

Există ceva atemporal în a deschide un terminal, a tasta o singură comandă și a vedea cum datele web brute încep să curgă, ca și cum ai fi deschis chiar Matrixul. Pentru dezvoltatori și utilizatorii avansați, cURL este exact genul acela de baghetă magică: un utilitar discret din linia de comandă, care rulează liniștit pe miliarde de dispozitive, de la servere cloud până la frigiderul tău inteligent. Și chiar și în 2026, cu toate uneltele no-code și AI pentru scraping apărute între timp, web scraping cu cURL rămâne o soluție de bază pentru oricine vrea viteză, control și posibilitatea de a-l integra în scripturi.
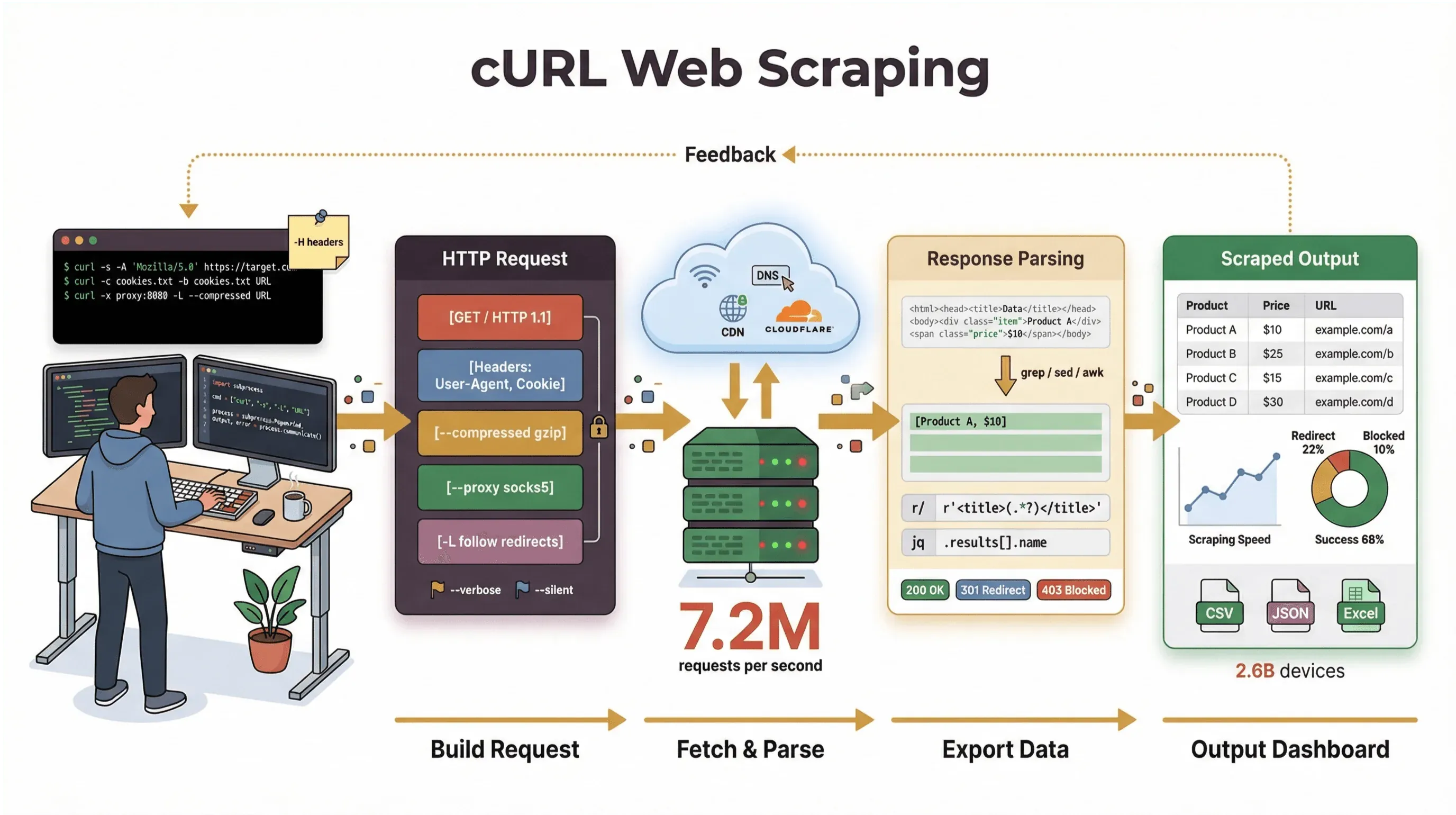 De-a lungul anilor am construit instrumente de automatizare și am ajutat echipe să lucreze cu date web, iar cURL rămâne una dintre primele opțiuni când trebuie să preiau o pagină, să depanez un API sau să fac un prototip de flux de scraping. În acest ghid, te voi duce printr-un tutorial de web scraping cu curl care acoperă atât bazele, cât și trucurile avansate — cu exemple reale de comenzi, sfaturi practice și o privire sinceră asupra zonelor în care cURL excelează (și a celor în care se blochează). Iar dacă ești mai degrabă un utilizator de business care nu vrea să atingă linia de comandă, îți voi arăta cum Thunderbit, web scraper-ul nostru bazat pe AI, te poate duce de la „am nevoie de datele astea” la „iată foaia mea de calcul” în două clicuri — fără cod.
De-a lungul anilor am construit instrumente de automatizare și am ajutat echipe să lucreze cu date web, iar cURL rămâne una dintre primele opțiuni când trebuie să preiau o pagină, să depanez un API sau să fac un prototip de flux de scraping. În acest ghid, te voi duce printr-un tutorial de web scraping cu curl care acoperă atât bazele, cât și trucurile avansate — cu exemple reale de comenzi, sfaturi practice și o privire sinceră asupra zonelor în care cURL excelează (și a celor în care se blochează). Iar dacă ești mai degrabă un utilizator de business care nu vrea să atingă linia de comandă, îți voi arăta cum Thunderbit, web scraper-ul nostru bazat pe AI, te poate duce de la „am nevoie de datele astea” la „iată foaia mea de calcul” în două clicuri — fără cod.
Hai să intrăm direct în subiect și să vedem de ce cURL încă contează pentru web scraping în 2026, cum îl folosești eficient și când e momentul să treci la ceva și mai puternic.
Ce este cURL? Fundamentul web scraping cu curl
În esență, cURL este un utilitar din linia de comandă și o bibliotecă pentru transferul de date prin URL-uri. Există de aproape 30 de ani (da, chiar atât) și este peste tot — integrat în sisteme de operare, folosit în scripturi și responsabil, discret, pentru transferuri de date în peste douăzeci de miliarde de instalări. Dacă ai rulat vreodată o comandă rapidă ca să preiei o pagină web, să testezi un API sau să descarci un fișier, sunt șanse mari să fi folosit cURL.
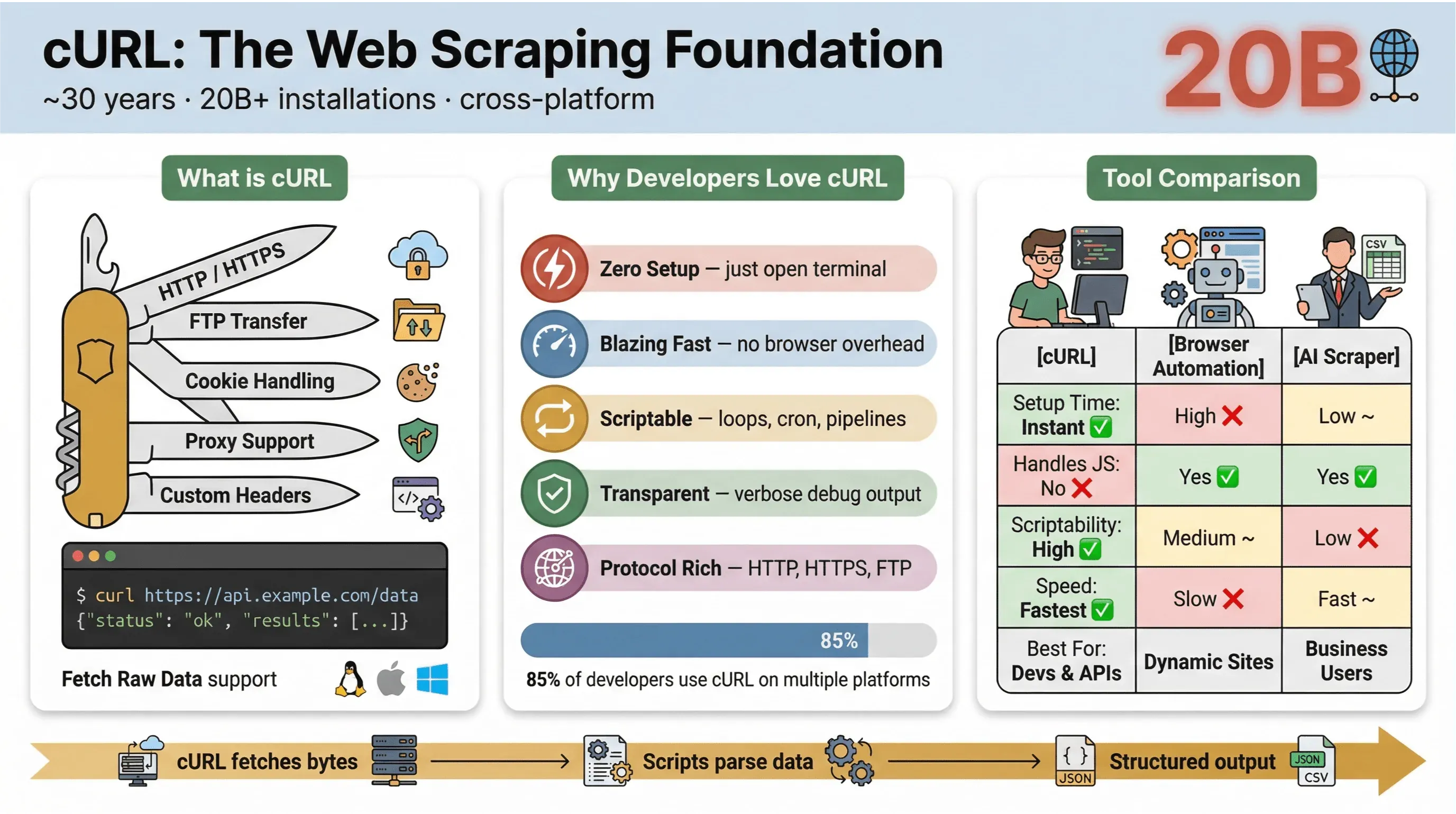 Iată de ce cURL este atât de popular pentru web scraping:
Iată de ce cURL este atât de popular pentru web scraping:
- Ușor și multiplatformă: rulează pe Linux, macOS, Windows și chiar pe dispozitive embedded.
- Suport pentru protocoale: gestionează HTTP, HTTPS, FTP și multe altele.
- Ușor de integrat în scripturi: perfect pentru automatizare, taskuri cron și cod de legătură.
- Nu necesită interacțiune cu utilizatorul: este gândit pentru utilizare non-interactivă — ideal pentru joburi în lot și pipeline-uri.
Dar să fim clari: rolul principal al cURL este să preia date brute — HTML, JSON, imagini, orice ai nevoie. Nu parsează, nu redă și nu structurează datele pentru tine. Gândește-te la cURL ca la „primul kilometru” din web scraping: îți aduce bytes-ii, dar ai nevoie de alte instrumente (cum ar fi scripturi Python, grep/sed/awk sau un AI web scraper) ca să transformi totul în informații structurate.
Dacă vrei să vezi documentația oficială, consultă ghidul cURL pentru scripting HTTP.
De ce să folosești cURL pentru web scraping? (tutorial de web scraping cu curl)
Așadar, de ce revin dezvoltatorii și utilizatorii tehnici mereu la cURL pentru web scraping, chiar și cu toate uneltele noi apărute? Iată ce îl face să iasă în evidență:
- Configurare minimă: fără instalări, fără dependențe — deschizi terminalul și ai pornit.
- Viteză: preiei date instant, fără să aștepți încărcarea unui browser.
- Posibilitatea de a-l integra în scripturi: poți itera ușor prin URL-uri, automatiza cereri și concatena comenzi.
- Suport pentru protocoale și funcții: cookie-uri, proxy-uri, redirecturi, headere personalizate și multe altele.
- Transparență: vezi exact ce se întâmplă cu outputul verbose/debug.
În sondajul cURL din 2025, 85,7% dintre respondenți au spus că folosesc utilitarul cURL din linia de comandă, iar 96,2% au raportat că îl folosesc pe Linux — încă de departe platforma principală pentru cURL.
--- Încă este briceagul elvețian pentru cereri HTTP, preluări rapide de date și depanare.
Iată o comparație rapidă între cURL și alte metode de scraping:
| Caracteristică | cURL | Automatizare în browser (de ex., Selenium) | AI Web Scraper (de ex., Thunderbit) |
|---|---|---|---|
| Timp de configurare | Instant | Ridicat | Redus |
| Posibilitate de scripting | Ridicată | Medie | Redusă (nu necesită cod) |
| Gestionează JavaScript | Nu | Da | Da (Thunderbit: prin browser) |
| Suport cookie-uri/sesiuni | Manual | Automat | Automat |
| Structurare date | Manual (parsezi ulterior) | Manual (parsezi ulterior) | Bazată pe AI/șabloane |
| Cel mai bun pentru | Dezvoltatori, preluări rapide | Site-uri complexe, dinamice | Utilizatori business, export structurat |
Pe scurt: cURL este greu de întrecut când vrei preluări rapide de date, ușor de automatizat — mai ales pentru pagini statice, API-uri sau când vrei să automatizezi fluxuri simple. Dar, imediat ce ai nevoie să parsezi HTML complex, să gestionezi JavaScript sau să exporți date structurate, îți va trebui ceva mai specializat.
Primii pași: exemple de comenzi cURL pentru web scraping de bază
Hai să trecem la practică. Iată cum folosești cURL pentru sarcini simple de web scraping, pas cu pas.
Preluarea HTML-ului brut cu cURL
Cel mai simplu caz de utilizare: preiei HTML-ul unei pagini web.
curl https://books.toscrape.com/
Această comandă preia pagina principală de pe Books to Scrape, un site demo public pentru web scraping. Vei vedea outputul HTML brut în terminal — caută taguri precum <title> sau fragmente ca „In stock”.
Salvarea outputului într-un fișier
Vrei să salvezi acel HTML pentru parsare ulterioară? Folosește opțiunea -o:
curl -o page.html https://books.toscrape.com/
Acum vei avea un fișier page.html cu conținutul HTML complet. Este perfect pentru analiză ulterioară sau parsare cu alte unelte.
Trimiterea de cereri POST cu cURL
Ai nevoie să trimiți un formular sau să interacționezi cu un API? Folosește opțiunea -d pentru cereri POST. Iată un exemplu cu httpbin, un site creat pentru testare HTTP:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Vei primi un răspuns JSON care reflectă datele trimise — foarte util pentru testare și prototipare.
Inspectarea headerelor și depanarea
Uneori vrei să vezi headerele răspunsului sau să depanezi cererea:
-
Doar headerele (cerere HEAD):
curl -I https://books.toscrape.com/ -
Include headerele împreună cu body-ul:
curl -i https://httpbin.org/get -
Output verbose/debug:
curl -v https://books.toscrape.com/
Aceste opțiuni te ajută să înțelegi ce se întâmplă în spate — esențial pentru depanare.
Iată un tabel de referință rapid pentru aceste comenzi:
| Sarcină | Exemplu de comandă | Observații |
|---|---|---|
| Preia HTML | curl URL | Afișează HTML-ul în terminal |
| Salvează într-un fișier | curl -o file.html URL | Scrie outputul în fișier |
| Inspectează headerele | curl -I URL sau curl -i URL | -I pentru HEAD doar, -i include headerele cu body-ul |
| Trimite date de formular | curl -d "a=1&b=2" URL | Trimite date codificate ca formular |
| Depanează cererea/răspunsul | curl -v URL | Afișează informații detaliate despre cerere/răspuns |
Pentru mai multe exemple, consultă documentația oficială cURL pentru scripting.
Nivel mai avansat: web scraping avansat cu cURL (web scraping cu curl)
După ce te obișnuiești cu bazele, cURL îți deschide o lume de funcții avansate pentru sarcini de scraping mai complexe.
Gestionarea cookie-urilor și a sesiunilor
Multe site-uri au nevoie de cookie-uri pentru a menține sesiunea de autentificare sau pentru a urmări utilizatorii. Cu cURL, poți salva și refolosi cookie-urile între cereri:
# Salvează cookie-urile după autentificare
curl -c cookies.txt https://example.com/login
# Folosește cookie-urile pentru cereri ulterioare
curl -b cookies.txt https://example.com/account
Asta îți permite să mimezi sesiunile de browser și să accesezi pagini din spatele unui login (atât timp cât nu există o provocare JavaScript).
Spoofing pentru User-Agent și headere personalizate
Unele site-uri afișează conținut diferit în funcție de User-Agent sau headere. Implicit, cURL se identifică drept „curl/VERSION”, ceea ce poate declanșa blocări sau conținut alternativ. Ca să mimezi un browser:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Poți seta și headere personalizate, cum ar fi preferințele de limbă:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Asta te ajută să obții același conținut pe care l-ar vedea un browser real.
Folosirea proxy-urilor pentru web scraping
Ai nevoie să redirecționezi cererile printr-un proxy (pentru testare geo sau ca să eviți blocarea IP-ului)? Folosește opțiunea -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Asigură-te doar că folosești proxy-uri responsabil și în limitele termenilor de utilizare ai site-ului.
Automatizarea scrapingului pe mai multe pagini
Vrei să extragi mai multe pagini — de exemplu, liste de produse paginante? Folosește o buclă simplă în shell:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Asta preia paginile 2 până la 5 din catalogul Books to Scrape și salvează fiecare pagină într-un fișier separat. (Pagina 1 este pagina principală.)
Limitele web scraping cu curl: ce trebuie să știi
Oricât de mult îmi place cURL, nu este o soluție universală. Iată unde are limite:
- Nu execută JavaScript: cURL nu poate gestiona paginile care au nevoie de JavaScript pentru a afișa conținutul sau pentru a trece de provocări anti-bot (developers.cloudflare.com).
- Necesită parsare manuală: primești HTML sau JSON brut, dar trebuie să le parsezi singur — de obicei cu scripturi sau unelte suplimentare.
- Gestionare limitată a sesiunilor: loginurile complexe, tokenurile sau formularele în mai mulți pași pot deveni rapid greu de întreținut.
- Nu structurează datele automat: cURL nu transformă paginile web în rânduri, tabele sau foi de calcul.
- Vulnerabil la detecția anti-bot: multe site-uri folosesc acum mecanisme avansate de protecție împotriva boților (JavaScript, fingerprinting, CAPTCHA) pe care cURL pur și simplu nu le poate ocoli (datadome.co).
Iată un tabel comparativ rapid:
| Limitare | cURL singur | Unelte moderne de scraping (de ex., Thunderbit) |
|---|---|---|
| Suport JavaScript | Nu | Da |
| Structurare date | Manual | Automat (AI/șablon) |
| Gestionarea sesiunilor | Manual | Automat |
| Ocolirea anti-bot | Limitată | Avansată (bazată pe browser/AI) |
| Ușurință în utilizare | Tehnică | Fără cunoștințe tehnice |
Pentru pagini statice și API-uri, cURL este excelent. Pentru orice este mai dinamic sau mai bine protejat, vei vrea să treci la un nivel superior în lanțul de unelte.
Thunderbit vs. cURL: cea mai bună abordare pentru utilizatorii non-tehnici
Acum să vorbim despre Thunderbit, extensia noastră Chrome de web scraper bazată pe AI. Dacă ești agent de vânzări, marketer sau profesionist din operațiuni și vrei doar să muți date dintr-un site în Excel, Google Sheets sau Notion — fără să atingi linia de comandă — Thunderbit a fost construit pentru tine.
Iată cum se compară Thunderbit cu cURL:
| Caracteristică | cURL | Thunderbit |
|---|---|---|
| Interfață utilizator | Linie de comandă | Point-and-click (extensie Chrome) |
| Sugestii AI pentru câmpuri | Nu | Da (AI citește pagina și sugerează coloane) |
| Gestionează paginare/subpagini | Scripting manual | Automat (AI detectează și extrage) |
| Export de date | Manual (parsezi + salvezi) | Direct în Excel, Google Sheets, Notion, Airtable |
| Paginile cu JavaScript/protejate | Nu | Da (scraping în browser) |
| Fără cod necesar | Nu (necesită scripting) | Da (poate fi folosit de oricine) |
| Nivel gratuit | Mereu gratuit | Gratuit până la 6 pagini (10 cu trial boost) |
Cu Thunderbit, deschizi extensia, dai clic pe „AI Suggest Fields” și lași AI-ul să decidă ce date să extragă. Poți extrage tabele, liste, detalii despre produse și chiar să navighezi automat prin subpagini. Apoi, exporți datele direct în uneltele tale de business preferate — fără parsare, fără bătăi de cap.
Thunderbit este folosit cu încredere de peste 100.000 de utilizatori din întreaga lume și este deosebit de popular în rândul echipelor de vânzări, ecommerce și real estate care au nevoie rapid de date structurate.
Încearcă extensia Chrome Thunderbit pentru web scraping
Vrei să-l încerci? Descarcă extensia Chrome de aici.
Combinarea cURL și Thunderbit: strategii flexibile de web scraping
Dacă ești utilizator tehnic, nu trebuie să alegi un singur instrument. De fapt, multe echipe folosesc împreună cURL și Thunderbit pentru flexibilitate maximă:
- Fă prototiparea cu cURL: folosește cURL ca să testezi rapid endpoint-uri, să inspectezi headerele și să înțelegi cum răspunde site-ul.
- Scalează cu Thunderbit: când ai nevoie de date structurate, scraping pe mai multe pagini sau un flux repetabil, treci la Thunderbit pentru extracție point-and-click și export direct.
Iată un flux de lucru exemplu pentru research de piață:
- Folosește cURL ca să preiei câteva pagini și să inspectezi structura HTML.
- Identifică câmpurile de date pe care le vrei (de ex., nume de produse, prețuri, recenzii).
- Deschide Thunderbit, dă clic pe „AI Suggest Fields” și lasă AI-ul să configureze scraperul.
- Extrage toate paginile (inclusiv subpagini sau liste paginante) și exportă în Google Sheets.
- Analizează, distribuie și acționează pe baza datelor — fără parsare manuală.
Iată un tabel rapid de decizie:
| Scenariu | Folosește cURL | Folosește Thunderbit | Folosește ambele |
|---|---|---|---|
| Preluare rapidă de API sau pagină statică | ✅ | ||
| Ai nevoie de date structurate în foaie | ✅ | ||
| Depanarea headerelor/cookie-urilor | ✅ | ||
| Extracția paginilor dinamice, cu mult JS | ✅ | ||
| Construirea unui flux repetabil, no-code | ✅ | ||
| Prototipare, apoi scalare | ✅ | ✅ | Flux hibrid |
Provocări obișnuite și capcane în web scraping cu cURL
Înainte să te avânți prea tare cu cURL, hai să discutăm despre provocările reale pe care le vei întâlni:
- Sisteme anti-bot: multe site-uri folosesc acum mecanisme avansate de protecție (provocări JavaScript, CAPTCHA, fingerprinting) pe care cURL nu le poate ocoli (developers.cloudflare.com).
- Probleme de calitate a datelor: schimbările în HTML, câmpurile lipsă sau layouturile inconsistente îți pot strica scripturile.
- Costuri de întreținere: de fiecare dată când un site se schimbă, trebuie să actualizezi logica de parsare.
- Riscuri legale și de conformitate: verifică întotdeauna termenii de utilizare ai site-ului, robots.txt și legislația relevantă înainte de a extrage date. Doar pentru că datele sunt publice nu înseamnă că le poți folosi oricum (calawyers.org, polsinelli.com).
- Limite de scalare: cURL este excelent pentru sarcini mici, dar pentru scraping la scară mare va trebui să gestionezi proxy-uri, rate limits și tratarea erorilor.
Sfaturi pentru depanare și conformitate:
- Începe mereu cu site-uri permise sau demo (cum ar fi Books to Scrape).
- Respectă limitele de rate — nu bombarda endpoint-urile.
- Evită extragerea datelor personale dacă nu ai un temei legal.
- Dacă te lovești de bariere JavaScript sau CAPTCHA, ia în calcul trecerea la o unealtă bazată pe browser, precum Thunderbit.
Rezumat pas cu pas: cum să extragi date de pe site-uri cu cURL
Iată checklistul tău rapid pentru web scraping cu curl:
- Identifică URL-ul/URL-urile țintă: începe cu o pagină statică sau un endpoint API.
- Preia pagina:
curl URL - Salvează outputul într-un fișier:
curl -o file.html URL - Inspectează headerele / depanează:
curl -I URL,curl -v URL - Trimite date POST:
curl -d "a=1&b=2" URL - Gestionează cookie-urile / sesiunile:
curl -c cookies.txt ...,curl -b cookies.txt ... - Setează headere personalizate / User-Agent:
curl -A "..." -H "..." URL - Urmează redirecturile:
curl -L URL - Folosește proxy-uri (dacă este nevoie):
curl -x proxy:port URL - Automatizează scrapingul pe mai multe pagini: folosește bucle shell sau scripturi.
- Parsează și structurează datele: folosește unelte/scripturi suplimentare, după nevoie.
- Treci la Thunderbit pentru scraping structurat, no-code sau pentru pagini dinamice.
Concluzie și idei cheie: alegerea instrumentului potrivit pentru web scraping
Extrage date de pe orice site folosind AI Get Started Free
Web scraping cu cURL rămâne o abilitate foarte puternică pentru utilizatorii tehnici în 2026 — mai ales pentru preluări rapide de date, prototipare și automatizare. Viteza, posibilitatea de scripting și omniprezența lui cURL îl fac o piesă de bază în trusa oricărui dezvoltator. Dar, pe măsură ce web-ul devine mai dinamic și mai bine protejat, iar utilizatorii de business cer date structurate fără cod, unelte precum Thunderbit schimbă regulile jocului.
Idei cheie:
- Folosește cURL pentru pagini statice, API-uri și prototipare rapidă — mai ales când vrei control total.
- Treci la Thunderbit (sau la alte AI web scrapers similare) când ai nevoie de date structurate, trebuie să gestionezi pagini dinamice / cu mult JavaScript sau vrei un flux no-code, potrivit pentru business.
- Combină-le pe ambele pentru flexibilitate maximă: prototipează cu cURL, apoi scalează și structurează cu Thunderbit.
- Extrage date responsabil — respectă termenii site-ului, limitele de rată și granițele legale.
Vrei să vezi cât de ușor poate fi web scraping-ul? Încearcă extensia Chrome gratuită de la Thunderbit și experimentează singur extracția de date cu AI. Iar dacă vrei să mergi mai departe, consultă blogul Thunderbit pentru mai multe tutoriale, sfaturi și perspective din industrie. S-ar putea să-ți placă și:
- Cum să extragi date de pe orice site folosind AI
- Cum să extragi date de pe un site în Excel folosind AI
- Ce este data scraping și cum îl faci în 2025
Scraping plăcut — și fie ca datele tale să fie mereu curate, structurate și la doar o comandă (sau un clic) distanță.
Explorează planurile Thunderbit pentru web scraping la scară
Întrebări frecvente
1. Poate cURL să gestioneze pagini web randate cu JavaScript?
Nu, cURL nu poate executa JavaScript. El preia HTML-ul brut, exact cum este livrat de server. Dacă o pagină are nevoie de JavaScript pentru a afișa conținutul sau pentru a trece de provocări anti-bot, cURL nu va putea accesa datele. În astfel de cazuri, folosește unelte bazate pe browser, precum Thunderbit.
2. Cum salvez outputul cURL direct într-un fișier?
Folosește opțiunea -o: curl -o filename.html URL. Aceasta scrie corpul răspunsului într-un fișier, în loc să-l afișeze în terminal.
3. Care este diferența dintre cURL și Thunderbit pentru web scraping?
cURL este un utilitar din linia de comandă pentru preluarea datelor web brute — excelent pentru utilizatori tehnici și automatizare. Thunderbit este o extensie Chrome bazată pe AI, creată pentru utilizatori de business care vor să extragă date structurate de pe orice site, să gestioneze pagini dinamice și să exporte direct în unelte precum Excel sau Google Sheets — fără cod.
4. Este legal să extragi date de pe site-uri cu cURL?
Extragerea datelor publice este, în general, legală în SUA după decizii judiciare recente, dar verifică mereu termenii de utilizare ai site-ului, robots.txt și legislația relevantă. Evită să extragi date personale sau protejate fără permisiune și respectă limitele de rată și principiile etice (calawyers.org, polsinelli.com).
5. Când ar trebui să trec de la cURL la o unealtă mai avansată, precum Thunderbit?
Dacă ai nevoie să extragi pagini dinamice, încărcate cu JavaScript, vrei date structurate într-o foaie de calcul sau preferi un flux no-code, Thunderbit este alegerea mai bună. Folosește cURL pentru sarcini rapide, tehnice; folosește Thunderbit pentru extracție de date repetabilă, potrivită pentru business.
Pentru mai multe sfaturi și tutoriale despre web scraping, vizitează blogul Thunderbit sau consultă canalul nostru de YouTube.
Încearcă AI Web Scraper de la Thunderbit Get Started Free




