

Cu câteva luni în urmă, unul dintre utilizatorii noștri a pus o întrebare care m-a făcut să îngheț cu cafeaua la jumătatea sorbiturii: „Dacă extrag public prețurile produselor de pe Coupang, ajung într-un tribunal coreean?” Sincer, nu aveam un răspuns scurt și sigur — și nici majoritatea ghidurilor juridice pe care le-am găsit online.
Întrebarea aceea mi-a rămas în minte pentru că este aceeași pe care o caută în liniște, în fiecare săptămână, mii de operatori de e-commerce, echipe de vânzări și fondatori SaaS. Piața globală a serviciilor de web scraping a ajuns la aproximativ 1,03 miliarde USD în 2024 și crește rapid. Mai multe companii ca oricând colectează date de pe web — și tot mai multe se întreabă unde sunt limitele legale în Coreea. Coreea nu interzice web scraping-ul în mod absolut.
Dar patru statute majore pot deveni aplicabile, în funcție de ce extragi, cum extragi și de ce. Cazul reper pe care îl citează toată lumea este hotărârea Curții Supreme din Coreea în dosarul Yanolja (2021Do1533, pronunțată la 12 mai 2022), care a achitat un instrument de scraping al unui competitor pe acuzații penale — iar apoi, pe latura civilă separată, a obligat aceeași companie la despăgubiri de aproximativ 1 miliard KRW. Acest rezultat dublu este cel mai important lucru pe care trebuie să-l înțeleagă un nespecialist despre legea coreeană a scraping-ului și reprezintă coloana vertebrală a acestui ghid. Nu ai nevoie de diplomă în drept — doar de un cadru practic de evaluare a riscului pe care chiar îl poți folosi.
Dificultate: Începător (nu este necesară experiență juridică sau tehnică)
Timp necesar: ~15 minute de lectură; poate fi folosit ca referință permanentă
Ce îți trebuie: O înțelegere de bază a ceea ce face web scraping-ul (dacă ai nevoie de o reîmprospătare, vezi articolul nostru despre ce este web scraping)
Este legal web scraping-ul în Coreea? Răspunsul scurt
Web scraping-ul în sine nu este ilegal în Coreea. Este o tehnologie neutră — la fel ca un browser web sau o formulă dintr-un spreadsheet. Instanțele coreene s-au concentrat constant nu pe instrument, ci pe conduita din jurul folosirii lui.
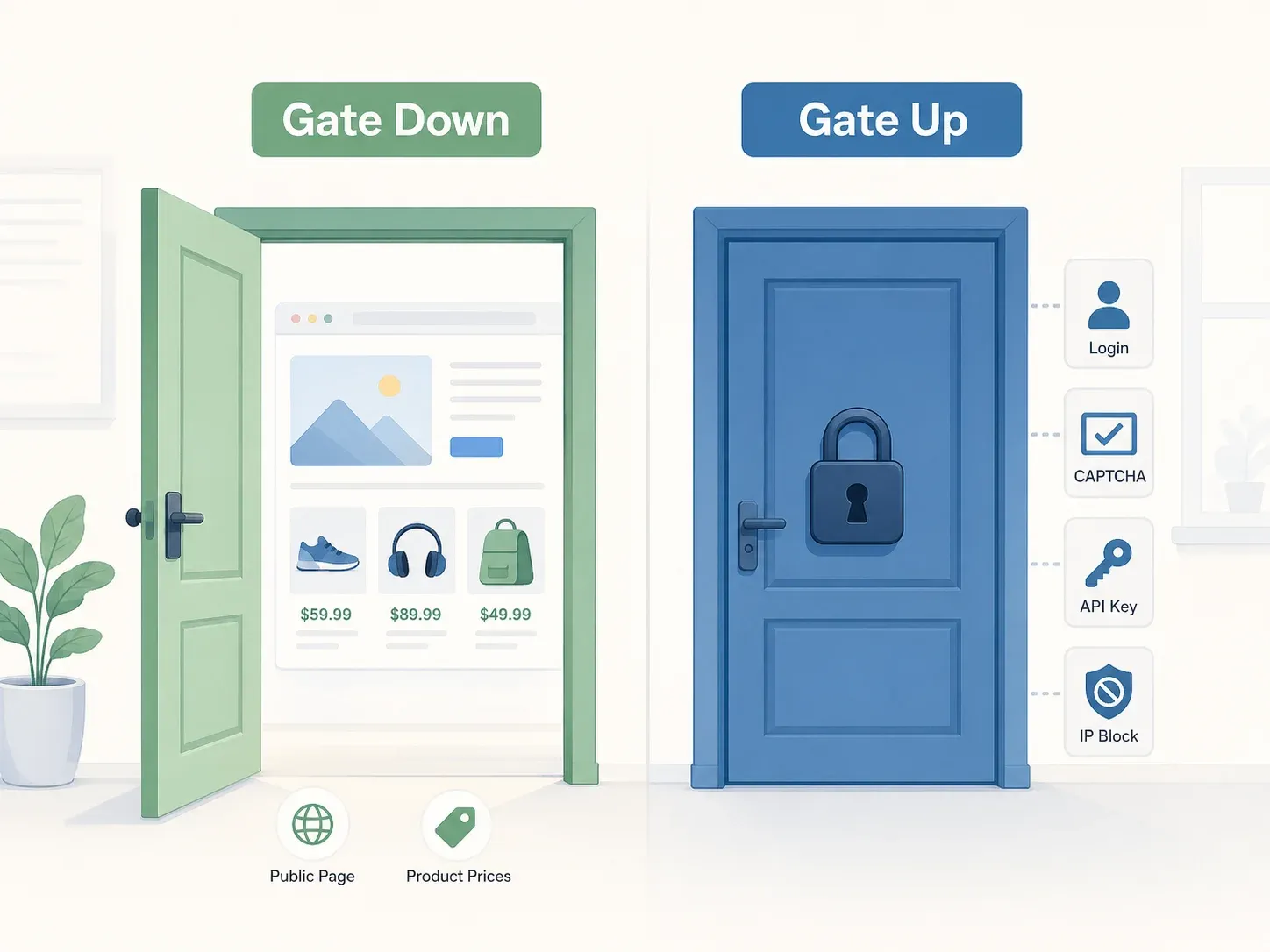
Cel mai bun model mental vine din decizia Curții Supreme în cazul Yanolja: principiul „poarta sus vs. poarta jos”. Dacă un site nu are restricții obiective de acces — fără zid de autentificare, fără CAPTCHA, fără cerință de API key, fără blocare IP — poarta este „jos”, iar accesarea datelor disponibile public este, în general, nu infracțiune conform Legii rețelelor de informații și comunicații din Coreea (ICNA). Curtea a analizat în mod specific dacă „măsurile de protecție, termenii de utilizare și alte împrejurări relevante obiectiv” restricționau accesul și a constatat că serverul API al Yanolja era accesibil liber prin aplicația publică.
Dar „nu este infracțiune” nu înseamnă „fără risc”.
Răspunderea civilă este o întrebare complet separată. Poți evita urmărirea penală și totuși să te confrunți cu o despăgubire de ordinul miliardelor de woni. Cazul Yanolja a demonstrat acest lucru cu o claritate dureroasă.
Patru legi coreene pot fi aplicabile web scraping-ului:
- ICNA (Information and Communications Network Act) — regula „nu intra fără drept”
- Legea drepturilor de autor — drepturile producătorului de baze de date
- PIPA (Personal Information Protection Act) — regulile privind colectarea datelor personale
- UCPA (Unfair Competition Prevention Act) — clauza generală „nu profita gratuit”
Restul ghidului mapează aceste legi pe scenarii reale, ca să poți vedea unde se încadrează de fapt proiectul tău de scraping.
Cadrul verde-galben-roșu de risc pentru web scraping în Coreea
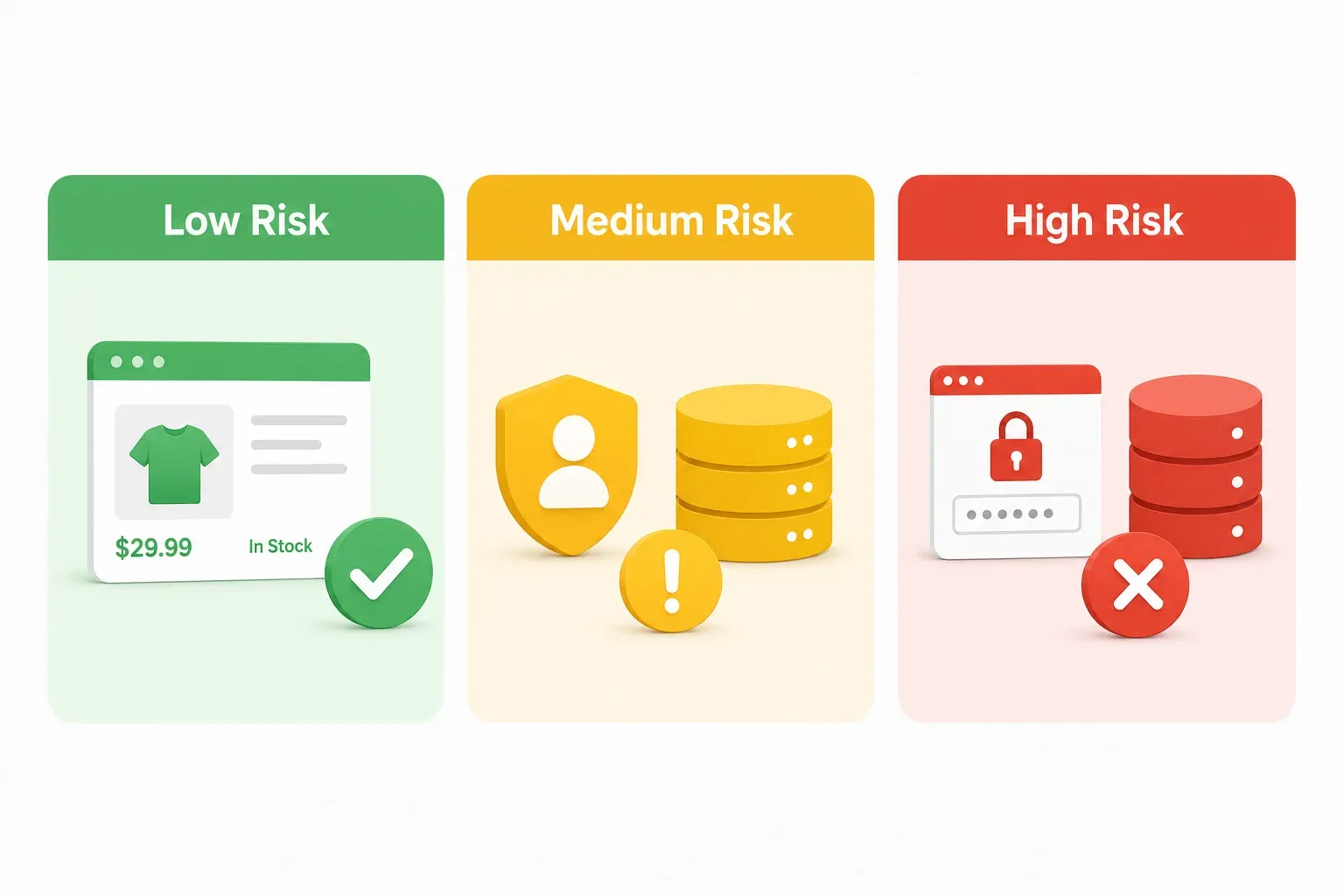
Fiecare articol juridic pe care l-am găsit despre legea coreeană a scraping-ului sună ca și cum ar fi fost scris pentru avocați. Dacă ești manager de operațiuni e-commerce sau fondator SaaS, nu ai nevoie de o analiză de 40 de pagini a statutului — ai nevoie de o metodă rapidă de a evalua riscul înainte de a porni un proiect. Gândește-te la asta ca la un semafor. Verde înseamnă pornește (cu prudența obișnuită). Galben înseamnă încetinește și uită-te în oglinzi. Roșu înseamnă oprește-te și sună un avocat.
Zona verde: scenarii cu risc redus de scraping
| Scenariu | Nivel de risc | Lege/legi-cheie | De ce |
|---|---|---|---|
| Extragerea listărilor publice de produse (fără login, fără CAPTCHA) | 🟢 Redus | ICNA, Legea drepturilor de autor | Hotărârea Yanolja: fără restricții de acces = fără încălcare ICNA; datele factuale (prețuri, disponibilitate) nu sunt expresie creativă |
| Extragerea prețurilor publice doar pentru analiză internă | 🟢 Redus | UCPA, Legea drepturilor de autor | Date factuale, scop limitat, fără redistribuire concurențială |
| Colectarea faptelor nepersonale, neprotejate prin drepturi de autor, de pe pagini publice | 🟢 Redus | ICNA, Legea drepturilor de autor | Nu este ocolită nicio barieră de acces; faptele individuale nu sunt protejate |
Decizia penală Yanolja ancorează această zonă. Curtea Supremă nu a constatat o intruziune ICNA deoarece serverul API era accesibil liber — utilizatorii obișnuiți îl puteau accesa prin aplicație, cu sau fără membru, iar nicio măsură de protecție separată nu bloca accesul API.
Pentru utilizatorii Thunderbit, acesta este punctul ideal. Dacă extragi pagini publice de e-commerce sau imobiliare folosind modul cloud scraping — colectând numele produselor, prețurile, disponibilitatea sau metadatele listărilor, în timp ce excluzi câmpurile cu date personale — de regulă te afli în zona verde. (Totuși, „de regulă” nu înseamnă „întotdeauna”, iar nuanțele le explic mai jos.)
Încearcă Thunderbit pentru extragerea datelor publice
Zona galbenă: scenarii cu risc mediu de scraping
| Scenariu | Nivel de risc | Lege/legi-cheie | De ce |
|---|---|---|---|
| Extragerea datelor personale (nume, emailuri, numere de telefon) chiar și de pe pagini publice | 🟡 Mediu | PIPA, ICNA | PIPA se aplică indiferent de vizibilitatea publică; amendamentele din 2023 au înăsprit regulile privind consimțământul |
| Extragerea unor volume mari care pot constitui o „parte substanțială” din baza de date a unui competitor | 🟡 Mediu | Legea drepturilor de autor, UCPA | Test cantitativ + calitativ în dreptul coreean |
| Ignorarea semnalelor robots.txt | 🟡 Mediu | Dovadă de rea-credință | Nu este infracțiune în sine, dar poate fi folosit împotriva ta în instanță |
| Extragerea datelor publice, dar folosirea lor pentru a concura direct cu sursa | 🟡 Mediu | UCPA | Profitare gratuită de pe urma investiției unei alte platforme |
Datele personale sunt principalul declanșator al zonei galbene.
Chiar dacă un număr de telefon sau un email este vizibil pe o pagină publică, PIPA tot se aplică. Reforma PIPA din 2023 a extins drepturile persoanei vizate și a înăsprit cerințele de consimțământ. Iar în 2024, Comisia pentru Protecția Informațiilor Personale din Coreea (PIPC) a emis orientări care abordează în mod specific informațiile personale disponibile public în contextul AI și al colectării de date — clarificând că simpla accesibilitate publică nu reprezintă o permisiune generală.
Contează și volumul. Curtea Supremă din cazul Yanolja a spus că atât factorii cantitativi, cât și cei calitativi stabilesc dacă ai copiat o „parte substanțială” a unei baze de date. Compară porțiunea copiată cu baza de date în ansamblu și întreabă-te dacă reflectă investiția substanțială a producătorului.
Zona roșie: scenarii cu risc ridicat de scraping
| Scenariu | Nivel de risc | Lege/legi-cheie | De ce |
|---|---|---|---|
| Extragerea din spatele unui zid de autentificare sau ocolirea controalelor de acces | 🔴 Ridicat | ICNA Art. 48 | „Poarta sus” = acces neautorizat; risc ridicat de urmărire penală |
| Ocolirea CAPTCHA, a interdicțiilor IP sau a sistemelor de detectare a roboților | 🔴 Ridicat | ICNA Art. 48(4) | Amendamentul din 2024 vizează în mod specific instrumentele/dispozitivele de ocolire |
| Copierea și revânzarea întregii baze de date a unui competitor | 🔴 Ridicat | Legea drepturilor de autor (drepturi DB), UCPA | Reproducere substanțială + profitare gratuită comercială |
| Colectarea de informații personale fără bază legală pentru marketing/contactare | 🔴 Ridicat | PIPA | Până la 5 ani / amendă de 50 milioane KRW; sancțiuni administrative de până la 3% din venituri |
O completare din 2024 la ICNA — Articolul 48(4) — interzice acum în mod specific instalarea, transferul sau distribuirea programelor ori dispozitivelor tehnice care ocolesc „procedurile normale de protecție sau autentificare” fără un motiv legitim.
Separat, o decizie a Curții Supreme din noiembrie 2024 (2021Do5555) a întărit ideea că intruziunea neautorizată într-o rețea poate exista chiar și fără distrugerea fizică a măsurilor de protecție. Este suficient să folosești identificatorii altcuiva sau comenzi necorespunzătoare pentru a evita limitele de acces.
Cele patru legi coreene care se aplică web scraping-ului
| Lege | Ce protejează | Când devine aplicabilă pentru cei care fac scraping |
|---|---|---|
| ICNA Art. 48 | Stabilitatea rețelei, dreptul de acces | Ocolirea login-ului, CAPTCHA, autentificării, blocărilor IP, limitelor de API key |
| Legea drepturilor de autor (Art. 93) | Operă creativă + drepturile producătorului de bază de date | Copierea conținutului expresiv, a imaginilor sau a tuturor părților/substanțiale dintr-o bază de date |
| PIPA | Informații personale, drepturile persoanei vizate | Colectarea numelor, numerelor de telefon, emailurilor, ID-urilor — chiar și de pe pagini publice |
| UCPA (Art. 2(1)(k) și (m)) | Concurență loială, date cu valoare comercială | Profitare gratuită de pe urma investiției în date a altei platforme pentru propriul tău business concurent |
ICNA Articolul 48: regula „nu intra fără drept”
ICNA Articolul 48(1) spune că nimeni nu trebuie să pătrundă într-o rețea de informații și comunicații „fără drept de acces legitim sau dincolo de dreptul de acces permis”. În termeni de scraping: dacă site-ul are restricții de acces pe care le ocolești, încalci legea. Dacă nu există restricții — pagină publică, fără login — de regulă ești în regulă.
Pedeapsa pentru încălcare este de până la cinci ani de închisoare sau amendă de până la 50 milioane KRW conform Articolului 71 din ICNA.
O nuanță importantă: Curtea Supremă din Coreea a tratat constant restricțiile din Termenii și Condițiile de Utilizare diferit de restricțiile de acces. Termenii aplicației Yanolja limitau reutilizarea comercială și interziceau programele automate care încărcau serverul, dar Curtea a considerat că aceste clauze nu restricționau în mod obiectiv accesul la serverul API în sine.
Legea drepturilor de autor: drepturile producătorului de bază de date
Legea coreeană a drepturilor de autor protejează separat producătorii de baze de date, distinct de drepturile de autor asupra conținutului individual. Conform Articolului 93, reproducerea „integrală sau a unei părți substanțiale” dintr-o bază de date este ilegală — chiar dacă punctele de date individuale sunt fapte publice.
Testul este atât cantitativ (cât ai copiat raportat la întreg?), cât și calitativ (porțiunea copiată reflectă investiția substanțială a producătorului în construirea, verificarea sau menținerea bazei de date?). Copierea repetată sau sistematică a unor porțiuni mai mici poate conta și ea dacă, în fapt, obține același rezultat ca și copierea unei părți substanțiale.
Pedeapsa pentru încălcarea drepturilor producătorului bazei de date: până la trei ani sau 30 milioane KRW conform Articolului 136(2)(3). Daunele statutare conform Articolului 125-2 permit până la 10 milioane KRW pe operă, sau până la 50 milioane KRW pe operă pentru încălcări intenționate în scop lucrativ.
PIPA: Legea privind protecția informațiilor personale
PIPA reglementează colectarea datelor personale — nume, informații de contact, ID-uri — chiar dacă sunt vizibile public. Reforma din 2023 a fost semnificativă: a extins drepturile persoanei vizate, a înăsprit cerințele de consimțământ, a introdus reguli privind luarea automată a deciziilor și a stabilit sancțiuni administrative de până la 3% din vânzările totale pentru anumite încălcări.
Ghidul PIPC din 2024 privind AI și datele publice menționează direct datele obținute prin „web crawling și scraping” în contextul informațiilor personale disponibile public. Ghidul clarifică faptul că interesul legitim poate servi drept temei în anumite contexte, dar organizațiile au nevoie de evaluare echilibrată, măsuri de protecție, protecția drepturilor și guvernanță.
Iar tendința devine mai strictă. În martie 2026, presa coreeană a relatat un amendament la PIPA care crește sancțiunile maxime pentru eșecuri grave și repetate de gestionare a scurgerilor de date până la 10% din venituri, cu intrare în vigoare mai târziu în 2026.
UCPA: clauza generală „nu profita gratuit”
UCPA este legea care a prins GC Company în cazul civil Yanolja. Actul actual conține două prevederi relevante:
- Articolul 2(1)(k): acoperă utilizările neloiale ale datelor tehnice sau de afaceri acumulate și gestionate electronic, care nu sunt secrete
- Articolul 2(1)(m): clauza generală mai largă pentru folosirea, fără permisiune, a rezultatelor altuia obținute prin investiții sau eforturi substanțiale, în propriul business, contrar practicilor comerciale loiale
UCPA este doar civil pentru aceste prevederi — nu există sancțiune penală — dar poate duce la interdicții prin Articolul 4, despăgubiri conform Articolului 5 și chiar despăgubiri triple în anumite cazuri intenționate conform Articolului 14-2. Cazul civil Yanolja a acordat aproximativ 1 miliard KRW pe baza acestui cadru.
Cazul Yanolja: de ce poți câștiga penal, dar pierde civil
Acesta este cazul pe care orice utilizator de business din Coreea trebuie să-l înțeleagă. Îl voi povesti ca pe o singură istorie, pentru că așa s-a întâmplat de fapt — și pentru că rezultatul împărțit este tocmai ideea centrală.
Ce s-a întâmplat: GC Company a extras datele de călătorie ale Yanolja
GC Company opera o platformă concurentă de turism online. Ei au construit un crawler dezvoltat intern care a accesat serverul API al aplicației Baro Reservation a Yanolja, învățând URL-urile API și comenzile de cerere și trimițându-le către server. Scraperul a colectat informații despre cazare — nume de parteneri, adrese, prețuri, disponibilitate și imagini. GC Company a folosit aceste date intern, pentru marketing și poziționare competitivă.
Yanolja a depus atât o plângere penală, cât și un proces civil.
Verdictul penal: nevinovat pe toate capetele de acuzare (Curtea Supremă 2021Do1533)
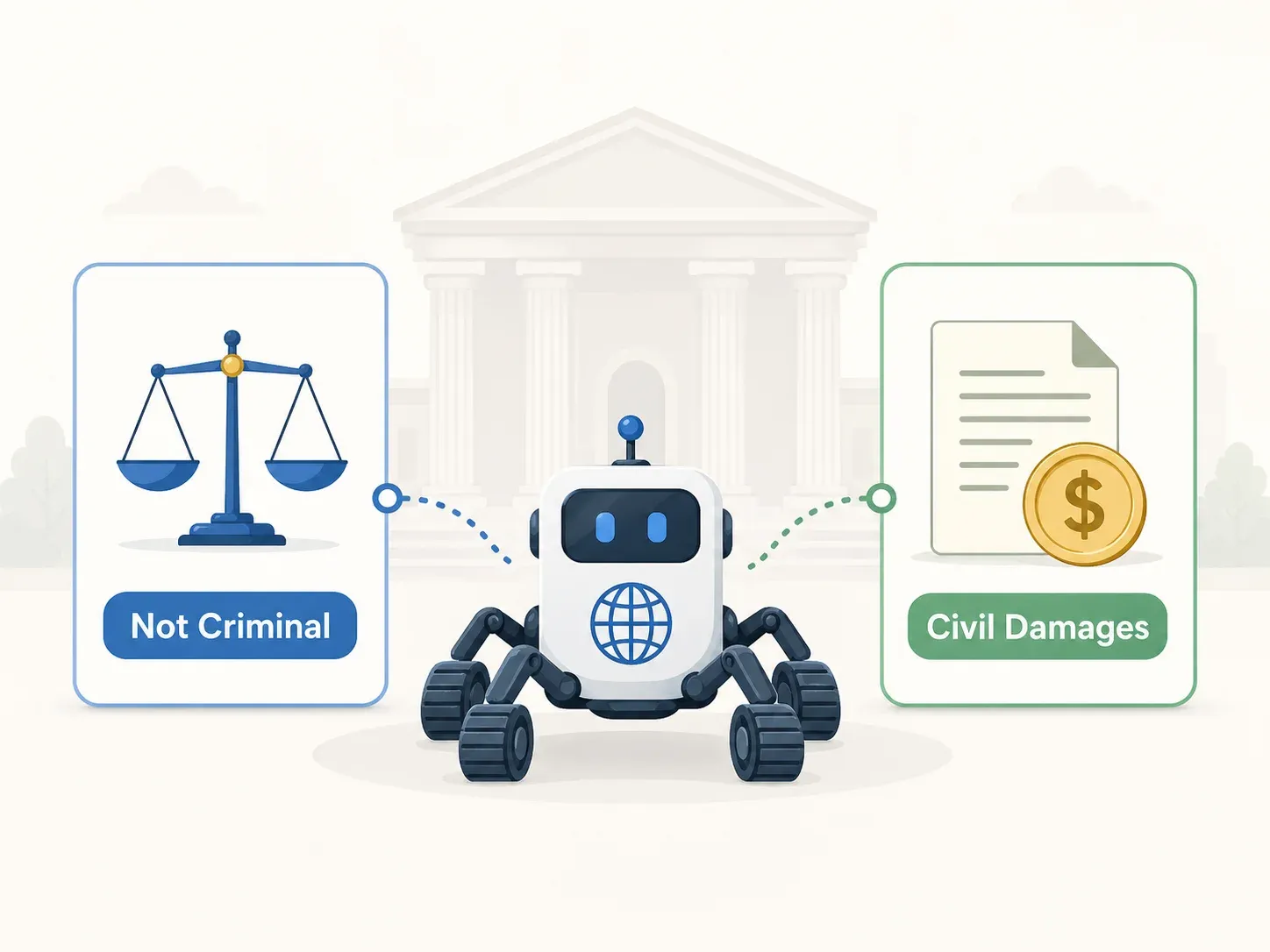
Curtea Supremă a confirmat achitarea pronunțată de instanța de apel la 12 mai 2022, pentru toate cele trei acuzații:
- ICNA Articolul 48 (intruziune): Nu existau restricții de acces. Serverul API era accesibil public prin browser și aplicația mobilă. Nu exista niciun mecanism tehnic de blocare. Clauzele ToS limitau folosirea, nu accesul.
- Legea drepturilor de autor (drepturi DB): Inculpații nu au reprodus „întregul sau o parte substanțială” din baza de date. Datele copiate erau deja cunoscute public, iar probele nu au demonstrat că porțiunea copiată reflecta investiția substanțială a Yanolja.
- Codul penal Articolul 314 (obstrucționarea activității): Nu s-a dovedit nicio perturbare reală a funcționării serverului API al Yanolja. Nicio modificare de date. Nicio intenție vinovată (mens rea) pentru obstrucționarea activității.
Formula citabilă: restricțiile de acces trebuie evaluate prin „măsuri de protecție, termeni de utilizare și alte împrejurări relevante obiectiv”. Dacă poarta este jos, a trece prin ea nu înseamnă să intri fără drept.
Verdictul civil: 1 miliard KRW despăgubiri în baza UCPA
Aici se schimbă povestea. Tribunalul Districtual Central din Seul — apoi Curtea de Apel din Seul (dosar 2021Na2034740, decis la 25 august 2022) — a stabilit că GC Company a încălcat clauza generală din UCPA. Instanța a acordat aproximativ 1 miliard KRW (~800.000 USD) despăgubiri compensatorii și a ordonat încetarea duplicării ulterioare a datelor.
Raționamentul: baza de date de cazare a Yanolja avea valoare comercială și reflecta o investiție substanțială — colectarea, verificarea și actualizarea datelor despre unități de cazare. GC Company a profitat gratuit de această investiție. Hotărârea civilă a rămas definitivă la nivelul Curții de Apel din Seul.
Concluzie practică: achitarea penală nu înseamnă siguranță civilă
Aceasta este cea mai contraintuitivă lecție din legea coreeană a scraping-ului. Un acces legal din punct de vedere penal nu a imunizat folosirea comercială neloială. „Pot fi urmărit penal?” și „Pot fi dat în judecată?” sunt întrebări diferite, cu răspunsuri potențial opuse.
Pentru utilizatorii de business: chiar dacă metoda ta de scraping se află clar în zona verde din punct de vedere penal, folosirea datelor — mai ales dacă concurează direct cu sursa — determină riscul civil.
Coreea vs. SUA vs. UE: cum se compară legile privind web scraping-ul
Nu am găsit alt ghid care să pună asta într-un singur tabel — ceea ce e uimitor, având în vedere câte companii fac scraping peste granițe.
| Dimensiune | Coreea de Sud | Statele Unite | UE / SEE |
|---|---|---|---|
| Legea de bază | ICNA Art. 48, Legea drepturilor de autor | CFAA (18 U.S.C. §1030), legi statale | GDPR, Directiva privind bazele de date (96/9/EC) |
| Caz de referință | Yanolja v GC Company (Curtea Supremă 2021Do1533, 2022) | hiQ v LinkedIn (9th Cir. 2022), Van Buren v. US (2021) | Ryanair v PR Aviation (CJEU C-30/14, 2015) |
| Scraping de date publice | Legal dacă nu există bariere obiective de acces („poarta jos”) | Legal conform raționamentului hiQ (date publice); Van Buren a restrâns CFAA | Depinde de drepturile asupra bazei de date, contract, copyright, GDPR, legea statului membru |
| Reguli privind datele personale | PIPA (modificată în 2023) — consimțământ sau bază legală | Sectorial: CCPA (California), legi statale privind confidențialitatea | GDPR — consimțământ strict / interes legitim; amendă maximă 20 milioane EUR sau 4% din venitul global |
| Încălcarea ToS = infracțiune? | Nu (instanțele consideră că ToS ≠ încălcare ICNA) | Nu (Van Buren 2021: ToS ≠ CFAA) | În general nu, dar poate exista încălcare contractuală (Ryanair) |
| Protecția bazelor de date | Drepturi DB în Legea drepturilor de autor | Fără drept federal general asupra bazelor de date | Drept sui generis asupra bazelor de date |
| Pedeapsă penală maximă | Până la 5 ani / 50 milioane KRW (ICNA) | Până la 10 ani / 250.000 USD (CFAA) | Variază în funcție de statul membru |
Diferențe esențiale pentru afacerea ta
- Coreea nu are o excepție largă pentru text și data mining (TDM), precum Directiva DSM a UE. Dacă antrenezi modele AI pe date coreene extrase, nu primești o derogare legală automată.
- Clauza generală UCPA din Coreea este mai amplă și mai puțin previzibilă decât legea americană a concurenței neloiale. Rezultatul civil din Yanolja ar fi mult mai greu de obținut sub dreptul american.
- Toate cele trei jurisdicții sunt de acord: încălcarea Terms of Service singură nu este infracțiune.
- Protecția bazelor de date în Coreea este statutară (ca în UE), în timp ce SUA nu au un drept federal general asupra bazelor de date. Asta le oferă proprietarilor de platforme coreene mai multe instrumente civile.
- Dacă faci scraping peste granițe, se aplică legea cea mai strictă relevantă. Un proiect care atinge date din Coreea, SUA și UE trebuie să respecte toate cele trei regimuri.
Scenarii pe industrii: este legal web scraping-ul în Coreea pentru domeniul tău?
Profilul de risc variază dramatic în funcție de industrie, iar niciun ghid pe care l-am găsit nu mapează legea coreeană a scraping-ului pe verticale specifice. Așa că am pus cap la cap informațiile eu însumi.
E-commerce: monitorizarea prețurilor și date despre produse

Extragerea prețurilor publice ale produselor de pe Coupang, Gmarket sau 11Street este cel mai curat exemplu din zona verde — rămâi la câmpurile factuale (preț, disponibilitate, numele produsului), evită zonele care cer login, nu ocoli blocajele tehnice și folosește datele intern, pentru benchmark.
Riscul crește atunci când extragi descrieri de produse (conținut creativ → copyright), informații de contact ale vânzătorilor (PIPA), imagini (copyright) sau întregul catalog (drepturi asupra bazei de date + UCPA).
Nu am găsit un proces coreean important privind scraping-ul în e-commerce comparabil cu Yanolja. Precedentul mai dezvoltat este în turism și recrutare — dar absența proceselor nu înseamnă absența riscului.
Modul scheduled scraper și modul cloud scraping din Thunderbit sunt construite exact pentru acest tipar: verificări recurente ale prețurilor și stocurilor pe pagini publice, iar AI Suggest Fields îți permite să alegi coloanele dorite și să excluzi câmpurile cu date personale.
Imobiliare: anunțuri de proprietăți
Imobiliarele sunt în mod natural teritoriu galben. Listările de pe platforme precum Zigbang sau Naver Real Estate combină date factuale (preț, suprafață, cartier) cu numele agenților, telefonul biroului, numere mobile, fotografii și baze de date atent curate de platformă.
Extragerea detaliilor publice despre proprietăți poate avea risc mai mic. Dar colectarea coloanelor cu datele de contact ale agenților declanșează imediat PIPA — iar extragerea tuturor anunțurilor dintr-o regiune începe să arate ca o copiere substanțială a bazei de date.
Măsuri de reducere a riscului: exclude coloanele personale, limitează aria geografică, documentează un scop legitim de business, respectă rate limits și evită să reproduci un serviciu concurent de listări. AI-ul Thunderbit poate fi configurat să extragă doar câmpurile de proprietate de care ai nevoie — preț, metri pătrați, locație — sărind peste datele personale de contact.
Recrutare: anunțuri de joburi
Recrutarea este sectorul cu risc ridicat, fără discuție. Coreea are un precedent direct: JobKorea v. Saramin. Saramin a extras baza de date cu anunțuri de joburi a JobKorea și a fost considerată răspunzătoare pentru încălcarea drepturilor asupra bazei de date și pentru concurență neloială. Datele de recrutare combină de obicei investiția platformei (listări curate și verificate), copierea unor volume mari din baza de date și informații personale sau de contact ale recrutorilor.
Recomandarea mea: evită, în general, să extragi o platformă concurentă de joburi pentru a construi sau îmbogăți o bază de date rivală. Dacă cazul de utilizare este restrâns, cere o analiză juridică înainte de colectare, minimizează volumul, elimină contactele personale și nu redistribui rezultatele.
Referință completă a sancțiunilor: ce riști dacă web scraping-ul merge prost în Coreea
| Statut coreean | Tipul încălcării | Pedeapsa penală maximă | Remediu civil/administrativ maxim | Schimbare-cheie 2023–2026 |
|---|---|---|---|---|
| ICNA Art. 48 | Acces neautorizat / interferență | 5 ani / amendă de 50 milioane KRW | Daune + interdicție | 2024: a fost adăugat Art. 48(4), care vizează instrumentele de ocolire |
| Legea drepturilor de autor (drepturi DB, Art. 93) | Reproducere substanțială a DB | 3 ani / amendă de 30 milioane KRW | Daune statutare de până la 50 milioane KRW/operă (intenționat, cu scop lucrativ) | — |
| PIPA | Colectare ilegală de date personale | 5 ani / amendă de 50 milioane KRW | Penalitate administrativă de până la 3% din vânzările totale; posibilă acțiune colectivă | Reforma din 2023; ghid AI pentru date publice în 2024; tendință spre 10% pentru scurgeri repetate în 2026 |
| UCPA Art. 2(1)(k)/(m) | Dobândire / folosire neloială a datelor | Doar civil (fără penal pentru clauza generală) | Daune + interdicție; despăgubiri triple în cazuri intenționate specifice | Legea-cadru a datelor din 2022 a întărit prevederile |
| Cod penal Art. 314 | Obstrucționarea activității prin mijloace tehnice | 5 ani / amendă de 15 milioane KRW | — | Yanolja: nu s-a dovedit nicio perturbare reală |
Punctul critic: traseele penal și civil rulează independent. Poți fi expus simultan la ambele — și poți câștiga unul, dar pierde celălalt.
Lista ta de conformitate în 10 puncte pentru web scraping în Coreea
Iată zece întrebări da/nu pe care să le treci în revistă înainte de a porni orice proiect de scraping. Tipărește-le, pune-le la bookmark, lipește-le pe monitor — orice funcționează.
- Site-ul țintă cere login pentru a accesa datele dorite? Dacă este nevoie de login, token sau cont, riscul se mută rapid spre ICNA Articolul 48.
- Nu există restricții tehnice de acces? CAPTCHA, blocări IP, API key-uri, rate limits și bariere anti-bot sunt semnale puternice de zonă roșie.
- Ai verificat robots.txt al site-ului? Nu este obligatoriu legal prin sine în precedentul coreean, dar este o dovadă utilă a așteptărilor site-ului și a bunei-credințe.
- Colectezi vreo dată personală? Dacă nume, numere de telefon, emailuri, ID-uri sau detalii individuale de contact intră în sferă, ai nevoie de analiză PIPA.
- Copiați o „parte substanțială” din baza de date a site-ului? Pune întrebări atât cantitative, cât și calitative — cât de mult și dacă porțiunea copiată reflectă investiția sursei.
- Ai definit scopul? Analiza internă are risc mai mic decât redistribuirea sau construirea unei baze de date concurente. (Dar Yanolja arată că folosirea competitivă internă nu este un scut complet.)
- Ai documentat în scris scopul legitim de business? Documentația ajută la echilibrarea interesului legitim în PIPA și ca probă de bună-credință.
- Ai eliminat sau anonimizat câmpurile cu date personale înainte de stocare/folosire? Excluderea detaliilor de contact scoate adesea scraping-ul pentru imobiliare, recrutare și directoare din tiparul PIPA cel mai periculos.
- Folosești intervale rezonabile între cereri? Evită supraîncărcarea serverului — riscurile din Codul penal Articolul 314 și ICNA Articolul 48(3) cresc atunci când scraping-ul afectează funcționarea serviciului.
- Ai consultat un avocat coreean pentru proiecte cu volum mare, comerciale sau transfrontaliere? Pot fi aplicabile simultan dreptul coreean plus GDPR/legile americane privind confidențialitatea sau accesul la calculatoare.
⚠️ Disclaimer: Această listă este pentru orientare, nu pentru consultanță juridică. Consultă întotdeauna un avocat local din Coreea pentru situații specifice.
Cum te ajută Thunderbit să extragi responsabil site-uri coreene
Transparență totală: lucrez în echipa de marketing de la Thunderbit. Dar chiar cred că potrivirea produs–lege este utilă aici, nu doar un argument de vânzare.
Thunderbit este construit pentru cazurile din zona verde descrise în acest articol: extragerea de date disponibile public, fără a fi necesar login. Iată cum se aliniază funcțiile specifice cu cadrul de conformitate:
- Modul cloud scraping pentru site-uri publice — nu ai nevoie să te autentifici, nu este necesară o sesiune locală, rămâi în limitele accesului public. Acest lucru se aliniază cu principiul Yanolja „poarta jos”.
- AI Suggest Fields îți permite să definești exact ce coloane de date vrei să extragi. Ai nevoie de prețurile și disponibilitatea produselor, dar nu și de numerele de telefon ale vânzătorilor? Pur și simplu excluzi coloanele personale. Este cea mai simplă cale de a evita declanșatoarele PIPA.
- Scheduled scraper pentru verificări recurente ale prețurilor, stocurilor sau listărilor, la intervale rezonabile — fără să bombardezi serverul cu cereri constante.
- Export gratuit de date în Excel, Google Sheets, Airtable și Notion pentru fluxuri de lucru interne de analiză.
- Subpage scraping pentru a îmbogăți datele publice din listări (de exemplu, accesarea paginilor individuale ale produselor pentru specificații) fără a intra în zone cu login sau restricții.
- Adaptare AI a layout-ului — scraperul citește structura site-ului de la zero de fiecare dată, adaptându-se la schimbările de layout fără selecători fragili, hardcodați.
Thunderbit suportă utilizare multilingvă în zeci de limbi, ceea ce contează pentru echipele care lucrează cu site-uri în limba coreeană. Îl poți încerca gratuit prin Thunderbit Chrome Extension.
Niciun instrument nu elimină riscul juridic. Dar o configurare responsabilă — pagini publice, date factuale, câmpuri personale excluse, intervale rezonabile — te menține în cadrul de conformitate descris în acest articol.
Idei-cheie despre legalitatea web scraping-ului în Coreea
Cinci lucruri care merită reținute:
- Tehnologia web scraping-ului în sine este legală în Coreea. Curtea Supremă a confirmat acest lucru în decizia Yanolja.
- Riscul depinde de metoda de acces (poarta sus vs. poarta jos), tipul datelor (personale vs. factuale) și utilizare (internă vs. redistribuire concurențială).
- Achitarea penală ≠ siguranță civilă. Cazul Yanolja dovedește că poți evita urmărirea penală, dar totuși să te confrunți cu despăgubiri de ordinul miliardelor.
- Când extragi date publice, nepersonale, factuale pentru uz intern, fără bariere de acces, ești în general în zona sigură. Dar „în general” contează — domeniul, volumul și scopul au importanță.
- Consultă întotdeauna un avocat local din Coreea pentru proiecte comerciale sau de amploare. Acest articol este pentru orientare, nu pentru consultanță juridică.
Dacă vrei să începi să extragi responsabil site-uri coreene, planul gratuit Thunderbit îți permite să testezi fluxul la scară mică. Pentru mai multe detalii despre cum funcționează în practică scraping-ul alimentat de AI, vezi ghidurile noastre despre AI web scraping și web scraping fără cod. Iar dacă vrei să vezi instrumentul în acțiune, canalul nostru de YouTube are tutoriale pentru cazuri de utilizare comune.
Întrebări frecvente
1. Este legal să extragi date disponibile public în Coreea?
În general, da, din punct de vedere penal — conform hotărârii Curții Supreme în cazul Yanolja, accesarea datelor de pe un site fără restricții obiective de acces nu încalcă ICNA. Totuși, răspunderea civilă în baza UCPA sau a Legii drepturilor de autor poate continua să se aplice, în funcție de volum, investiția sursei și utilizarea comercială a datelor.
2. Pot fi dat în judecată pentru web scraping în Coreea chiar dacă nu este infracțiune?
Da. Traseele penal și civil sunt independente. GC Company a fost achitată de toate acuzațiile penale, dar a fost obligată să plătească aproximativ 1 miliard KRW despăgubiri civile în baza clauzei generale din UCPA. Achitarea penală nu oferă protecție împotriva pretențiilor civile.
3. Încălcarea Termenilor și Condițiilor unui site face scraping-ul ilegal în Coreea?
Instanțele coreene au stabilit constant că încălcarea ToS, singură, nu constituie infracțiune în baza ICNA — Curtea a făcut diferența între restricționarea folosirii (ToS) și restricționarea accesului (bariere tehnice). Cu toate acestea, încălcarea ToS poate susține totuși o acțiune civilă pentru încălcarea contractului sau poate servi ca probă de rea-credință într-o analiză de concurență neloială.
4. Cum se compară legea coreeană privind web scraping-ul cu cea din SUA?
Ambele jurisdicții protejează scraping-ul datelor publice (Yanolja în Coreea, hiQ v LinkedIn în SUA) și ambele consideră că simpla încălcare a ToS nu este infracțiune (Van Buren în SUA). Diferența cheie: Coreea are o protecție statutară mai puternică pentru baze de date și o clauză generală mai largă privind concurența neloială decât SUA, care nu au un drept federal general asupra bazelor de date. Proprietarii de platforme coreene au mai multe instrumente de drept civil pentru a-i urmări pe cei care fac scraping.
5. Ce se întâmplă dacă extrag date personale de pe site-uri coreene?
PIPA se aplică indiferent dacă informația este vizibilă public. Colectarea de informații personale — nume, numere de telefon, emailuri — fără consimțământ sau alt temei legal reprezintă o încălcare. Amendamentul PIPA din 2023 a întărit aceste protecții, iar ghidul PIPC din 2024 privind informațiile personale disponibile public abordează în mod specific web crawling-ul și scraping-ul. Sancțiunile pot ajunge la până la 5 ani de închisoare, amenzi de 50 milioane KRW și penalități administrative de până la 3% din vânzările totale.
Încearcă Thunderbit pentru web scraping responsabil Get Started Free
Află mai multe




