Lasă-mă să-ți spun ceva: dacă aș primi un dolar de fiecare dată când cineva îmi trimite un PDF plin de „date importante” și se așteaptă să-l transform, ca prin minune, într-un spreadsheet, probabil mi-aș permite o rezervă pe viață de cafea și poate câteva extensii Chrome în plus. PDF-urile sunt peste tot — contracte de vânzare, cataloage de produse, lucrări de cercetare, facturi, orice vrei. Dar când vine vorba să folosești efectiv datele din aceste fișiere? Aici încep problemele.
Am trecut și eu prin asta — copy-paste, reformatare și, uneori, renunțat de tot când formatarea o lua razna sau imaginile și linkurile dispăreau în neant. Vestea bună este că lumea extragerii de date din PDF-uri s-a schimbat radical, mai ales odată cu apariția instrumentelor bazate pe AI. Dacă te-ai săturat să petreci ore întregi reintroducând numere sau să-ți pierzi răbdarea din cauza tabelelor stricate, ești exact unde trebuie. Hai să intrăm în lumea extragerii de date din PDF-uri, să vedem de ce contează și cum instrumente precum fac totul, în sfârșit, fără durere.
Ce este extragerea de date din PDF? Înțelegerea bazelor extragerii datelor din PDF
Să începem simplu: extragerea de date din PDF înseamnă, pe scurt, „scoaterea automată a datelor structurate din fișiere PDF”. Un extrator de date din PDF este un instrument (software, extensie sau serviciu) care extrage informațiile care te interesează — text, tabele, imagini, linkuri, orice — și le pune într-un format pe care chiar îl poți folosi, cum ar fi Excel, Google Sheets sau o bază de date.
Dar există o problemă: PDF-urile nu sunt ca paginile web sau fișierele Excel. Ele seamănă mai degrabă cu niște printuri digitale, create să arate la fel peste tot, nu să fie descompuse ușor de un computer. Unele PDF-uri au text selectabil, altele sunt doar imagini scanate (care au nevoie de OCR — recunoaștere optică a caracterelor), iar formatarea poate fi complet haotică. Așadar, extragerea datelor dintr-un PDF nu înseamnă doar copierea textului — înseamnă descifrarea unui puzzle de layout-uri, fonturi și, uneori, chiar metadate ascunse.
Ce poți extrage dintr-un PDF?
- Text simplu (paragrafe, titluri etc.)
- Tabele (de exemplu: date financiare, specificații de produs, date din sondaje)
- Imagini și elemente grafice (grafice, logo-uri, semnături scanate)
- Hyperlinkuri și referințe (URL-uri încorporate, citări)
- Date din formulare (câmpuri din formulare completabile)
- Metadate (autor, titlu, data creării, etichete)
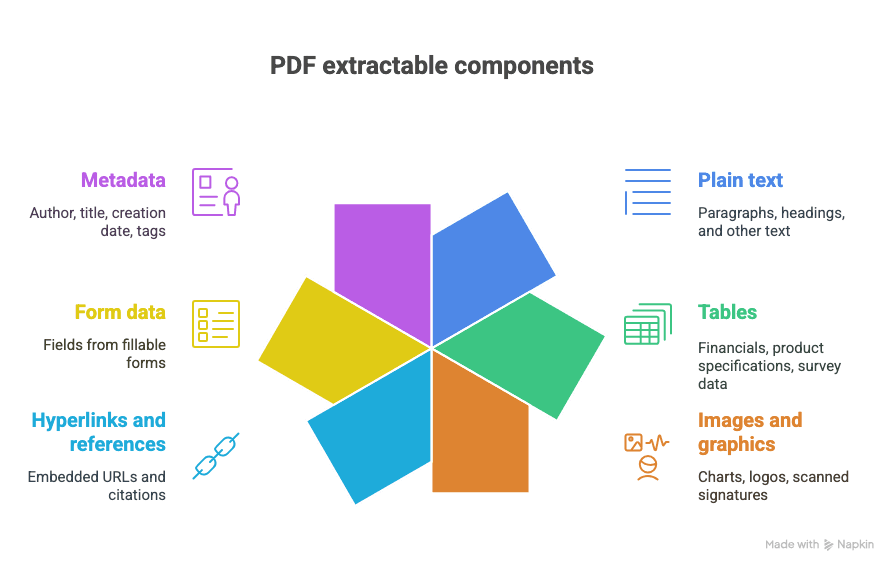
Și da, uneori toate astea sunt amestecate într-un singur document glorios și haotic.
De ce contează extragerea datelor din PDF: cazuri reale de utilizare și beneficii pentru business
Așadar, de ce să te chinui să extragi date din PDF-uri? Pentru că toată lumea le folosește, iar datele din interior sunt adesea esențiale pentru business. Aici strălucește extragerea din PDF:
| Caz de utilizare | Efort manual | Cu un extractor de PDF | Economii de timp și erori |
|---|---|---|---|
| Extragerea lead-urilor de vânzări | Ore întregi copiere contacte din propuneri sau PDF-uri de la evenimente, risc de a pierde lead-uri | Preia instant toate lead-urile într-un spreadsheet | Cu 80–90% mai rapid, mai puține greșeli |
| Date despre produse pentru e-commerce | Zile întregi introducând specificații din PDF-urile furnizorilor, probleme de formatare | Extragere în masă în CSV sau Sheets | Economie de timp de peste 95%, date consecvente |
| Analiza datelor de cercetare | Săptămâni de transcriere a tabelelor din lucrări academice, risc mare de greșeli de tastare | Extrage tabele, referințe și chiar text scanat | 80% timp economisit, acuratețe mai mare |
Să punem și niște cifre pe masă:
- sunt create în fiecare an.
- folosesc PDF-ul ca format principal pentru partajarea informațiilor.
- Administrația digitală manuală (cum ar fi introducerea datelor din PDF-uri) consumă .
- Instrumentele automate pot reduce rata de eroare de la .
Dacă lucrezi în vânzări, e-commerce sau cercetare, automatizarea extragerii datelor din PDF nu este doar un „nice-to-have” — este un avantaj competitiv.
Metode tradiționale de extragere din PDF: provocări și limitări
Să fim sinceri: metodele vechi de a scoate date din PDF-uri nu sunt… grozave. Iată ce am încercat majoritatea dintre noi (și de ce e atât de frustrant):

1. Copy-paste manual
- Probleme: Formatarea se strică, tabelele devin o harababură, imaginile și linkurile dispar, iar tu rămâi cu o migrenă.
- Cost de muncă: Mare. Dacă ai 5.000 de PDF-uri, chiar și la 1 minut fiecare, înseamnă peste 80 de ore din viața ta pe care nu le mai recuperezi.
- Rată de eroare: 5–10%. Greșeli de tastare, rânduri omise, ștergeri accidentale — am pățit, am făcut, am trecut prin asta.
2. Conversie în Word/Excel, apoi curățare
- Probleme: Uneori merge pentru documente simple, dar layout-urile complexe sau tabelele sunt date peste cap. Tot trebuie să cureți mizeria.
- Imagini/linkuri: De obicei se pierd pe drum.
- Extragere țintită: Nu prea. Primești întregul document, nu doar ce ai nevoie.
3. Scripturi personalizate (Python etc.)
- Probleme: Ai nevoie să fii programator (sau să ai unul „on speed dial”). Fiecare format nou de PDF înseamnă ajustări în script. PDF-uri scanate? Succes.
- Mentenanță: Mare. De fiecare dată când un furnizor își schimbă șablonul de factură, scriptul tău se strică.
- Scalabilitate: Nu pentru cei care se sperie ușor (sau pentru cei non-tehnici).
4. Convertoare online
- Probleme: Ușor de folosit pentru sarcini punctuale, dar trebuie să încarci documente sensibile pe un server terț (bună, probleme de conformitate). Control limitat asupra a ceea ce se extrage.
- Formatare: Când merge, când nu. Poți ajunge să petreci mai mult timp curățând decât ai economisit.
Concluzia: metodele tradiționale sunt lente, predispuse la erori și nu scalează. De aceea, multe echipe pur și simplu „se împacă cu ideea” — dar cu un cost uriaș de productivitate.
Soluții moderne pentru extragerea din PDF: de la cod la instrumente no-code
Din fericire, nu mai suntem blocați în Evul Mediu. Peisajul s-a extins enorm, cu opțiuni mai inteligente, mai rapide și mai prietenoase pentru cei care folosesc PDF scraping.
1. Biblioteci de cod (pentru dezvoltatori)
- Exemple: , , .
- Puncte forte: Foarte flexibile, pot fi automatizate pentru loturi mari, gratuite (open source).
- Puncte slabe: Timp mare de configurare, necesită abilități de programare, fragile (se strică la formate noi), suport limitat pentru OCR/imagine.
2. Convertoare online pentru PDF
- Exemple: , , .
- Puncte forte: Fără configurare, ușor pentru cei fără profil tehnic, rapid pentru sarcini mici.
- Puncte slabe: Personalizare limitată, probleme de confidențialitate, erori de formatare, limite de dimensiune/pagini.
3. Extractoare de PDF bazate pe AI
- Exemple: , Nanonets, Docparser.
- Puncte forte: Fără cod, gestionează text/tabele/imagine/linkuri, AI sugerează ce să extragi, suportă joburi în lot, se integrează cu Sheets/Notion/Airtable.
- Puncte slabe: Unele au limite de credite/pagini, pot necesita conexiune la internet, uneori există o curbă de învățare pentru documente complexe.
Compararea instrumentelor de extragere din PDF: ce abordare se potrivește nevoilor tale?
| Instrument/Metodă | Configurare | Cel mai potrivit pentru | Extrage | Poate fi personalizat? | Cost |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Medie (UI/cod) | Tabele în PDF-uri | Tabele | Într-o oarecare măsură | Gratuit |
| PDFMiner | Necesită cod | PDF-uri bogate în text | Text | Da (cod) | Gratuit |
| PyPDF2 | Necesită cod | Text simplu/metadate | Text, metadate | Da (cod) | Gratuit |
| Smallpdf/Convertor online | Nicio configurare | Conversii rapide | Tot documentul (Word/Excel) | Nu | Freemium |
| Thunderbit | Instalare în 2 clicuri | Utilizatori business, echipe | Text, tabele, imagini, linkuri | Da (prompturi AI) | Freemium (16,5 $/lună pentru Pro) |
Fă cunoștință cu Thunderbit: extensia Chrome AI pentru extragerea datelor din PDF
Acum hai să vorbim despre instrumentul care mi-a făcut viața mea (și viața multor utilizatori business) mult mai ușoară: .
Ce face Thunderbit diferit?
- Extragere în 2 clicuri: Deschizi un PDF în Chrome, dai click pe extensia Thunderbit și lași AI-ul să facă restul.
- Sugestii de câmpuri generate de AI: Funcția „AI Suggest Fields” din Thunderbit citește PDF-ul și recomandă coloanele de care probabil ai nevoie (cum ar fi „Nume”, „Email”, „Preț” etc.).
- Gestionează imagini, linkuri și tabele: Nu doar text simplu — Thunderbit poate extrage imagini, hyperlinkuri și poate face chiar OCR pe documente scanate.
- Prompturi personalizate: Ai nevoie doar de numere de telefon sau specificații de produs? Adaugi o instrucțiune personalizată și Thunderbit se concentrează doar pe asta.
- Exporturi oriunde: Trimite datele direct în Excel, Google Sheets, Airtable sau Notion. Gata cu jongleriile cu CSV-uri.
- Extragere în lot și pe subpagini: Ai o listă de PDF-uri sau linkuri? Thunderbit le poate procesa pe toate dintr-o singură mișcare.
- Fiabilitate la nivel business: Conceput pentru acuratețe, confidențialitate și fluxuri de lucru reale.
Pe scurt, e ca și cum ai avea un intern digital căruia chiar îi place să introducă date (și care nu obosește niciodată).
Cum să extragi date dintr-un PDF folosind Thunderbit: ghid pas cu pas
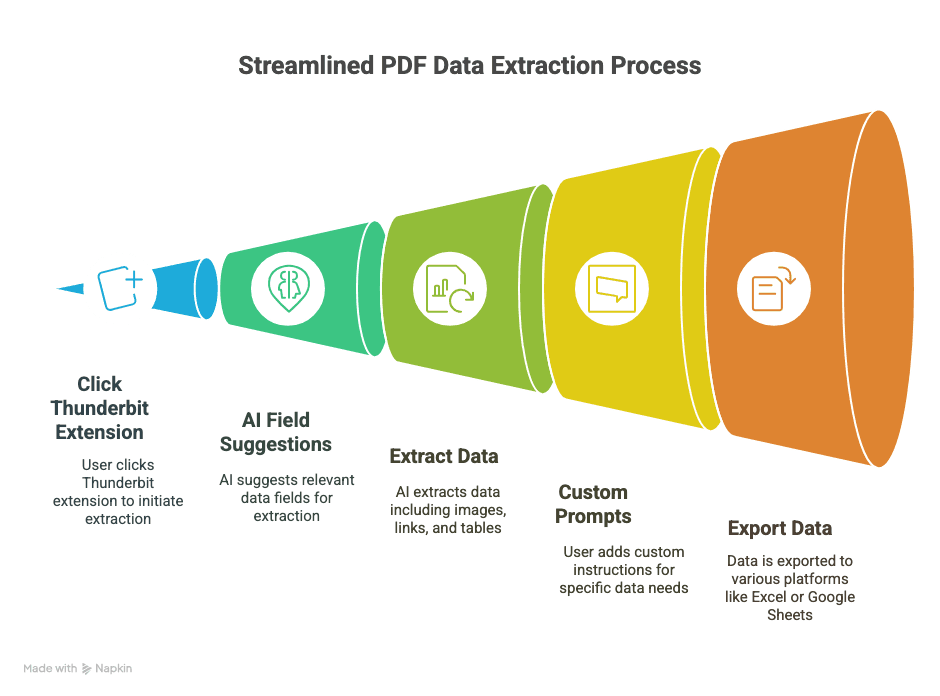
Ești gata să vezi cât de simplu poate fi? Așa folosesc eu Thunderbit ca să transform PDF-urile în date structurate, utile:
1. Instalează Thunderbit
- Ia .
- Creează-ți contul (cu Google sau email — durează câteva secunde).
2. Deschide PDF-ul în Chrome
- Fie deschizi un PDF dintr-un link web, fie tragi un PDF local într-un tab Chrome.
3. Pornește Thunderbit pe PDF
- Dă click pe iconița Thunderbit din bara de instrumente a browserului.
- Selectează „AI Web Scraper” — Thunderbit va detecta PDF-ul și va fi gata de lucru.
4. Lasă AI-ul să sugereze câmpurile
- Dă click pe „AI Suggest Columns”.
- AI-ul Thunderbit scanează PDF-ul și recomandă coloane (cum ar fi „Dată”, „Sumă”, „Nume contact” etc.).
- Previzionează datele extrase într-un tabel direct în extensie.
5. Personalizează (dacă e nevoie)
- Redenumește coloanele, șterge ce nu-ți trebuie sau adaugă propriile câmpuri (de exemplu, „Termen garanție” sau „URL produs”).
- Pentru date mai dificile, selectează text în PDF ca să antrenezi AI-ul asupra a ceea ce vrei.
6. Alege formatul de export
- Alege dintre CSV, Google Sheets, Airtable sau Notion.
- Autorizează Thunderbit să se conecteze (configurare o singură dată).
7. Extrage și exportă
- Apasă „Scrape” sau „Export”.
- Thunderbit procesează PDF-ul și trimite datele acolo unde vrei — de obicei în câteva secunde.
Asta e tot. Fără cod, fără copy-paste, fără dramă.
Sfaturi pentru extragerea corectă a datelor din PDF cu Thunderbit
- Verifică câmpurile sugerate de AI: AI-ul e inteligent, dar o privire rapidă îți confirmă că obții exact ce ai nevoie.
- Gestionează tabelele complexe: Pentru tabele pe mai multe pagini sau cu formatare ciudată, folosește previzualizarea ca să observi problemele și să ajustezi coloanele după caz.
- Extrage imagini/linkuri: Asigură-te că incluzi aceste câmpuri dacă PDF-ul le conține — Thunderbit le poate prelua și pe ele.
- PDF-uri scanate: OCR-ul încorporat al Thunderbit este solid, dar cu cât scanarea e mai clară, cu atât rezultatele sunt mai bune.
- Prompturi personalizate: Vrei doar emailuri sau numere de telefon? Adaugă un prompt de tipul „Extrage toate adresele de email” și Thunderbit se va concentra pe ele.
Extragere avansată din PDF: imagini, linkuri și date personalizate
Thunderbit nu înseamnă doar text simplu. Iată cum poți obține și mai mult din PDF-urile tale:
- Imagini: Extrage logo-uri, grafice sau orice element grafic încorporat. Thunderbit poate chiar să facă OCR pentru textul din imagini.
- Hyperlinkuri: Scoate toate URL-urile sau referințele — excelent pentru lucrări de cercetare sau CV-uri.
- Tipuri de date personalizate: Folosește prompturi AI pentru a extrage exact ce ai nevoie (de exemplu, „Găsește toate SKU-urile produselor și prețurile lor”).
- Rezumate și categorizare: Adaugă o coloană și cere-i lui Thunderbit să rezume o secțiune sau să categorizeze datele din mers.
Parsarea datelor din PDF pentru nevoi business specifice
- Vânzări: Extrage doar informațiile de contact dintr-un lot de propuneri.
- E-commerce: Preia specificațiile, prețurile și imaginile produselor din cataloagele furnizorilor.
- Cercetare: Scoate tabele, referințe și chiar generează rezumate din lucrări academice.
Iar când ai datele, structurează-le pentru analiză ușoară în Excel, Google Sheets sau Notion — Thunderbit face munca grea, tu doar folosești rezultatele.
Exportarea și folosirea datelor din PDF: de la extragere la acțiune
Scoaterea datelor este doar începutul. Iată cum le poți pune la treabă:
- Opțiuni de export: CSV, Excel, Google Sheets, Airtable, Notion — alege ce preferi.
- Sfaturi de formatare: Folosește setările de tip de coloană din Thunderbit (număr, dată, text) pentru date curate, gata de analiză.
- Integrare în fluxul de lucru: Conectează datele exportate la CRM-uri, sisteme de inventar sau dashboard-uri de analiză.
- Colaborare: Partajează foile Google Sheets sau bazele Airtable cu echipa ta — toată lumea lucrează din aceleași date actualizate.
Partea cea mai bună? Nu mai trebuie să trimiți spreadsheet-uri pe email înapoi și înainte sau să te întrebi dacă ai ratat vreun rând.
Capcane comune în extragerea din PDF și cum să le eviți
Chiar și cu cele mai bune instrumente, pot apărea câteva capcane. Iată ce am învățat eu (uneori pe pielea mea):
- Erori OCR: Scanările neclare sau fonturile ciudate pot încurca chiar și cel mai bun OCR. Încearcă să folosești PDF-uri cât mai curate și verifică manual câmpurile critice.
- Layout-uri complexe: Tabelele pe mai multe coloane sau cele imbricate pot avea nevoie de puțină ghidare manuală — folosește selecția manuală sau prompturile Thunderbit.
- Tipuri de date: Numere cu virgule sau date în formate ciudate? Setează tipul coloanei înainte de export sau curăță datele în Excel/Sheets.
- Limite de dimensiune/pagini: PDF-uri uriașe? Împarte-le în bucăți mai mici sau folosește modul cloud al Thunderbit pentru joburi în lot.
- „Halucinații” AI: Rare, dar uneori AI-ul poate ghici un nume de coloană sau poate completa date lipsă. Verifică întotdeauna rezultatul, mai ales când e vorba de cifre importante.
- Revizuire manuală: Pentru date critice, fă o validare rapidă — instrumentele automate sunt precise, dar un ochi uman nu strică niciodată.
Și dacă te lovești de un zid, suportul și comunitatea Thunderbit sunt acolo să te ajute.
Concluzie și idei-cheie: cum să faci extragerea din PDF să lucreze pentru business-ul tău
Să încheiem. Extragerea datelor din PDF-uri era odinioară un coșmar — lentă, predispusă la erori și pur și simplu obositoare. Dar cu instrumente moderne precum , acum este rapidă, precisă și (îndrăznesc să spun) aproape plăcută.
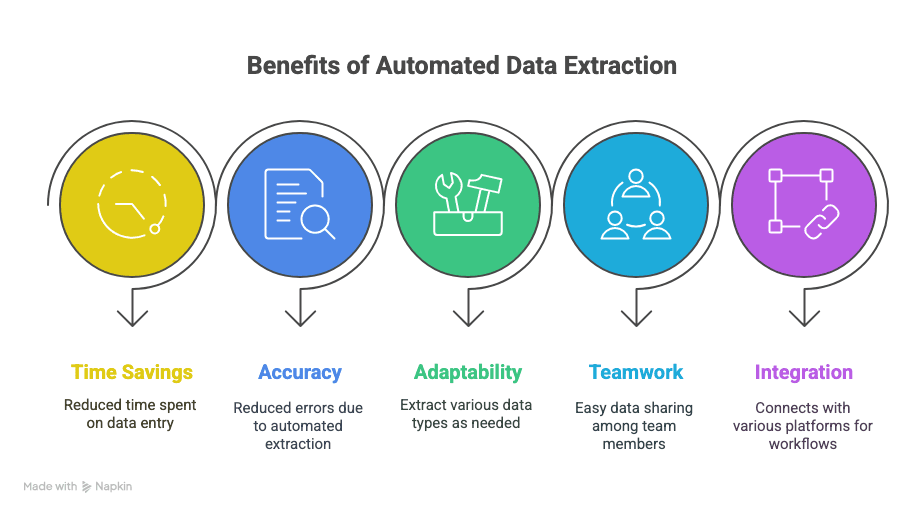
Iată ce obții:
- Timp câștigat înapoi: Ore (sau chiar săptămâni) economisite la introducerea manuală a datelor.
- Mai puține greșeli: Extragerea automată înseamnă mai puține greșeli de tastare și rânduri omise.
- Flexibilitate: Extragi exact ce ai nevoie — text, tabele, imagini, linkuri, orice.
- Colaborare: Partajezi instant datele cu echipa, oriunde s-ar afla.
- Fluxuri de lucru mai inteligente: Integrare cu Sheets, Notion, Airtable și multe altele.
Ești gata să încerci? Descarcă , ruleaz-o pe următorul tău PDF și vezi cât de ușoară poate fi viața. Viitorul tău eu (și tunelul tău carpian) îți vor mulțumi.
Pentru mai multe sfaturi și ghiduri, vezi sau aprofundează cu .
Hai să transformăm durerile de cap provocate de PDF-uri în câștiguri de productivitate — un clic pe rând.
Shuai Guan, Co-fondator & CEO, Thunderbit