Te înscrii la ScraperAPI, vezi „100.000 de credite” în planul Hobby și începi să faci scraping. Trei zile mai târziu, în dashboard apare că 80% din acele credite au dispărut — și ai extras poate 6.000 de pagini. Ce s-a întâmplat? S-a întâmplat sistemul de multiplicatori de credite, iar acesta este, de departe, cel mai important lucru despre ScraperAPI pe care aproape nicio recenzie nu îl explică. Am petrecut săptămâni analizând documentația ScraperAPI, comparând prețuri reale de la cinci furnizori concurenți și citind fiecare thread de pe Reddit și fiecare recenzie de pe Capterra pe care am putut-o găsi. Această recenzie ScraperAPI este exact cea pe care mi-aș fi dorit să o găsesc când echipa noastră a început să evalueze API-uri de scraping. O să îți arăt matematica reală din spatele creditelor, unde performează ScraperAPI bine (și unde dă greș complet), ce spun utilizatorii reali pe G2, Capterra și Reddit și — sincer — te ajut să îți dai seama dacă ai nevoie măcar de un API de scraping.
Ce este ScraperAPI și pentru cine a fost creat?
ScraperAPI este un API de web scraping care gestionează infrastructura complicată din spatele scrapingului la scară mare: rotația proxy-urilor pe , rezolvarea automată a CAPTCHA-urilor, randarea JavaScript și retry-uri automate. Tu îi trimiți un URL printr-un simplu apel API, iar el returnează HTML-ul (sau JSON-ul parsate, dacă folosești endpointurile lor de structured data). Compania a fost fondată în 2018 de Daniel Ni, are sediul în Las Vegas și deservește acum , inclusiv Deloitte, Sony și Alibaba — procesând .
Publicul principal este format din echipe de dezvoltare și operațiuni tehnice care construiesc fluxuri personalizate de scraping. Dacă nu scrii cod, ScraperAPI nu este făcut pentru tine (revenim imediat la asta).
Funcții de bază: rotație de proxy-uri, randare JavaScript, geotargetare, endpointuri de structured data pentru site-uri populare și retry-uri automate pentru cererile eșuate.
Dar iată partea pe care majoritatea recenziilor o trec cu vederea: cifrele mari de pe pagina de prețuri ScraperAPI sunt foarte înșelătoare dacă nu înțelegi cum funcționează multiplicatorii. Așa că de acolo începem.
Cum funcționează, de fapt, sistemul de credite ScraperAPI (partea pe care cele mai multe recenzii o sar)
ScraperAPI taxează printr-un sistem de credite. Premisa de bază pare simplă: 1 cerere API = 1 credit. Numai că aproape niciodată nu se întâmplă asta în realitate. Costul real în credite depinde de două lucruri: domeniul pe care îl faci scraping și opțiunile de funcționalitate pe care le activezi. Iar aceste costuri se adună în moduri deloc intuitive.
Tabelul multiplicatorilor de credite pe care orice utilizator ar trebui să îl vadă înainte de înscriere

Înainte să activezi măcar un singur parametru, tipul de site pe care îl scrapi stabilește costul de bază în credite:
| Categorie domeniu | Credite de bază per cerere | Exemple |
|---|---|---|
| Site-uri obișnuite | 1 | Bloguri, site-uri de știri, HTML simplu |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (motoare de căutare) | 25 | Google, Bing |
| Social media | 30 |
Pe lângă asta, anumite opțiuni adaugă credite suplimentare:
| Parametru | Credite suplimentare | Note |
|---|---|---|
render=true (randare JS) | +10 | Toate planurile |
screenshot=true | +10 | Toate planurile |
premium=true (proxy premium) | +10 | Toate planurile |
ultra_premium=true | +30 | Doar planurile plătite |
| Ocolire anti-bot (Cloudflare, DataDome, PerimeterX) | +10 fiecare | Detectare automată — nu alegi tu asta |
premium=true + render=true combinate | +25 | NU +20 |
ultra_premium=true + render=true combinate | +75 | NU +40 |
Ultimul rând este cheia. Combinarea funcțiilor costă MAI MULT decât suma costurilor individuale. Proxy-ul premium (+10) plus randarea JavaScript (+10) ar trebui logic să coste +20 de credite în plus, dar ScraperAPI taxează . Ultra-premium (+30) plus randare JavaScript (+10) ar trebui să coste +40, dar costă de fapt — aproape dublu. Această logică de cost neliniară nu este documentată clar și este principalul motiv pentru care utilizatorii spun că le dispar creditele mai repede decât se așteptau.
Parametri care nu costă credite suplimentare: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Ce primește efectiv fiecare plan: de la Free la Enterprise
Iată oferite de ScraperAPI:
| Plan | Preț lunar | Anual (pe lună) | Credite API | Thread-uri concurente | Geotargetare |
|---|---|---|---|---|---|
| Free | $0 | — | 1.000 | 5 | Nu |
| Hobby | $49 | $44 | 100.000 | 20 | Doar SUA & UE |
| Startup | $149 | $134 | 1.000.000 | 50 | Doar SUA & UE |
| Business | $299 | $269 | 3.000.000 | 100 | La nivel de țară (peste 50 de țări) |
| Scaling | $475 | $427 | 5.000.000 | 200 | La nivel de țară |
| Enterprise | Personalizat | Personalizat | 5.000.000+ | 200+ | La nivel de țară |
Acum, iată costul efectiv per 1.000 de cereri pentru fiecare nivel, ținând cont de multiplicatori:
| Plan | Standard (1×) | Randare JS (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
Un plan de $49/lună promovat ca având „100.000 de credite” oferă doar 1.333 de cereri reale atunci când faci scraping pe site-uri protejate cu ultra-premium plus randare JavaScript. Asta înseamnă — mai scump decât multe servicii de scraping complet gestionate.
De ce creditele dispar mai repede decât te aștepți
Trei lucruri îi iau pe utilizatori prin surprindere.
Primul: prețul bazat pe domeniu se aplică automat. Nu alegi tu multiplicatorul 5× pentru Amazon sau 25× pentru Google. Se aplică în momentul în care ScraperAPI detectează domeniul. La fel și creditele pentru ocolirea anti-bot (+10 pentru Cloudflare, DataDome, PerimeterX) — sunt adăugate automat când sunt detectate.
Al doilea: creditele NU se reportează. Creditele nefolosite . Nu se acumulează.
Și al treilea — acesta doare — Pay-As-You-Go este disponibil doar pe planul Scaling ($475/lună) și peste. Dacă ești pe Hobby, Startup sau Business și îți termini creditele la mijlocul ciclului, pur și simplu ești blocat până la următoarea perioadă de facturare. Singura opțiune este să treci la un plan superior.
Un utilizator de pe Reddit a spus că i s-au cotat $3.600 pentru 60 de milioane de credite la 1 credit per cerere Amazon, dar după plată a fost aplicat fără avertisment un multiplicator de 5 credite. Practic, planul de 60M valora doar 12M cereri — un deficit de față de ce se aștepta.
Capcana de credite DataPipeline
Funcția no-code DataPipeline a ScraperAPI (scraping programat cu livrare prin webhook) folosește o schemă separată de credite, semnificativ mai mare. O cerere simplă normală costă în API-ul standard:
| Tip cerere | API standard | DataPipeline | Raport |
|---|---|---|---|
| Cerere normală de bază | 1 | 6 | 6× |
| E-commerce de bază | 5 | 10 | 2× |
| SERP de bază | 25 | 30 | 1.2× |
| Ultra-premium + JS (normal) | 75 | 80 | 1.07× |
Utilizatorii care configurează fluxuri no-code presupunând că vor plăti costurile standard descoperă că ard de 6× mai multe credite chiar și pentru cereri de bază. Acest lucru este documentat, dar trebuie să cauți bine ca să dai peste el.
Cost real per cerere: ScraperAPI vs. concurență
Prețul afișat în titlu nu spune mare lucru fără multiplicatori. Am luat prețurile actuale de la cinci furnizori și am standardizat comparația la nivelul de aproximativ $300/lună pentru trei scenarii comune.
Scraping HTML de bază (fără JS, fără proxy premium)
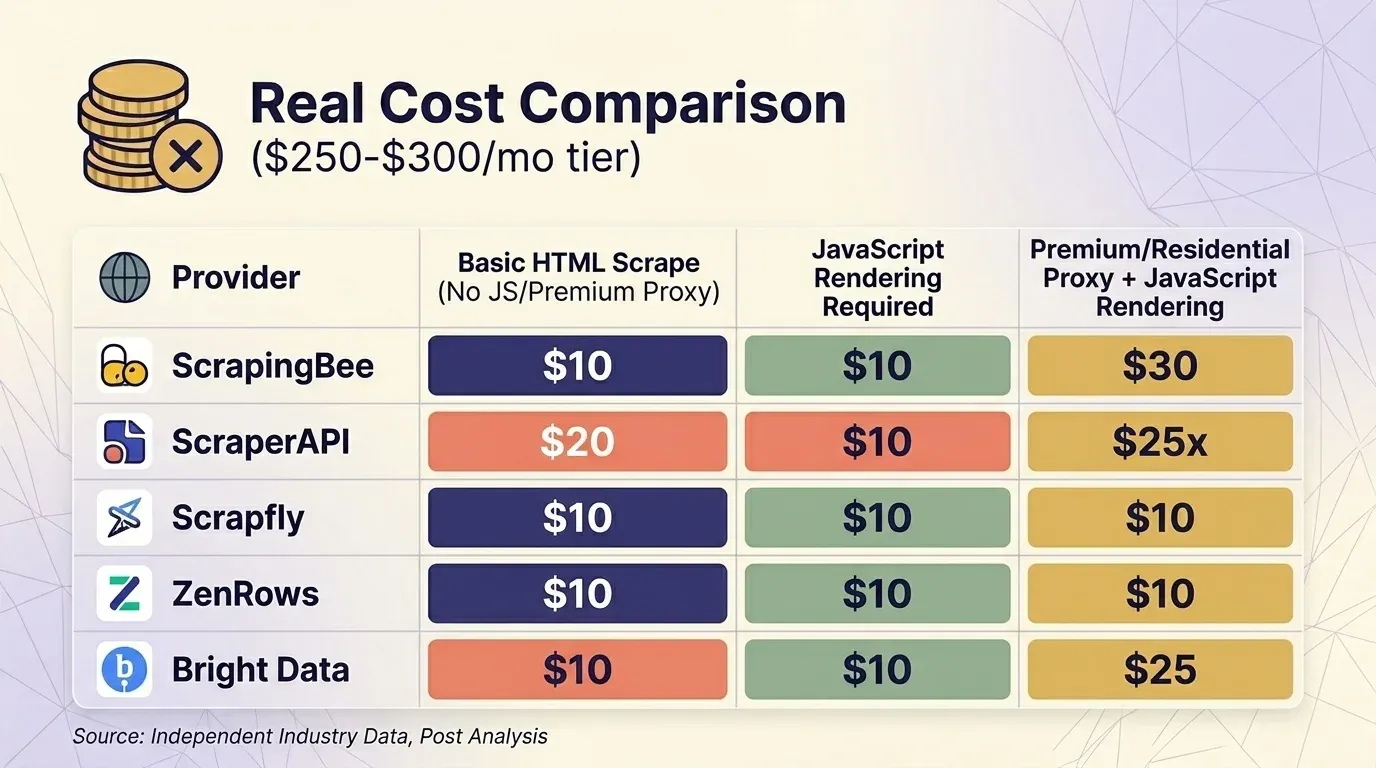
| Furnizor | Plan | Credite per cerere | Cereri reale | Cost per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3.000.000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3.000.000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2.500.000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1.071.000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | ~200.000 | $1.50 |
Este necesară randarea JavaScript
| Furnizor | Plan | Credite per cerere | Cereri reale | Cost per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (activă implicit) | 600.000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416.667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300.000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214.000 | $1.40 |
| Bright Data | PAYG | tarif fix | ~200.000 | $1.50 |
Proxy premium / residential + randare JavaScript (site-uri protejate)
| Furnizor | Plan | Credite per cerere | Cereri reale | Cost per 1K |
|---|---|---|---|---|
| Bright Data | PAYG | tarif fix | ~200.000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120.000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120.000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80.645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42.857 | $7.00 |
Bright Data Web Unlocker este singurul furnizor care — toate cererile costă la fel, la tarif fix. La nivelul de aproximativ $300, ScrapingBee și ScraperAPI sunt competitive pentru scraping pe site-uri protejate, în timp ce ZenRows este cel mai scump.
O observație importantă despre comportament: ScrapingBee la un cost de 5×. Dacă compari direct ScrapingBee și ScraperAPI, asigură-te că folosești exact aceleași setări de randare.
O analiză independentă realizată de Scrape.do a arătat că ScraperAPI costă în medie — „mai mult decât orice alt furnizor testat” — cu un timp mediu de răspuns de , ceea ce îl face „unul dintre cei mai lenți furnizori disponibili”. Merită să știi asta înainte să te angajezi.
Rate reale de succes pe site: unde ScraperAPI strălucește și unde se chinuie
Niciun API de scraping nu funcționează la fel de bine pe fiecare site. Testele independente realizate de Scrapeway (aprilie 2026) spun o poveste puternic bifurcată.
Performanță pe categorii de site
| Site țintă | Rată de succes | Viteză medie | Cost per 1K (Business Plan) |
|---|---|---|---|
| Zillow | 100% | 10.5s | $0.49 |
| Etsy | 99% | 4.8s | $4.90 |
| Amazon | 98% | 6.5s | $2.45 |
| 95% | 17.8s | $14.70 | |
| Walmart | 93% | 11.4s | $2.45 |
| Indeed | 90% | 15.8s | $4.90 |
| StockX | 84% | 3.9s | $4.90 |
| Realtor.com | 12% | 11.8s | $0.49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
Rata medie generală de succes: , ușor peste media industriei de 58.2–59.5%. Timpul mediu de răspuns: 5.2–7.3 secunde, mai bun decât media industriei de 9.8 secunde.
Unde performează bine ScraperAPI
ScraperAPI este într-adevăr puternic pe e-commerce (Amazon, Walmart, Etsy) și real estate (Zillow). Endpointurile de structured data pentru aceste site-uri returnează JSON parsate cu o fiabilitate ridicată. Dacă use-case-ul tău principal este scrapingul paginilor de produse Amazon sau al rezultatelor Google SERP, ScraperAPI este o alegere rezonabilă.
Unde ScraperAPI nu se descurcă bine
Social media este o zonă moartă. Instagram, Twitter/X și Booking.com au toate rate de succes de 0% în testările independente. LinkedIn funcționează la 95%, dar la 30 de credite per cerere costul este ridicat.
Site-urile care cer autentificare sunt explicit interzise. ScraperAPI suportă persistența sesiunii prin parametrul session_number, dar . Nu poate gestiona completarea formularelor, autentificarea în doi pași sau fluxuri complexe de autentificare.
Date învechite pe țintele protejate. ScraperAPI aplică un , ceea ce înseamnă că, dacă extragi date sensibile la timp (prețuri, stocuri), poți primi rezultate vechi cu până la 10 minute.
În benchmarkul Proxyway din 2025, ScraperAPI a avut , cu 81.72%.
Rezumatul performanței pe categorii de site
| Categorie site | Performanța ScraperAPI | Probleme cunoscute | Alternativă posibilă |
|---|---|---|---|
| Amazon / e-commerce | ✅ Puternic (endpointuri SDP) | Consum mare de credite la scară | Șabloane Thunderbit (1 click, fără credite pe rând pentru șablon) |
| Google SERP | ✅ Puternic | Geotargetarea costă extra; cea mai slabă rată Google într-un benchmark | — |
| Real estate (Zillow) | ✅ Excelent (100%) | — | — |
| Instagram / social media | ❌ 0% succes | Eșec total | Playwright + proxy-uri (DIY) |
| SPA-uri foarte încărcate cu JS | ⚠️ Moderat | Necesită randare headless cu cost 10× | Scrapfly, ZenRows |
| Site-uri care cer login | ❌ Interzis de ToS | Fără suport pentru sesiuni/autentificare | Browser scraping Thunderbit (folosește sesiunea ta de login) |
| Booking.com / travel | ❌ 0% succes | Eșec total | Bright Data |
Ce spun utilizatorii reali: sinteză de sentiment din G2, Capterra și Reddit
Am analizat feedback de pe trei platforme. Iată ratingurile actuale:
| Platformă | Rating | Recenzii |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Sub-ratinguri pe Capterra: Ușurința în utilizare 4.9/5, Suport clienți 4.6/5, Funcții 4.5/5, Raport calitate-preț 4.5/5.
Sinteză de sentiment pe teme
| Temă | Semnale pozitive | Semnale negative | |---|---|---|---| | Ușurința de configurare / documentație | „Foarte ușor de configurat. Poți începe scrapingul în câteva minute.” — comunitatea Latenode; scor Capterra pentru ușurința de utilizare 4.9/5 | — | | Transparența prețurilor | „Plan de intrare accesibil” (mai multe recenzii Capterra) | „Defalcarea costurilor în credite poate fi confuză” — John S., Founder, Capterra (feb. 2025); „Prețurile au crescut cu 1000% și calitatea s-a degradat” — CTO, Online Media, Capterra (sept. 2022) | | Fiabilitate | „Merge excelent pentru Amazon/Google” (G2, Capterra) | „ScraperAPI devine instabil pentru joburi grele” — emcarter, Latenode; „rată de eșec de 80% pe unele ținte” (Reddit) | | Suport clienți | „Echipă receptivă” (Capterra) | Un utilizator a spus că a primit un preț, dar a fost facturat la 5× rata fără avertisment clar în prealabil (Reddit) | | Valoare în timp | Se taxează doar cererile reușite (200/404) | „Dacă rulezi operațiuni la scară mare, costurile se pot aduna rapid” și construirea propriei infrastructuri este „mai rentabilă pe termen lung” — mikezhang, Latenode |
Concluzia: ScraperAPI este apreciat pentru ușurința instalării inițiale și performează fiabil pe ținte populare, bine susținute. Criticile se concentrează pe surprizele legate de prețuri (multiplicatori, creșteri neașteptate) și pe fiabilitatea în cazul țintelor mai dificile.
Endpointurile de structured data ScraperAPI: merită creditele premium?
ScraperAPI oferă pe 5 platforme, returnând JSON parsate în loc de HTML brut:
- Amazon (3 endpointuri): detalii produs după ASIN, rezultate de căutare, oferte concurente. Returnează peste 18 câmpuri, inclusiv prețuri, ratinguri, descrieri, recenzii, BSR, imagini, informații despre vânzător. Suportă .
- Google (5 endpointuri): (rezultate organice, knowledge graph, videoclipuri, întrebări similare, paginare), Shopping, Maps, News, Jobs.
- Walmart (4 endpointuri): Product, Search, Category, Reviews.
- eBay (2 endpointuri): Product, Search.
- Redfin (4 endpointuri): Search, Agent Details, Rental Properties, For Sale.
SDE-urile sunt disponibile pe toate planurile, inclusiv Free. ScraperAPI susține o pentru domeniile SDE suportate — deși benchmarkurile independente arată o imagine mai nuanțată în funcție de site.
Completitudinea datelor
Amazon SDP este cea mai puternică ofertă a ScraperAPI. Returnează un set complet de câmpuri: preț, recenzii, BSR, variante, imagini, informații despre vânzător și multe altele. Google SERP SDP returnează rezultate organice, reclame, featured snippets și People Also Ask. Completitudinea datelor este într-adevăr foarte bună pentru aceste două platforme.
Eficiența creditelor: SDP vs. parsare făcută intern
Pe planul Business ($299/lună, 3M credite), extragerea a 10.000 de produse Amazon prin SDE costă 50.000 de credite (5 credite fiecare) — adică aproximativ $5 din valoarea planului. Construirea propriului parser cu o cerere standard (1 credit fiecare) ar costa doar 10.000 de credite, dar ar necesita timp de dezvoltare pentru construirea și întreținerea parserului.
Pentru echipe mici fără dezvoltatori, SDE-urile economisesc timp real.
Pentru echipe cu capacitate de inginerie care fac scraping la scară mare, premiumul de 5× în credite este greu de justificat.
Cum se compară SDPs cu șabloanele no-code de scraping
Comparația asta contează mai mult decât lasă să se vadă majoritatea recenziilor. oferă șabloane instant pentru Amazon, Shopify, Zillow și , care nu necesită cod și nu implică cost pe rând pentru șablonul propriu-zis.
| Factor | ScraperAPI SDP (Amazon) | Șablon Thunderbit Amazon |
|---|---|---|
| Timp de configurare | 30–60 min (cod + integrare API) | ~2 minute (instalezi extensia, deschizi Amazon, alegi șablonul) |
| Cost per 1.000 produse (plan Business) | ~$5 (50.000 credite la $0.10/credit) | ~$16.50 (1.000 rânduri × 1 credit la $0.0165/credit pe Pro) |
| Câmpuri returnate | 18+ (foarte complet) | Nume produs, preț, rating, recenzii, imagini, URL și altele |
| Opțiuni de export | JSON (necesită cod pentru parsare) | Excel, CSV, Google Sheets, Airtable, Notion — 1 click |
| Întreținere | ScraperAPI întreține SDP-ul | Echipa Thunderbit întreține șabloanele |
| Competențe tehnice | Necesită Python/Node.js | Niciuna |
Pentru echipe de dezvoltare care rulează scraping Amazon la volum mare, SDP-ul ScraperAPI este mai eficient ca preț per produs la scară. Pentru utilizatorii de business care vor date din Amazon într-un spreadsheet fără să scrie cod, Thunderbit este mult mai rapid de configurat și folosit.
Chiar ai nevoie de un API de scraping? Varianta no-code pe care multe recenzii o ignoră
Mulți oameni care caută o „recenzie ScraperAPI” nu s-au hotărât încă să adopte un workflow bazat pe API. De fapt, încearcă să afle dacă au nevoie de unul.
Surprinzător, mulți nu au nevoie. Piața API-urilor de web scraping valorează și crește cu 14–18% CAGR, dar această creștere este alimentată în mare parte de echipe enterprise de inginerie — nu de managerul de sales ops care are nevoie de 500 de leaduri dintr-un site.
API de scraping vs. tool no-code: cadru de decizie comparativ
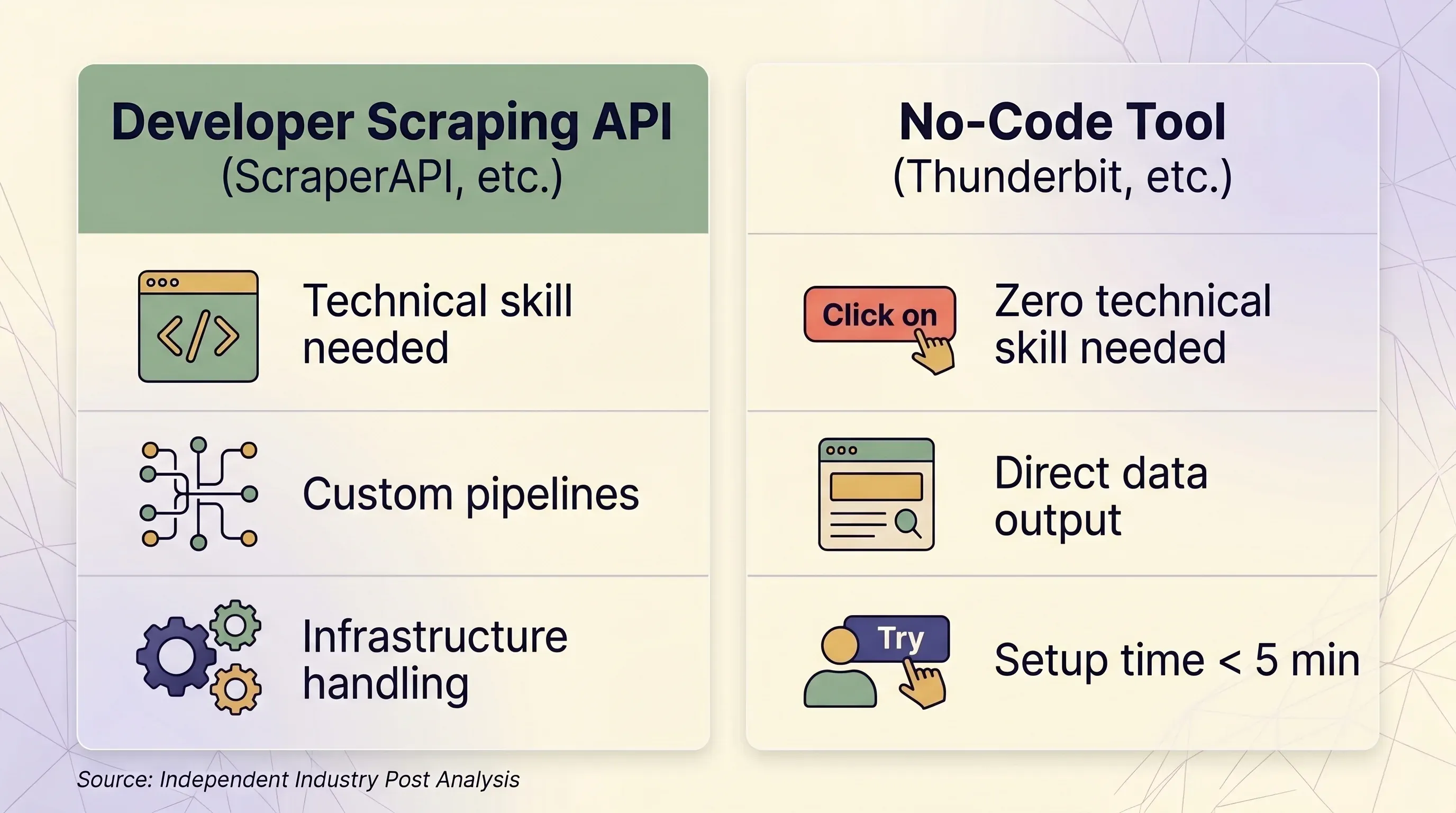
| Factor | API de scraping (ScraperAPI etc.) | Tool no-code (Thunderbit etc.) |
|---|---|---|
| Cel mai potrivit pentru | Dezvoltatori care construiesc pipeline-uri de date la scară | Utilizatori de business, marketeri, echipe de vânzări, cercetători |
| Competențe tehnice necesare | Python/Node.js, concepte HTTP, parsare JSON | Niciuna — point-and-click în browser |
| Timp de configurare | Minim 1–2 ore (cod + test + debug) | Sub 5 minute |
| Tratarea anti-bot | Proxy-uri premium (10–75 credite/cerere) | Sesiune reală de browser — ocolește natural fingerprinting-ul |
| Site-uri cu login | ❌ Interzis de ToS-ul ScraperAPI | ✅ Browser Scraping folosește sesiunea ta existentă |
| Scală (pagini/zi) | 100K–3M+ cereri/lună | Ad-hoc, de obicei sub 1.000 de pagini/zi |
| Output de date | HTML brut sau JSON (necesită cod pentru parsare) | Rânduri/coloane structurate — gata de folosit |
| Export | JSON, CSV (prin cod) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON |
| Întreținere | Trebuie actualizate selectorii, logica de retry, infrastructura | Nicio întreținere — AI re-citește structura paginii de fiecare dată |
| Unitatea de preț | Credite per cerere (variabil: 1–75 credite/cerere) | Credite per rând (1 credit = 1 rând, 2 pentru subpagini) |
| Preț de intrare | $49/lună pentru 100K credite | $9/lună pentru 5.000 credite (anual) |
| Plan gratuit | 1.000 credite/lună, 5 concurrente | 6 pagini/lună, 30 credite/pagină |
| Predictibilitatea prețului | Scăzută — multiplicatorii creează costuri surpriză | Ridicată — 1 rând = întotdeauna 1 credit |
Când are sens un API de scraping
- Ai o echipă de dezvoltare sau inginerie
- Trebuie să faci scraping la peste 100.000 de pagini pe zi în mod programatic
- Ai nevoie de personalizare profundă a headerelor, sesiunilor și logicii de retry
- Țintele tale sunt bine suportate (Amazon, Google, Walmart, Zillow)
Când are mai mult sens un tool no-code precum Thunderbit
- Lucrezi în sales, e-commerce ops, marketing sau real estate — nu în inginerie
- Ai nevoie de date din zeci de site-uri diferite fără să construiești parsere custom pentru fiecare
- Vrei export direct în Excel, Google Sheets, Airtable sau Notion
- Trebuie să faci scraping pe site-uri care cer login (browser scraping-ul Thunderbit )
- Vrei ca AI să recitească pagina de fiecare dată — fără mentenanță de cod când site-urile își schimbă layout-ul
- Ai nevoie de scraping pe subpagini: Thunderbit poate vizita fiecare pagină de detaliu și poate îmbogăți automat rândurile
Fluxul este cu adevărat simplu: instalezi extensia, navighezi pe orice pagină, apeși „AI Suggest Fields”, apoi „Scrape”, și exporți. AI-ul își dă seama ce date există pe pagină și îți sugerează coloanele — nu trebuie să scrii selectori sau cod. Pentru mai multe detalii, vezi .
au avut depășiri de costuri în cloud în 2024, iar companiile care folosesc prețuri bazate pe utilizare fără protecții adecvate au rate de churn din cauza șocului la facturare. Predictibilitatea unui model de credit per rând merită luată în calcul dacă ai fost deja lovit de costuri variabile ale API-urilor.
Avantaje și dezavantaje ScraperAPI, pe scurt
| Avantaje | Dezavantaje |
|---|---|
| Infrastructură proxy puternică (peste 40M IP-uri, peste 50 de țări) | Sistem confuz de multiplicare a creditelor — combinarea funcțiilor costă mai mult decât suma |
| Documentație excelentă și configurare inițială ușoară (Capterra Ease of Use: 4.9/5) | Creditele NU se reportează de la o lună la alta |
| Fiabil pe Amazon, Google, Zillow, Etsy | 0% succes pe Instagram, Twitter/X, Booking.com |
| Taxează doar cererile reușite (200/404) | Răspunsurile 404 consumă totuși credite |
| 18 endpointuri de structured data cu output JSON parsate | Site-urile care cer login sunt explicit interzise |
| Disponibil pe toate planurile, inclusiv Free | Pay-As-You-Go este disponibil doar pe Scaling ($475/lună) și peste |
| Politică de rambursare de 7 zile, fără întrebări | Cache forțat de 10 minute pe țintele dificile — risc de date învechite |
| Creștere de venit de 30–35% YoY sugerează dezvoltare activă | DataPipeline costă până la 6× creditele API standard |
| — | Geotargetarea dincolo de SUA & UE necesită planul Business ($299/lună) |
| — | Fără alerte proactive de utilizare — trebuie să verifici manual dashboardul |
Sfaturi practice ca să scoți maximum din ScraperAPI (dacă decizi să îl folosești)
Monitorizează zilnic consumul de credite
ScraperAPI oferă statistici de utilizare, inclusiv latența medie, domeniile scrapiate și metrici de concurență. Totuși, nu există alerte proactive de utilizare — nici email, nici SMS când creditele se apropie de zero. Trebuie să verifici manual. Istoricul de analytics este limitat la 2 săptămâni pe planurile Hobby/Startup și 6 luni pe Business+.
Pune-ți un reminder în calendar să verifici dashboardul în fiecare zi în prima lună. Trebuie să îți formezi o intuiție despre cât de repede se consumă creditele pe țintele tale specifice.
Începe cu planul Free ca să testezi site-urile țintă
Folosește cele 1.000 de credite gratuite (plus trialul de 7 zile cu 5.000 de credite) ca să testezi ratele de succes pe site-urile tale țintă înainte să te angajezi la un plan plătit. Notează ce site-uri au nevoie de randare JavaScript sau de proxy-uri premium, ca să poți estima costurile lunare reale cu multiplicatorii incluși.
Dezactivează funcțiile premium dacă ținta nu le cere
ScraperAPI NU activează automat proxy-urile premium sau randarea JavaScript — trebuie să setezi explicit render=true, premium=true sau ultra_premium=true. Dar taxarea pe domeniu ESTE automată: Amazon costă mereu 5 credite, Google mereu 25, LinkedIn mereu 30. Creditele pentru ocolirea anti-bot (+10 pentru Cloudflare, DataDome, PerimeterX) sunt și ele adăugate automat când sunt detectate. Ține cont de asta înainte să rulezi un batch.
Folosește endpointurile de structured data pentru site-urile suportate
Dacă faci scraping pe Amazon sau Google, SDE-urile economisesc timp de dezvoltare chiar dacă consumă mai multe credite. Pentru site-urile nesuportate, evaluează dacă un ar fi mai rapid și mai ieftin decât construirea unui parser custom.
Ai un plan de rezervă pentru țintele instabile
Dacă rata de succes ScraperAPI pe un anumit site scade sub 90%, ia în calcul să redirecționezi acele cereri către un alt furnizor sau să folosești un tool bazat pe browser. Pentru site-urile care cer login, ScraperAPI pur și simplu nu va funcționa — vei avea nevoie de un instrument precum , care operează în sesiunea ta de browser.
Ce trebuie să știi ca să eviți surprizele
- Răspunsurile 404 consumă credite — ScraperAPI taxează atât codurile 200, cât și 404
- Cerile anulate sunt taxate dacă le oprești înainte să se încheie fereastra de procesare de 70 de secunde
- Cache forțat de 10 minute pe țintele dificile — poți primi date vechi
- Pay-As-You-Go este disponibil doar pe Scaling ($475/lună) și peste — utilizatorii de nivel inferior care își consumă creditele sunt blocați
- Geotargetarea dincolo de SUA & UE cere planul Business ($299/lună)
Idei principale: este ScraperAPI instrumentul potrivit pentru tine?
După toată cercetarea, am ajuns aici:
- ScraperAPI este o alegere solidă pentru echipele de dezvoltare care fac scraping la volum mare pe ținte bine suportate precum Amazon, Google, Walmart și Zillow. Endpointurile de structured data chiar sunt utile, infrastructura de proxy-uri este mare, iar documentația este peste medie.
- Sistemul de multiplicare a creditelor este cel mai mare risc. Dacă nu înțelegi cum se adună multiplicatorii, vei cheltui prea mult. Diferența dintre creditele afișate și cererile reale poate fi de 5–75×. Fă calculul pentru cazul tău concret înainte să alegi un plan plătit.
- Fiabilitatea depinde de site. ScraperAPI este excelent pe e-commerce și real estate, mediocru pe site-uri de joburi și social media și complet inutil pe Instagram, Twitter/X și Booking.com. Nu presupune performanță uniformă.
- Pentru echipe non-tehnice, ScraperAPI este instrumentul greșit. Dacă lucrezi în sales, marketing sau ops și ai nevoie de date structurate fără să scrii cod, un tool no-code precum te duce acolo în două clickuri — cu detectare de câmpuri bazată pe AI, export direct în spreadsheet, îmbogățire pe subpagini și fără mentenanță. Vezi sau urmărește tutoriale pe .
- Pentru dezvoltatori cu buget limitat, testează planul gratuit ScraperAPI pe țintele tale specifice, apoi compară costul efectiv per cerere cu ScrapingBee, Scrapfly și Bright Data înainte să alegi. Cea mai ieftină opțiune depinde integral de use case-ul și de cerințele de funcționalitate.
Vrei să vezi cum arată calculele pentru nevoile tale specifice de scraping? Începe cu planul gratuit ScraperAPI ca să testezi site-urile țintă sau ca să vezi cât de departe te pot duce două clickuri. Pentru mai multe informații despre , vezi planurile noastre.
Întrebări frecvente
ScraperAPI este gratuit?
Da, ScraperAPI oferă un plan gratuit cu și un trial de 7 zile cu 5.000 de credite. Totuși, multiplicatorii de credite pentru randarea JavaScript, proxy-urile premium sau domeniile scumpe (Amazon = 5×, Google = 25×, LinkedIn = 30×) înseamnă că capacitatea reală poate fi mult mai mică decât 1.000 de cereri. În planul gratuit, proxy-urile ultra-premium nu sunt disponibile.
Cât costă ScraperAPI per cerere?
Depinde foarte mult de opțiunile activate și de domeniul țintă. O cerere standard către un site HTML simplu costă 1 credit. O cerere Amazon costă 5 credite. O cerere Google SERP costă 25 de credite. Adăugarea randării JavaScript mai adaugă 10 credite. Combinarea proxy-ului ultra-premium cu randarea JavaScript costă 75 de credite per cerere. Pe planul Hobby ($49/lună, 100K credite), asta înseamnă de la $0.00049 per cerere (standard) până la $0.0368 per cerere (ultra-premium + JS). Vezi tabelele complete de cost mai sus pentru detalii.
ScraperAPI este bun pentru scraping Amazon?
Endpointul Amazon Structured Data de la ScraperAPI este una dintre cele mai puternice funcții ale sale, cu o în benchmarkuri independente și output JSON parsate foarte complet (peste 18 câmpuri). Totuși, fiecare cerere Amazon costă minimum 5 credite, așa că la scară mare costurile cresc repede. Pentru echipe mai mici care vor date Amazon într-un spreadsheet fără cod, oferă o alternativă cu 1 click și export direct.
Care sunt cele mai bune alternative la ScraperAPI?
Pentru dezvoltatori: (cel mai ieftin pentru HTML de bază), (bun pentru randare JavaScript), (cel mai bun pentru site-uri protejate — tarif fix indiferent de randare) și . Pentru utilizatori non-tehnici: — o extensie Chrome no-code, cu AI, care exportă direct în Excel, Google Sheets, Airtable și Notion. Vezi pentru o analiză mai profundă.
Poate ScraperAPI să facă scraping pe site-uri care cer login?
ScraperAPI suportă persistența sesiunii prin parametrul session_number (aceeași adresă IP pe mai multe cereri), dar . Nu poate gestiona completarea formularelor, autentificarea în doi pași sau fluxuri complexe de autorizare. Pentru site-uri care cer login, instrumentele bazate pe browser precum — care folosește sesiunea ta existentă de browser pentru a extrage ce poți vedea — sunt opțiunea mai fiabilă.
Află mai multe