

Optimizarea interogărilor pentru listele Apollo nu este doar un exercițiu tehnic — este o abilitate esențială pentru oricine depinde de date de știri în timp real, de extragerea automată de informații din știri sau de fluxuri de lucru de vânzări și operațiuni cu volum mare. Am văzut pe propria piele cum o interogare lentă pentru listă poate transforma un dashboard elegant într-un blocaj, lăsând echipele de vânzări să se uite la încărcări interminabile și oamenii din ops să caute soluții de avarie în foi de calcul. Într-o lume în care 60% din timpul reprezentanților de vânzări este deja irosit pe sarcini care nu aduc vânzări, fiecare milisecundă contează.
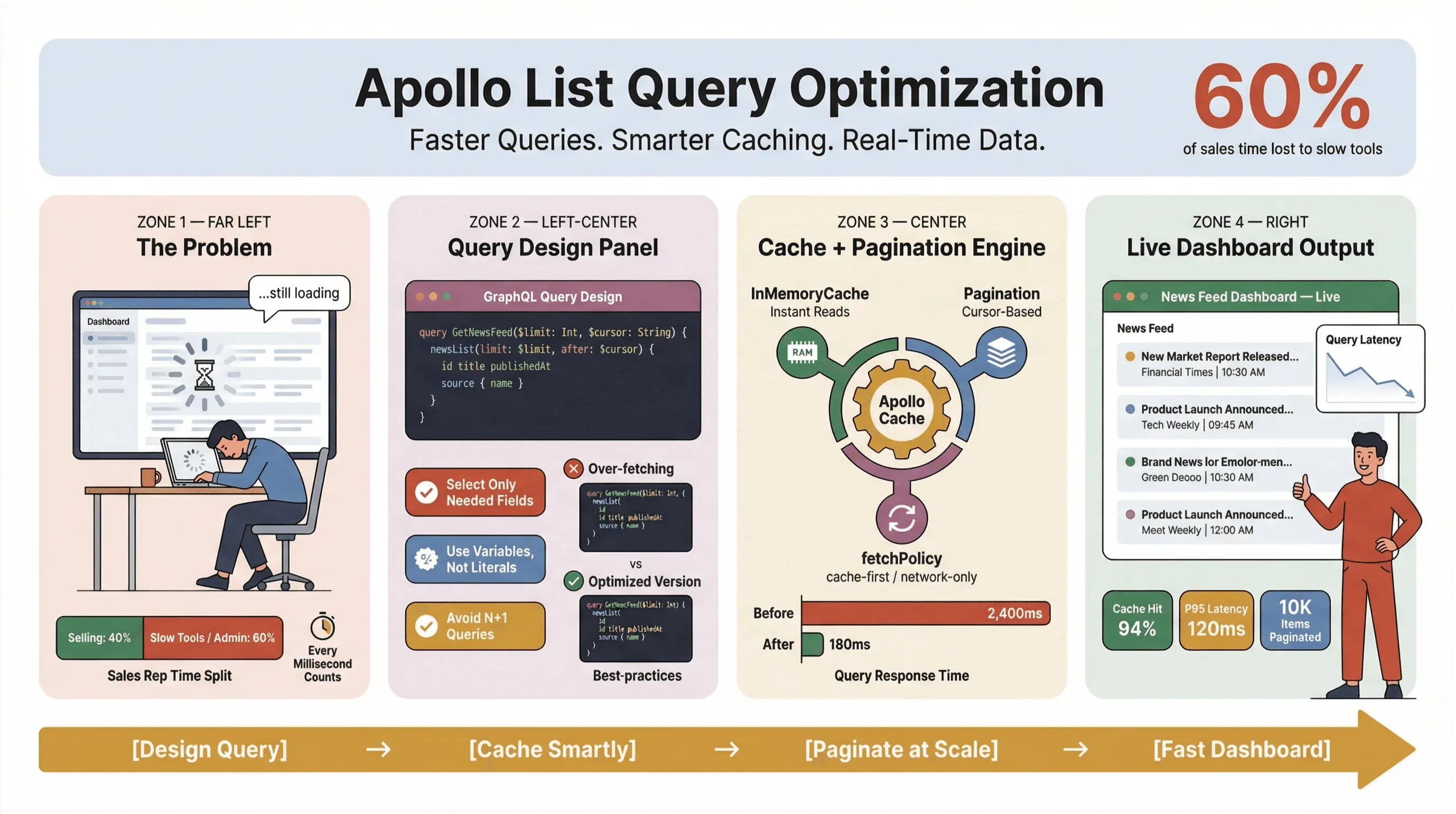
Așadar, cum poți menține interogările de tip listă din Apollo Client rapide, fiabile și consecvente la scară — mai ales când extragi știri, urmărești leaduri sau alimentezi dashboarduri critice pentru business? În acest ghid, îți voi arăta practicile care au rezistat în producție: designul interogărilor, caching-ul, paginarea și integrarea unor instrumente no-code precum Thunderbit pentru a automatiza munca repetitivă de extragere a știrilor.
--- Fie că ești dezvoltator, product manager sau doar persoana pe care toată lumea o învinovățește când dashboardul merge greu, acesta este ghidul tău pentru performanța listelor în Apollo GraphQL.
Încearcă Thunderbit pentru extragerea automată a știrilor
De ce să optimizezi interogările Apollo pentru liste? (apollo client list performance, optimize apollo list queries)
Să fim sinceri: nimeni nu vrea să aștepte după încărcarea titlurilor de știri sau a leadurilor de vânzări. În mediile de business — mai ales în cele care se bazează pe extragerea automată a știrilor sau pe date în timp real — interogările lente pentru liste Apollo nu doar enervează utilizatorii; ele costă bani, întârzie deciziile și împing oamenii înapoi spre munca manuală. Cercetările recurente din Slack Workforce Lab arată constant că angajații de birou petrec aproximativ o treime — iar în rapoartele mai recente, aproape 40% — din zi cu sarcini repetitive și cu valoare scăzută, adesea pentru că instrumentele lor fragmentează munca în suprafețe lente.
Iată ce se întâmplă când interogările de listă nu sunt optimizate:
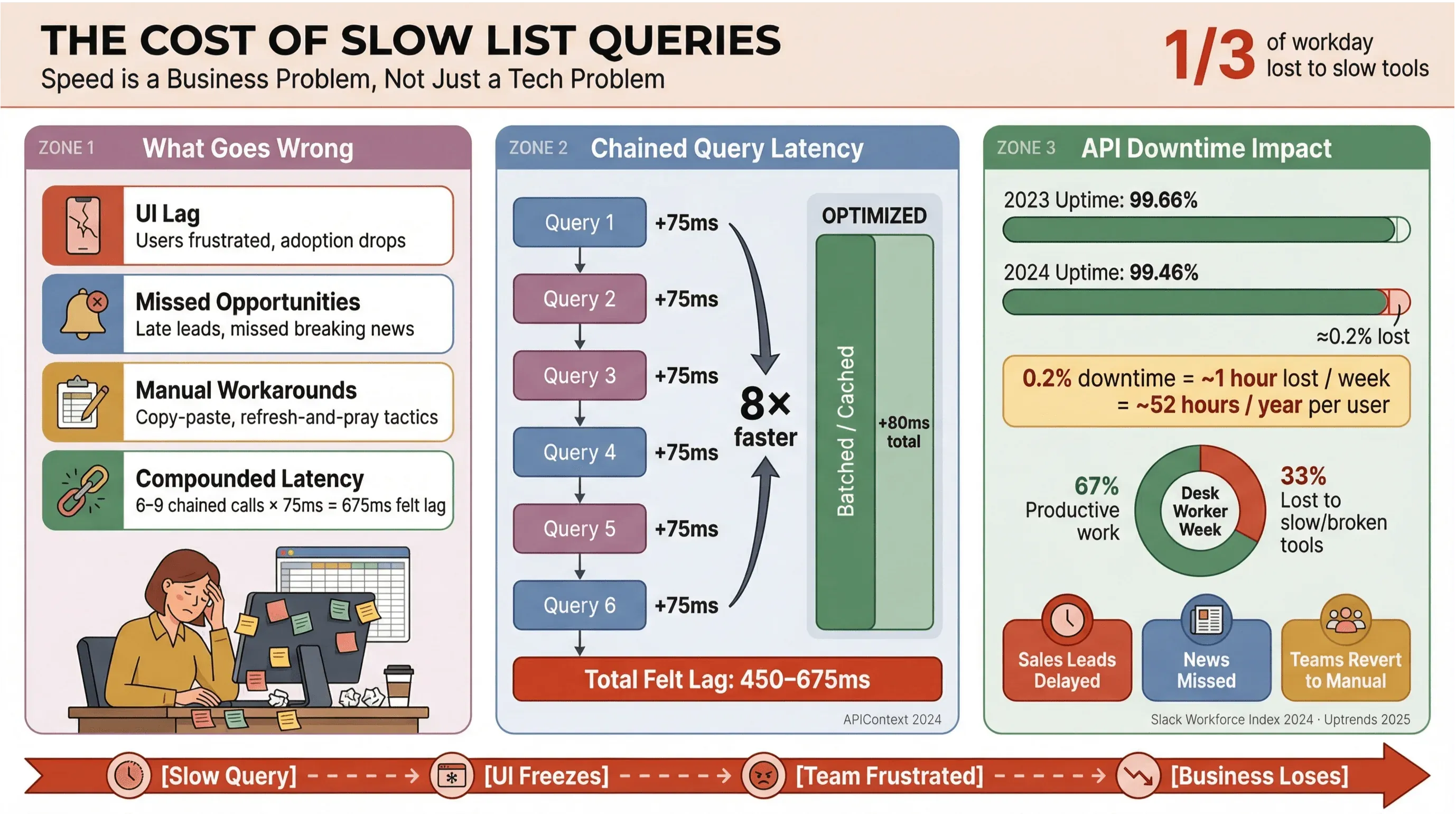
- Întârziere în UI: Utilizatorii simt lag, ceea ce duce la frustrare și adopție mai mică.
- Oportunități ratate: În vânzări sau monitorizarea știrilor, chiar și câteva secunde de întârziere pot însemna pierderea unui lead fierbinte sau a unei știri importante.
- Soluții manuale de avarie: Echipele revin la copy-paste, foi de calcul sau tactici de tipul „refresh și speră”.
- Latență acumulată: Fiecare apel API lent se adună — dacă fluxul tău declanșează 6–9 interogări dependente, o întârziere modestă de 75 ms per apel poate crește până la un lag resimțit de 450–675 ms (APIContext).
Și nu e doar o chestiune de viteză. Downtime-ul API este în creștere, iar uptime-ul mediu a scăzut de la 99,66% la 99,46% într-un singur an — ceea ce se traduce prin aproape o oră de productivitate pierdută pe săptămână pentru aplicațiile cu multe liste. Când businessul tău depinde de date de știri în timp real, acesta este un risc pe care nu ți-l poți permite.
Alegerea structurii corecte de date și a câmpurilor (apollo graphql list best practices)
Una dintre cele mai frecvente greșeli pe care le văd (și, da, am făcut-o și eu) este să tratezi orice interogare de listă ca pe o interogare de detaliu. În GraphQL, ai puterea să ceri exact ce îți trebuie — așa că folosește-o. A cere prea multe date este inamicul performanței, mai ales în instrumentele de news scraping și dashboardurile în timp real.
Adaptarea câmpurilor pentru extragerea automată a știrilor
Să presupunem că construiești un feed de știri. Chiar ai nevoie de corpul complet al articolului, toate tagurile, comentariile și biografiile autorilor în interogarea de listă? Probabil că nu. Iată diferența:
Interogare de listă eficientă:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Interogare de listă ineficientă (nu face asta):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
Prima interogare este suplă și rapidă — ideală pentru sortare, filtrare și randarea rândurilor. A doua? Este de fapt o interogare de detaliu deghizată, care trage după ea payload-uri mari și încetinește totul (spec GraphQL, Apollo best practices).
Sfat util: folosește o abordare pe două niveluri — în listă cere doar câmpurile ușoare, iar datele grele (precum textul integral sau îmbogățirea NLP) încarcă-le doar când utilizatorul deschide un element sau trece cu mouse-ul peste el.
Folosirea cache-ului Apollo Client pentru interogări mai rapide (apollo client list performance)
Cache-ul din Apollo Client este cea mai importantă pârghie pe care o ai pentru performanța interogărilor de listă. Când este configurat corect, îți permite să:
- Livrezi instant interogările repetate (fără drumuri suplimentare la rețea)
- Reduci încărcarea serverului și costurile API
- Oferi navigare fluidă înapoi/înainte și schimbări de filtre
Dar caching-ul nu face minuni singur — necesită puțină configurare și disciplină.
Stabilirea unor politici de cache eficiente
Apollo suportă mai multe fetch policies:
| Politică | Ce face | Cel mai bun caz de utilizare pentru liste de știri |
|---|---|---|
| cache-first | Citește din cache, apoi face request la rețea dacă lipsește | Revenirea la liste, schimbarea filtrelor, navigare înapoi/înainte |
| network-only | Ia mereu datele din rețea | Refresh manual, „ultimele titluri” |
| cache-and-network | Returnează mai întâi cache-ul, apoi actualizează din rețea | Randare inițială rapidă + actualizare în fundal (excelent pentru feeduri) |
| no-cache | Ia mereu datele, dar nu le stochează în cache | Interogări sensibile, ocazionale (rareori pentru liste) |
Pentru date de știri în timp real, îmi place cache-and-network — oferă rezultate instant, apoi actualizează în fundal. Doar ai grijă la efectele vizuale de tip flicker dacă datele se reordonează la refresh (issue GitHub).
Sfaturi pentru configurarea cache-ului:
- Folosește ID-uri stabile (
idsau_id) pentru normalizare (documentația Apollo cache). - Ajustează dimensiunea cache-ului și garbage collection-ul pentru liste mari (memory management).
- Evită să stochezi blob-uri uriașe, nenormalizate, sub
ROOT_QUERY— îți poate bloca aplicația (raport din comunitate).
Implementarea paginării și limitarea numărului de elemente (apollo graphql list best practices)
Dacă încarci sute sau mii de articole de știri sau leaduri de vânzări dintr-odată, îți cauți probleme. Paginarea nu este doar o funcție de UX — este o necesitate de performanță.
Apollo suportă atât paginarea pe offset, cât și paginarea pe cursor. Iată cum se compară:
| Tip de paginare | Avantaje | Dezavantaje | Potrivit pentru |
|---|---|---|---|
| Pe offset | Simplu, ușor de implementat | Poate să sară/repete elemente dacă datele se schimbă | Liste mici sau imuabile |
| Pe cursor | Stabil, gestionează bine schimbările de date | Puțin mai complex | Feeduri de știri, liste mari |
Pentru majoritatea listelor de știri în timp real sau a listelor de leaduri, paginarea pe cursor este soluția potrivită. Menține datele consistente chiar și atunci când apar elemente noi sau cele vechi sunt șterse (GraphQL Foundation).
Sfaturi pentru paginarea în Apollo:
- Configurează
keyArgspentru a controla cheile cache-ului la câmpurile paginate (docs). - Implementează o funcție
mergepentru a combina paginile în cache. - Folosește
fetchMorepentru a încărca pagini suplimentare fără să suprascrii rezultatele anterioare.
Modele practice de paginare pentru instrumente de extragere a știrilor
Un UI tipic pentru news scraping va:
- Afișa cele mai recente 20–50 de titluri (doar câmpuri ușoare)
- Încărca mai multe la scroll sau la click pe „pagina următoare”
- Recupera detaliile doar când sunt necesare
Asta face UI-ul rapid, API-ul mulțumit și utilizatorii productivi.
Integrarea Thunderbit pentru extragerea automată a știrilor
Acum, hai să discutăm despre întrebarea esențială: de unde vin, de fapt, toate aceste date structurate despre știri? Aici intervine Thunderbit.
Obține extensia Chrome Thunderbit Get Started Free
Thunderbit este o extensie Chrome de tip AI web scraper, fără cod, care poate extrage titluri de știri, URL-uri, surse, autori, date de publicare, rezumate și imagini din aproape orice site — fără să scrii cod. Am văzut echipe folosind Thunderbit pentru a automatiza întregul proces de extragere a știrilor, transformând paginile web nestructurate în date curate, structurate, gata de introdus într-o bază de date sau într-un API GraphQL.
Combinarea Thunderbit cu Apollo pentru date de știri în timp real
Iată un flux de lucru pe care îl recomand mult echipelor de vânzări și operațiuni care au nevoie de știri actualizate:
- Stratul de extracție: Folosește News Scraper template din Thunderbit pentru a extrage date structurate de pe site-urile țintă, conform unui program.
- Stratul de stocare: Salvează datele extrase într-o bază de date optimizată pentru acces rapid.
- Stratul GraphQL: Expune prin API un câmp de listă
newsFeedși un câmp de detaliunewsArticle(id). - Stratul client: Folosește Apollo Client pentru a prelua lista (câmpuri ușoare, paginate) și detaliile doar când este nevoie.
Acest pipeline „extrage → stochează → interoghează” înseamnă că interogările Apollo lucrează mereu cu date proaspete și structurate — fără copy-paste manual sau scripturi fragile.
Bonus: Thunderbit poate și să îmbogățească listele cu câmpuri suplimentare (cum ar fi sentimentul sau categoria) folosind sugestiile sale alimentate de AI, făcând feedul de știri și mai inteligent.
Ghid pas cu pas: optimizarea interogărilor Apollo pentru liste
Ești gata să pui totul în practică? Iată checklist-ul meu preferat pentru optimizarea interogărilor de listă în Apollo:
-
Redu dimensiunea interogărilor
- Cere doar câmpurile necesare pentru afișarea listei (titlu, URL, timestamp etc.).
- Mută câmpurile grele (text integral, imagini, îmbogățiri) în interogările de detaliu.
-
Implementează paginarea
- Folosește paginarea pe cursor pentru liste mari sau dinamice.
- Configurează funcțiile
keyArgsșimergepentru corectitudinea cache-ului.
-
Profită de cache-ul Apollo
- Normalizează entitățile cu ID-uri stabile.
- Alege politica potrivită de fetch (
cache-and-networkeste foarte bună pentru știri). - Ajustează dimensiunea cache-ului și garbage collection-ul în funcție de volum.
-
Integrează extracția automată
- Folosește Thunderbit pentru a automatiza scraping-ul de știri și pentru a menține datele proaspete.
- Exportă datele structurate direct în baza ta de date sau în foaia de calcul.
-
Monitorizează și diagnostichează
- Folosește Apollo Client Devtools pentru a inspecta interogările, cache-ul și performanța.
- Urmărește scrierile mari în cache, numărul excesiv de query-uri urmărite și sacadarea UI-ului.
- Monitorizează latența p95/p99 și ratele de eroare (New Relic, Uptrends).
Monitorizarea și depanarea performanței interogărilor
Apollo Devtools sunt extrem de utile aici. Poți:
- Inspecta interogările active și starea cache-ului
- Identifica interogări duplicate sau watchers excesivi
- Depista blob-uri mari în cache sau probleme de normalizare
Dacă observi lag în UI sau actualizări lente, verifică:
- Interogări de listă prea mari (redu-le)
- Normalizare slabă a cache-ului (corectează ID-urile)
- Probleme la merge-ul paginării (verifică
keyArgsșimerge)
Și nu uita să măsori tail latency — nu doar mediile. Acolo se ascunde, de fapt, durerea utilizatorului.
Comparație între scraping-ul tradițional și abordările de extragere a știrilor bazate pe AI
Să fim sinceri: odinioară, extragerea datelor din știri însemna să scrii scripturi personalizate, să te lupți cu browsere headless și să speri că structura site-ului nu se schimbă peste noapte. Acum, cu instrumente bazate pe AI precum Thunderbit, poți automatiza întregul proces — fără cod, fără stres.
| Abordare | Puncte forte | Limitări pentru utilizatorii de business |
|---|---|---|
| Scraping cu scripturi | Total personalizabil, ieftin la scară | Necesită multă mentenanță, cere timp de la echipa tehnică |
| Platforme managed de scraping | Rapid de pornit, preia gestionarea anti-bot | Tot necesită configurare, costurile cresc odată cu utilizarea |
| Extragere bazată pe AI (Thunderbit) | Gestionează layouturi dezordonate, nu necesită cod | Rezultatul are nevoie de QA, integrare cu schema ta |
| Scraper-e vizuale no-code | Accesibile pentru non-ingineri | Se pot rupe la schimbări de UI, scalare limitată |
| Infrastructură proxy/unlocker | Ocolește blocajele, suportă throughput mare | Tot ai nevoie de logică de extracție, plus riscuri de conformitate |
Notă legală: Extragerea datelor publice este, în general, legală, dar respectă întotdeauna termenii de utilizare și limitele de rată (Reuters).
Idei cheie pentru cele mai bune practici Apollo GraphQL pentru liste
Să recapitulăm esențialul:
- Optimizează pentru viteză și claritate: fă interogările de listă suple, aplică paginare și folosește caching agresiv.
- Structura contează: cere doar ce ai nevoie — mută câmpurile grele în interogările de detaliu.
- Cache-ul este prietenul tău: folosește normalizarea și politicile de fetch din Apollo pentru a servi datele instant.
- Automatizează extracția: instrumente precum Thunderbit fac scraping-ul de știri și îmbogățirea listelor accesibile tuturor.
- Monitorizează și îmbunătățește: folosește Devtools și dashboarduri de observabilitate pentru a identifica din timp blocajele.
Pentru echipele de vânzări, operațiuni și știri, aceste bune practici înseamnă mai puțin timp de așteptare, mai mult timp de acțiune — și mult mai puține mesaje pe Slack de tipul „de ce merge atât de încet?”.
Concluzie: pașii următori pentru optimizarea interogărilor Apollo pentru liste
Dacă încă folosești interogări grele, fără paginare sau nepotrivite pentru cache, acum este momentul să le auditezi și să le îmbunătățești. Începe simplu: redu câmpurile, adaugă paginare și reglează cache-ul. Apoi, mergi mai departe integrând instrumente de extracție automată precum Thunderbit pentru a menține datele proaspete și acționabile.
Vrei să aprofundezi? Consultă documentația Apollo, Thunderbit Blog sau alătură-te Apollo Community pentru sfaturi reale și depanare. Iar dacă ești gata să automatizezi extragerea știrilor, încearcă News Scraper template din Thunderbit — este un game-changer pentru oricine are nevoie de date în timp real fără bătăi de cap.
Folosește șablonul Thunderbit News Scraper
Dacă nu faci altceva după ce citești acest articol: redu selecția de câmpuri din interogările de listă, adaugă paginare pe cursor și alege o politică de fetch rezonabilă. Doar aceste trei schimbări duc, de obicei, o interogare de listă de la un lag „vizibil” la unul „aproape imperceptibil” — și te eliberează să te concentrezi pe date, nu pe starea de încărcare.
Întrebări frecvente
1. De ce devin lente interogările Apollo pentru liste în dashboardurile de știri sau vânzări în timp real?
Interogările de listă pot deveni lente dacă preiau prea multe date, nu au paginare sau nu sunt cache-uite corect. În fluxuri de lucru cu frecvență mare, cum este monitorizarea știrilor, chiar și întârzierile mici se adună, ducând la lag în UI și productivitate pierdută.
2. Care este cea mai bună metodă de a structura interogările Apollo pentru extragerea automată a știrilor?
Cere doar câmpurile necesare pentru afișarea listei (de exemplu: titlu, URL, timestamp). Mută câmpurile grele (precum textul complet al articolului sau imaginile) în interogări de detaliu și paginează rezultatele pentru a păstra payload-urile mici și rapide.
3. Cum îmbunătățește cache-ul Apollo Client performanța listelor?
Cache-ul Apollo stochează datele deja preluate, permițând răspunsuri instant pentru interogările repetate. Normalizarea corectă a cache-ului și politicile de fetch (cum ar fi cache-and-network) pot accelera semnificativ afișarea listelor și reduce încărcarea serverului.
4. Cum poate ajuta Thunderbit la scraping-ul de știri și la integrarea cu Apollo?
Thunderbit este un AI web scraper no-code care extrage date structurate despre știri din orice site. Îl poți folosi pentru a automatiza extragerea știrilor, apoi poți trimite aceste date în baza ta de date sau în API-ul GraphQL pentru a le folosi cu Apollo Client.
5. Ce instrumente pot folosi pentru a monitoriza și a depana performanța interogărilor Apollo pentru liste?
Apollo Client Devtools îți permit să inspectezi interogările, starea cache-ului și performanța în timp real. Combină-le cu dashboarduri de observabilitate (precum New Relic sau Uptrends) pentru a urmări latența și ratele de eroare și ajustează designul interogărilor pentru rezultate optime.
Vrei mai multe sfaturi despre web scraping, automatizare și fluxuri de lucru cu date în timp real? Intră pe Thunderbit Blog pentru analize aprofundate, tutoriale și cele mai noi idei despre productivitatea alimentată de AI.
Încearcă Thunderbit AI Web Scraper Get Started Free
Află mai multe
- Cum să optimizezi listele Apollo pentru o gestionare eficientă a leadurilor
- Îmbogățirea datelor Apollo: funcții, beneficii și impulsul oferit de AI
- Cum să stăpânești prospectarea în Apollo: un ghid pas cu pas
- Cum să folosești paginarea în web scraper pentru o extracție eficientă
- Cum să folosești paginarea în web scraper pentru o extracție eficientă




