
Ritmul știrilor digitale de azi este pur și simplu amețitor. În fiecare minut, mii de titluri sunt publicate, actualizate sau editate discret — pe site-uri consacrate, bloguri de nișă și fluxuri sociale.
Ca să punem lucrurile în perspectivă, preia peste 4 milioane de articole de presă în fiecare zi, în timp ce urmărește știri în peste 100 de limbi și își actualizează fluxul global la fiecare 15 minute.
Pentru oricine lucrează în media, cercetare sau business intelligence, să încerci să ții pasul manual cu acest torent e ca și cum ai încerca să golești cu o cană un vas care se scufundă.
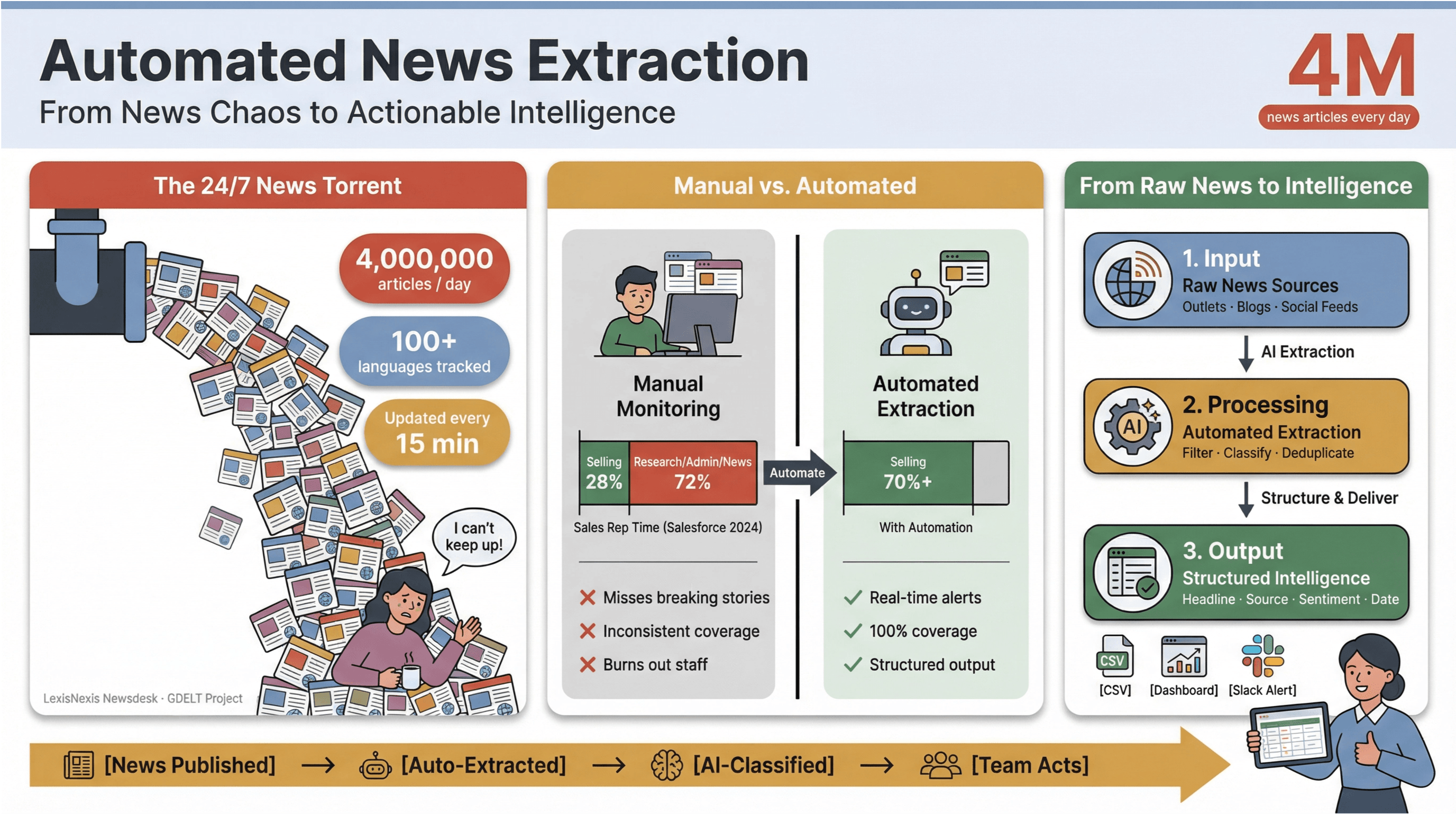
Am văzut pe propria piele cât timp consumă monitorizarea manuală a știrilor și câte resurse irosește. Echipele de vânzări petrec mai puțin de o treime din săptămână vânzând efectiv — — iar restul se pierde în cercetare, sarcini administrative și, da, în jonglatul nesfârșit între taburile de știri.
De aceea, Extracția automată a știrilor a devenit arma secretă a echipelor moderne: este singura modalitate de a transforma haosul ciclului de știri 24/7 în informații structurate, utile și acționabile — fără să-ți epuizezi oamenii și fără să ratezi poveștile care contează cel mai mult.
Hai să vedem ce înseamnă cu adevărat Extracția automată a știrilor, de ce este esențială pentru oricine se bazează pe date de știri în timp real și cum poți construi un flux de lucru robust și conform cu ajutorul celor mai bune instrumente (inclusiv cum face tot procesul surprinzător de simplu — chiar și pentru persoane non-tehnice, cum e mama mea).
Extracția automată a știrilor: de ce este esențială pentru redacțiile moderne
Extragerea automată a știrilor este exact ceea ce pare: folosirea unui software pentru a colecta automat conținutul de știri și a-l transforma în date structurate, ușor de căutat — adică rânduri și coloane, nu pagini web dezordonate sau PDF-uri. În practică, asta înseamnă că poți monitoriza sute (sau mii) de surse, poți extrage câmpuri-cheie precum titlul, ora publicării, autorul și textul articolului și poți trimite datele în dashboard-uri, alerte sau analize ulterioare — fără să mai folosești vreodată Ctrl+C/Ctrl+V.
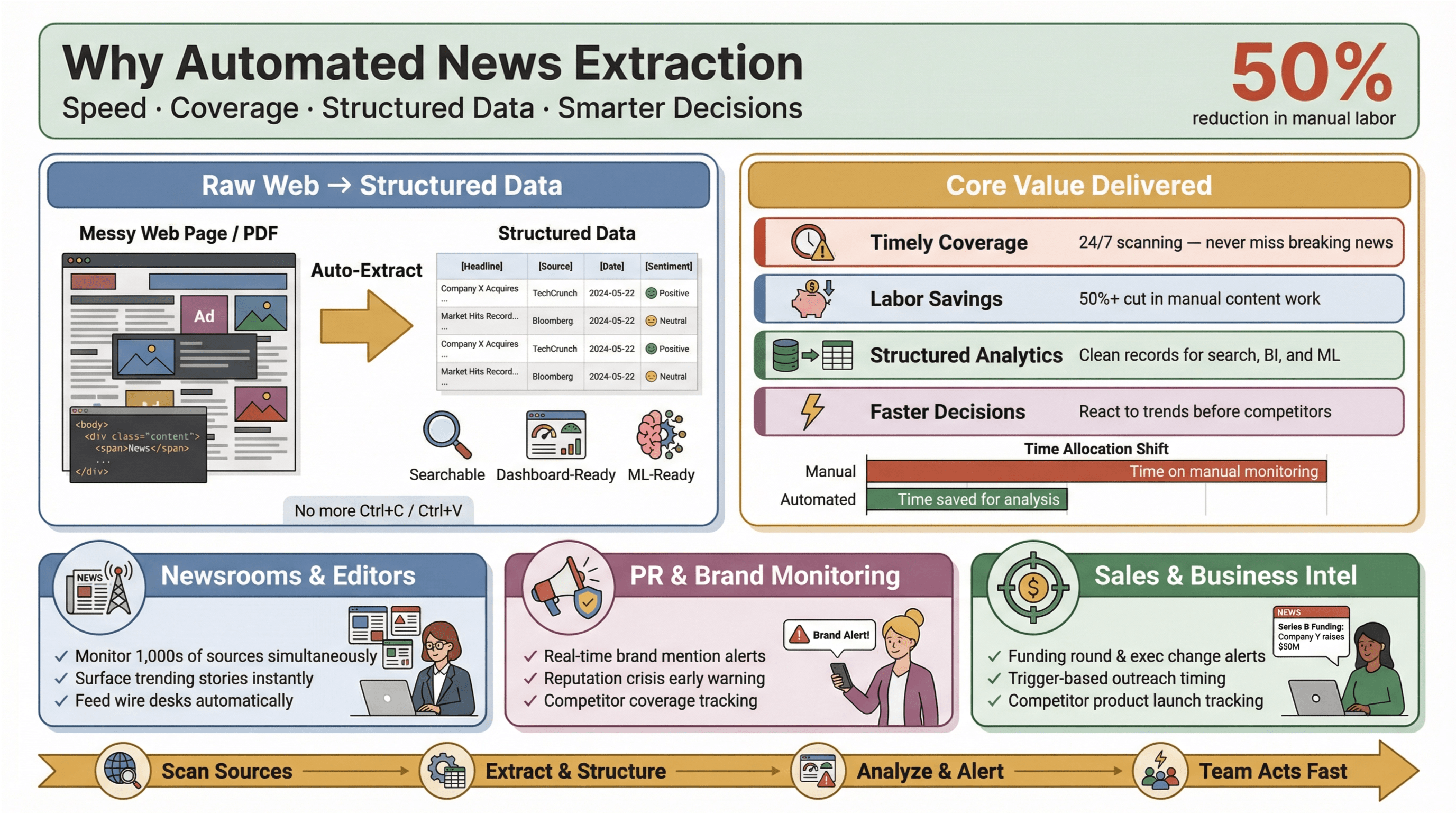 De ce contează asta? Pentru că, în peisajul actual al știrilor, viteza este totul. Fie că ești editor într-o redacție, PR manager care urmărește mențiunile de brand sau analist de business care monitorizează mișcările concurenței, a afla primul poate face diferența dintre a prinde o oportunitate și a recupera întârzierea. Instrumentele automate de extracție le permit chiar și echipelor mici să joace la nivel mare — adunând date de știri în timp real de pe tot webul, reducând munca manuală și scoțând la suprafață poveștile care contează cel mai mult.
De ce contează asta? Pentru că, în peisajul actual al știrilor, viteza este totul. Fie că ești editor într-o redacție, PR manager care urmărește mențiunile de brand sau analist de business care monitorizează mișcările concurenței, a afla primul poate face diferența dintre a prinde o oportunitate și a recupera întârzierea. Instrumentele automate de extracție le permit chiar și echipelor mici să joace la nivel mare — adunând date de știri în timp real de pe tot webul, reducând munca manuală și scoțând la suprafață poveștile care contează cel mai mult.
Iar impactul este real: studiile arată că automatizarea poate reduce munca manuală pentru actualizările de conținut cu cel puțin 50%, eliberând timp pentru analiză și luarea deciziilor.
Valoarea de bază a extracției automate a știrilor în industria media
Să fim practici. Ce aduce concret Extracția automată a știrilor pentru redacții și echipele de business?
- Acoperire la timp și completă: Nu mai ratezi știrile de ultim moment doar pentru că cineva a uitat să verifice un feed. Instrumentele automate scanează sursele 24/7, astfel încât să nu pierzi niciun moment important.
- Economii de muncă și costuri: Echipele mici și medii pot monitoriza la fel de multe surse ca jucătorii mari — fără să angajeze o armată de interni.
- Date structurate pentru analiză: În loc să răscolești articole nestructurate, primești înregistrări curate, structurate, gata pentru căutare, dashboard-uri și machine learning.
- Decizii mai rapide și mai inteligente: Datele de știri în timp real îți permit să reacționezi la schimbările din piață, crizele de PR sau tendințele emergente înaintea concurenței.
Să luăm PR și comunicarea: platforme precum și poziționează monitorizarea media în timp real drept esențială pentru protejarea reputației și reacția rapidă la acoperirea negativă. În vânzări, alertele de știri în timp real devin „context cards” pentru prospectare — de la runde de finanțare și schimbări la nivel de executivi până la lansări de produse care declanșează outreach-ul exact la momentul potrivit.
Alegerea instrumentelor potrivite pentru extracția știrilor în funcție de scenariu
Nu toate instrumentele de extracție a știrilor sunt la fel. Alegerea corectă depinde de obiectivele tale, de nivelul tău tehnic și de tipurile de știri care te interesează. Iată un cadru care te ajută să găsești varianta potrivită:
Evaluarea ușurinței în utilizare și a accesibilității
Pentru majoritatea utilizatorilor de business și a jurnaliștilor, ușurința în utilizare nu este negociabilă. Vrei un instrument care funcționează imediat, fără programare și fără configurări complicate. Platforme no-code și low-code precum , și îți permit să construiești scrapers vizual — pur și simplu indici, dai click și extragi.
Thunderbit, în special, se remarcă prin procesul în doi pași: descrii ce vrei, lași AI-ul să propună câmpurile și apeși „Scrape”. Chiar și utilizatorii fără competențe tehnice pot pune la punct un flux de date de știri în minute, nu în ore.
Considerații privind securitatea și confidențialitatea datelor
Cu date multe vine și o mare responsabilitate. Instrumentele de extracție a știrilor accesează adesea conținut sensibil, așa că securitatea și conformitatea trebuie să fie prioritare. Caută:
- Criptarea datelor (în tranzit și în repaus)
- Politici clare de confidențialitate (Thunderbit, de exemplu, declară că nu vinde datele utilizatorilor și accesează doar conținutul pe care alegi să-l extragi)
- Permisiuni granulare (mai ales pentru extensiile de browser — verifică întotdeauna la ce date poate accesa instrumentul)
- Conformitate cu legislația locală (GDPR, CCPA și, pentru utilizatorii din UE, )
Pentru extra liniște, alege furnizori de încredere, verifică permisiunile extensiilor și limitează accesul doar la ceea ce este necesar.
Potrivirea instrumentelor cu tipurile de știri și nevoile industriei
Unele instrumente excelează în anumite domenii de știri:
- Finanțe: API-uri precum și oferă clustering, analiză de sentiment și detectarea evenimentelor pentru știrile financiare.
- Tehnologie și startup-uri: Extragerea personalizată cu Thunderbit sau Octoparse îți permite să țintești bloguri de nișă, comunicate de presă sau listări de evenimente.
- Politică și politici publice: Bazele de date licențiate precum și oferă acces la surse premium și arhive.
Dacă trebuie să monitorizezi un mix de surse consacrate, de nișă și internaționale — inclusiv pe cele fără API-uri — scrapers flexibili, bazați pe AI, precum Thunderbit sunt cea mai bună alegere.
Avantajele unice ale Thunderbit pentru extracția datelor de știri în timp real
Acum, hai să vorbim despre ce face din o alegere remarcabilă pentru extracția automată a știrilor — mai ales dacă vrei date de știri în timp real fără bătăi de cap tehnice.
Thunderbit este o extensie Chrome de web scraper cu AI concepută pentru utilizatori de business, jurnaliști și analiști care au nevoie de conținut de știri actualizat și structurat de pe orice site. Iată de ce a devenit instrumentul meu preferat:
- AI Suggest Fields: Thunderbit citește pagina de știri și sugerează automat cele mai bune coloane de extras — titlul, ora publicării, autorul, rezumatul și altele. Nu trebuie să te chinui cu selectoare sau șabloane.
- Subpage Scraping: Ai nevoie de articolul complet, nu doar de titlu? Thunderbit poate vizita fiecare link de știre, poate extrage textul integral, entitățile și etichetele și poate reuni totul într-un singur tabel structurat.
- Export în masă și actualizări instant: Exportă datele de știri direct în Excel, Google Sheets, Airtable sau Notion cu un singur click. Gata cu maratoanele de copy-paste sau cu chinul fișierelor CSV.
- Scheduled Scraping: Setează sarcini recurente (orare, zilnice sau la intervale personalizate) pentru a-ți menține fluxul de știri proaspăt — ideal pentru breaking news, monitorizarea pieței sau cercetare continuă.
- Adaptabilitate: AI-ul Thunderbit se adaptează la schimbările de layout și la site-urile de știri de nișă, așa că petreci mai puțin timp reparând scrapers stricte și mai mult timp analizând datele.
Cu peste și un rating de 4,8 stele, este folosit cu încredere de echipe din toată lumea pentru totul, de la monitorizarea PR până la intelligence competitiv.
Detectarea câmpurilor bazată pe AI și extragerea subpaginilor
Una dintre funcțiile de top ale Thunderbit este detectarea câmpurilor bazată pe AI. Dă click pe „AI Suggest Fields”, iar instrumentul scanează pagina de știri — identificând câmpuri-cheie precum titlul, data, autorul și rezumatul. Poți ajusta sau adăuga câmpuri personalizate (de exemplu, „marchează acest articol ca ‘câștiguri’ dacă menționează rezultatele trimestriale”), iar AI-ul Thunderbit se ocupă de restul.
Extragerea subpaginilor schimbă jocul pentru știri: extragi pagina principală sau lista unei secțiuni pentru titluri, apoi lași Thunderbit să viziteze fiecare URL al articolului pentru a extrage textul complet, entitățile și chiar imaginile. Asta înseamnă că obții înregistrări complete și îmbogățite despre știri — gata pentru căutare, dashboard-uri sau analiză AI ulterioară.
Export în masă și actualizări instant
Thunderbit face exportul datelor de știri fără efort. Cu un singur click, poți trimite fluxul structurat de știri în Google Sheets, Airtable, Notion sau îl poți descărca ca CSV/Excel. Pentru echipele care trăiesc în foi de calcul sau în instrumente BI, asta înseamnă enorm de mult timp economisit.
Și pentru că Thunderbit suportă scheduled scraping, îl poți seta să ruleze la fiecare oră, în fiecare zi sau după propriul program personalizat — astfel încât datele tale despre știri să fie mereu actualizate. Nu mai trebuie să aștepți ca Google Alerts să indexeze poveștile cu zile întârziere.
Depășirea provocărilor operaționale în soluțiile de date de știri în timp real
Chiar și cu cele mai bune instrumente, extracția știrilor în timp real vine cu propriul set de provocări. Iată cum le poți aborda pe cele mai frecvente:
Gestionarea latenței și a prospețimii datelor
- Programează extragerile în funcție de viteza știrilor: Pentru breaking news, setează scraper-ele să ruleze la fiecare 15–30 de minute (aliniat ciclului de actualizare al ). Pentru subiecte mai lente, zilnic sau orar poate fi suficient.
- Monitorizează decalajul dintre publicare și preluare: Urmărește diferența dintre momentul publicării unui articol și momentul în care sistemul tău îl capturează. Dacă decalajul crește, verifică blocajele sau încetinirile.
- Re-extrage pentru „editări discrete”: Articolele de știri sunt adesea actualizate după publicare. Programează o a doua extragere după 24 de ore pentru a prinde corecturile sau editările ascunse ().
Gestionarea limitelor API și a variabilității surselor
- Respectă cotele API: Dacă folosești API-uri de știri, urmărește limitele de rată — distribuie cererile în timp și, dacă se poate, cache-uiește rezultatele ().
- Elimină duplicatele și canonicalizează: Poveștile apar adesea pe mai multe URL-uri sau sunt actualizate. Capturează URL-urile canonice și folosește hash-uri (de exemplu, titlu + dată) pentru a evita duplicatele ().
- Gestionează conținutul dinamic: Pentru site-uri cu infinite scroll sau lazy loading, folosește instrumente care suportă randarea dinamică și urmăresc schimbările de layout ().
Analiza inteligentă a datelor din știri: rolul AI și al machine learning
Extragerea știrilor este doar primul pas. Valoarea reală vine din analizarea și acționarea asupra acestor date — iar aici strălucesc AI și machine learning.
- Extragerea entităților: Folosește NLP pentru a identifica persoanele, organizațiile și locurile menționate în fiecare articol ().
- Clasificarea pe subiecte: Etichetează automat articolele după subiect, sentiment sau urgență — permițând dashboard-uri și alerte mai inteligente ().
- Clustering de evenimente: Grupează poveștile duplicate sau înrudite din diferite publicații, ca să vezi imaginea de ansamblu și nu doar o avalanșă de titluri aproape identice.
- Personalizare și targetare: Folosește datele de știri în timp real pentru a segmenta audiențele, a îmbunătăți targetarea reclamelor sau a recomanda conținut — crescând engagementul și ROI-ul.
De exemplu, echipele de PR folosesc analizele de știri în timp real pentru a observa crizele emergente înainte să devină virale, iar echipele de vânzări îmbogățesc listele de prospecti cu „trigger events” precum runde de finanțare sau angajări la nivel executiv.
Checklist de bune practici pentru Extracția automată a știrilor
Iată o listă scurtă de verificare pentru a-ți menține fluxul de extracție a știrilor fără probleme:
| Bună practică | De ce contează | Cum o implementezi |
|---|---|---|
| Programează extrageri frecvente | Reduci întârzierile de date și prinzi știrile de ultim moment | Potrivește frecvența cu viteza știrilor (de ex. la fiecare 15 min pentru subiecte rapide) |
| Folosește extracție bazată pe AI | Se adaptează la schimbările de layout și reduce timpul de configurare | Instrumente precum Thunderbit, Diffbot, Zyte API |
| Elimină duplicatele și canonicalizează | Eviți alertele duplicate și menții datele curate | Capturează URL-uri canonice, folosește hash-uri pentru deduplicare |
| Monitorizează calitatea extracției | Depistezi câmpuri lipsă, deviații sau eșecuri | Urmărește % de înregistrări complete, latența și ratele de eroare |
| Respectă limitele legale și de conformitate | Evită riscul juridic și menține încrederea | Preferă API-uri/feed-uri oficiale, revizuiește termenii, minimizează datele personale |
| Exportă în formate structurate | Permite analize ulterioare | CSV, Excel, Sheets, Notion, Airtable |
| Programează re-extrageri pentru modificări | Prinde schimbările apărute după publicare | Revino la articole după 24h/1săpt. (modelul GDELT) |
| Asigură-ți fluxul | Protejează datele sensibile | Criptare, controale de acces, instrumente de încredere |
Construirea unui flux de lucru robust pentru extracția automată a știrilor
Ești gata să-ți construiești propriul „black box” pentru date de știri? Iată un workflow pas cu pas:
- Identifică sursele: Fă o listă cu site-urile de știri, blogurile sau API-urile pe care vrei să le monitorizezi.
- Configurează extracția: Folosește Thunderbit sau instrumentul ales pentru a defini câmpurile (AI Suggest Fields face asta foarte ușor).
- Programează extragerile: Setează frecvența în funcție de viteza știrilor — orar pentru breaking news, zilnic pentru subiecte mai lente.
- Îmbogățirea subpaginilor: Pentru fiecare titlu, extrage articolul complet pentru text, entități și etichete.
- Elimină duplicatele și normalizează: Capturează URL-uri canonice, fă hash-uri pentru înregistrări și standardizează câmpurile.
- Exportă și integrează: Trimite datele structurate în Excel, Google Sheets, Airtable sau Notion pentru analiză.
- Monitorizează și adaptează-te: Urmărește calitatea extracției, observă schimbările de layout și ajustează când e nevoie.
- Rămâi conform: Revizuiește termenii, respectă robots.txt și minimizează datele personale.
Pentru un workflow vizual, gândește-te așa:
Surse → Extracție (câmpuri AI) → Îmbogățire subpagini → Deduplicare → Export → Analiză/Alerte → Monitorizare
Concluzie și idei-cheie
Extracția automată a știrilor nu mai este doar un „nice-to-have” — este o necesitate pentru oricine trebuie să rămână în față într-o lume în care știrile apar (și se schimbă) de la un minut la altul. Urmând bunele practici și folosind instrumentele potrivite, poți transforma furtunul de date al știrilor digitale într-un flux stabil de informații structurate și acționabile.
Idei-cheie:
- Scara și viteza știrilor online cer automatizare — monitorizarea manuală pur și simplu nu poate ține pasul.
- Instrumentele automate de extracție a știrilor economisesc timp, reduc costurile și le permit echipelor mici să rivalizeze cu organizații mult mai mari.
- Alegerea instrumentului potrivit înseamnă echilibru între ușurință în utilizare, securitate și adaptabilitate — Thunderbit iese în evidență prin simplitatea bazată pe AI și opțiunile de export în timp real.
- Construiește-ți fluxul de lucru în jurul prospețimii, deduplicării, conformității și monitorizării calității pentru a asigura date de știri fiabile și utile.
- AI și machine learning deblochează și mai multă valoare — permițând targetare mai inteligentă, personalizare și decizii mai bune.
Dacă încă dai copy-paste la titluri sau aștepți ca Google Alerts să te ajungă din urmă, e momentul să treci la nivelul următor. și vezi cât de ușoară poate fi Extracția automată a știrilor. Pentru mai multe sfaturi, fluxuri de lucru și analize detaliate, aruncă un ochi pe .
Întrebări frecvente
1. Ce este extracția automată a știrilor și cum funcționează?
Extracția automată a știrilor este procesul de folosire a unui software pentru a colecta articole de știri și a le transforma în date structurate (cum ar fi tabele sau JSON) pentru analiză, căutare sau alerte. Instrumente precum Thunderbit folosesc AI pentru a identifica câmpurile cheie (titlu, oră, autor, textul articolului) și a le extrage automat din pagini web sau API-uri.
2. De ce sunt datele de știri în timp real atât de importante pentru business?
Datele de știri în timp real le permit companiilor să reacționeze rapid la evenimente de piață, crize de PR sau mișcările concurenților. Fie că lucrezi în vânzări, PR sau cercetare, știrile actualizate te ajută să iei decizii mai rapide și mai inteligente și să rămâi înaintea competiției.
3. Cum face Thunderbit extracția știrilor mai ușoară pentru utilizatorii non-tehnici?
Thunderbit oferă un proces simplu, în doi pași: descrii ce date vrei, iar AI-ul propune câmpurile. Cu funcții precum extragerea subpaginilor și exportul instant în Excel sau Google Sheets, chiar și utilizatorii non-tehnici pot construi în câteva minute fluxuri robuste de date despre știri.
4. Care sunt considerentele legale și de conformitate pentru extracția știrilor?
Verifică întotdeauna termenii de utilizare ai site-urilor vizate, preferă API-urile sau feed-urile oficiale atunci când sunt disponibile și respectă instrucțiunile din robots.txt. Evită extragerea conținutului care necesită autentificare sau este în spatele unui paywall fără permisiune și minimizează colectarea datelor personale pentru a rămâne în conformitate cu legislația privind confidențialitatea.
5. Cum pot să mă asigur că fluxul meu de extracție a știrilor rămâne fiabil în timp?
Programează extrageri regulate, monitorizează calitatea extracției și folosește instrumente care se adaptează la schimbările de layout (precum extracția bazată pe AI a Thunderbit). Elimină duplicatele, urmărește decalajul dintre publicare și extracție și setează alerte pentru erori sau câmpuri lipsă, ca să-ți menții fluxul sănătos și actualizat.
Află mai multe