

Panoul meu din OpenRouter arăta 47 de dolari cheltuiți înainte de prânz, într-o marți. Rulasem poate vreo duzină de sarcini de programare — nimic ieșit din comun, doar niște refactorizări și câteva corecturi de bug-uri. Atunci mi-am dat seama că setările implicite din OpenClaw redirecționau, pe furiș, fiecare interacțiune, inclusiv ping-urile de tip heartbeat din fundal, prin Claude Opus, la peste 15 dolari per milion de tokeni.
Dacă ai avut parte de surprize similare — iar din ce se vede pe forumuri, nu ești singur („I already spend 40 dollars and doesn't even use it much”, a scris un utilizator) — ghidul acesta îți arată metoda completă de audit și optimizare pe care am folosit-o ca să-mi reduc cheltuiala lunară cu aproximativ 90%. Nu e doar „treci pe un model mai ieftin”, ci o analiză sistematică a locurilor unde se duc de fapt tokenii, cum îi monitorizezi, ce modele low-cost chiar rezistă în muncă agentică reală și trei configurații pe care le poți copia și folosi chiar azi. Tot procesul a durat o după-amiază.
Ce înseamnă utilizarea de tokeni OpenClaw (și de ce este atât de mare implicit)?
Tokenii sunt unitatea de facturare pentru fiecare interacțiune AI din OpenClaw. Gândește-te la ei ca la bucăți foarte mici de text — aproximativ 4 caractere englezești per token. Fiecare mesaj pe care îl trimiți, fiecare răspuns pe care îl primești, fiecare proces din fundal care pornește: toate se taxează în tokeni.
Problema este că setările implicite din OpenClaw sunt optimizate pentru capabilitate maximă, nu pentru cost minim. Din start, modelul principal este setat pe anthropic/claude-opus-4-5 — cea mai scumpă opțiune disponibilă. Ping-urile de heartbeat? Rulează tot pe Opus. Sub-agenții care pornesc pentru sarcini secundare? Tot Opus. Să folosești Opus pentru un heartbeat e ca și cum ai angaja un neurochirurg ca să pună un plasture. Tehnic, poate face treaba; financiar, e de-a dreptul absurd.
Majoritatea utilizatorilor nu realizează că plătesc tarife premium pentru sarcini banale din fundal. Configurația implicită pornește de la ideea că vrei cel mai bun model pentru orice, oricând — și te taxează în consecință.
De ce reducerea utilizării de tokeni OpenClaw înseamnă mai mult decât economii de bani
Beneficiul evident este reducerea costurilor. Dar există și avantaje secundare care se acumulează în timp.
Modelele mai ieftine sunt adesea și mai rapide. Gemini 2.5 Flash-Lite rulează la aproximativ 214 tokeni pe secundă față de Opus, care are în jur de 51 — adică de 4 ori mai rapid la fiecare interacțiune. GPT-OSS-120B pe Cerebras ajunge la 1.917 tokeni pe secundă, ceea ce înseamnă cam de 35 de ori mai rapid decât Opus. Într-o buclă agentică cu peste 50 de pași de tool-calling, diferența asta înseamnă minute în loc de așteptarea chinuitoare de 13,6 secunde până la primul token în fiecare rundă.
Mai primești și mai multă marjă înainte să lovești limitele de rate, mai puține sesiuni throttled și suficient spațiu pentru a scala utilizarea fără să-ți scalezi și anxietatea legată de factură.
Economii estimate pentru diferite profiluri de utilizare:
| Profil utilizator | Cheltuială lunară estimată (implicit) | După optimizare completă | Economie lunară |
|---|---|---|---|
| Ușor (~10 interogări/zi) | ~$100 | ~$12 | ~88% |
| Moderat (~50 interogări/zi) | ~$500 | ~$90 | ~82% |
| Intens (~200+ interogări/zi) | ~$1,750 | ~$220 | ~87% |
Acestea nu sunt calcule ipotetice. Un dezvoltator a documentat trecerea de la $600–750/lună la $3–4/zi — o reducere reală de 90% — combinând rutarea modelelor cu fixurile pentru scurgerile ascunse prezentate mai jos în ghid.
Anatomia utilizării de tokeni OpenClaw: unde se duc, de fapt, toți tokenii
Aceasta este partea pe care cele mai multe ghiduri de optimizare o sar, deși e partea care contează cel mai mult. Nu poți repara ce nu vezi.
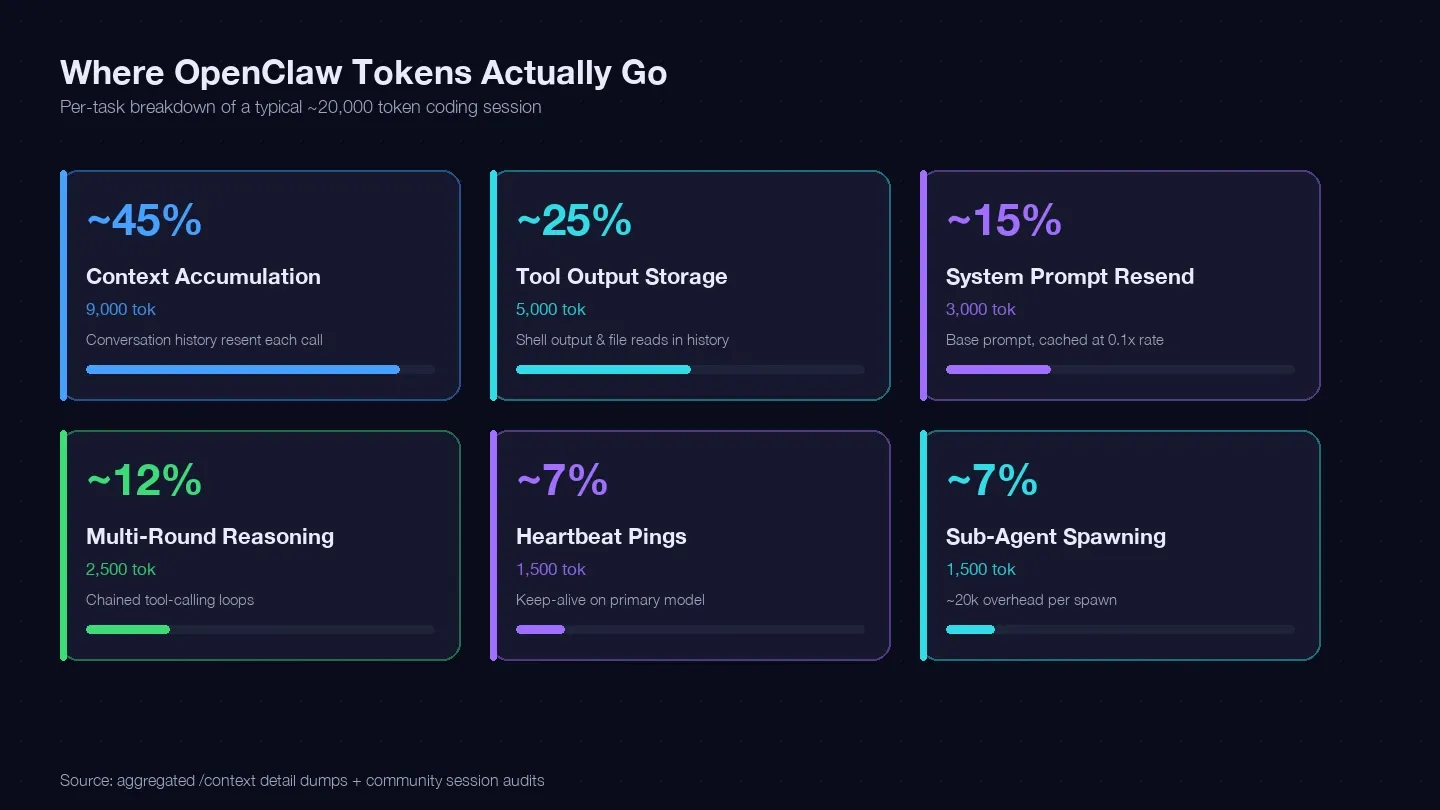
Am auditat mai multe sesiuni și le-am comparat cu ghidul de optimizare a costurilor LaoZhang și cu dump-uri de comunitate /context, ca să construiesc o evidență a tokenilor pentru o sarcină tipică de programare. Iată unde s-au dus, aproximativ, 20.000 de tokeni:
| Categorie de tokeni | Procent tipic din total | Exemplu (1 sarcină de programare) | Poți controla? |
|---|---|---|---|
| Acumularea contextului (istoricul conversației retrimis la fiecare apel) | ~40–50% | ~9.000 tokeni | Da — /clear, /compact, sesiuni mai scurte |
| Stocarea ieșirilor din tool-uri (output din shell, fișiere păstrate în istoric) | ~20–30% | ~5.000 tokeni | Da — citiri mai mici, scope mai restrâns |
| Retrimiterea system prompt-ului (~15K bază) | ~10–15% | ~3.000 tokeni | Parțial — citirile cache sunt taxate la 0.1x |
| Raționament în mai multe runde (bucle legate de tool-calling) | ~10–15% | ~2.500 tokeni | Alegerea modelului + prompturi mai bune |
| Ping-uri heartbeat / keep-alive | ~5–10% | ~1.500 tokeni | Da — schimbare de configurație |
| Apeluri către sub-agenți | ~5–10% | ~1.500 tokeni | Da — rutare de modele |
Cea mai mare categorie — acumularea contextului — înseamnă că istoricul conversației tale este retrimis la fiecare apel API. Un dump real de sesiune a arătat 185.400 de tokeni doar în bucket-ul Messages, înainte ca modelul să fi răspuns măcar o dată. System prompt-ul și tool-urile au mai adăugat încă aproximativ 35.800 de tokeni de overhead fix.
Concluzia: dacă nu cureți sesiunile între sarcini fără legătură între ele, plătești ca să retransmiți tot istoricul conversației la fiecare pas.
Cum monitorizezi utilizarea de tokeni OpenClaw (nu poți tăia ce nu vezi)
Înainte să schimbi ceva, fă vizibilă zona în care se duc tokenii. Să sari direct la „folosește un model mai ieftin” fără monitorizare e ca și cum ai încerca să slăbești fără să te urci vreodată pe cântar.
Verifică panoul OpenRouter
Dacă treci traficul prin OpenRouter, pagina Activity este cel mai simplu dashboard, fără configurare. Poți filtra după model, provider, cheie API și interval de timp. Secțiunea Usage Accounting împarte tokenii în prompt, completion, reasoning și cached, pentru fiecare cerere. Există și buton de Export (CSV sau PDF) pentru analize pe perioade mai lungi.
La ce să fii atent: ce model a consumat cei mai mulți tokeni și dacă cererile de heartbeat sau sub-agent apar ca linii de cost neobișnuit de mari.
Analizează logurile API locale
OpenClaw stochează datele de sesiune în ~/.openclaw/agents.main/sessions/sessions.json, unde găsești totalTokens pentru fiecare sesiune. Poți rula și openclaw logs --follow --json pentru logging în timp real, pe fiecare cerere.
Un avertisment important: sessions.json totalTokens nu este actualizat după compaction, așa că dashboard-ul poate afișa valori vechi, de dinainte de compaction. Ai mai multă încredere în /status și /context detail decât în totalurile salvate.
Folosește tracking extern (pentru utilizatori moderat sau intens)
LiteLLM proxy îți oferă un endpoint compatibil OpenAI în fața a peste 100 de provideri și loghează automat cheltuielile per cheie virtuală, model, utilizator și echipă. Funcția-cheie: bugete fixe per cheie care supraviețuiesc după /clear — un sub-agent scăpat de sub control nu poate depăși limita pe care ai setat-o.
Helicone este și mai simplu — un singur swap de base URL care îți oferă o vedere de tip Sessions, grupând cererile înrudite. Un singur prompt de tip „rezolvă acest bug”, care se împarte în 8+ apeluri de sub-agent, apare ca un singur rând de sesiune, cu costul real total. Free tier: 10.000 de cereri/lună.
Verificări rapide direct în OpenClaw
Pentru monitorizarea de zi cu zi, patru comenzi din sesiune sunt suficiente:
/status— arată utilizarea contextului, ultimii tokeni de input/output, costul estimat/usage full— afișează footer-ul de usage per răspuns/context detail— defalcare de tokeni per fișier, per skill, per tool/compact [guidance]— forțează compaction, cu un text-opțional de focalizare
Rulează /context detail înainte și după schimbările de configurare. Așa verifici dacă optimizările chiar au funcționat.
Duelul modelelor OpenClaw cele mai ieftine: ce LLM-uri low-cost rezistă cu adevărat la muncă agentică
Aici greșesc cele mai multe ghiduri. Arată un tabel de prețuri, indică rândul cel mai ieftin și gata. Dar benchmark-urile nu prezic performanța reală în scenarii agentice — lucru spus clar și repetat de comunitate. După cum a formulat un utilizator: „benchmarks aren't doing any justice to understand which one works best for agentic AI.”
Ideea critică este aceasta: cel mai ieftin model nu produce întotdeauna cel mai ieftin rezultat. Un model care dă greș și reîncearcă de patru ori costă mai mult decât un model din gama medie care reușește din prima. În sisteme agentice de producție, planifică pentru o rată de retry de 5–10% — iar dacă sunt înlănțuite cinci apeluri LLM și pasul 4 eșuează, o reîncercare naivă reexecută toate cele cinci etape.
Mai jos este matricea mea de capabilități, cu un „Real Agentic Score” bazat pe rapoarte reale ale utilizatorilor, nu pe benchmark-uri sintetice:
| Model | Input $/1M | Output $/1M | Fiabilitate tool-calling | Raționament în mai mulți pași | Scor agentic real (1–5) | Cel mai bun pentru |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Mixt — uneori intră în bucle | De bază | ⭐2.5 | Heartbeat-uri, căutări simple |
| GPT-OSS-120B | $0.04 | $0.19 | Acceptabil | Acceptabil | ⭐3.0 | Experimentare low-cost, viteză critică |
| DeepSeek V3.2 | $0.26 | $0.38 | Inconstant (6 issue-uri deschise) | Bun | ⭐3.0 | Raționament intens, puțin tool-calling |
| Kimi K2.5 | $0.38 | $1.72 | Bun (prin :exacto) | Acceptabil | ⭐3.5 | Coding simplu spre mediu |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Bun | Bun | ⭐4.0 | Model de lucru zilnic pentru coding |
| Claude Haiku 4.5 | $1.00 | $5.00 | Excelent | Bun | ⭐4.5 | Fallback mid-tier de încredere |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Excelent | Excelent | ⭐5.0 | Sarcini complexe în mai mulți pași |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Excelent | Excelent | ⭐5.0 | Păstrează-l doar pentru cele mai grele probleme |
Un avertisment despre DeepSeek și Gemini Flash pentru tool-calling
DeepSeek V3.2 arată foarte bine pe hârtie — 72–74% pe SWE-Bench, de 11–36 ori mai ieftin decât Sonnet. În practică, șase issue-uri GitHub separate în Cline, Roo Code, Continue și NVIDIA NIM documentează un comportament defectuos la tool-calling. Verdictul Capului la Cap din Composio: „DeepSeek V3.2 a construit părți din aplicație, dar a clacat la execuție, viteză și fiabilitate.” Replica scurtă a lui Zvi Mowshowitz: „ok și ieftin, dar.”
Gemini 2.5 Flash are un gol similar. Un thread din Google AI Developers Forum, intitulat „Very frustrating experience with Gemini 2.5 function calling performance”, începe cu: „comportamentul de function calling al modelelor Gemini a devenit complet nesigur și imprevizibil.”
OpenRouter a semnalat o nuanță critică: „tendința unui model de a apela tool-uri și acuratețea acestor apeluri pot varia dramatic între host-uri care folosesc aceiași weights.” Dacă rutezi modele ieftine prin OpenRouter, caută tag-ul :exacto — un swap tăcut de provider poate transforma peste noapte un model ieftin și fiabil într-o buclă scumpă de retry.
Când să folosești fiecare model
- Gemini Flash-Lite: Heartbeat-uri, ping-uri keep-alive, întrebări simple și răspunsuri rapide. Niciodată pentru tool-calling în mai mulți pași.
- MiniMax M2.5/M2.7: Modelul tău de zi cu zi pentru sarcini generale de coding. SWE-Pro 56.22, Terminal-Bench 2 57.0% la o fracțiune din prețul lui Sonnet.
- Claude Haiku 4.5: Fallback-ul de încredere când modelele ieftine se blochează la tool-calling. Fiabilitate excelentă, la aproximativ de 3 ori mai ieftin decât Sonnet.
- Claude Sonnet 4.6: Muncă agentică complexă, în mai mulți pași. Aici chiar îți recuperezi banii.
- Claude Opus: Păstrează-l pentru cele mai grele probleme. Nu-l lăsa să fie implicit pentru nimic.
(Prețurile modelelor se schimbă frecvent — verifică tarifele curente pe OpenRouter sau pe paginile directe ale providerilor înainte să te fixezi pe o configurație.)
Scurgerile ascunse de tokeni pe care cele mai multe ghiduri le sar
Utilizatorii de pe forum spun că dezactivarea unor funcții specifice reduce drastic costurile, dar niciun ghid pe care l-am găsit nu oferă o listă unificată a tuturor scurgerilor ascunse și a impactului lor real asupra tokenilor. Iată analiza completă:
| Scurgere ascunsă | Cost în tokeni per apariție | Cum o repari | Cheie de configurare |
|---|---|---|---|
| Heartbeat implicit pe Opus | ~100.000 tokeni/rulare fără izolare | Override pe Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Pornirea sub-agenților | ~20.000 tokeni per pornire înainte să facă efectiv ceva | Redirecționează sub-agenții către Haiku | subagents.model |
| Încărcare completă de context a codului | ~3.000–15.000 tokeni per auto-explore | .clawignore pentru node_modules, dist, lockfiles | .clawrules + .clawignore |
| Auto-sumarizare memory | ~500–2.000 tokeni/sesiune | Dezactivează sau redu frecvența | memory: false sau memory.max_context_tokens |
| Acumularea istoricului conversației | ~500+ tokeni/rundă (cumulativ) | Pornește sesiuni noi între sarcini fără legătură | Disciplina /clear |
| Overhead de tool-uri MCP server | ~7.000 tokeni pentru 4 servere; 50.000+ pentru 5+ | Ține MCP-ul la minimum | Elimină MCP-urile nefolosite |
| Inițializare skill/plugin | 200–1.000 tokeni per skill încărcat | Dezactivează skill-urile nefolosite | skills.entries.<name>.enabled: false |
| Agent Teams (plan mode) | ~7x costul unei sesiuni standard | Folosește doar pentru muncă cu adevărat paralelă | Preferă secvențialul |
Scurgerea de tip heartbeat merită menționată separat. Implicit, heartbeat-urile pornesc pe modelul principal (Opus) la fiecare 30 de minute. Setarea isolatedSession: true scade costul de la aproximativ 100.000 de tokeni per rulare la 2.000–5.000 de tokeni — o reducere de 95–98% pentru acea singură categorie.
Trei câștiguri rapide care îți salvează cei mai mulți tokeni în sub două minute
Toate trei sunt fără risc și durează sub două minute:
-
/clearîntre sarcini fără legătură (5 secunde). Este cel mai mare economizor de tokeni. Consensul din forum spune că aduce o reducere de 50–70% doar prin ștergerea istoricului sesiunii înainte de a începe o muncă nouă. Ții minte bucket-ul de 185k tokeni din dump-ul /context?/clearîl golește. -
/model haiku-4.5pentru munca de rutină (10 secunde). Schimbarea tactică de model produce o reducere de cost de 60–80% pentru sarcini obișnuite. Haiku se descurcă foarte bine cu coding simplu, căutări în fișiere și mesaje de commit. -
Redu
.clawrulesla sub 200 de linii + adaugă.clawignore(90 secunde). Fișierul de reguli se încarcă la fiecare mesaj. La 200 de linii înseamnă ~1.500–2.000 de tokeni per rundă; la 1.000 de linii înseamnă 8.000–10.000 de tokeni taxați permanent la fiecare cerere. Combinat cu un.clawignorecare excludenode_modules/,dist/, lockfiles și codul generat, un dezvoltator susține că a obținut o reducere de 92% a tokenilor doar din această disciplină.
Pas cu pas: trei configurații gata de copiat pentru a reduce utilizarea de tokeni OpenClaw

Mai jos găsești trei configurații complete, comentate, pentru openclaw.json — de la „începe simplu” până la „stack complet de optimizare”. Fiecare include comentarii inline și estimări ale costului lunar.
Înainte să începi:
- Dificultate: Începător (Config A) → Intermediar (Config B) → Avansat (Config C)
- Timp necesar: ~5 minute pentru Config A, ~15 minute pentru Config C
- Ce îți trebuie: OpenClaw instalat, un editor de text, acces la
~/.openclaw/openclaw.json
Config A: Începător — doar economisește bani
Cinci linii. Nicio complexitate. Schimbă modelul implicit din Opus în Sonnet, dezactivează overhead-ul de memory și izolează heartbeat-urile pe Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // era Opus — economii instant de 3–5x
"heartbeat": {
"every": "55m", // se aliniază cu TTL-ul de 1h pentru cache hits maxime
"model": "anthropic/claude-haiku-4-5", // Haiku pentru ping-uri, nu Opus
"isolatedSession": true // ~100k → 2-5k tokeni per rulare
}
}
},
"memory": { "enabled": false } // economisește ~500-2k tokeni/sesiune
}
Ce ar trebui să vezi după aplicare: Rulează /status înainte și după. Costul per cerere ar trebui să scadă vizibil, iar intrările de heartbeat din pagina ta OpenRouter Activity ar trebui să arate Haiku în loc de Opus.
| Nivel de utilizare | Implicit (Opus) | Config A (Sonnet + heartbeat pe Haiku) | Economie |
|---|---|---|---|
| Ușor (~10 cereri/zi) | ~$100 | ~$35 | 65% |
| Moderat (~50 cereri/zi) | ~$500 | ~$250 | 50% |
| Intens (~200 cereri/zi) | ~$1,750 | ~$900 | 49% |
Config B: Intermediar — rutare inteligentă pe trei niveluri
Sonnet principal pentru munca reală. Haiku pentru sub-agenți și compaction. Gemini Flash-Lite ca fallback bugetar când Claude este throttled. Lanțurile de fallback gestionează automat întreruperile de provider.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // dacă Sonnet este throttled
"google/gemini-2.5-flash-lite" // ultimă soluție, ultra-ieftină
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 min < TTL cache 1h = cache hits
"model": "google/gemini-2.5-flash-lite", // câțiva bani per ping
"isolatedSession": true,
"lightContext": true // context minim în apelurile heartbeat
},
"subagents": {
"maxConcurrent": 4, // redus de la 8 în mod implicit
"model": "anthropic/claude-haiku-4-5" // sub-agenții nu au nevoie de Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // sumarizări de compaction prin Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Rezultat așteptat: Intrările de sub-agent din loguri ar trebui să afișeze acum prețurile lui Haiku. Heartbeat-urile ar trebui să coste aproape zero. Lanțul de fallback te salvează dacă apare o întrerupere la Claude — sesiunea continuă degradându-se elegant la Gemini.
| Nivel de utilizare | Implicit | Config B | Economie |
|---|---|---|---|
| Ușor | ~$100 | ~$20 | 80% |
| Moderat | ~$500 | ~$150 | 70% |
| Intens | ~$1,750 | ~$500 | 71% |
Config C: Power user — stack complet de optimizare
Atribuire de model per sub-agent, compaction de context fixată pe Haiku, rutare de vision către Gemini Flash, .clawrules + .clawignore stricte, skill-uri nefolosite dezactivate. Aceasta este configurația care te duce în zona de economii de 85–90%.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // alt provider, ca backup
"minimax/minimax-m2-7", // fallback ieftin pentru uz zilnic
"anthropic/claude-haiku-4-5" // ultimă soluție
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // fără heartbeat-uri peste noapte
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // redus de la 20000 implicit
"imageModel": "google/gemini-3-flash" // task-uri de vision prin model ieftin
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // memory minimă
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Exemplu de override per sub-agent — lipește în ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Rulează verificări de lint/format și aplică remedieri triviale
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
.clawignore minim viabil — asta singură reduce de obicei bootstrap-urile de la 150k caractere spre 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Nivel de utilizare | Implicit | Config C | Economie |
|---|---|---|---|
| Ușor | ~$100 | ~$12 | 88% |
| Moderat | ~$500 | ~$90 | 82% |
| Intens | ~$1,750 | ~$220 | 87% |
Aceste cifre se aliniază cu două rapoarte independente, din lumea reală: documentarea lui Praney Behl de la $600–750/lună → $3–4/zi (o reducere de 90%) și studiile de caz LaoZhang care arată $943 → $347 (63%), $1,750 → $1,000 (64%), $200 → $70 (65%) cu optimizare parțială.
Folosirea comenzii /model pentru a controla din mers utilizarea de tokeni OpenClaw
Comanda /model schimbă modelul activ pentru următoarea rundă, păstrând contextul conversației — fără reset, fără pierderea istoricului. Acesta este obiceiul zilnic care adună economii în timp.
Flux practic:
- Lucrezi la un refactor complicat, cu multe fișiere? Rămâi pe Sonnet.
- O întrebare rapidă de tipul „ce face regex-ul ăsta?”?
/model haiku, întrebi, apoi/model sonnetca să revii. - Mesaj de commit sau polish pe documentație?
/model flash-lite, gata.
Poți seta alias-uri în openclaw.json, la commands.aliases, ca să mapezi nume scurte (haiku, sonnet, opus, flash) la string-urile complete ale providerului. Economisești câteva tastări la fiecare schimbare.
Calculul: 50 de interogări/zi pe Sonnet înseamnă aproximativ 3 dolari/zi. Aceleași 50 de interogări împărțite 70/20/10 între Haiku/Sonnet/Opus ajung la circa 1,10 dolari/zi. Pe o lună, asta înseamnă 90 → 33 de dolari — cu 63% mai ieftin fără să schimbi tool-urile, ci doar obiceiul.
Bonus: urmărirea prețurilor modelelor OpenClaw la mai mulți provideri cu Thunderbit
Urmărește prețurile modelelor la mai mulți provideri cu AI Get Started Free
Cu atâtea modele și provideri — OpenRouter, API-ul direct Anthropic, Google AI Studio, DeepSeek, MiniMax — prețurile se schimbă des. Anthropic a redus peste noapte prețul la output pentru Opus cu aproximativ 67%. Google a tăiat limitele pentru free tier la Gemini cu 50–80% în decembrie 2025. Să ții un spreadsheet static de prețuri actualizat manual este o luptă pierdută.
Thunderbit rezolvă problema fără să scrii cod de scraping. Este un AI web scraper sub formă de extensie Chrome, creat exact pentru acest tip de extragere structurată de date.
Fluxul pe care îl folosesc:
- Deschid pagina de modele OpenRouter în Chrome și apăs „AI Suggest Fields” din Thunderbit. Citește pagina și propune coloane — nume model, preț input, preț output, context window, provider.
- Apăs Scrape, apoi export direct în Google Sheets.
- Setez un scrape programat în limbaj simplu — „în fiecare luni la 9:00, re-citește lista de modele OpenRouter” — și rulează automat în cloud.
De acolo înainte, tracker-ul tău personal de prețuri se actualizează singur. Orice model care devine brusc cu 30% mai ieftin — sau orice provider care primește tag-ul Exacto — apare în spreadsheet-ul de luni dimineață fără să miști un deget. Am scris mai multe despre extragerea datelor cu AI pentru business pe blog.
Compari prețuri pe paginile directe ale providerilor (Anthropic, Google, DeepSeek)? Funcția de scraping pe subpagini din Thunderbit urmărește fiecare link de model până la pagina lui de detalii și extrage tarifele pe provider — utilă când vrei să știi dacă e mai ieftin să rutezi Kimi K2.5 prin OpenRouter decât direct prin NVIDIA Build. Verifică prețurile Thunderbit pentru detalii despre free tier și planuri.
Idei cheie pentru reducerea utilizării de tokeni OpenClaw
Formula este: Înțelege → Monitorizează → Rutează → Optimizează.
Acțiunile cu cel mai mare impact, în ordinea importanței:
- Nu lăsa Opus ca implicit. Schimbă modelul principal pe Sonnet sau MiniMax M2.7. Numai asta înseamnă o reducere de cost de 3–5 ori.
- Izolează heartbeat-urile. Setează
isolatedSession: trueși direcționează heartbeat-urile către Gemini Flash-Lite. Astfel, o scurgere de ~100k tokeni devine ~2–5k. - Trimite sub-agenții către Haiku. Fiecare pornire încarcă aproximativ 20k tokeni de context înainte să facă ceva util. Nu lăsa asta să ruleze pe Opus.
- Folosește
/clearconstant. E gratis, durează 5 secunde și consensul comunității spune că salvează mai mult decât orice altă acțiune individuală. - Adaugă
.clawignore. Excludereanode_modules, lockfiles și artifactelor de build reduce drastic contextul de bootstrap. - Monitorizează cu
/context detailînainte și după schimbări. Dacă nu poți măsura, nu poți îmbunătăți.
Cel mai ieftin model depinde de sarcină. Gemini Flash-Lite pentru heartbeat-uri. MiniMax M2.7 pentru coding zilnic. Haiku pentru tool-calling de încredere. Sonnet pentru muncă complexă, în mai mulți pași. Opus doar pentru problemele cu adevărat grele — și pentru nimic altceva.
Cei mai mulți cititori pot obține economii de 50–70% într-o singură după-amiază cu Config A sau B. Economia completă de 85–90% cere să combini tot ce am spus mai sus — rutarea modelelor, fixurile pentru scurgerile ascunse, .clawignore, disciplina sesiunilor — dar este realizabilă și durabilă.
Întrebări frecvente
1. Cât costă OpenClaw pe lună?
Depinde complet de configurație, volum de utilizare și modelele alese. Utilizatorii ușori (~10 interogări/zi) cheltuiesc de obicei 5–30 de dolari/lună cu optimizare, sau peste 100 de dolari pe setările implicite. Utilizatorii moderați (~50 interogări/zi) ajung de regulă la 90–400 de dolari/lună. Utilizatorii intensivi pot urca la $600–2.000+/lună pe setările implicite — un caz extrem documentat a fost de 5.623 de dolari într-o singură lună. Telemetria internă Anthropic sugerează un median de $13/dezvoltator/zi activă.
2. Care este cel mai ieftin model OpenClaw care încă merge bine pentru coding?
MiniMax M2.5/M2.7 este cea mai bună opțiune generală pentru uz zilnic — fiabilitate bună la tool-calling, SWE-Pro 56.22, la aproximativ 0,28/1,10 dolari per milion de tokeni. Pentru heartbeat-uri și căutări simple, Gemini 2.5 Flash-Lite la 0,10/0,40 dolari este foarte greu de bătut. Claude Haiku 4.5 la 1/5 dolari este fallback-ul mid-tier de încredere când ai nevoie de tool-calling excelent fără prețurile lui Sonnet.
3. Pot folosi modele gratuite cu OpenClaw?
Tehnic, da. GPT-OSS-120B este gratuit pe tag-ul :free din OpenRouter și pe NVIDIA Build. Gemini Flash-Lite are un free tier (15 RPM, 1.000 de cereri/zi). DeepSeek oferă 5 milioane de tokeni gratis la înregistrare. Dar free tier-urile vin cu limite agresive, viteză mai mică și disponibilitate nesigură. Modelele plătite ieftine — câțiva bani per milion de tokeni — sunt mult mai fiabile pentru utilizare regulată.
4. Schimbarea modelului la mijlocul conversației cu /model îmi pierde contextul?
Nu. /model păstrează tot contextul sesiunii — următoarea rundă este trimisă către noul model, cu tot istoricul intact. Acest lucru este confirmat în documentația de concepte OpenClaw și funcționează la fel în Claude Code. Poți comuta liber între Haiku pentru întrebări rapide și Sonnet pentru muncă complexă fără să pierzi nimic.
5. Care este cel mai rapid mod de a-mi reduce factura OpenClaw chiar azi?
Tastează /clear între sarcini fără legătură. Este gratuit, durează cinci secunde și șterge istoricul conversației care este retrimis la fiecare apel API. O sesiune reală a arătat 185.000 de tokeni de istoric acumulat — totul era retransmis și refacturat la fiecare rundă. Golirea lui înainte să începi o muncă nouă este obiceiul cu cel mai mare ROI pe care îl poți construi.
Încearcă Thunderbit pentru AI Web Scraping Get Started Free




