

Datele web cresc exploziv, iar presiunea de a ține pasul crește la fel de repede. Am văzut direct cum echipele de vânzări și operațiuni pierd mai mult timp cu fișiere Excel, copiat din site-uri și lipit informații decât cu luarea deciziilor propriu-zise. Potrivit Salesforce, reprezentanții de vânzări își petrec acum până la 70% din timp pe sarcini care nu țin de vânzare, iar Asana arată că 60% din muncă este doar „muncă despre muncă”. Asta înseamnă o mulțime de ore pierdute cu colectarea manuală a datelor — ore care ar putea fi folosite pentru închiderea de contracte sau lansarea de campanii.
Vestea bună este că web scraping-ul a devenit deja ceva obișnuit, iar acum nu mai trebuie să fii dezvoltator ca să profiți de el. Ruby a fost mult timp una dintre limbile preferate pentru automatizarea extragerii de date de pe web, iar atunci când îl combini cu un AI web scraper modern, precum Thunderbit, obții ce e mai bun din ambele lumi: flexibilitate pentru cei care scriu cod și simplitate fără cod pentru toți ceilalți. Fie că ești marketer, manager de ecommerce sau doar cineva sătul de copy-paste la nesfârșit, acest ghid îți arată cum să stăpânești web scraping-ul cu Ruby și AI — fără să fie nevoie de programare.
Încearcă Thunderbit pentru web scraping fără cod
Ce înseamnă web scraping cu Ruby? Poarta ta către automatizarea datelor
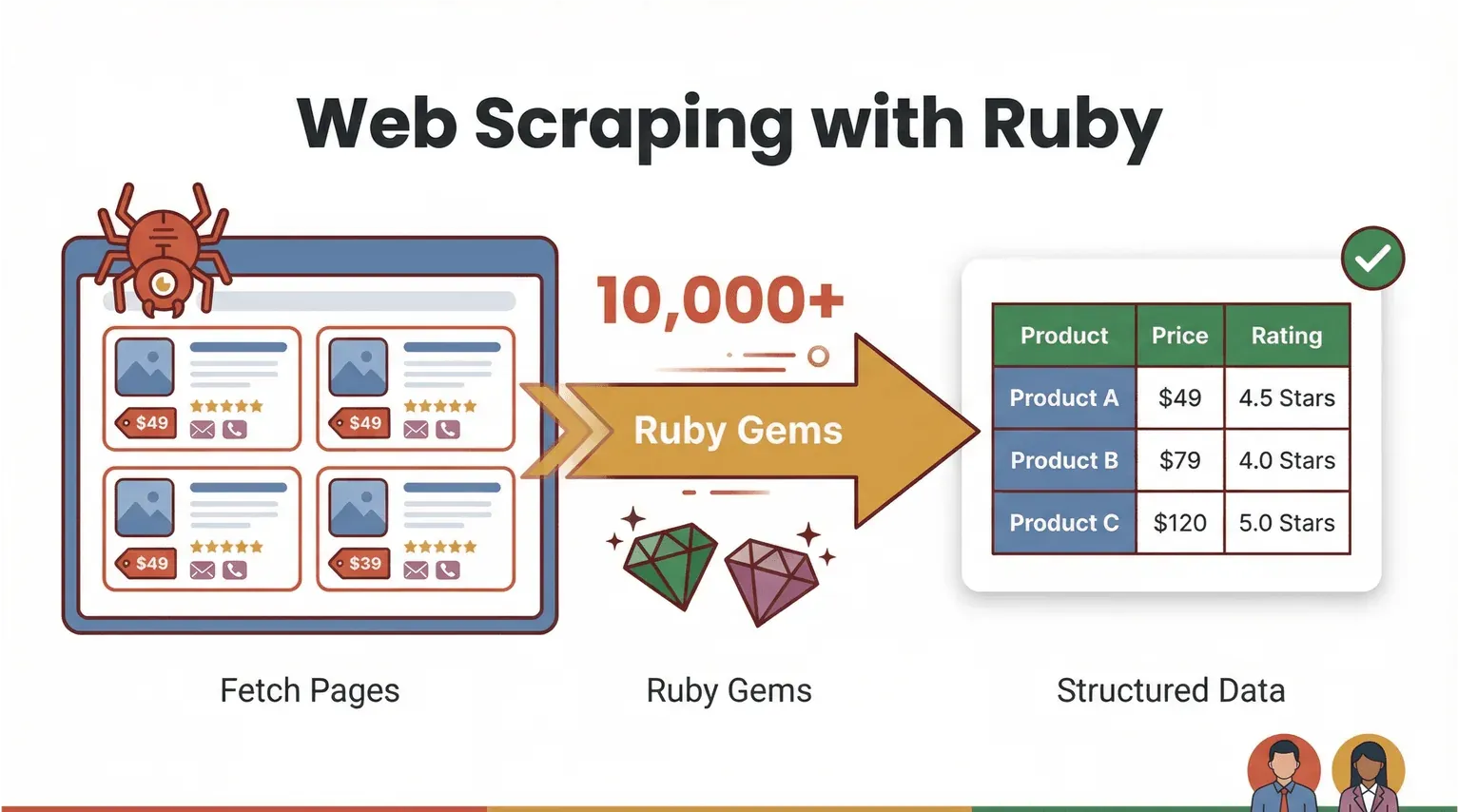
Hai să începem cu bazele. Web scraping-ul este, pe scurt, procesul prin care folosești software pentru a prelua pagini web și a extrage informații specifice — cum ar fi prețuri de produse, date de contact sau recenzii — într-un format structurat, de exemplu CSV sau Excel. Cu Ruby, web scraping-ul este atât puternic, cât și accesibil. Limbajul este cunoscut pentru sintaxa ușor de citit și pentru ecosistemul enorm de „gems” (biblioteci) care fac automatizarea mult mai simplă (Ruby Programming Language).
Cum arată, concret, „web scraping cu Ruby”? Imaginează-ți că vrei să extragi numele și prețurile tuturor produselor de pe un site de ecommerce. Cu Ruby, poți scrie un script care:
- descarcă pagina web (folosind o bibliotecă precum HTTParty)
- parsează HTML-ul pentru a găsi datele dorite (cu Nokogiri)
- exportă rezultatele într-un spreadsheet sau într-o bază de date
Dar aici devine interesant: nu întotdeauna trebuie să scrii cod. Un AI web scraper fără cod, cum este Thunderbit, poate prelua acum partea grea — citește paginile, identifică câmpurile și exportă tabele curate de date în doar câteva clicuri. Ruby rămâne o soluție excelentă ca „lipici” de automatizare pentru fluxuri personalizate, însă AI web scrapers deschid accesul și pentru utilizatorii de business care vor rezultate fără bătaie de cap.
Ce este data scraping-ul? Get Started Free
De ce contează web scraping-ul cu Ruby pentru echipele de business

Să fim sinceri: nimeni nu își dorește să petreacă ziua copiind și lipind date. Cererea pentru extragerea automată a datelor web este în creștere accelerată, și pe bună dreptate. Iată cum web scraping-ul cu Ruby (și cu instrumente AI) schimbă modul în care funcționează operațiunile de business:
- Generare de lead-uri: extragi instant date de contact din directoare sau LinkedIn pentru pipeline-ul de vânzări.
- Monitorizarea prețurilor concurenței: urmărești modificările de preț pentru sute de SKU-uri ecommerce — fără verificări manuale.
- Construirea catalogului de produse: aduni detalii și imagini pentru propriul magazin sau marketplace.
- Cercetare de piață: colectezi recenzii, ratinguri sau articole de știri pentru analiza tendințelor.
ROI-ul este clar: echipele care automatizează colectarea datelor de pe web economisesc ore în fiecare săptămână, reduc erorile și obțin date mai proaspete și mai fiabile. În industrie, de exemplu, 70% dintre companii încă introduc datele manual, deși volumul de date s-a dublat în doar doi ani. Este o oportunitate uriașă pentru automatizare.
Iată un rezumat rapid al valorii oferite de web scraping-ul cu Ruby și de instrumentele AI:
| Caz de utilizare | Problema manuală | Beneficiul automatizării | Rezultat tipic |
|---|---|---|---|
| Generare de lead-uri | Copierea emailurilor unul câte unul | Extragi mii în câteva minute | De 10 ori mai multe lead-uri, mai puțin efort repetitiv |
| Monitorizarea prețurilor | Verificări zilnice ale site-urilor | Extrageri automate, programate | Inteligență de preț în timp real |
| Construirea catalogului | Introducere manuală a datelor | Extragere în masă și formatare | Lansări mai rapide, mai puține erori |
| Cercetare de piață | Citirea manuală a recenziilor | Extragere și analiză la scară | Insight-uri mai profunde și mai proaspete |
Și nu este vorba doar despre viteză — automatizarea înseamnă mai puține greșeli și date mai consistente, ceea ce este esențial atunci când 58% dintre lideri spun că deciziile lor se bazează pe date inexacte sau inconsistente.
Analiza soluțiilor de web scraping: scripturi Ruby vs. AI Web Scraper
Așadar, ar trebui să scrii propriul script Ruby sau să folosești un web scraper fără cod, bazat pe AI? Hai să descompunem opțiunile.
Scriptare în Ruby: control total, dar mentenanță mai mare
Ecosistemul Ruby este plin de gems pentru aproape orice nevoie de scraping:
- Nokogiri: soluția standard pentru parsarea HTML și XML.
- HTTParty: pentru preluarea paginilor web și a API-urilor.
- Mechanize: pentru site-uri care necesită cookie-uri, formulare și navigare.
- Selenium / Watir: pentru automatizarea browserelor reale (excelent pentru site-uri încărcate cu JavaScript).
Cu scripturile Ruby, obții flexibilitate completă — logică personalizată, curățare de date și integrare cu propriile sisteme. Dar îți asumi și partea de mentenanță: când un site își schimbă structura, scriptul se poate strica. Iar dacă nu ești confortabil cu programarea, există și o curbă de învățare.
AI Web Scraper & instrumente fără cod: rapide, ușor de folosit și adaptabile
Web scrapers moderni fără cod, precum Thunderbit, schimbă complet jocul. În loc să scrii cod, faci așa:
- deschizi extensia Chrome
- apeși „AI Suggest Fields” ca să lași AI-ul să identifice ce trebuie extras
- apeși „Scrape” și exporți datele
AI-ul din Thunderbit se adaptează la layout-uri web care se schimbă, gestionează subpagini (cum ar fi detaliile produselor) și exportă direct în Excel, Google Sheets, Airtable sau Notion. Este perfect pentru utilizatorii de business care vor rezultate fără complicații.
Iată o comparație directă:
| Abordare | Avantaje | Dezavantaje | Potrivit pentru |
|---|---|---|---|
| Scriptare Ruby | Control total, logică personalizată, flexibilitate | Curba de învățare mai abruptă, mentenanță | Dezvoltatori, utilizatori avansați |
| AI Web Scraper | Fără cod, configurare rapidă, se adaptează la schimbări | Control mai puțin granular, anumite limite | Utilizatori business, echipe operaționale |
Tendința este clară: pe măsură ce site-urile devin mai complexe și mai defensive, AI web scrapers devin soluția preferată pentru majoritatea fluxurilor de lucru din business.
Cum începi: configurarea mediului Ruby pentru web scraping
Dacă ești gata să încerci scriptarea în Ruby, hai să îți pregătim mediul. Vestea bună? Ruby se instalează ușor și funcționează pe Windows, macOS și Linux.
Pasul 1: Instalează Ruby
- Windows: descarcă RubyInstaller și urmează pașii. Asigură-te că incluzi și MSYS2 pentru compilarea extensiilor native (necesar pentru gems precum Nokogiri).
- macOS/Linux: folosește rbenv pentru gestionarea versiunilor. În Terminal:
brew install rbenv ruby-build
rbenv install 4.0.4
rbenv global 4.0.4
(Verifică pagina de descărcări Ruby pentru cea mai recentă versiune stabilă.)
Pasul 2: Instalează Bundler și gems esențiale
Bundler te ajută să gestionezi dependențele:
gem install bundler
Creează un Gemfile pentru proiectul tău:
source 'https://rubygems.org'
gem 'nokogiri'
gem 'httparty'
Apoi rulează:
bundle install
Asta îți asigură un mediu consecvent și pregătit pentru scraping.
Pasul 3: Testează configurarea
Încearcă asta în IRB (shell-ul interactiv Ruby):
require 'nokogiri'
require 'httparty'
puts Nokogiri::VERSION
Dacă vezi un număr de versiune, ești gata de lucru!
Pas cu pas: construirea primului tău web scraper în Ruby
Hai să parcurgem un exemplu real — extragerea datelor despre produse de pe Books to Scrape, un site creat special pentru practică.
Iată un script Ruby simplu pentru a extrage titluri de cărți, prețuri și statusul stocului:
require "net/http"
require "uri"
require "nokogiri"
require "csv"
BASE_URL = "https://books.toscrape.com/"
def fetch_html(url)
uri = URI.parse(url)
res = Net::HTTP.get_response(uri)
raise "HTTP #{res.code} for #{url}" unless res.is_a?(Net::HTTPSuccess)
res.body
end
def scrape_list_page(list_url)
html = fetch_html(list_url)
doc = Nokogiri::HTML(html)
products = doc.css("article.product_pod").map do |pod|
title = pod.css("h3 a").first["title"]
price = pod.css(".price_color").text.strip
stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
{ title: title, price: price, stock: stock }
end
next_rel = doc.css("li.next a").first&.[]("href")
next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
[products, next_url]
end
rows = []
url = "#{BASE_URL}catalogue/page-1.html"
while url
products, url = scrape_list_page(url)
rows.concat(products)
end
CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
end
puts "Wrote #{rows.length} rows to books.csv"
Acest script preia fiecare pagină, parsează HTML-ul, extrage datele și le scrie într-un fișier CSV. Îl poți deschide apoi în Excel sau Google Sheets.
Capcane frecvente:
- Dacă primești erori legate de gems lipsă, verifică din nou
Gemfileși ruleazăbundle install. - Pentru site-urile care încarcă datele prin JavaScript, vei avea nevoie de un instrument de automatizare a browserului, precum Selenium sau Watir.
Cum îți duci scraping-ul Ruby la nivelul următor cu Thunderbit: AI Web Scraper în acțiune
Acum să vedem cum Thunderbit poate duce scraping-ul la nivelul următor — fără cod.
Thunderbit este o extensie Chrome AI web scraper care îți permite să extragi date structurate din orice site în doar două clicuri. Iată cum funcționează:
- Deschide extensia Thunderbit pe pagina pe care vrei să o extragi.
- Apasă „AI Suggest Fields”. AI-ul Thunderbit scanează pagina și propune cele mai bune coloane de extras (de exemplu „Nume produs”, „Preț”, „Stoc”).
- Apasă „Scrape”. Thunderbit colectează datele, gestionează paginarea și chiar urmărește subpagini dacă ai nevoie de detalii suplimentare.
- Exportă datele direct în Excel, Google Sheets, Airtable sau Notion.
Ce face Thunderbit diferit este capacitatea lui de a gestiona pagini web complexe și dinamice — fără selectori fragili și fără cod. Iar dacă vrei să combini fluxurile, poți folosi Thunderbit pentru a extrage datele, apoi să le procesezi sau să le îmbogățești cu un script Ruby.
Sfat util: scraping-ul de subpagini în Thunderbit este extrem de valoros pentru echipele de ecommerce și real estate. Extragi o listă de linkuri de produse, apoi lași Thunderbit să viziteze fiecare pagină pentru a prelua specificații, imagini sau recenzii — îmbogățindu-ți automat setul de date.
Cum să extragi date de pe orice site folosind AI Get Started Free
Exemplu real: extragerea datelor de produse și prețuri din ecommerce cu Ruby și Thunderbit
Hai să punem totul cap la cap printr-un flux practic pentru echipele de ecommerce.
Scenariu: vrei să monitorizezi prețurile concurenței și detaliile produselor pentru sute de SKU-uri.
Pasul 1: folosește Thunderbit pentru a extrage lista principală de produse
- Deschide pagina cu listarea produselor a concurentului.
- Pornește Thunderbit și apasă „AI Suggest Fields” (de exemplu: Product Name, Price, URL).
- Apasă „Scrape” și exportă rezultatele în CSV.
Pasul 2: îmbogățește datele cu scraping de subpagini
- În Thunderbit, folosește funcția „Scrape Subpages” pentru a vizita pagina de detalii a fiecărui produs și a extrage câmpuri suplimentare (cum ar fi descrierea, stocul sau imaginile).
- Exportă tabelul îmbogățit.
Pasul 3: procesează sau analizează cu Ruby
- Folosește un script Ruby pentru a curăța, transforma sau analiza în continuare datele. De exemplu, poți să:
- convertești prețurile într-o monedă standard
- filtrezi produsele fără stoc
- generezi statistici sumar
Iată un snippet Ruby simplu pentru filtrarea produselor aflate în stoc:
require 'csv'
rows = CSV.read('products.csv', headers: true)
in_stock = rows.select { |row| row['stock'].include?('In stock') }
CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
in_stock.each { |row| csv << row }
end
Rezultat:
Treci de la pagini web brute la un tabel de date curat și utilizabil — pregătit pentru analiza prețurilor, planificarea stocurilor sau campanii de marketing. Și ai făcut totul fără să scrii nicio linie de cod de scraping.
Fără cod, fără probleme: automatizarea extragerii datelor web pentru toată lumea
Unul dintre lucrurile mele preferate la Thunderbit este că îi ajută și pe utilizatorii fără profil tehnic. Nu trebuie să știi Ruby, HTML sau CSS — deschizi extensia, lași AI-ul să facă treaba și exporți datele.
Curba de învățare: cu scripturi Ruby, trebuie să înveți bazele programării și structura web-ului. Cu Thunderbit, timpul de configurare se măsoară în minute, nu în zile.
Integrare: Thunderbit exportă direct în instrumentele pe care echipele de business deja le folosesc — Excel, Google Sheets, Airtable, Notion. Poți chiar programa extrageri recurente pentru monitorizare continuă.
Feedback de la utilizatori: am văzut echipe de marketing, sales ops și manageri de ecommerce folosind Thunderbit pentru a automatiza totul, de la construirea listelor de lead-uri până la urmărirea prețurilor — fără să apeleze vreodată la IT.
Cele mai bune practici: combinarea Ruby și AI Web Scraper pentru automatizare scalabilă
Vrei să construiești un flux de scraping robust și scalabil? Iată recomandările mele principale:
- Gestionează schimbările de site: AI web scrapers precum Thunderbit se adaptează automat, dar dacă folosești scripturi Ruby, fii pregătit să actualizezi selectoarele atunci când site-urile se schimbă.
- Programează extragerile: folosește funcția de programare din Thunderbit pentru extrageri regulate de date. Pentru Ruby, setează un cron job sau folosește un scheduler de sarcini.
- Procesare pe loturi: pentru seturi mari de date, împarte scraping-ul în loturi ca să eviți blocarea sau suprasolicitarea sistemului.
- Formatarea datelor: curăță și validează întotdeauna datele înainte de analiză — exporturile Thunderbit sunt structurate, dar scripturile Ruby personalizate pot avea nevoie de verificări suplimentare.
- Conformitate: extrage doar date disponibile public, respectă
robots.txtși fii atent la legile privind confidențialitatea (mai ales în UE — GDPR se aplică datelor personale extrase). - Planuri de rezervă: dacă un site devine prea complex sau blochează scraping-ul, caută API-uri oficiale sau surse alternative de date.
Când folosești fiecare?
- Folosește scripturi Ruby când ai nevoie de control complet, logică personalizată sau integrare cu sisteme interne.
- Folosește Thunderbit când vrei viteză, ușurință și adaptabilitate — mai ales pentru sarcini de business punctuale sau recurente.
- Combină-le pe ambele pentru fluxuri avansate: lasă Thunderbit să facă extragerea, apoi folosește Ruby pentru îmbogățire, QA sau integrare.
Concluzie și idei principale
Web scraping-ul cu Ruby a fost mereu o superputere pentru automatizarea colectării de date — iar acum, cu AI web scrapers precum Thunderbit, această putere este accesibilă tuturor. Fie că ești dezvoltator și cauți flexibilitate, fie că ești utilizator de business și vrei doar rezultate, poți automatiza extragerea datelor web, economisi ore de muncă manuală și lua decizii mai bune, mai rapid.
Iată ce sper să reții:
- Ruby este un instrument excelent pentru web scraping și automatizare — mai ales cu gems precum Nokogiri și HTTParty.
- AI web scrapers precum Thunderbit fac extragerea datelor accesibilă și pentru cei fără cod, cu funcții precum „AI Suggest Fields” și scraping de subpagini.
- Combinarea Ruby cu Thunderbit îți oferă ce e mai bun din ambele lumi: extragere rapidă, fără cod, plus automatizare și analiză personalizată.
- Automatizarea colectării datelor web este o strategie excelentă pentru echipele de vânzări, marketing și ecommerce — reduce munca manuală, crește acuratețea și descuie insight-uri noi.
Gata de pornire? Descarcă Thunderbit, încearcă un script Ruby simplu și vezi cât timp poți economisi. Iar dacă vrei să aprofundezi, consultă Thunderbit Blog pentru mai multe ghiduri, sfaturi și exemple din lumea reală.
Descarcă extensia Chrome Thunderbit
Întrebări frecvente
1. Trebuie să știu să programez ca să folosesc Thunderbit pentru web scraping?
Nu. Thunderbit este creat pentru utilizatori fără profil tehnic. Deschizi extensia, apeși „AI Suggest Fields” și lași AI-ul să facă restul. Poți exporta datele în Excel, Google Sheets, Airtable sau Notion — fără cod.
2. Care sunt principalele avantaje ale utilizării Ruby pentru web scraping?
Ruby oferă biblioteci puternice precum Nokogiri și HTTParty pentru fluxuri de scraping flexibile și personalizate. Este ideal pentru dezvoltatorii care vor control complet, logică proprie și integrare cu alte sisteme.
3. Cum funcționează funcția „AI Suggest Fields” din Thunderbit?
AI-ul Thunderbit scanează pagina web, detectează cele mai relevante câmpuri de date (cum ar fi numele produselor, prețurile sau emailurile) și îți propune un tabel structurat. Poți ajusta coloanele înainte de scraping, dacă este nevoie.
4. Pot combina Thunderbit cu scripturi Ruby pentru fluxuri avansate?
Absolut. Multe echipe folosesc Thunderbit pentru a extrage datele, mai ales din site-uri complexe sau dinamice, iar apoi le procesează sau le analizează mai departe cu scripturi Ruby. Această abordare hibridă este excelentă pentru raportare personalizată sau îmbogățirea datelor.
5. Este web scraping-ul legal și sigur pentru uz de business?
Web scraping-ul este legal atunci când colectezi date disponibile public și respecți termenii site-ului și legile privind confidențialitatea. Verifică întotdeauna robots.txt și evită extragerea datelor personale fără consimțământul adecvat — mai ales pentru utilizatorii din UE, unde se aplică GDPR.
Vrei să vezi cum web scraping-ul îți poate transforma fluxul de lucru? Încearcă varianta gratuită Thunderbit sau experimentează azi cu un script Ruby. Iar dacă te blochezi, Thunderbit Blog și canalul Thunderbit de YouTube sunt pline de tutoriale și sfaturi care te ajută să stăpânești automatizarea datelor web — fără cod.
Încearcă AI Web Scraper-ul Thunderbit Get Started Free
Află mai multe




