Este web scraping-ul ilegal? Aceasta este întrebarea de un milion de dolari pe care o aud în fiecare săptămână de la fondatori, marketeri și pasionați de date.
Cu — pentru prima dată când traficul automat l-a depășit pe cel generat de oameni — și cu o mare parte din acest volum dedicată web scraping-ului pentru business intelligence, vânzări și antrenarea AI, nu e de mirare că toată lumea încearcă să înțeleagă unde se trasează liniile legale.
Într-o zi vezi un titlu despre o hotărâre judecătorească ce spune că extragerea datelor publice este permisă. În ziua următoare, autoritățile avertizează despre colectarea „ilegală” de date de pe rețelele sociale. E confuz, chiar și pentru oameni ca mine, care își petrec zilele construind instrumente AI de web scraping la .
Așadar, este web scraping-ul ilegal? Răspunsul nu este un simplu da sau nu. Depinde de ce extragi, de unde extragi, cum folosești datele și ce spune legea din țara ta.
În această analiză aprofundată, voi descompune peisajul juridic, voi demonta câteva mituri comune și voi împărtăși sfaturi practice (plus câteva povești din teren) pentru a rămâne în conformitate — fie că ești un fondator solo sau o echipă de date dintr-o companie Fortune 500.
Web scraping și legea: există o linie clară?
Dacă speri la un răspuns într-o singură propoziție, îți economisesc timp: legea nu a trasat o linie clară și ușor de văzut pentru web scraping.
În schimb, există un mozaic de reguli care se suprapun — proprietatea datelor, confidențialitatea, proprietatea intelectuală, legile anti-hacking și celebra categorie a Termenilor de utilizare (ToS). Fiecare poate intra în joc, iar răspunsul depinde adesea de scenariul tău concret ().
Să împărțim lucrurile în trei mari categorii juridice:
- Proprietatea datelor: În general, faptele și informațiile publice (cum ar fi prețurile sau numerele de telefon) nu pot fi protejate prin copyright. Dar conținutul creativ (articole, imagini) și bazele de date proprietare pot fi protejate — mai ales în UE, unde există „drepturi asupra bazelor de date” ().
- Confidențialitatea: Legile moderne privind protecția datelor (gândește-te la GDPR în Europa, PIPL în China) tratează datele personale ca pe un activ reglementat — chiar dacă sunt publicate deschis. Extragerea de nume, e-mailuri sau profiluri sociale fără un temei legal te poate aduce în dificultate ().
- Contractele (Termenii de utilizare): Multe site-uri interzic explicit scraping-ul în ToS. Deși ToS nu sunt legi, instanțele le pot trata ca pe contracte obligatorii. Încălcarea lor poate duce la procese și, în unele cazuri, poate declanșa chiar și statute anti-hacking dacă ocolești blocajele tehnice ().
Așadar, este web scraping-ul ilegal? Uneori da, alteori nu, și adesea „depinde”. Diavolul stă în detalii.
Comparație între perspectivele juridice: SUA, UE, UK, China
Iată un tabel rapid care arată cum abordează marile regiuni web scraping-ul:
| Regiune | Scraping de date publice | Scraping de date personale/private | Aplicare și aspecte notabile |
|---|---|---|---|
| SUA | În general permis pentru date publice (vezi hiQ v. LinkedIn). Încălcarea ToS poate duce la procese civile. | Restricționat/ilegal dacă ocolești autentificarea sau folosești abuziv date personale. Se pot aplica legi la nivel de stat (cum ar fi CCPA). | Scrisori de încetare și renunțare, blocare IP, procese. CFAA se aplică dacă ocolești barierele tehnice. |
| UE | Permis condiționat pentru date publice, nepersonale. Pot exista drepturi asupra bazelor de date. Legea UE privind AI (2026) adaugă cerințe de transparență pentru datele de antrenare AI. | Puternic reglementat prin GDPR — chiar și datele personale publice au nevoie de un temei legal. | Autoritățile de protecție a datelor pot amenda încălcările de confidențialitate. Se aplică și drepturile de autor/drepturile asupra bazelor de date. Legea UE privind AI interzice extragerea imaginilor faciale pentru AI. |
| UK | Similar UE. Datele publice, nepersonale pot fi extrase, dar trebuie respectate drepturile asupra datelor și contractele. | Strict pentru date personale — se aplică UK GDPR. Computer Misuse Act incriminează accesul neautorizat. | ICO poate sancționa încălcările de protecție a datelor. Instanțele pot aplica ToS. |
| China | Strict controlat. Datele publice, nepersonale pot fi extrase pentru uz intern, dar mediul este precaut. | Foarte restricționat — PIPL cere consimțământ pentru datele personale. Se aplică și legile anti-concurență neloială. | Cazuri penale pentru scraping la scară largă. Instanțele folosesc legea concurenței neloiale pentru a opri scraping-ul neautorizat. |
(, )
Este web scraping-ul ilegal? Factorii juridici cheie de luat în calcul
Deci, ce determină de fapt dacă proiectul tău de scraping este legal sau riscant? Iată factorii importanți:
- Date publice vs. private: Extragerea datelor pe care oricine le poate vedea pe web-ul deschis este, în general, mai sigură. Extragi ceva aflat în spatele unui login, paywall sau bariere tehnice? Probabil este ilegal ().
- Natura datelor: Datele personale (nume, e-mailuri, profiluri) activează legile privind confidențialitatea. Conținutul protejat prin copyright (articole, imagini) nu poate fi copiat integral. Faptele pure (prețuri, vreme) sunt, de obicei, permisibile ().
- Scopul urmărit: Analiza internă sau cercetarea sunt privite mai indulgent decât republicarea ori vânzarea datelor extrase. Folosirea datelor extrase pentru a concura direct cu sursa? Asta înseamnă un proces care abia așteaptă să se întâmple ().
- Respectarea regulilor site-ului: Verifică întotdeauna robots.txt și ToS. Robots.txt nu este obligatoriu din punct de vedere legal, dar este o bună practică să îl respecți. Încălcarea ToS poate însemna procese civile sau mai rău ().
- Măsuri tehnice: Extragerea la viteze asemănătoare celor umane și fără ocolirea măsurilor de securitate este esențială. Bombardarea unui server sau evitarea CAPTCHA-urilor poate trece linia în zona hacking-ului ().
Ce s-a schimbat în 2024–2026: cazuri judiciare și reglementări importante
Peisajul juridic al web scraping-ului s-a schimbat dramatic din 2023 încoace. Iată evoluțiile pe care orice scraper trebuie să le cunoască:
Hotărâri majore ale instanțelor
-
Meta v. Bright Data (2024): O instanță federală din SUA . Judecătorul a constatat că „un vizitator nu este considerat «utilizator» decât dacă are un cont”. Meta a retras la scurt timp cererile rămase. Aceasta este o victorie importantă pentru scraping-ul datelor publice.
-
X Corp v. Bright Data (2024): Twitter (acum X) a pierdut un proces similar, întărind același principiu: extragerea datelor accesibile public fără autentificare nu încalcă ToS, deoarece scraperul nu a acceptat niciodată acești termeni.
-
Reddit v. Perplexity AI (octombrie 2025): Reddit , invocând DMCA și susținând eludarea sistemelor anti-bot. Acest lucru semnalează o nouă strategie juridică: platformele se îndreaptă către pretenții bazate pe copyright și anti-eludare, în locul CFAA.
-
NYT v. OpenAI (martie 2025): Un judecător federal , respingând cererea OpenAI de a respinge acțiunea. Acest lucru ar putea stabili un precedent major privind dacă scraping-ul de conținut pentru antrenarea modelelor AI se încadrează la „fair use”.
-
Acordul Anthropic (septembrie 2025): Anthropic a acceptat să plătească 1,5 miliarde de dolari pentru a închide o acțiune colectivă din SUA privind folosirea textelor protejate prin copyright pentru antrenarea modelului său AI — semn că costurile scraping-ului pentru AI sunt foarte reale.
Tendința majoră: de la CFAA la dreptul contractual și al copyright-ului
Modelul este clar: CFAA (Computer Fraud and Abuse Act) își pierde din forță ca armă împotriva celor care extrag date publice. Companiile care au încercat să folosească CFAA împotriva scraping-ului de date publice — Meta, X, LinkedIn — au eșuat în mare parte. În schimb, terenul juridic se mută către:
- dreptul contractual (încălcări ale ToS — dar instanțele spun că neutilizatorii nu sunt obligați de ToS)
- pretenții de copyright (mai ales pentru datele de antrenare AI)
- statute anti-eludare (DMCA Secțiunea 1201)
Pentru cei care fac scraping, asta înseamnă că riscul juridic nu a dispărut — doar s-a mutat.
Schimbări de reglementare
- Actualizări CCPA 2026: Regulamentele revizuite din California privind CCPA , adăugând reguli noi pentru tehnologia de luare automată a deciziilor (ADMT), evaluările de risc și obligațiile brokerilor de date.
- Noi legi de confidențialitate la nivel de stat în SUA: Indiana, Kentucky și Rhode Island au adoptat legi cuprinzătoare privind protecția datelor, aplicabile din 2026.
- Legea UE privind AI: Aplicarea completă începe — cerând dezvoltatorilor de AI să dezvăluie sursele datelor de antrenare, să respecte opțiunile de excludere a copyright-ului și interzicând extragerea imaginilor faciale pentru sistemele AI.
- AI Accountability for Publishers Act (februarie 2026): O propunere de lege din SUA care ar obliga companiile de AI să ceară permisiune și să plătească editorii înainte de a le extrage conținutul.
Politicile de scraping ale marilor platforme: ce trebuie să știi
Nu toate site-urile tratează scraping-ul la fel. Iată o analiză platformă cu platformă a ceea ce permit cele mai mari site-uri, ce blochează și ce au spus instanțele:
| Platformă | ToS despre scraping | Apărări tehnice | Aplicare juridică | Ce este sigur în practică |
|---|---|---|---|---|
| Google (Search & Maps) | Interzice accesul automat în ToS. Platforma Maps are o clauză explicită „No Scraping”. | Provocări SearchGuard JS, CAPTCHA, limitare de rată. robots.txt actualizat în 2025 pentru a bloca crawler-ele AI. | A dat în judecată scrapers în decembrie 2025 folosind DMCA. Blochează activ crawler-ele AI (Anthropic, Meta, OpenAI). | Extragerea datelor publice despre afaceri din Google Maps este defensabilă juridic (precedentul hiQ), dar așteaptă-te la blocaje tehnice. Folosește API-urile oficiale când este posibil. |
| Amazon | Interzice explicit tot scraping-ul în Conditions of Use („fără robot, spider, scraper sau alte mijloace automate”). | Detecție agresivă a boților, CAPTCHA, blocare IP. robots.txt blochează toți boții, cu excepția Googlebot/Bingbot. Blochează explicit crawler-ele AI din 2025. | A dat în judecată Perplexity AI în noiembrie 2025. Trimite regulat scrisori de încetare și renunțare. A actualizat BSA în martie 2026 cu reguli pentru agenți AI. | Datele publice despre produse (prețuri, listări) sunt fapte și pot fi extrase conform legislației SUA, dar Amazon ripostează dur. Limitează ritmul cererilor și evită datele personale. |
| Interzice scraping-ul în ToS; pentru acces la servicii este necesar acordul utilizatorului. | Pereți de autentificare pentru majoritatea datelor de profil, detecție anti-bot, limitare de rată. | Cazul hiQ a confirmat că scraping-ul profilurilor publice nu încalcă CFAA, dar LinkedIn a câștigat pe contract și concurență neloială atunci când au fost folosite conturi false. | Profilurile publice (vizibile fără autentificare) sunt defensabile juridic pentru scraping. Nu crea niciodată conturi false și nu extrage date din zone autentificate. | |
| Meta (Facebook & Instagram) | ToS interzic scraping-ul; reguli separate pentru date autentificate vs. neautentificate. | Pereți de autentificare pentru majoritatea conținutului, detecție avansată anti-bot. | A pierdut în fața Bright Data în 2024 — instanța a decis că ToS nu se aplică scraperelor neautentificate. A retras cererile rămase. | Datele publice (pagini de business, postări publice) vizibile fără autentificare sunt într-o poziție mai sigură. Nu extrage niciodată profiluri private sau date din spatele autentificării. |
| X (Twitter) | A actualizat ToS în 2023 pentru a interzice tot scraping-ul și crawling-ul fără consimțământ scris. A eliminat vechea excepție din robots.txt. | robots.txt blochează toți crawlerii (Disallow: /). Provocări Cloudflare Turnstile. Limite stricte de rată (300 cereri/oră). Scorare a reputației IP-ului. | A pierdut în fața Bright Data pe date publice, dar limitează agresiv accesul tehnic. | Tweet-urile și profilurile publice sunt defensabile juridic, dar barierele tehnice ale X sunt printre cele mai dure în 2026. Așteaptă-te la blocaje fără infrastructură proxy premium. |
Ideea principală: Instanțele au decis constant că scraping-ul datelor vizibile public, fără autentificare, nu încalcă CFAA. Dar platformele te pot urmări în continuare pe baza dreptului contractual, a copyright-ului sau a legilor anti-eludare — și îți vor complica viața prin bariere tehnice. Fă scraping responsabil.
Datele de antrenare AI și web scraping-ul: noua frontieră juridică
Dacă urmărești știrile din 2026, știi deja că extragerea datelor pentru antrenarea modelelor AI a devenit cel mai fierbinte câmp de luptă juridic. Iată ce se întâmplă:
- Procesele pe copyright se adună. New York Times, autori și editori au dat în judecată OpenAI, Anthropic și alții, susținând că scraping-ul în masă al conținutului protejat pentru antrenarea LLM-urilor nu este „fair use”. Anthropic a încheiat un acord major într-o acțiune colectivă pentru 1,5 miliarde de dolari în 2025 — semn că costurile scraping-ului pentru AI sunt foarte reale.
- Apărarea prin „fair use” este fragilă. Instanțele din SUA nu au emis încă o hotărâre definitivă privind dacă antrenarea AI pe date extrase intră la fair use. Primele decizii sugerează că totul depinde mult de cum au fost obținute datele și de ce se face cu rezultatul AI.
- Se pregătește legislație nouă. (introdusă în februarie 2026) urmărește să oblige companiile AI să ceară permisiune și să plătească editorii înainte de a le extrage conținutul.
- Legea UE privind AI (aplicare completă ) cere dezvoltatorilor de AI să dezvăluie sursele datelor de antrenare, să respecte opțiunile de excludere a copyright-ului lizibile de mașini (în cadrul excepției TDM din Directiva Copyright) și să eticheteze conținutul generat de AI. De asemenea, interzice sistemele AI care extrag imagini faciale de pe internet.
- Crawler-ele AI/LLM explodează. Crawler-ele AI și-au cvadruplat cota din traficul web, de la 2,6% la 10,1%, în doar opt luni. Doar GPTBot de la OpenAI a crescut cu 305%. Ca reacție, site-urile mari (Amazon, Reddit, NYT) își actualizează robots.txt pentru a bloca explicit crawler-ele AI.
Ce înseamnă asta pentru tine: Dacă extragi date pentru scopuri clasice de business (generare de lead-uri, monitorizarea prețurilor, cercetare de piață), aceste reguli specifice AI s-ar putea să nu se aplice direct. Dar dacă trimiți datele extrase către modele AI, mergi foarte atent — și cere sfat juridic.
Legile web scraping-ului în lume: o comparație rapidă
Să privim imaginea de ansamblu și să vedem cum se așază regulile la nivel global:
- Statele Unite: Nu există o interdicție generală. Scraping-ul site-urilor publice este, în general, legal (), iar hotărârile Meta și X Corp din 2024 au întărit și mai mult argumentul pentru scraping-ul datelor publice. Dar scraping-ul din spatele autentificării sau al barierelor tehnice poate declanșa în continuare CFAA. Tendința actuală este ca firmele să folosească mai degrabă dreptul contractual și pretențiile de copyright. Legile privind confidențialitatea se extind rapid: CCPA a primit actualizări importante, valabile de la 1 ianuarie 2026, inclusiv reguli noi pentru luarea automată a deciziilor și obligațiile brokerilor de date. Indiana, Kentucky și Rhode Island au adoptat de asemenea legi cuprinzătoare privind confidențialitatea în 2026.
- Uniunea Europeană: Legi stricte privind confidențialitatea. GDPR se aplică și datelor personale publice. Drepturile asupra bazelor de date pot bloca scraping-ul la scară largă al datelor structurate (). NOU: intră în aplicare completă la 2 august 2026, cerând dezvoltatorilor de AI să dezvăluie sursele datelor de antrenare și să respecte opțiunile de excludere a copyright-ului. Legea interzice scraping-ul imaginilor faciale de pe internet pentru sistemele AI.
- Regatul Unit: Urmează regulile UE după Brexit. Datele publice pot fi extrase, dar extragerea informațiilor personale este strict reglementată. Computer Misuse Act poate incrimina accesul neautorizat.
- China: Foarte restrictivă. PIPL și Data Security Law cer consimțământ pentru datele personale. Instanțele folosesc legea concurenței neloiale pentru a bloca scraping-ul care afectează afacerile ().
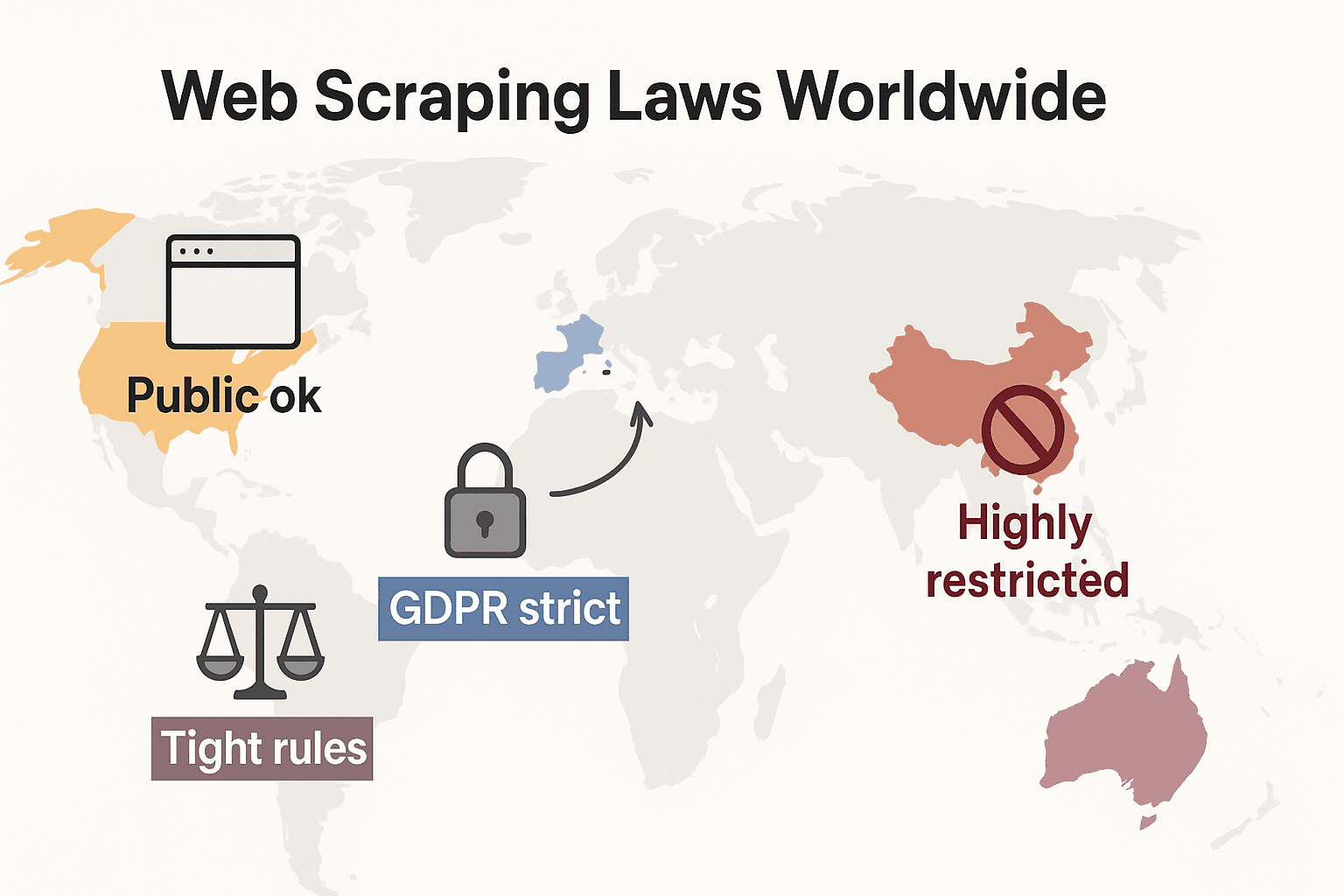
Concluzia: scraping-ul datelor publice, nepersonale, pentru uz intern este, în general, cel mai sigur. Altceva? Verifică legile locale și mergi cu prudență.
Mituri comune despre legalitatea web scraping-ului
Să demontăm câteva mituri pe care le aud tot timpul:
- Mitul 1: „Web scraping-ul este ilegal, punct.”
Fals. Nu există nicio lege care să interzică tot web scraping-ul. Contează cum și ce extragi (). - Mitul 2: „Dacă datele sunt publice, pot face orice vreau cu ele.”
Nu chiar. Datele publice pot fi în continuare protejate de legile privind confidențialitatea sau copyright-ul, iar ToS pot restricționa anumite utilizări (). - Mitul 3: „Web scraping-ul este la fel ca hacking-ul.”
Nu. Extragerea paginilor web publice nu este hacking. Ocolirea autentificării sau a barierelor tehnice este altceva (). - Mitul 4: „Dacă nu sunt prins, e în regulă.”
Gândire riscantă. Multe site-uri folosesc tehnologie anti-bot și vor observa. Tăcerea nu înseamnă consimțământ. - Mitul 5: „Dacă dau credit sau folosesc datele intern, e ok.”
Atribuirea nu anulează legea copyright-ului sau a confidențialității. Utilizarea internă este mai sigură, dar nu îți oferă liberă trecere. - Mitul 6: „Tot web scraping-ul încalcă viața privată.”
Nu orice scraping implică date personale. Dar extragerea unui volum mare de informații personale fără măsuri de protecție este aproape întotdeauna ilegală (). - Mitul 7: „Dacă ToS-ul unui site interzice scraping-ul, atunci e mereu ilegal să faci scraping.”
Nu neapărat. În 2024, instanțele au decis în Meta v. Bright Data și X Corp v. Bright Data că ToS nu îi pot obliga pe utilizatorii care nu au acceptat niciodată acei termeni — adică dacă extragi date fără autentificare sau fără să creezi un cont, ToS-ul site-ului s-ar putea să nu ți se aplice. Încă este un domeniu în dezvoltare, dar schimbarea este importantă.
Cum să extragi date legal: bune practici pentru conformitate
Iată checklist-ul meu preferat pentru web scraping legal și etic:
- Citește și respectă Termenii de utilizare ai site-ului. Dacă spun „fără scraping”, ia în calcul să te oprești sau cere permisiune ().
- Limitează-te la date publice. Dacă ai nevoie de o parolă, datele sunt restricționate — nu le extrage ().
- Verifică robots.txt și crawl-uiește politicos. Nu este obligatoriu legal, dar este o etichetă bună. Nu bombarda serverele — distanțează cererile ().
- Evită datele personale, dacă nu ai un temei legal. Dacă trebuie să le colectezi, respectă GDPR/CCPA și minimizează volumul colectat.
- Nu republica integral conținutul extras. Adaugă valoare sau analiză ori cere permisiune ().
- Nu introduce conținut extras în modele AI fără să verifici copyright-ul. Peisajul juridic se schimbă rapid — cere sfat dacă acesta este cazul tău de utilizare.
- Folosește API-uri oficiale sau exporturi de date când sunt disponibile. Sunt concepute pentru acest scop și sunt, de obicei, mai sigure ().
- Fii transparent și asumă-ți responsabilitatea. Dacă colectezi date personale, informează oamenii și păstrează un jurnal al activităților tale.
- Minimizează și securizează datele. Colectează doar ce ai nevoie, păstrează acuratețea și stochează-le în siguranță.
- Rămâi informat și cere sfat juridic pentru cazurile la limită. Legile și hotărârile se schimbă rapid — mai ales Legea UE privind AI și legile statelor americane privind confidențialitatea. Când ai dubii, întreabă un profesionist.
Folosirea legală a instrumentelor de web scraping: ce trebuie să știe companiile
Instrumente de web scraping precum fac colectarea datelor accesibilă și pentru cei care nu programează, dar tot trebuie folosite responsabil:
- Alege instrumente axate pe conformitate. Thunderbit, de exemplu, extrage doar ce poți vedea în browser — fără trucuri ascunse de tip API hack sau acces neautorizat ().
- Limitează-te la cazuri de utilizare legitime. Analizele interne, cercetarea de piață și monitorizarea competitivă a prețurilor sunt, în general, sigure. Republicarea sau vânzarea datelor extrase? Mult mai riscante.
- Configurează instrumentele pentru conformitate. Setează întârzieri între crawl-uri, respectă robots.txt și folosește șabloane care colectează doar ce ai nevoie.
- Păstrează datele în interiorul organizației. Folosirea internă a datelor extrase este mai sigură decât republicarea lor.
- Educă-ți echipa. Asigură-te că toată lumea înțelege regulile și bunele practici.
- Profită de funcțiile de conformitate integrate. Thunderbit avertizează utilizatorii despre site-uri riscante, extrage la viteze asemănătoare celor umane și nu îți stochează datele pe serverele lor.
- Nu forța lucrurile. Dacă un instrument nu poate extrage un site, nu încerca să îl ocolești prin hack-uri. Nu toate datele pot fi obținute fără risc.
Abordarea Thunderbit: web scraping AI conform cu regulile
La , am petrecut mult timp gândindu-ne la conformitate. Iată cum AI Web Scraper-ul nostru ajută utilizatorii să rămână pe partea corectă a legii:
- Extrage doar ce poți vedea. Thunderbit funcționează în sesiunea ta de browser, așa că nu poate accesa date pe care nu le-ai putea copia manual.
- Îi ghidează pe utilizatori cu avertismente. Dacă încerci să extragi un site cu politici stricte anti-scraping, Thunderbit te va atenționa.
- Viteze de scraping asemănătoare celor umane. Fie că extragi local sau în cloud, Thunderbit evită să bombardeze serverele.
- Selectarea datelor personalizabilă. AI-ul nostru sugerează coloane relevante, ajutându-te să colectezi doar ce ai nevoie.
- Gestionarea subpaginilor și paginării. Thunderbit navighează pe site-uri ca un utilizator real, respectând structura lor.
- Confidențialitate și securitate. Datele tale rămân la tine — Thunderbit nu le stochează și nu le reutilizează.
- Exporturi prietenoase cu conformitatea. Exportă direct către Google Sheets, Airtable, Notion sau CSV pentru uz intern securizat.
- Programare și automatizare. Configurează extrageri recurente la intervale responsabile.
- Suport multilingv. Interfața Thunderbit suportă 34 de limbi, făcând conformitatea accesibilă la nivel global.
- Actualizări regulate ale șabloanelor. Șabloanele noastre instant pentru site-uri populare sunt menținute la zi cu schimbările juridice și tehnice.
Prin integrarea conformității în produs, Thunderbit ajută echipele să colecteze datele de care au nevoie — fără bătăi de cap juridice.
Să rămâi în față: adaptarea la schimbările juridice și tehnice din web scraping
Web scraping-ul nu este un joc de tip „setezi și uiți”. Legile și structurile site-urilor evoluează constant. Iată cum să rămâi în față:
- Urmărește evoluțiile juridice. Ritmul schimbărilor s-a accelerat în 2024–2026 — urmărește știrile despre dreptul tehnologic, actualizările autorităților de reglementare și blogurile de industrie (cum ar fi ). Ține sub observație aplicarea Legii UE privind AI (august 2026), noile legi de confidențialitate din statele americane și cazurile în curs privind copyright-ul în AI.
- Adaptează-te la schimbările tehnice. Site-urile își actualizează constant layout-ul și apărarea anti-bot. Platformele mari (Amazon, X, Google) și-au întărit semnificativ apărarea în 2025–2026. AI-ul și șabloanele Thunderbit sunt concepute să se adapteze automat.
- Folosește API-urile oficiale când sunt disponibile. Dacă un site trece la un model API plătit, ia în calcul să faci trecerea pentru fiabilitate și conformitate.
- Auditează-ți scraping-ul în mod regulat. Documentează sursele, verifică schimbările de ToS sau politici și ajustează strategia când e nevoie.
- Profită de actualizările de șabloane Thunderbit. Echipa noastră ține șabloanele actualizate, astfel încât să nu trebuiască să-ți faci griji pentru schimbări care rup fluxul sau noi cerințe de conformitate.
- Rămâi flexibil. Dacă o sursă de date devine prea riscantă, treci la alta sau caută un parteneriat.
Cu instrumentele și mentalitatea potrivite, poți să-ți menții fluxul de date în mișcare — fără să calci pe mine juridice.
Concluzie: navigarea peisajului juridic al web scraping-ului
Web scraping-ul nu este, prin natura lui, ilegal — este un instrument puternic pentru business, cercetare și inovație. Dar, ca orice instrument, vine cu reguli. Cheia este să înțelegi ce extragi, cum extragi și ce vei face cu datele. Respectă legile locale, onorează politicile site-urilor și folosește instrumente axate pe conformitate precum pentru a-ți menține operațiunile în regulă.
Hotărârile din 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) au întărit argumentul pentru extragerea datelor publice, dar apar noi riscuri în jurul datelor de antrenare AI, pretențiilor de copyright și Legii UE privind AI. Politicile diferă mult de la o platformă la alta — Google, Amazon, LinkedIn, Meta și X aplică regulile în mod diferit — așa că află cum stă situația înainte să faci scraping.
Dacă nu ești sigur, cere sfat juridic — mai ales pentru proiecte mari sau sensibile. Și amintește-ți: peisajul juridic se schimbă mereu, deci rămâi informat și agil.
Vrei să afli mai multe despre web scraping, conformitate și automatizare? Intră pe pentru mai multe ghiduri sau încearcă singur .
Întrebări frecvente
1. Este web scraping-ul ilegal peste tot?
Nu. Web scraping-ul nu este ilegal în mod inerent, dar legalitatea lui depinde de ce extragi, cum extragi și unde te afli. Extragerea datelor publice, nepersonale, pentru uz intern este, în general, permisă în majoritatea regiunilor, dar extragerea datelor personale sau protejate prin copyright, ori încălcarea termenilor site-ului, poate fi ilegală ().
2. Face robots.txt scraping-ul ilegal dacă îl ignor?
Robots.txt nu este obligatoriu din punct de vedere legal, dar este o bună practică să îl respecți. Ignorarea lui nu te va da singură în judecată, dar te poate face să pari un „bad actor” dacă apare un conflict ().
3. Pot face scraping la Google, Amazon sau LinkedIn?
E complicat. Toate trei interzic scraping-ul în ToS, dar instanțele au decis că ToS s-ar putea să nu-i oblige pe utilizatorii care nu sunt autentificați (vezi Meta v. Bright Data și X Corp v. Bright Data, ambele din 2024). Extragerea datelor vizibile public (prețuri de produse, listări de business, profiluri publice) este, în general, defensabilă juridic în SUA. Totuși, fiecare platformă își aplică regulile diferit: Amazon este cea mai agresivă în acțiuni legale (a dat în judecată Perplexity AI în noiembrie 2025); LinkedIn se bazează pe bariere tehnice și pe pretenții contractuale; Google folosește tot mai mult aplicarea bazată pe DMCA. Fă întotdeauna scraping responsabil și așteaptă-te la contramăsuri tehnice.
4. Pot face scraping la Facebook sau Instagram?
După Meta v. Bright Data (2024), scraping-ul datelor publice de pe Facebook și Instagram fără autentificare este pe un teren juridic mai solid. Instanța a decis că ToS-urile Meta nu se aplică neutilizatorilor. Dar nu crea niciodată conturi false și nu extrage date din spatele zidurilor de autentificare — asta trece linia.
5. Pot face scraping la X (Twitter)?
X și-a actualizat ToS în 2023 pentru a interzice tot scraping-ul fără consimțământ scris și a implementat apărări tehnice agresive (Cloudflare Turnstile, limite de 300 de cereri/oră, scorare a reputației IP-ului). Totuși, Bright Data a câștigat în instanță pe baze similare — datele publice extrase fără cont nu sunt obligate de ToS-ul X. Din punct de vedere tehnic, X este una dintre cele mai dificile platforme de extras în 2026.
6. Este legal să extragi date pentru antrenarea modelelor AI?
Aceasta este cea mai mare întrebare deschisă în 2026. Procesele majore (NYT v. OpenAI, acordul de 1,5 miliarde USD al Anthropic) sugerează un risc juridic semnificativ. Legea UE privind AI cere dezvăluirea surselor datelor de antrenare și respectarea opțiunilor de excludere a copyright-ului. Propunerea AI Accountability for Publishers Act ar impune permisiune și plată. Dacă extragi date pentru a antrena AI, cere sfat juridic înainte să continui.
7. Care este cea mai sigură modalitate de a folosi instrumente de web scraping precum Thunderbit?
Rămâi la extragerea datelor publice, respectă termenii site-urilor, evită informațiile personale dacă nu ai un temei legal și folosește datele intern. Thunderbit este conceput să te ajute să rămâi în conformitate, extrăgând doar ce este vizibil în browserul tău și avertizându-te despre site-urile riscante ().
8. Pot extrage date pentru uz comercial?
Depinde. Folosirea datelor extrase pentru analize interne sau cercetare este, în general, mai sigură. Republicarea sau vânzarea datelor extrase, mai ales dacă sunt protejate prin copyright sau personale, este mult mai riscantă și poate necesita permisiune sau o licență.
9. Cum țin pasul cu schimbările juridice și tehnice din web scraping?
Urmărește știrile despre dreptul tehnologic, monitorizează site-urile tale țintă pentru schimbări de ToS sau politici și folosește instrumente precum Thunderbit, care își actualizează regulat șabloanele și funcțiile de conformitate. Lucruri importante de urmărit în 2026: aplicarea Legii UE privind AI (august), cazurile în curs privind copyright-ul în AI și noile legi de confidențialitate din statele americane. Când ai dubii, consultă un specialist juridic.