
Există ceva ciudat de satisfăcător în a vedea un script cum trece în viteză printr-un site și strânge datele, în timp ce tu îți bei cafeaua. Dacă ești ca mine, probabil te-ai întrebat: „Cum pot face web scraping-ul mai rapid, mai inteligent și mai puțin enervant?”
Exact asta m-a atras în lumea web scraping-ului cu OpenClaw. Într-un peisaj digital în care peste 90% dintre companii se bazează pe extragerea de date web pentru orice, de la leaduri de vânzări la intelligence de piață, stăpânirea instrumentelor potrivite nu e doar un moft de tech flex — e o necesitate de business.
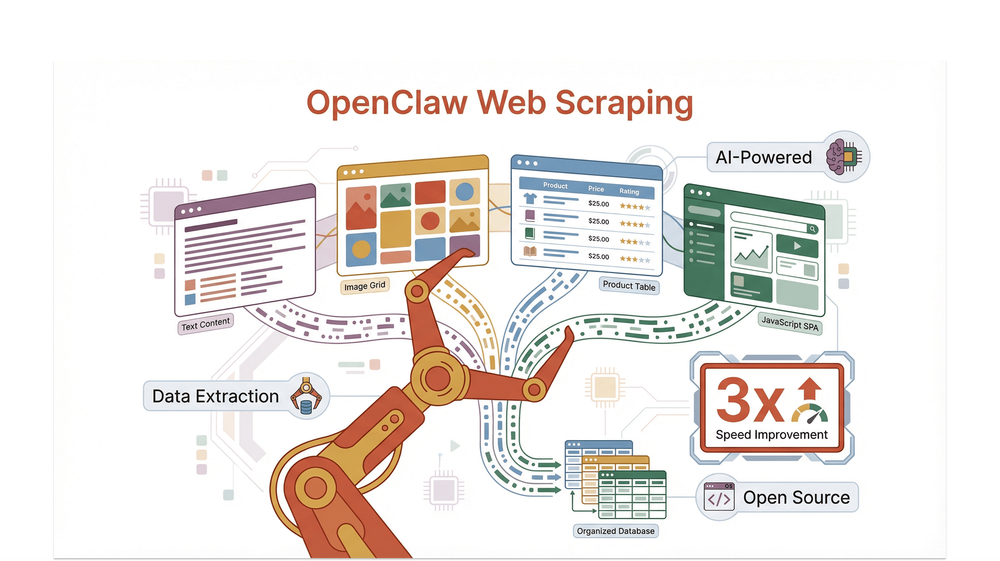
OpenClaw a devenit rapid preferatul comunității de scraping, mai ales pentru cei care lucrează cu site-uri dinamice, bogate în imagini sau complexe, care îi fac pe scraper-ele tradiționale să gâfâie.
În acest ghid, te voi purta prin tot procesul, de la configurarea OpenClaw până la construirea unor fluxuri de lucru avansate, automatizate. Și, pentru că sunt mare fan al economisirii timpului, îți voi arăta cum să îți turboîncarci scraping-ul cu funcțiile AI ale Thunderbit, pentru un workflow care nu este doar puternic, ci chiar plăcut de folosit.
Încearcă Thunderbit pentru web scraping mai inteligent
Ce este web scraping-ul cu OpenClaw?
Să începem cu baza. Web scraping-ul cu OpenClaw înseamnă folosirea platformei OpenClaw — un gateway de agenți open-source, găzduit de tine — pentru a automatiza extragerea datelor din site-uri. OpenClaw nu este doar încă un scraper; este un sistem modular care conectează canalele tale preferate de chat (precum Discord sau Telegram) la un set de instrumente pentru agenți, inclusiv fetchere web, utilitare de căutare și chiar un browser gestionat pentru acele site-uri pline de JavaScript care fac alte instrumente să transpire.
Ce face OpenClaw să iasă în evidență pentru extragerea de date web? Este gândit să fie atât flexibil, cât și robust. Poți folosi instrumente integrate precum web_fetch pentru extragere simplă prin HTTP, poți porni un browser Chromium controlat de agent pentru conținut dinamic sau poți conecta skill-uri create de comunitate (cum ar fi openclaw-plugin-web-scraper) pentru fluxuri mai avansate. Este open-source (licențiat MIT), întreținut activ și are un ecosistem sănătos de pluginuri și skill-uri, ceea ce îl face o alegere de top pentru oricine ia în serios scraping-ul la scară.
OpenClaw gestionează o gamă largă de tipuri de date și formate de site-uri, inclusiv:
- Text și HTML structurat
- Imagini și linkuri media
- Conținut dinamic randat de JavaScript
- Structuri DOM complexe, cu mai multe niveluri
Și pentru că este bazat pe agenți, poți orchestra sarcini de scraping, automatiza rapoarte și chiar interacționa cu datele tale în timp real — totul din aplicația ta preferată de chat sau din terminal.
De ce OpenClaw este un instrument puternic pentru extragerea de date web
Așadar, de ce se îngrămădesc atât de mulți oameni de date și pasionați de automatizare spre OpenClaw? Hai să desfacem pe rând punctele forte tehnice care îl transformă într-o adevărată forță în web scraping:
Viteză și compatibilitate
Arhitectura OpenClaw este construită pentru viteză. Instrumentul său de bază web_fetch folosește cereri HTTP GET cu extragere inteligentă a conținutului, cache și tratarea redirectărilor. În benchmark-uri interne și ale comunității, OpenClaw depășește constant instrumente mai vechi precum BeautifulSoup sau Selenium atunci când extrage volume mari de date din site-uri statice și semi-dinamice (docs.openclaw.ai).
Dar unde strălucește cu adevărat OpenClaw este la compatibilitate. Datorită modului său de browser gestionat, poate face față site-urilor care se bazează pe JavaScript pentru randare — lucru care blochează multe scraper-e tradiționale. Fie că țintești un catalog e-commerce încărcat cu imagini sau o aplicație single-page cu infinite scroll, profilul Chromium controlat de agent din OpenClaw își face treaba.
Rezistență la schimbările site-ului
Una dintre cele mai mari bătăi de cap în web scraping este să te lovești de actualizări ale site-ului care îți rup scripturile. Sistemul de pluginuri și skill-uri al OpenClaw este gândit să fie rezilient. De exemplu, wrapper-ele din jurul bibliotecii Scrapling oferă extragere adaptivă, ceea ce înseamnă că scraper-ul tău poate „reloca” elementele chiar dacă se schimbă aspectul site-ului — un mare avantaj pentru proiectele pe termen lung.
Performanță în lumea reală
În teste comparative, fluxurile bazate pe OpenClaw au arătat:

- Până la 3x mai rapidă extragere pe site-uri complexe, cu mai multe pagini, comparativ cu scraper-ele tradiționale în Python (scrapling.readthedocs.io)
- Rate de succes mai mari pe pagini dinamice, cu mult JavaScript, datorită browserului gestionat
- Gestionare mai bună a paginilor cu conținut mixt (text, imagini, fragmente HTML)
Mărturiile utilizatorilor subliniază adesea capacitatea OpenClaw de a „merge pur și simplu” acolo unde alte instrumente dau greș — mai ales când vine vorba de extragerea datelor de pe site-uri cu layout-uri dificile sau cu măsuri anti-bot.
Cum începi: configurarea OpenClaw pentru web scraping
Gata să intri în subiect? Iată cum pui OpenClaw în funcțiune pe sistemul tău.
Pasul 1: Instalează OpenClaw
OpenClaw este compatibil cu Windows, macOS și Linux. Documentația oficială recomandă să începi cu fluxul ghidat de onboarding:
openclaw onboard
Această comandă te ghidează prin configurarea inițială, inclusiv verificarea mediului și configurarea de bază.
Pasul 2: Instalează dependențele necesare
În funcție de workflow, s-ar putea să ai nevoie de:
- Node.js (pentru gateway-ul de bază)
- Python 3.10+ (pentru pluginuri/skill-uri care folosesc Python, precum wrapper-ele Scrapling)
- Chromium/Chrome (pentru modul browser gestionat)
Pe Linux, poate fi nevoie să instalezi pachete suplimentare pentru suportul browserului. Documentația are o secțiune dedicată de depanare pentru problemele frecvente.
Pasul 3: Configurează instrumentele web
Setează furnizorul de căutare web:
openclaw configure --section web
Asta îți permite să alegi dintre furnizori precum Brave, DuckDuckGo sau Firecrawl.
Pasul 4: Instalează pluginuri sau skill-uri (opțional)
Pentru a debloca scraping-ul avansat, instalează pluginuri sau skill-uri create de comunitate. De exemplu, pentru a adăuga openclaw-plugin-web-scraper:
git clone https://github.com/hvkeyn/openclaw-plugin-web-scraper.git
cd openclaw-plugin-web-scraper
openclaw plugins install .
openclaw gateway restart

Sfaturi pro pentru începători
- Rulează
openclaw security auditdupă instalarea unor pluginuri noi, pentru a verifica vulnerabilitățile (docs.openclaw.ai). - Dacă folosești Node prin nvm, verifică de două ori certificatele CA — nepotrivirile pot rupe cererile HTTPS (docs.openclaw.ai).
- Izolează întotdeauna pluginurile și componentele browserului într-o mașină virtuală sau într-un container, pentru siguranță suplimentară.
Ghid pentru începători: primul tău proiect de scraping cu OpenClaw
Hai să construim un proiect simplu de scraping — fără să ai nevoie de un doctorat în informatică.
Pasul 1: Alege site-ul țintă
Alege un site cu date structurate, cum ar fi o listare de produse sau un director. Pentru acest exemplu, vom extrage titlurile produselor de pe o pagină demo de e-commerce.
Pasul 2: Înțelege structura DOM
Folosește instrumentul „Inspect Element” din browser pentru a găsi etichetele HTML care conțin datele dorite (de exemplu, <h2 class="product-title">).
Pasul 3: Configurează filtrele de extragere
Cu skill-urile OpenClaw bazate pe Scrapling, poți folosi selectori CSS pentru a ținti elementele. Iată un script de exemplu care folosește skill-ul openclaw-ultra-scraping:
PYTHON=/opt/scrapling-venv/bin/python3
$PYTHON scripts/scrape.py fetch "https://example.com/products" --css "h2.product-title::text"
Această comandă preia pagina și extrage toate titlurile produselor.
Pasul 4: Gestionarea în siguranță a datelor
Exportă rezultatele în CSV sau JSON pentru o analiză ușoară:
$PYTHON scripts/scrape.py fetch "https://example.com/products" --css "h2.product-title::text" -f csv -o products.csv
Concepte-cheie explicate
- Schemele instrumentelor: definesc ce poate face fiecare instrument sau skill (fetch, extract, crawl).
- Înregistrarea skill-urilor: adaugă noi capabilități de scraping în OpenClaw prin ClawHub sau prin instalare manuală.
- Gestionarea în siguranță a datelor: validează și curăță întotdeauna rezultatele înainte de a le folosi în producție.
Automatizarea fluxurilor complexe de scraping cu OpenClaw

După ce ai stăpânit bazele, e momentul să automatizezi. Iată cum construiești un workflow care rulează singur, în timp ce tu te ocupi de lucruri mai importante — cum ar fi prânzul.
Pasul 1: Creează și înregistrează skill-uri personalizate
Scrie sau instalează skill-uri care corespund nevoilor tale specifice de extragere. De exemplu, poate vrei să extragi informații despre produse și imagini, apoi să trimiți un raport zilnic.
Pasul 2: Configurează sarcini programate
Pe Linux sau macOS, folosește cron pentru a programa scripturile de scraping:
0 6 * * * /usr/bin/python3 /path/to/scrape.py fetch "https://example.com/products" --css "h2.product-title::text" -f csv -o /data/products_$(date +\%F).csv
Pe Windows, folosește Task Scheduler cu argumente similare.
Pasul 3: Integrează cu alte instrumente
Pentru navigare dinamică (de exemplu, click pe butoane sau autentificare), combină OpenClaw cu Selenium sau Playwright. Multe skill-uri OpenClaw pot apela aceste instrumente sau pot accepta scripturi de automatizare a browserului.
Comparație între workflow manual și automat
| Pas | Workflow manual | Workflow automat OpenClaw |
|---|---|---|
| Extragerea datelor | Rulezi scriptul manual | Programat prin cron/Task Scheduler |
| Navigare dinamică | Dai click manual | Automatizat cu Selenium/skill-uri |
| Exportul datelor | Copy/paste sau descărcare | Auto-export în CSV/JSON |
| Raportare | Rezumat manual | Rapoarte generate automat și trimise pe email |
| Gestionarea erorilor | Le repari pe parcurs | Retry-uri și logging integrate |
Rezultatul? Mai multe date, mai puțină corvoadă și un workflow care crește odată cu ambițiile tale.
Creșterea eficienței: integrarea funcțiilor AI de scraping ale Thunderbit cu OpenClaw
Aici lucrurile devin cu adevărat interesante. În calitate de cofondator al Thunderbit, cred foarte mult în combinarea celor mai bune părți din ambele lumi: motorul flexibil de scraping al OpenClaw și detectarea de câmpuri + exportul cu AI ale Thunderbit.
Cum accelerează Thunderbit OpenClaw
- AI Suggest Fields: Thunderbit poate analiza automat o pagină web și poate recomanda cele mai bune coloane de extras — gata cu ghicitul selectoarelor CSS.
- Export instant de date: exportă datele extrase direct în Excel, Google Sheets, Airtable sau Notion, cu un singur click (Thunderbit Docs).
- Workflow hibrid: folosește OpenClaw pentru navigarea complexă și logica de scraping, apoi trimite rezultatele în Thunderbit pentru maparea câmpurilor, îmbogățire și export.

Exemplu de workflow hibrid
- Folosește browserul gestionat OpenClaw sau skill-ul Scrapling pentru a extrage date brute dintr-un site dinamic.
- Importă rezultatele în Thunderbit.
- Apasă „AI Suggest Fields” pentru a mapa automat datele.
- Exportă în formatul sau platforma preferată.
Combinația asta schimbă regulile jocului pentru echipele care au nevoie atât de putere, cât și de ușurință în utilizare — gândește-te la sales ops, analiști e-commerce și oricine s-a săturat să se lupte cu foi de calcul dezordonate.
Încearcă AI Suggest Fields de la Thunderbit
Depanare în timp real: erori frecvente OpenClaw și cum le repari
Chiar și cele mai bune instrumente mai dau uneori de probleme. Iată un ghid rapid pentru diagnosticarea și rezolvarea problemelor frecvente de scraping cu OpenClaw:
Erori frecvente
- Probleme de autentificare: Unele site-uri blochează boții sau cer login. Folosește browserul gestionat OpenClaw sau integrează Selenium pentru fluxurile de autentificare (docs.openclaw.ai).
- Cereri blocate: rotește user agent-urile, folosește proxy-uri sau redu rata cererilor ca să eviți blocările.
- Eșecuri de parsare: verifică din nou selectoarele CSS/XPath; este posibil ca site-urile să-și fi schimbat structura.
- Erori de plugin/skill: rulează
openclaw plugins doctorpentru a diagnostica problemele cu extensiile instalate (docs.openclaw.ai).
Comenzi de diagnostic
openclaw status– verifică starea gateway-ului și a instrumentelor.openclaw security audit– scanează pentru vulnerabilități.openclaw browser --browser-profile openclaw status– verifică sănătatea automatizării browserului.
Resurse din comunitate
Cele mai bune practici pentru scraping OpenClaw fiabil și scalabil

Vrei ca scraping-ul tău să rămână fluid și sustenabil? Iată checklist-ul meu:
- Respectă robots.txt: extrage doar ce ai voie să extragi.
- Pune frână cererilor: evită să bombardezi site-urile cu prea multe cereri pe secundă.
- Validează rezultatele: verifică întotdeauna datele pentru completitudine și acuratețe.
- Monitorizează utilizarea: loghează rulările de scraping și urmărește erorile sau blocările.
- Folosește proxy-uri la scară: rotește IP-urile pentru a evita limitele de rată.
- Deploy în cloud: pentru joburi mari, rulează OpenClaw într-o mașină virtuală sau într-un mediu containerizat.
- Gestionează erorile cu eleganță: construiește mecanisme de retry și fallback în scripturile tale.
| Ce să faci | Ce să nu faci |
|---|---|
| Folosește pluginuri/skill-uri oficiale | Instalează orbește cod nesigur |
| Rulează audituri de securitate regulat | Ignora avertismentele de vulnerabilitate |
| Testează în staging înainte de producție | Extrage date sensibile sau private |
| Documentează-ți workflow-urile | Te baza pe selectori hardcodați |
Sfaturi avansate: personalizarea și extinderea OpenClaw pentru nevoi unice
Dacă ești gata să treci în modul power user, OpenClaw îți permite să construiești skill-uri și pluginuri personalizate pentru sarcini specializate.
Dezvoltarea de skill-uri personalizate
- Urmează documentația OpenClaw pentru skill SDK ca să creezi noi instrumente de extragere.
- Folosește Python sau TypeScript, în funcție de zona în care te simți mai confortabil.
- Înregistrează-ți skill-ul în ClawHub pentru partajare și reutilizare ușoară.
Funcții avansate
- Înlănțuirea skill-urilor: combină mai mulți pași de extragere (de exemplu, extragi o pagină de listare, apoi vizitezi fiecare pagină de detalii).
- Browsere headless: folosește Chromium-ul gestionat de OpenClaw sau integrează Playwright pentru site-uri cu mult JavaScript.
- Integrarea cu agenți AI: conectează OpenClaw la servicii AI externe pentru parsare sau îmbogățire mai inteligentă a datelor.
Gestionarea erorilor și a contextului
- Construiește o gestionare robustă a erorilor în skill-urile tale (try/except în Python, callbacks de eroare în TypeScript).
- Folosește obiecte de context pentru a transmite starea între pașii de scraping.
Pentru inspirație, aruncă o privire la skill-urile oferite de comunitate și la referința API Scrapling.
Concluzie și idei-cheie
Am parcurs mult teren — de la instalarea OpenClaw și primul tău scraping până la construirea unor fluxuri automatizate, hibride, cu Thunderbit. Iată ce sper să reții:
- OpenClaw este o forță flexibilă, open-source pentru extragerea de date web, mai ales pe site-uri complexe sau dinamice.
- Ecosistemul său de pluginuri/skill-uri îți permite să abordezi orice, de la fetch-uri simple la scraping avansat, în mai mulți pași.
- Combinarea OpenClaw cu funcțiile AI ale Thunderbit face maparea câmpurilor, exportul datelor și automatizarea workflow-ului extrem de ușoare.
- Rămâi sigur și conform: fă audituri ale mediului, respectă regulile site-urilor și validează-ți datele.
- Nu te teme să experimentezi: comunitatea OpenClaw este activă și primitoare — intră în joc, încearcă skill-uri noi și împărtășește-ți reușitele.
Dacă vrei să îți împingi și mai departe eficiența scraping-ului, Thunderbit este aici să te ajute. Iar dacă vrei să continui să înveți, aruncă o privire pe Thunderbit Blog pentru mai multe analize aprofundate și ghiduri practice.
Scraping plăcut — și fie ca selectoarele tale să nimerească mereu ținta.
Întrebări frecvente
1. Ce face OpenClaw diferit de scraper-ele web tradiționale precum BeautifulSoup sau Scrapy?
OpenClaw este construit ca un gateway de agenți, cu instrumente modulare, suport pentru browser gestionat și un sistem de pluginuri/skill-uri. Asta îl face mai flexibil pentru site-uri dinamice, cu mult JavaScript sau bogate în imagini, și mai ușor de automatizat cap-coadă comparativ cu framework-urile tradiționale, intens bazate pe cod (docs.openclaw.ai).
2. Pot folosi OpenClaw dacă nu sunt developer?
Da! Fluxul de onboarding și ecosistemul de pluginuri din OpenClaw sunt prietenoase pentru începători. Pentru sarcini mai complexe, poți folosi skill-uri create de comunitate sau poți combina OpenClaw cu instrumente no-code precum Thunderbit pentru mapare și export ușor al câmpurilor.
3. Cum rezolv problemele frecvente din OpenClaw?
Începe cu openclaw status și openclaw security audit. Pentru probleme cu pluginurile, folosește openclaw plugins doctor. Consultă documentația oficială și issue-urile de pe GitHub pentru soluții la problemele comune.
4. Este sigur și legal să folosesc OpenClaw pentru web scraping?
Ca în cazul oricărui scraper, respectă întotdeauna termenii de utilizare ai site-ului și robots.txt. OpenClaw este open-source și rulează local, dar ar trebui să verifici pluginurile din punct de vedere al securității și să eviți extragerea datelor sensibile sau private fără permisiune (github.com).
5. Cum pot combina OpenClaw cu Thunderbit pentru rezultate mai bune?
Folosește OpenClaw pentru logica de scraping complexă, apoi importă datele brute în Thunderbit. AI Suggest Fields din Thunderbit îți va mapa automat datele, iar tu poți exporta direct în Excel, Google Sheets, Notion sau Airtable — făcând workflow-ul mai rapid și mai fiabil (Thunderbit Docs).
Vrei să vezi cum poate Thunderbit să îți ducă scraping-ul la nivelul următor? Descarcă extensia Chrome și începe chiar azi să construiești workflow-uri hibride, mai inteligente. Și nu uita să dai o tură și pe canalul Thunderbit de YouTube pentru tutoriale practice și sfaturi.
Încearcă Thunderbit pentru web scraping mai inteligent Get Started Free
Află mai multe
- Cum să instalezi extensia Claude pentru Chrome: un ghid simplu
- Ce este Markdown pentru agenți de la Cloudflare? O prezentare detaliată
- Top 10 cele mai bune instrumente de crawling pentru extragere eficientă de date web
- Top 10 cele mai bune instrumente software de web scraper în 2026
- Cum să cauți eficient o adresă de email în 2026




