețurilor și analiza concurenței. Dar iată problema: pe măsură ce tot mai multe companii folosesc scraping-ul, site-urile ripostează mai agresiv ca niciodată. De fapt, peste , iar au devenit deja norma. Dacă ai văzut vreodată cum scriptul tău Python rulează perfect 20 de minute — apoi se lovește brusc de un zid de erori 403 — știi cât de reală este frustrarea.
Am lucrat ani de zile în SaaS și automatizare și am văzut direct cum proiectele de scraping pot trece într-o clipă de la „wow, e foarte ușor” la „de ce sunt blocat peste tot?”. Așa că hai să fim practici: îți voi arăta cum să faci web scraping fără să fii blocat în Python, voi împărtăși cele mai bune tehnici și fragmente de cod și îți voi arăta când merită să iei în calcul alternative bazate pe AI, precum . Fie că ești un profesionist Python sau doar te descurci cum poți cu scraping-ul, vei pleca de aici cu un set de instrumente pentru extragere de date fiabilă, fără blocaje.
Ce înseamnă web scraping fără să fii blocat în Python?
În esență, web scraping fără să fii blocat înseamnă extragerea datelor de pe site-uri într-un mod care evită declanșarea apărărilor lor anti-bot. În lumea Python, asta înseamnă mai mult decât să scrii un simplu loop requests.get() — înseamnă să te integrezi natural, să imiți utilizatorii reali și să rămâi cu un pas înaintea sistemelor de detecție.
De ce Python? — datorită sintaxei simple, ecosistemului vast (de exemplu: requests, BeautifulSoup, Scrapy, Selenium) și flexibilității pentru orice, de la scripturi rapide la crawlere distribuite. Dar popularitatea vine cu un preț: multe sisteme anti-bot sunt acum calibrate să detecteze tiparele de scraping bazate pe Python.
Așadar, dacă vrei să faci scraping în mod fiabil, trebuie să treci dincolo de bazele simple. Asta înseamnă să înțelegi cum detectează site-urile boții și cum îi poți depăși — fără să treci peste limitele etice sau legale.
De ce contează evitarea blocajelor în proiectele de web scraping Python
A fi blocat nu este doar un hop tehnic — poate deraia fluxuri de lucru întregi din business. Hai să descompunem lucrurile:
| Caz de utilizare | Impactul blocării |
|---|---|
| Generare de lead-uri | Liste de prospecte incomplete sau depășite, vânzări pierdute |
| Monitorizarea prețurilor | Ratezi schimbările de preț ale concurenței, decizii de preț slabe |
| Agregare de conținut | Goluri în datele despre știri, recenzii sau cercetare |
| Inteligență de piață | Puncte moarte în urmărirea concurenței sau a industriei |
| Anunțuri imobiliare | Date despre proprietăți inexacte sau învechite, oportunități ratate |
Când un scraper este blocat, nu pierzi doar date — irosești resurse, riști probleme de conformitate și poți lua decizii greșite bazate pe informații incomplete. Într-o lume în care , fiabilitatea este totul.
Cum detectează și blochează site-urile web scrapers-urile Python
Site-urile au devenit foarte istețe în a depista boții. Iată cele mai comune mecanisme anti-scraping pe care le vei întâlni (, ):
- Blacklisting de adrese IP: Prea multe cereri de la același IP? Blocat.
- Verificări User-Agent și headere: Cererile cu headere lipsă sau generice (cum ar fi
python-requests/2.25.1implicit) ies în evidență. - Rate limiting: Prea multe cereri într-un timp scurt declanșează limitări sau interdicții.
- CAPTCHA: Puzzle-uri de tipul „dovedește că ești om” pe care boții nu le pot rezolva (ușor).
- Analiză comportamentală: Site-urile urmăresc tipare robotice — de exemplu, apăsarea aceluiași buton la același interval.
- Honeypots: Linkuri sau câmpuri ascunse cu care doar boții interacționează.
- Browser fingerprinting: Colectarea detaliilor despre browserul și dispozitivul tău pentru a identifica instrumentele de automatizare.
- Urmărirea cookie-urilor și a sesiunilor: Boții care nu gestionează corect cookie-urile sau sesiunile sunt marcați.
Gândește-te la asta ca la controlul de securitate din aeroport: dacă arăți, te porți și te miști ca toți ceilalți, treci rapid. Dacă apare cineva în trench coat și ochelari de soare, te poți aștepta la întrebări suplimentare.
Tehnici Python esențiale pentru web scraping fără să fii blocat
Hai la partea bună: cum să eviți efectiv blocajele când faci scraping cu Python. Iată strategiile de bază pe care orice scraper ar trebui să le cunoască:

Proxy-uri rotative și adrese IP
De ce contează: Dacă toate cererile tale vin de la același IP, ești o țintă ușoară pentru interdicții IP. Proxy-urile rotative îți permit să distribui cererile pe mai multe IP-uri, făcând blocarea mult mai dificilă.
Cum faci asta în Python:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...mai multe proxy-uri
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # procesează răspunsulPoți folosi servicii de proxy plătite (de exemplu, residential sau proxy-uri rotative) pentru mai multă fiabilitate ().
Setarea User-Agent și a headerelor personalizate
De ce contează: Headerele implicite din Python strigă „bot”. Imită browserele reale setând user-agent și alte headere.
Exemplu de cod:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)Rotește user-agent-urile pentru un plus de discreție ().
Randomizarea timpului și a tiparelor cererilor
De ce contează: Boții sunt rapizi și predictibili; oamenii sunt lenți și impredictibili. Adaugă întârzieri și variază navigarea.
Sfat Python:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # Așteaptă 2–7 secundePoți, de asemenea, să randomizezi traseele de click și tiparele de scroll dacă folosești Selenium.
Gestionarea cookie-urilor și sesiunilor
De ce contează: Multe site-uri necesită cookie-uri sau tokenuri de sesiune pentru a accesa conținutul. Boții care le ignoră sunt blocați.
Cum le gestionezi în Python:
1import requests
2session = requests.Session()
3response = session.get(url)
4# session va gestiona automat cookie-urilePentru fluxuri mai complexe, folosește Selenium pentru a captura și reutiliza cookie-urile.
Simularea comportamentului uman cu browsere headless
De ce contează: Unele site-uri folosesc JavaScript, mișcarea mouse-ului sau scroll-ul ca semnale că vizitatorul este real. Browserele headless precum Selenium sau Playwright pot imita aceste acțiuni.
Exemplu cu Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))Asta te ajută să ocolești analiza comportamentală și conținutul dinamic ().
Strategii avansate: ocolirea CAPTCHA-urilor și honeypot-urilor în Python
CAPTCHA-urile sunt create pentru a opri boții pe loc. Deși unele biblioteci Python pot rezolva CAPTCHA-uri simple, majoritatea scraper-elor serioase se bazează pe servicii terțe (precum 2Captcha sau Anti-Captcha) pentru a le rezolva contra cost ().
Integrare exemplu:
1# Pseudocod pentru folosirea API-ului 2Captcha
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# Așteaptă soluția, apoi trimite-o odată cu cererea taHoneypots sunt câmpuri sau linkuri ascunse cu care interacționează doar boții. Evită să dai click pe orice nu este vizibil într-un browser real ().
Cum să construiești headere de cerere robuste cu bibliotecile Python
Dincolo de user-agent, poți roti și randomiza alte headere (cum ar fi Referer, Accept, Origin etc.) pentru a te integra și mai bine.
Cu Scrapy:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # Mai multe headere
7 }
8 }Cu Selenium: folosește profile de browser sau extensii pentru a seta headerele, sau injectează-le prin JavaScript.
Ține lista de headere actualizată — copiază cereri reale din browser folosind DevTools pentru inspirație.
Când scraping-ul Python tradițional nu mai este suficient: ascensiunea tehnologiei anti-bot
Asta este realitatea: pe măsură ce scraping-ul devine mai popular, apar și mai multe actualizări anti-bot. . Detecția bazată pe AI, pragurile dinamice pentru cereri și browser fingerprinting fac tot mai dificilă menținerea nedetectată chiar și a scripturilor Python avansate ().
Uneori, oricât de isteț ar fi codul tău, tot vei da de un zid. Atunci e momentul să iei în considerare o abordare diferită.
Thunderbit: o alternativă AI Web Scraper la scraping-ul în Python
Când Python își atinge limitele, intră în scenă ca un web scraper fără cod, bazat pe AI, construit pentru utilizatori de business — nu doar pentru dezvoltatori. În loc să te lupți cu proxy-uri, headere și CAPTCHA-uri, agentul AI al Thunderbit citește site-ul, sugerează cele mai bune câmpuri de extras și se ocupă de tot, de la navigarea pe subpagini până la exportul datelor.
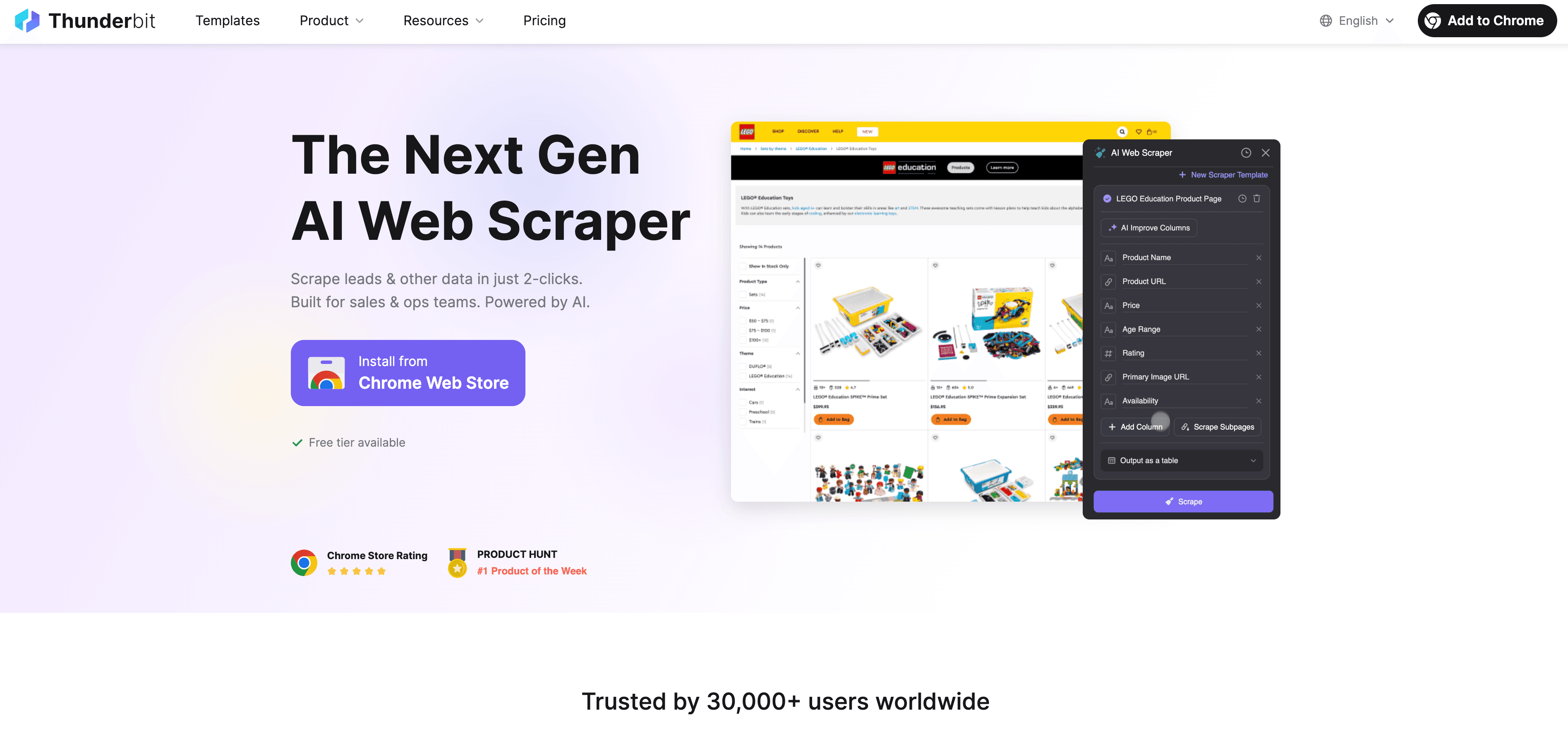
Ce face Thunderbit diferit?
- Sugestii AI pentru câmpuri: Apasă „AI Suggest Fields” și Thunderbit scanează pagina, recomandă coloane și chiar generează instrucțiuni de extragere.
- Scraping pe subpagini: Thunderbit poate vizita fiecare subpagină (cum ar fi detalii de produse sau profiluri LinkedIn) și îți îmbogățește automat tabelul.
- Scraping în cloud sau în browser: Alege opțiunea cea mai rapidă — cloud pentru site-uri publice, browser pentru pagini protejate de autentificare.
- Scraping programat: Setează-l și uită de el — Thunderbit poate face scraping după program, astfel încât datele tale să fie mereu actualizate.
- Șabloane instant: Pentru site-uri populare (Amazon, Zillow, Shopify etc.), Thunderbit oferă șabloane cu un singur click — fără configurare.
- Export gratuit de date: Exportă în Excel, Google Sheets, Airtable sau Notion — fără taxe suplimentare.
Thunderbit este de încredere pentru peste , iar tu nu trebuie să scrii nici măcar o singură linie de cod.
Cum ajută Thunderbit utilizatorii să evite blocajele și să automatizeze extragerea datelor
AI-ul Thunderbit nu doar imită comportamentul uman — se adaptează fiecărui site în timp real, reducând riscul de blocare. Iată cum:
- AI-ul se adaptează schimbărilor de aspect: Gata cu scripturile care se strică atunci când un site își schimbă designul.
- Gestionarea subpaginilor și a paginării: Thunderbit urmează automat linkurile și listele paginate, exact ca un utilizator real.
- Scraping în cloud la scară mare: Extrage date de pe până la 50 de pagini simultan, extrem de rapid.
- Fără cod, fără mentenanță: Petrece-ți timpul analizând datele, nu depanând.
Pentru o analiză mai detaliată, vezi .
Compararea scraping-ului în Python vs. Thunderbit: pe care ar trebui să-l alegi?
Să le punem alături:
| Funcționalitate | Scraping în Python | Thunderbit |
|---|---|---|
| Timp de configurare | Mediu–ridicat (scripturi, proxy-uri etc.) | Redus (2 clickuri, AI face restul) |
| Abilități tehnice | Necesită programare | Fără programare |
| Fiabilitate | Variabilă (se poate strica ușor) | Ridicată (AI se adaptează la schimbări) |
| Risc de blocare | Mediu–ridicat | Scăzut (AI imită utilizatorul, se adaptează) |
| Scalabilitate | Are nevoie de cod personalizat/configurare cloud | Scraping în cloud și pe loturi, integrate |
| Mentenanță | Frecventă (schimbări ale site-ului, blocaje) | Minimă (AI se ajustează automat) |
| Opțiuni de export | Manual (CSV, DB) | Direct în Sheets, Notion, Airtable, CSV |
| Cost | Gratuit (dar consumă mult timp) | Plan gratuit, planuri plătite pentru scară mare |
Când să folosești Python:
- Ai nevoie de control total, logică personalizată sau integrare cu alte fluxuri Python.
- Faci scraping pe site-uri cu apărări anti-bot minime.
Când să folosești Thunderbit:
- Vrei viteză, fiabilitate și zero configurare.
- Faci scraping pe site-uri complexe sau care se schimbă frecvent.
- Nu vrei să te ocupi de proxy-uri, CAPTCHA-uri sau cod.
Ghid pas cu pas: configurarea web scraping-ului fără să fii blocat în Python
Hai să parcurgem un exemplu practic: extragerea datelor despre produse de pe un site demo, aplicând bune practici pentru evitarea blocării.
1. Instalează bibliotecile necesare
1pip install requests beautifulsoup4 fake-useragent2. Pregătește scriptul
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Înlocuiește cu URL-urile tale
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # Extrage datele aici
16 print(soup.title.text)
17 else:
18 print(f"Blocat sau eroare la {url}: {response.status_code}")
19 time.sleep(random.uniform(2, 6)) # Întârziere aleatorie3. Adaugă rotația proxy-urilor (opțional)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # Mai multe proxy-uri
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...restul codului4. Gestionează cookie-urile și sesiunile
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...restul codului5. Sfaturi de depanare
- Dacă vezi multe erori 403/429, încetinește cererile sau încearcă proxy-uri noi.
- Dacă întâlnești CAPTCHA-uri, ia în calcul folosirea Selenium sau a unui serviciu de rezolvare CAPTCHA.
- Verifică întotdeauna
robots.txtși termenii de utilizare ai site-ului.
Concluzie și idei esențiale
Web scraping-ul în Python este puternic — dar a fi blocat este un risc constant pe măsură ce tehnologiile anti-bot evoluează. Cea mai bună metodă de a evita blocajele? Combină bunele practici tehnice (proxy-uri rotative, headere inteligente, întârzieri aleatorii, gestionarea sesiunilor și browsere headless) cu respect pentru regulile și etica site-ului.
Dar uneori, nici cele mai bune trucuri Python nu sunt suficiente. Aici strălucesc instrumentele bazate pe AI precum — oferind o modalitate fără cod, rezistentă la blocaje și prietenoasă pentru business de a extrage rapid datele de care ai nevoie.
Vrei să vezi cât de ușor poate fi scraping-ul? și încearc-o chiar tu — sau intră pe pentru mai multe sfaturi și tutoriale despre scraping.
Întrebări frecvente
1. De ce blochează site-urile web scrapers-urile Python?
Site-urile blochează scrapers-urile pentru a-și proteja datele, a preveni supraîncărcarea serverelor și a opri boții automatizați care abuzează de serviciile lor. Scripturile Python sunt ușor de observat dacă folosesc headere implicite, nu gestionează cookie-urile sau trimit prea multe cereri prea repede.
2. Care sunt cele mai eficiente metode de a evita blocarea când faci scraping cu Python?
Folosește proxy-uri rotative, setează user-agent și headere realiste, randomizează momentul cererilor, gestionează cookie-urile/sesiunile și simulează comportamentul uman cu instrumente precum Selenium sau Playwright.
3. Cum ajută Thunderbit să eviți blocajele comparativ cu scripturile Python?
Thunderbit folosește AI pentru a se adapta la aspectul site-urilor, a imita navigarea umană și a gestiona automat subpaginile și paginarea. Reduce riscul de blocaj prin integrare naturală și actualizarea strategiei în timp real — fără cod sau proxy-uri.
4. Când ar trebui să folosesc scraping în Python vs. un instrument AI precum Thunderbit?
Folosește Python când ai nevoie de logică personalizată, integrare cu alt cod Python sau când extragi de pe site-uri simple. Folosește Thunderbit pentru scraping rapid, fiabil și scalabil — mai ales când site-urile sunt complexe, se schimbă des sau blochează agresiv scripturile.
5. Este legal web scraping-ul?
Web scraping-ul este legal pentru date disponibile public, dar trebuie să respecți termenii de utilizare, politicile de confidențialitate și legile relevante ale fiecărui site. Nu extrage niciodată date sensibile sau private și folosește scraping-ul în mod etic și responsabil.
Ești gata să faci scraping mai inteligent, nu mai greu? Încearcă Thunderbit și lasă blocajele în urmă.
Află mai multe:
- Scraping Google News cu Python: ghid pas cu pas
- Construiește un instrument de urmărire a prețurilor pentru Best Buy folosind Python
- 14 moduri de a face web scraping fără să fii blocat
- 10 sfaturi excelente despre cum să nu fii blocat la web scraping