
Temu ajunge acum la peste în peste 50 de piețe. Catalogul său de produse acoperă totul, de la gadgeturi de bucătărie și accesorii pentru animale de companie până la benzi LED. Dacă lucrezi în ecommerce, dropshipping sau intelligence competitiv, probabil ai vrut să extragi date din Temu într-un spreadsheet — și apoi ai descoperit că Temu chiar nu vrea să faci asta.
Am petrecut mult timp cercetând și testând instrumente de scraping pentru site-uri ecommerce protejate. Temu este una dintre cele mai dificile ținte de acolo. Cele mai multe ghiduri online fie îți oferă un tutorial Python care se strică în decurs de o săptămână, fie te trimit către API-uri enterprise care costă mai mult decât bugetul tău lunar de advertising.
Realitatea este că majoritatea utilizatorilor business — dropshipperi, operatori solo, echipe de marketing — vor doar un spreadsheet curat cu nume de produse, prețuri, imagini, evaluări și informații despre vânzător. Nu vor să depaneze scripturi Playwright la 2 dimineața.
Acest ghid este construit în jurul acestui gol: o analiză practică, organizată pe nivel de competență, a celor mai bune Temu scrapers care chiar funcționează în 2026, plus bunele practici care transformă un scraping brut în intelligence competitiv continuu. Fie că ești începător sau un dezvoltator care construiește un data pipeline, aici există o secțiune pentru tine.
De ce să faci scraping Temu? Principalele cazuri de utilizare pentru echipele business
Datele din Temu nu sunt doar interesante — sunt utile strategic.
Platforma a devenit o forță de stabilire a prețurilor în categoriile de produse ieftine și medii. Chiar dacă nu vinzi pe Temu, clienții tăi compară prețurile tale cu ceea ce văd acolo. Iată cum folosesc echipele diferite datele din Temu:
| Caz de utilizare | Date necesare | De ce contează |
|---|---|---|
| Cercetare de produse pentru dropshipping | Titlu, preț, imagine, evaluare, număr de recenzii, număr de vândute, variante | Găsește produse cu cost redus și semnale de cerere pentru comparație pe Amazon, Shopify, AliExpress, TikTok Shop |
| Prețuri competitive | Preț curent, preț inițial, discount %, monedă, livrare, marcaj temporal | Construiește o bază pentru strategia de preț și planificarea promoțiilor |
| Sourcing de produse | Specificații, imagini, variante, vânzător/magazin, ID articol, categorie | Identifică tipuri de produse și listări de tip furnizor care merită verificări suplimentare |
| Analiza tendințelor pieței | Cuvânt cheie de căutare, categorie, număr de vândute, număr de recenzii, evaluare | Arată ce produse câștigă tracțiune în diferite categorii |
| Cercetare de marketing și creativ | Titlu, imagine, număr de recenzii, evaluare, descrieri, etichete de categorie | Dezvăluie mesajele, elementele vizuale, pachetele și afirmațiile folosite de listările cu volum mare |
| Monitorizarea stocurilor și disponibilității | URL produs, disponibilitate, estimare de livrare, preț, marcaj temporal | Surprinde lipsurile de stoc, schimbările de depozit local și variațiile de preț în timp |
Publicul care caută „cele mai bune Temu scrapers” tinde să se împartă în trei grupuri. Utilizatorii non-tehnici vor o extensie Chrome care scoate un spreadsheet. Operatorii semi-tehnici vor un instrument vizual cu template-uri și programare. Dezvoltatorii vor un API, un script Playwright și o strategie de proxy.
Acest articol le acoperă pe toate trei — dar începe cu cel mai mare grup: oamenii care au nevoie de date, nu de cod.
Ce face ca cele mai bune Temu scrapers să iasă în evidență în 2026
Un scraper care funcționează pe Amazon sau Shopify nu va supraviețui neapărat pe Temu. Criteriile de evaluare pentru acest articol sunt:
- Fiabilitate pe Temu — Returnează într-adevăr date curate sau este blocat, returnează rânduri goale ori se strică după o schimbare de layout?
- Ușurința în utilizare — Poate porni un utilizator business non-tehnic fără să scrie cod?
- Completitudinea datelor — Suportă îmbogățirea subpaginilor (vizitarea fiecărei pagini de detalii produs pentru specificații, variante, informații despre vânzător)?
- Efort de mentenanță — Se adaptează când Temu își schimbă structura paginii?
- Programare și monitorizare — Poate rula scraping recurent și exporta către o destinație de date care rămâne activă?
- Destinații de export — CSV, Excel, Google Sheets, Airtable, Notion, JSON?
- Claritatea costurilor — Cât costă realist, pe lună, un flux de lucru de scraping Temu?
Raportările comunității de pe descriu constant Temu drept unul dintre cele mai dificile site-uri ecommerce de făcut scraping. Un utilizator a scris că „nici măcar nu poate obține un preț ca și cumpărător”, în timp ce altul a remarcat că Temu și Shopee au echipe care întăresc continuu mecanismele anti-bot. Date publice comparative despre rata de eșec pentru Temu nu există, dar a constatat că traficul automat a depășit traficul uman, boții reprezentând din tot traficul de internet. Acesta este mediul în care se apără Temu.
Apărările anti-bot ale Temu: de ce eșuează majoritatea scrapers
Cele mai multe articole despre scraping Temu dedică o singură propoziție măsurilor anti-bot: „Temu folosește anti-bot.” Asta nu ajută.
Dacă alegi un instrument, trebuie să știi ce apărări folosește Temu și ce capabilități ale instrumentului le înving pe fiecare. Iată harta practică:
| Apărarea Temu | Ce face | Capabilitatea necesară a instrumentului | Exemple de instrumente |
|---|---|---|---|
| Cloudflare WAF / verificări de browser | Blochează user-agent-urile automate, detectează fingerprint-uri de bot, returnează pagini de challenge | Infrastructură cloud cu IP-uri rezidențiale rotative și fingerprint-uri reale de browser | Thunderbit (cloud scraping), Bright Data, Oxylabs, ScraperAPI |
| Randare JavaScript intensă | Datele produsului se încarcă prin JS; HTML-ul brut este gol | Browser headless sau randare completă în browser | Thunderbit (modul browser scraping), Playwright, Selenium, ParseHub, actori browser Apify |
| Selectori CSS dinamici | Numele claselor se schimbă între deploy-uri, stricând scrapers bazate pe CSS | Detectare de câmpuri pe bază de AI (nu depinde de selectori fixați) | Thunderbit (AI citește pagina proaspăt de fiecare dată), Bright Data AI scraper builder |
| Rate limiting | Limitează solicitările secvențiale rapide | Solicitări cloud concurente cu throttling inteligent | Thunderbit (până la 50 de pagini simultan prin cloud), ScraperAPI, Bright Data |
| Provocări CAPTCHA | Întrerupe sesiunile după comportament suspect | Rezolvare CAPTCHA integrată sau strategie cu declanșare mai redusă | Bright Data, Oxylabs, ScraperAPI premium/ultra-premium |
| Infinite scroll / încărcare lazy | Apar doar primele produse fără interacțiune | Scrolling inteligent, detectarea paginării, automatizare a interacțiunii | Thunderbit pagination, Apify smart scrolling, Octoparse workflow builder |
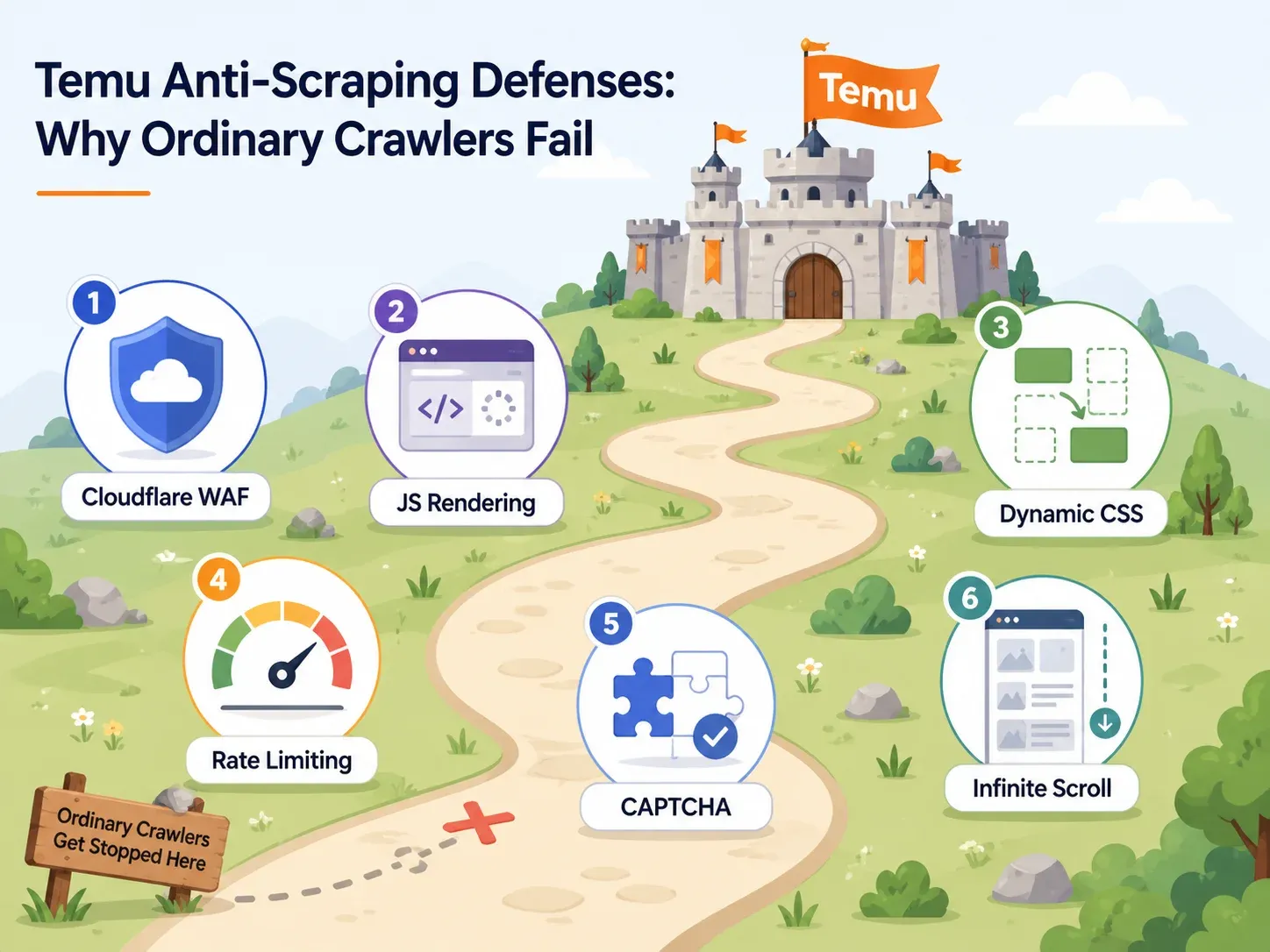
Cloudflare WAF și blocarea IP-urilor
Ușa de intrare a Temu este păzită de verificări de integritate ale browserului de tip Cloudflare. Cererile HTTP de bază — genul făcut de un simplu apel Python requests.get() — sunt provocate, primesc 403 sau sunt servite cu date incomplete.
Instrumentele care funcționează aici au nevoie de IP-uri rezidențiale sau mobile rotative și de fingerprint-uri reale de browser. a raportat că boții non-AI au început 2025 fiind responsabili pentru aproximativ jumătate din cererile către paginile HTML. Aceasta este scala automată împotriva căreia se apără platforme precum Temu.
Randarea JavaScript și selectori dinamici
Aici eșuează în tăcere majoritatea scraperelor pentru începători.
Dacă vezi sursa paginii Temu, vei găsi adesea un shell gol — cardurile reale de produs, prețurile și imaginile sunt injectate prin JavaScript după ce se încarcă pagina. Un scraper care citește doar HTML brut nu va returna nimic util. În plus, numele claselor CSS și structurile DOM ale Temu se schimbă între deploy-uri. Un scraper care se bazează pe un selector CSS fix precum .product-card__price va funcționa azi și va returna coloane goale mâine.
Scrapers pe bază de AI (ca ) citesc pagina semantic de fiecare dată, așa că nu depind de menținerea acelorași nume de clasă.
Rate limiting și provocări CAPTCHA
Dacă lovești Temu prea repede sau de prea multe ori dintr-un singur IP, vei declanșa limite de rată sau provocări CAPTCHA. Unele instrumente gestionează asta cu throttling inteligent și rezolvare CAPTCHA integrată. Altele te lasă pe tine să rezolvi problema — ceea ce, pentru un utilizator non-tehnic, este practic o fundătură.
Pentru cloud scraping, cheia este reprezentată de solicitări concurente distribuite pe IP-uri curate, cu logică automată de retry.
Cele mai bune Temu scrapers pe nivel de competență: o analiză completă
Găsește-ți rândul și sari la secțiunea potrivită:
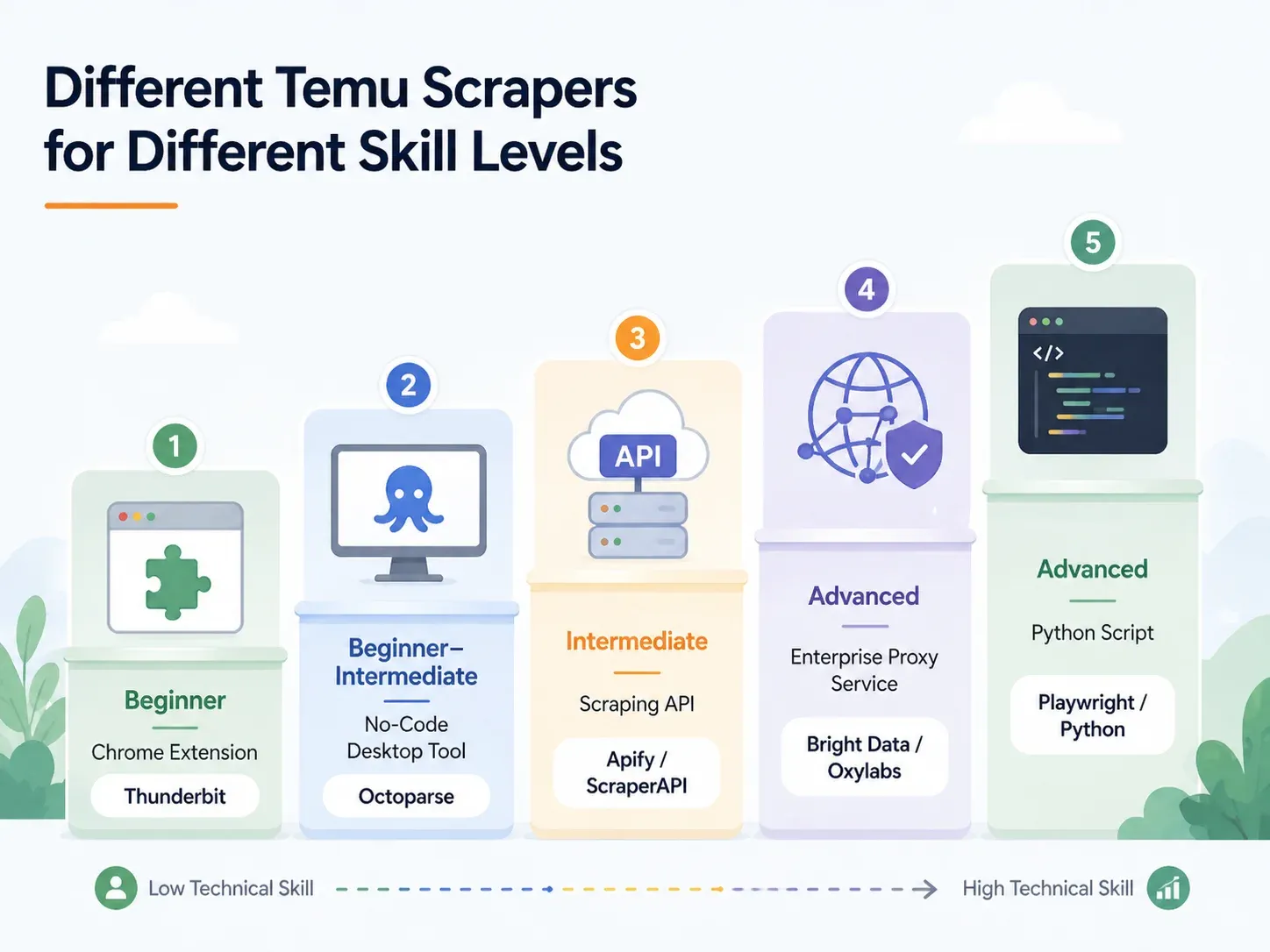
| Abordare | Nivel de competență | Timp de configurare | Gestionarea anti-bot | Cel mai bun pentru |
|---|---|---|---|---|
| Extensie Chrome AI (ex. Thunderbit) | Începător | < 2 min | Gestionat (cloud sau browser) | Dropshipperi, marketeri, operațiuni ecommerce |
| Instrument desktop no-code (ex. Octoparse, ParseHub) | Începător–Intermediar | 10–60 min | Parțial (este nevoie de configurare proxy) | Scraping regulat cu template-uri |
| API/serviciu de scraping (ex. ScraperAPI, Apify) | Intermediar | 15–45 min | Integrat | Dezvoltatori care îl integrează în pipeline-uri |
| Proxy gestionat/enterprise (ex. Bright Data, Oxylabs) | Avansat/Enterprise | Ore–zile | Infrastructură completă | Volum mare, livrare în warehouse |
| Script Python personalizat (Playwright/Selenium) | Avansat | 1–4 ore+ | Manual (configurare proxy + CAPTCHA) | Control total, personalizare pentru cazuri speciale |
Thunderbit: cel mai bun Temu scraper pentru utilizatorii non-tehnici
este o extensie Chrome alimentată de AI, construită pentru utilizatori business — echipe de vânzări, operatori ecommerce, dropshipperi, marketeri — care au nevoie de date structurate din site-uri fără să scrie cod. Lucrez în echipa Thunderbit, așa că știu bine produsul. O să fiu direct despre ce face și unde se potrivește.
Fluxul de bază are două clicuri: deschizi o pagină Temu, apeși AI Suggest Fields, verifici coloanele sugerate (numele produsului, preț, imagine, evaluare etc.), apoi apeși Scrape.
AI-ul Thunderbit citește structura paginii și propune automat numele coloanelor și tipurile de date. Nu se bazează pe selectori CSS fixați, așa că atunci când Temu își schimbă numele claselor sau layout-ul cardurilor, scraperul se adaptează.
Funcții cheie pentru Temu:
- Modul cloud scraping: Mai rapid pentru pagini publice, procesează până la 50 de pagini simultan. Ideal pentru pagini de categorie, rezultate de căutare și listări de produse care nu necesită autentificare.
- Modul browser scraping: Folosește sesiunea ta curentă Chrome, inclusiv cookie-uri, localizare și starea de login. Ideal atunci când regiunea, pop-up-urile sau conținutul autentificat influențează ce afișează pagina.
- Scrape Subpages: După ce faci scraping la o pagină de listare, apasă „Scrape Subpages” pentru a vizita fiecare pagină de detalii produs și a adăuga coloane precum descriere completă, variante, informații despre vânzător, estimare de livrare și specificații — fără nicio configurare suplimentară.
- Field AI Prompts: Clasifică, traduce sau reformatează datele în timpul scrapingului. De exemplu: „Clasifică acest produs în Kitchen Utensils, Small Appliances, Storage sau Other.”
- Scraping programat: Setezi un program în limbaj natural („în fiecare luni la 9:00”), introduci URL-urile, iar Thunderbit rulează scrapingul în cloud și exportă către Google Sheets, Airtable sau o altă destinație.
- Exporturi gratuite: Excel, CSV, Google Sheets, Airtable, Notion, JSON — fără paywall pentru export. Imaginile se exportă ca atașamente reale în Airtable și Notion.
Prețuri: plan gratuit cu până la 6 pagini (sau 10 cu un trial boost); planurile plătite încep de la aproximativ pentru 500 de credite, cu 1 credit = 1 rând de ieșire.
Comparativ, unul lângă altul: Thunderbit vs. script Python pe aceeași pagină Temu
Contrastul este puternic:
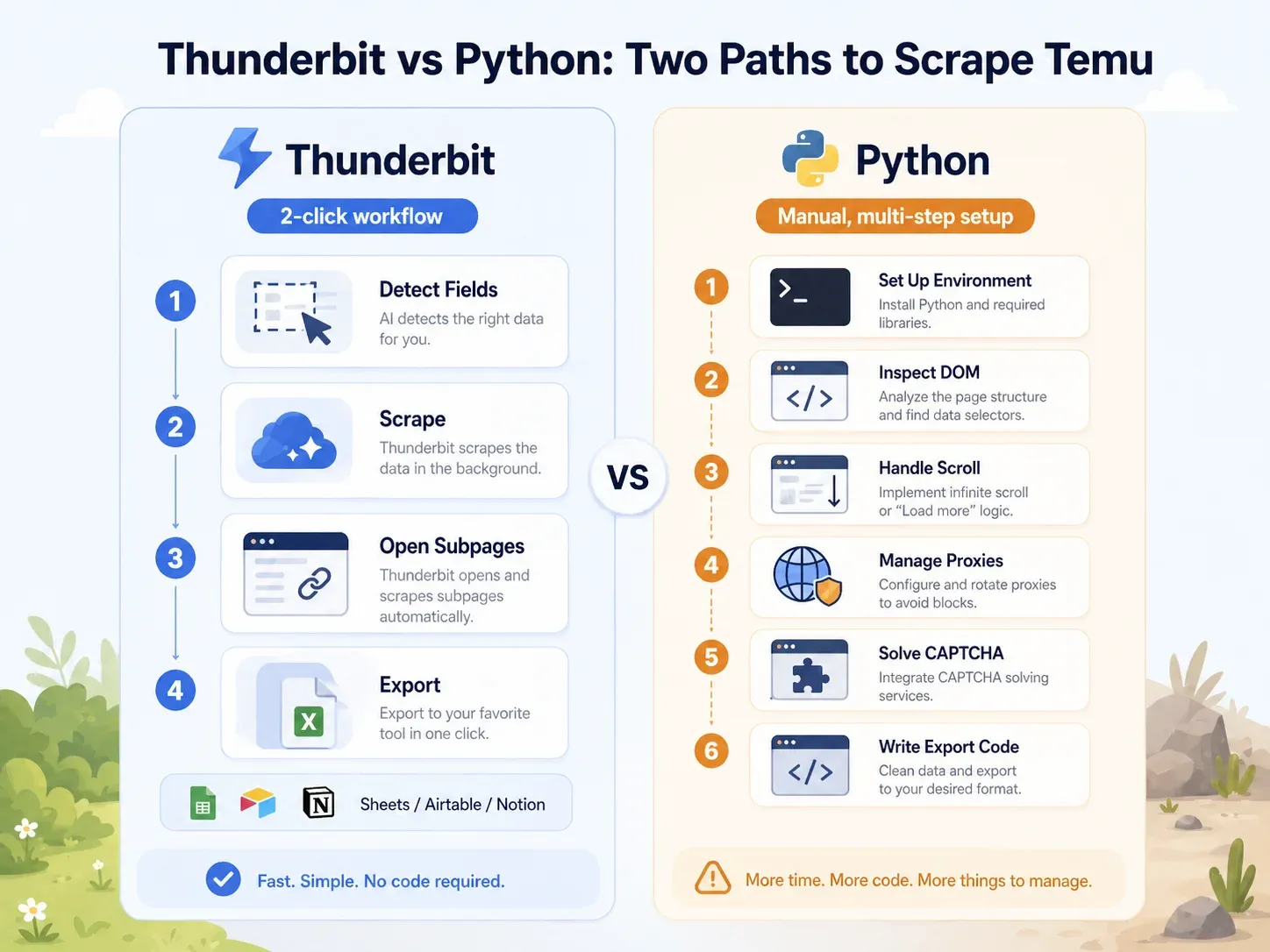
| Sarcină | Thunderbit | Python (Playwright) |
|---|---|---|
| Deschide pagina de categorie Temu | Deschide pagina în Chrome | Configurează mediul Python, instalează Playwright, instalează browsere |
| Identifică câmpurile | Apasă „AI Suggest Fields” | Inspectează DOM-ul, apelurile de rețea, payload-urile JSON |
| Gestionează încărcarea dinamică | Modul browser/cloud + paginare | Scrie logică de scroll/wait, interceptare request-uri |
| Gestionează blocările | Încearcă modul cloud sau browser | Adaugă proxy-uri, headere, fingerprinting, retry-uri |
| Extrage câmpurile listării | Apasă „Scrape” | Scrie selectori sau logică de parsare API |
| Îmbogățește paginile de produs | Apasă „Scrape Subpages” | Construiește un crawler separat pentru PDP |
| Export | Apasă Sheets/Airtable/Notion/Excel | Scrie cod de integrare CSV/JSON/Sheets |
| Configurare tipică pentru un utilizator business | Sub 2 minute | Minim 1–4 ore; mentenanță continuă |
Un prototip minim Playwright pentru Temu ar putea arăta așa (pseudocod — nu este gata de producție):
1from playwright.sync_api import sync_playwright
2with sync_playwright() as p:
3 browser = p.chromium.launch(headless=False)
4 page = browser.new_page()
5 page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
6 page.wait_for_load_state("networkidle")
7 for _ in range(8):
8 page.mouse.wheel(0, 2000)
9 page.wait_for_timeout(1200)
10 cards = page.locator("[data-product-id], a[href*='goods.html']")
11 # Codul de producție mai are nevoie de selectori, proxy-uri, retry-uri,
12 # gestionare CAPTCHA, crawling PDP și logică de export.
13 print(cards.count())Asta înseamnă peste 10 linii înainte să fi extras un singur câmp, și nici nu ai atins proxy-urile, CAPTCHA, îmbogățirea PDP sau exportul. Pentru un utilizator non-tehnic, Thunderbit comprimă întregul flux în câteva clicuri. Pentru un dezvoltator, ruta Python oferă mai mult control — dar cu un cost de mentenanță mult mai mare.
Octoparse și ParseHub: scrapers Temu desktop no-code
Dacă vrei mai mult control decât oferă o extensie Chrome, dar nu vrei să scrii cod, Octoparse și ParseHub sunt principalele opțiuni.
Octoparse are un template public Temu Details Scraper. Outputul său de exemplu include ID-uri de produs, titluri, prețuri, date despre vânzător/magazin, URL-uri de imagine, discounturi, URL-uri de magazin și specificații detaliate. Acesta este un avantaj real — poți începe cu un template, nu să construiești un flux de la zero. Octoparse suportă, de asemenea, extragere cloud, programare și construirea vizuală a fluxurilor de lucru.
Atenționările pentru Temu:
- Add-on-urile anti-bot (proxy-uri rezidențiale la , rezolvare CAPTCHA la $1–$1.50 per mie) pot ajunge rapid costisitoare.
- Template-urile se pot rupe când Temu își schimbă layout-ul. Poate fi nevoie să actualizezi selectoarele sau să aștepți ca Octoparse să întrețină template-ul.
- Configurarea durează 10–60 de minute, în funcție de complexitatea paginii.
Prețurile Octoparse: plan gratuit cu 10 task-uri și 50K export lunar de date; Standard în jur de $75/lună anual; Professional în jur de $108/lună anual. Add-on-urile pentru proxy-uri, CAPTCHA și servicii gestionate costă extra.
ParseHub este un scraper vizual desktop/web care gestionează bine paginile dinamice (rulează un browser Chromium complet). Totuși, planurile plătite încep de la $189/lună, ceea ce este abrupt pentru un operator solo. În cercetarea mea nu am găsit un template public puternic, specific Temu. ParseHub se potrivește mai bine echipelor deja obișnuite să construiască proiecte vizuale de scraping.
| Instrument | Puncte forte pentru Temu | Slăbiciuni pe Temu | Prețuri |
|---|---|---|---|
| Octoparse | Template public Temu, flux de lucru vizual, extragere cloud, programare | Mentenanță a template-ului, add-on-urile anti-bot cresc costul | Gratuit; ~75$/lună anual Standard; ~108$/lună anual Pro; add-on-uri separat |
| ParseHub | Gestionare a paginilor dinamice, builder de flux de proiect, rotație IP pe planurile plătite | Preț de intrare mai mare, nu a fost găsit un template public Temu | Planuri plătite de la 189$/lună |
API-uri de scraping: ScraperAPI, Apify și Bright Data pentru Temu
Serviciile de scraping bazate pe API gestionează proxy-urile, randarea și logica anti-bot, astfel încât dezvoltatorii să se poată concentra pe parsarea și stocarea datelor. Se potrivesc când construiești un pipeline, nu când rulezi o exportare unică într-un spreadsheet.
ScraperAPI este un API pentru dezvoltatori pentru rotația proxy-urilor și randare. Pagina sa de prețuri listează un trial de 7 zile cu 5.000 de credite, Hobby la $49/lună pentru 100.000 de credite și niveluri mai mari după aceea. Capcana pentru Temu: randarea JavaScript și pool-urile premium de proxy-uri costă 10–75 de credite per solicitare, în funcție de nivel. Această multiplicare a creditelor înseamnă că prețul efectiv per rând poate fi mult mai mare decât prețul afișat.
Apify este o platformă cu un marketplace de „actori” predefiniți (scrapers). Există mai mulți actori Temu. Un Temu Scraper menținut de comunitate listează prețuri pay-per-event în jur de $5 per 1.000 de produse pe nivelul gratuit. Un alt Temu Products Scraper listează $4 per 1.000 de rezultate. Riscul: calitatea actorilor variază, mentenanța depinde de comunitate, iar unii actori pot fi depășiți sau se pot rupe când Temu actualizează platforma. Verifică întotdeauna data „last modified” și ratingurile utilizatorilor înainte de a te angaja.
Bright Data este opțiunea enterprise. Pagina sa de scraper Temu spune că joburile rulează pe infrastructura Bright Data cu rotație de proxy-uri, geo-targeting, logică CAPTCHA/deblocare și autoscaling. Formatele de output includ JSON, CSV, Parquet și livrare directă către S3, GCS, Azure Blob, BigQuery și Snowflake. Recenziile din industrie raportează Web Scraper API pay-as-you-go la aproximativ $2.5 per 1.000 de înregistrări, cu planuri contractuale începând de la circa $499/lună. Puternic, dar prețuit pentru echipe cu bugete reale.
Oxylabs are, de asemenea, o pagină dedicată Temu Scraper API. Planurile încep de la $49/lună, cu un trial gratuit de până la 2.000 de rezultate. Este o alternativă solidă la Bright Data pentru echipele de dezvoltare care vor date Temu structurate prin API.
| API/Platformă | Dovadă specifică pentru Temu | Punct forte | Punct slab | Cel mai bun pentru |
|---|---|---|---|---|
| ScraperAPI | Nu a fost găsită o pagină specifică Temu, dar funcțiile anti-bot pentru ecommerce sunt documentate | Endpoint simplu, randare JS, proxy-uri premium | Multiplicatori de credite pentru funcțiile premium; dezvoltatorii trebuie să parseze datele | Pipeline-uri pentru dezvoltatori |
| Apify | Mai mulți actori Temu în marketplace | Cel mai rapid traseu pentru dezvoltatori dacă actorul se potrivește și este menținut | Calitatea actorilor variază; unii sunt depășiți | Dezvoltatori care vor marketplace de actori + programare |
| Bright Data | Pagină dedicată pentru scraper Temu | Infrastructură enterprise, deblocare, livrare în warehouse | Scump; conceptele de web scraping rămân necesare | Echipe enterprise de date |
| Oxylabs | Pagină dedicată Temu Scraper API | Preț clar per rezultat, gestionare JS, revendicări privind IP/CAPTCHA | Flux de lucru API pentru dezvoltatori | Echipe de dezvoltare care au nevoie de acces Temu prin API |
Scripturi Python personalizate (Playwright/Selenium): control total, efort mare
Scrapers Python personalizate oferă flexibilitate maximă — acesta este avantajul. Playwright este, în general, un punct de pornire mai bun decât Selenium pentru Temu datorită modelului său de auto-wait și a gestionării mai bune a paginilor încărcate intens cu JavaScript.
Dar compromisurile sunt dure.
Un prototip durează 1–4 ore. Un scraper de producție are nevoie de rotație de proxy-uri, fingerprint-uri de browser realiste, strategie CAPTCHA, retry-uri, validarea schemei, stocarea outputului, monitorizare, alertare și revizuire legală.
Și se strică. Comunitățile de scraping de pe Reddit descriu constant scrapingul modern ecommerce ca fiind instabil când site-urile folosesc Cloudflare, randare JavaScript și fingerprint-uri anti-bot.
| Mod de eșec | Cauză tipică | Măsură de atenuare | |---|---|---|---| | HTML gol / produse lipsă | JS încarcă cardurile de produs după HTML-ul inițial | Folosește Playwright, așteaptă rețeaua și DOM-ul | | Doar primele câteva produse | Infinite scroll / încărcare lazy | Buclă de scroll, așteptări pentru network idle, praguri de numărare a cardurilor | | Prețuri lipsă sau inconsistente | Stare region/session/monedă sau răspuns anti-bot | Setează localizarea, cookie-urile, proxy geotargetat | | 403 / challenge / CAPTCHA | Reputația IP-ului, fingerprint headless, rată de request | Proxy-uri rezidențiale, browser stealth, rată mai mică | | Ruperea selectorilor | Schimbări DOM/clasă, teste A/B | Extragere semantică sau parsare API, dacă este disponibilă |
Scripturile personalizate nu sunt opțiunea „gratuită”. Ele mută costul de la abonamente la timpul dezvoltatorilor, facturile de proxy, costurile CAPTCHA și riscul de mentenanță. Dacă ai un inginer de scraping în echipă și ai nevoie de logică neobișnuită, aceasta este calea potrivită. Pentru toți ceilalți, în practică este cea mai scumpă opțiune.
Bună practică: scraping subpagini pentru date complete despre produsele Temu
Aceasta este cea mai importantă bună practică din acest articol — și aproape niciun alt ghid nu o acoperă.
O pagină de categorie sau de căutare Temu îți arată elementele de bază: titlu, thumbnail, preț, evaluare aproximativă. Dar câmpurile care fac cu adevărat un rând util — descrieri detaliate, liste de variante, număr complet de recenzii, estimări de livrare, numele vânzătorului, tabele de specificații — se află pe pagina de detalii a produsului (PDP).
Dacă faci scraping doar la pagina de listare, lucrezi cu un set de date parțial.
Fluxul în doi pași:
- Pasul 1 — Scrape page-ul de listare (PLP): Extrage numele produsului, prețul, thumbnail-ul și evaluarea dintr-o pagină Temu de căutare sau categorie.
- Pasul 2 — Îmbogățește prin scraping de subpagini: Vizitează PDP-ul fiecărui produs și adaugă coloane precum descriere completă, numărul de recenzii, opțiuni de variantă, timpul de livrare, informații despre vânzător.
Așa arată datele înainte și după:
| Câmp | Din PLP (Pasul 1) | Adăugat din PDP (Pasul 2) |
|---|---|---|
| Titlu produs | ✅ | — |
| Preț | ✅ | ✅ (verificat / %) |
| Thumbnail | ✅ | — |
| Evaluare stele | ✅ | ✅ (cu numărul de recenzii) |
| Descriere completă | ❌ | ✅ |
| Variante (mărimi, culori) | ❌ | ✅ |
| Nume vânzător | ❌ | ✅ |
| Estimare livrare | ❌ | ✅ |
| Specificații detaliate | ❌ | ✅ |
În Thunderbit, acest lucru se face dintr-un singur clic: după scrapingul inițial, apasă „Scrape Subpages”. AI-ul vizitează fiecare URL de produs și adaugă coloanele suplimentare — fără configurare extra, fără spider separat, fără mentenanță de selectori. Template-ul Temu Details din Octoparse și actorul Temu din Apify suportă, de asemenea, câmpuri la nivel de PDP, dar cu mai multă configurare și mentenanță. În Python, ar trebui să construiești un crawler PDP separat, să-i menții selectoarele și să gestionezi paginarea în interiorul paginilor de detalii — o investiție suplimentară semnificativă.
Bună practică: scraping Temu programat pentru monitorizarea continuă a prețurilor și stocurilor
Scrapingul unic este util pentru descoperirea produselor. Intelligence-ul competitiv cere observație repetată.
Prețurile se schimbă, produsele se epuizează, apar zilnic articole noi, iar adâncimea discounturilor se modifică odată cu promoțiile. Un scraping săptămânal sau zilnic creează un tabel istoric pe care echipa ta îl poate folosi efectiv.
Trei cazuri de utilizare care merită automatizate:
- Monitorizarea prețurilor: Urmărește săptămânal primele 50 de SKU-uri Temu ale unui competitor. Primește prețurile actualizate exportate automat în Google Sheets pentru comparație rapidă cu propriile prețuri.
- Monitorizarea stocurilor și disponibilității: Detectează când un produs în trend iese din stoc, apare o variantă nouă sau se schimbă estimările de livrare.
- Detectarea produselor/tendințelor noi: Programează zilnic scrapingul paginii Temu „New Arrivals” sau al unei pagini de categorie prioritară. Sortează după numărul de vândute sau după numărul de recenzii pentru a observa devreme produsele în creștere.
În Thunderbit, configurezi asta descriind intervalul în limbaj natural („în fiecare luni la 9:00”), introducând URL-urile țintă și apăsând „Schedule”. Scrapingul rulează în cloud și exportă în destinația aleasă. Deoarece AI-ul citește pagina proaspăt de fiecare dată, scrapingurile programate se adaptează automat la schimbările de layout ale Temu — nu trebuie să actualizezi selectoarele atunci când Temu redesenează un card de produs.
Alternativa: setezi un cron job, menții un script Python, configurezi rotația de proxy-uri, construiești un pipeline de output și repari selectoarele de fiecare dată când Temu își schimbă layout-ul. Pentru o echipă non-tehnică, asta nu este o opțiune. Pentru un dezvoltator, este un overhead continuu. Apify și Bright Data suportă, de asemenea, rulări programate, dar cu o configurare mai tehnică și praguri de cost mai mari.
Bună practică: fluxul end-to-end de date Temu (Scrape → Curățare → Export → Acțiune)
Cele mai multe ghiduri de scraping se opresc la „descarcă CSV”.
Dar utilizatorii business au nevoie de date în instrumentele cu care chiar lucrează — Google Sheets pentru colaborare, Airtable pentru baze de date de produse, Notion pentru dashboard-uri de echipă. Adevărata bună practică este un flux end-to-end:
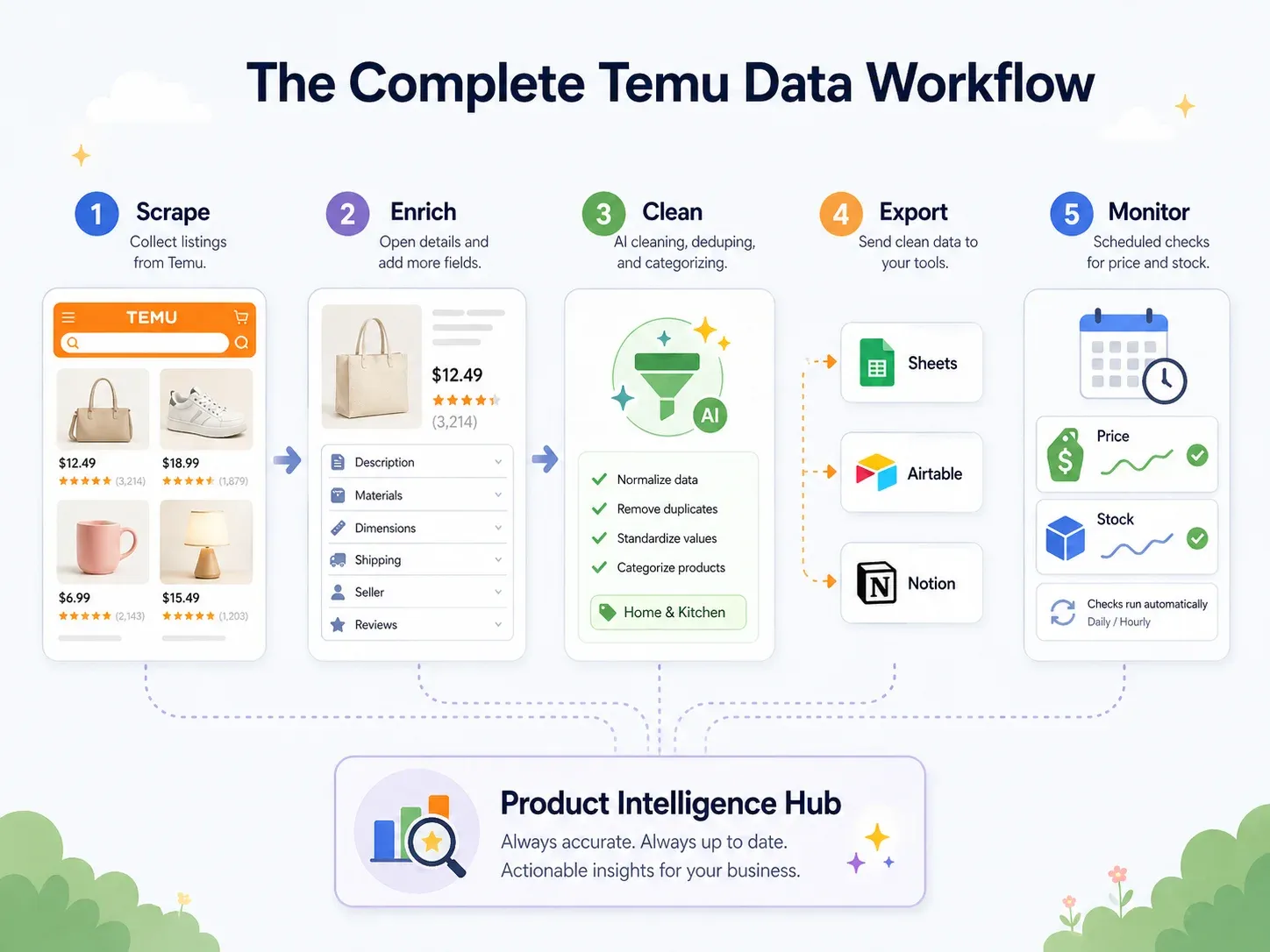
| Pas din flux | Ce se întâmplă | Capabilitatea Thunderbit |
|---|---|---|
| Scrape | Extrage date din paginile Temu | AI Suggest Fields → Scrape (2 clicuri) |
| Îmbogățește | Vizitează pagina de detalii a fiecărui produs | Scrape Subpages (1 clic) |
| Curăță și etichetează | Clasifică produse, normalizează prețuri, traduce titluri | Field AI Prompt — etichetează, formatează, traduce în timpul scrapingului |
| Exportă | Trimite datele către instrumentele business | Export gratuit către Excel, Google Sheets, Airtable, Notion; descarcă CSV/JSON |
| Monitorizează | Urmărește schimbările în timp | Scheduled Scraper cu intervale în limbaj natural |
Iată un exemplu concret: extragi 200 de produse de bucătărie Temu. În timpul scrapingului, un Field AI Prompt clasifică automat fiecare produs în „Utensils / Small Appliances / Storage / Cleaning / Decor.” Prețurile sunt normalizate la valori numerice în USD. Titlurile produselor chinezești sunt traduse în engleză. Datele se exportă direct într-un Airtable base cu imaginile produselor păstrate intacte (nu doar URL-uri — atașamente reale ale imaginilor, așa cum este descris în ). Un scraping programat reîmprospătează datele săptămânal.
Câteva instrucțiuni utile de Field AI Prompt pentru datele Temu:
- „Clasifică acest produs într-una dintre următoarele: Kitchen Utensils, Small Appliances, Storage, Cleaning, Decor, Other. Returnează doar categoria.”
- „Tradu titlul produsului într-o engleză concisă, păstrând numele de brand, cantitățile, mărimile și numerele de model.”
- „Normalizează prețul ca număr, fără simboluri de monedă.”
- „Etichetează cererea ca High, Medium sau Low pe baza evaluării, numărului de recenzii și numărului de vândute. Dacă datele lipsesc, returnează Unknown.”
Acest flux transformă un scraping brut într-o bază de date vie de intelligence despre produse — fără ca un dezvoltator să construiască un pipeline ETL separat.
Cele mai bune Temu scrapers comparate: tabel side-by-side
| Instrument | Nivel de competență | Timp de configurare | Gestionarea anti-bot | Scraping de subpagini | Programare | Opțiuni de export | Nivel de preț | Cel mai bun pentru |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Începător | Minute | Mod browser, mod cloud, detectare AI a câmpurilor | Da (Scrape Subpages) | Da (programări în limbaj natural) | Excel, CSV, Google Sheets, Airtable, Notion, JSON | Gratuit 6 pagini; plătit de la ~9–15$/lună pentru 500 credite | Echipe ecommerce non-tehnice, dropshipperi |
| Octoparse | Începător–Intermediar | 10–60 min | Extragere cloud, add-on-uri proxy/CAPTCHA | Da (fluxuri template) | Da (planuri plătite/cloud) | Excel, CSV, JSON, HTML, XML, bază de date, Google Sheets | Gratuit; ~75$/lună anual Standard; add-on-uri extra | Operatori care vor fluxuri vizuale + template Temu |
| ParseHub | Începător–Intermediar | 30–60 min | Randare dinamică, rotație IP plătită | Da (fluxuri de proiect) | Planuri plătite | CSV/JSON, Dropbox/S3 pe planurile plătite | De la 189$/lună | Echipe care construiesc proiecte vizuale pentru site-uri dinamice |
| ScraperAPI | Dezvoltator | Ore | Rotație proxy, randare JS, pool-uri premium | Codare personalizată | DataPipeline/scheduler | HTML/JSON/CSV | Trial 5K credite; Hobby 49$/lună; niveluri superioare disponibile | Dezvoltatori care construiesc pipeline-uri Temu personalizate |
| Apify | Intermediar | 10–30 min dacă actorul se potrivește | Logică browser/proxy specifică actorului | Depinde de actor | Da | JSON, CSV, Excel, API/datasets | Platformă gratuită; actori Temu ~4–5$/1K produse | Dezvoltatori/operatori care pot evalua calitatea actorilor |
| Bright Data | Avansat/Enterprise | Ore–zile | Proxy complet, CAPTCHA, deblocare, autoscaling | Personalizat prin scraper/API | Da | JSON, CSV, Parquet, S3, GCS, Azure, BigQuery, Snowflake | ~2.5$/1K înregistrări PAYG; contractat de la ~499$/lună | Echipe enterprise de date, extragere la volum mare |
| Oxylabs | Avansat | Ore | Gestionare JS, revendicări IP/CAPTCHA | Personalizat prin API | Da | JSON/output API | De la 49$/lună; trial până la 2K rezultate | Echipe de dezvoltare care au nevoie de acces Temu prin API |
| Custom Python (Playwright) | Avansat | 1–4 ore+; mentenanță continuă | Proxy-uri manuale, CAPTCHA, fingerprint-uri | Complet personalizat | Cron/queue/manual | Personalizat | Timp de dezvoltare + costuri proxy/CAPTCHA/hosting | Cazuri speciale, echipe cu ingineri de scraping |
Ce Temu scraper ar trebui să alegi? Recomandări rapide
- Dropshipper care are nevoie de cercetare rapidă de produse? Începe cu . Este cea mai rapidă cale de la „vreau date Temu” la „am un spreadsheet”. Dacă funcționează pe paginile tale țintă (și ar trebui pentru majoritatea paginilor publice de categorie și produs), ai terminat.
- Operator care vrea control vizual și template-uri reutilizabile? Octoparse are un template public Temu Details și un builder vizual de workflow. Așteaptă-te la 10–30 de minute de configurare și la ceva setări proxy/CAPTCHA.
- Dezvoltator care construiește un data pipeline sau un instrument intern? ScraperAPI sau Apify îți oferă fluxuri API/actori care se integrează cu cod și joburi programate. Evaluează cu atenție actorii Apify — verifică starea de mentenanță și ratingurile utilizatorilor.
- Echipă enterprise care are nevoie de date Temu la volum mare și livrare în warehouse? Bright Data este soluția de infrastructură. Scumpă, dar gestionează scala, deblocarea și livrarea către S3/BigQuery/Snowflake.
- Inginer de scraping care are nevoie de logică neobișnuită? Custom Playwright/Selenium îți oferă control total. Doar bugetează pentru mentenanță continuă, costuri de proxy și gestionare CAPTCHA.
Pentru majoritatea utilizatorilor business non-tehnici, aș recomanda să testezi mai întâi planul gratuit Thunderbit. Întrebarea imediată este mereu „pot obține rândurile de care am nevoie din această pagină Temu exactă?” — iar la asta poți răspunde în mai puțin de două minute, fără să cheltui nimic. Pentru dezvoltatori, rulează un benchmark cost-per-rând reușit pe Apify, ScraperAPI și un mic prototip Playwright înainte să aprobi bugetul.
Întrebări frecvente despre scraping Temu
Este legal să faci scraping Temu?
Depinde de jurisdicție, de datele pe care le colectezi, de metoda de acces și de modul în care folosești datele. restricționează explicit accesul automat, inclusiv crawling-ul, scraping-ul sau spidering-ul paginilor ori datelor. Instanțele din SUA au oferit unele precedente favorabile pentru accesarea datelor disponibile public (decizia hiQ v. LinkedIn a celui de-al Nouălea Circuit), dar au susținut și pretenții de încălcare a contractului și intruziune. Răspunsul scurt: scrapingul datelor de produse disponibile public pentru cercetare poate fi defensabil în unele contexte, dar contează termenii de serviciu, legislația privind confidențialitatea, drepturile de autor și modul în care folosești datele. Acesta nu este sfat juridic — consultă un avocat pentru utilizare comercială.
Cât de des își schimbă Temu layout-ul site-ului?
Nu a fost documentată nicio frecvență publică. Raportările comunității și ecosistemul de instrumente tratează Temu ca pe o țintă dinamică, actualizată frecvent. Pornește de la premisa că selectorii CSS se pot rupe oricând și preferă extragerea AI/semantică sau template-urile întreținute activ în locul selectorilor hardcodați.
Pot face scraping Temu fără să fiu blocat?
Pentru pagini publice limitate, cu ritm responsabil, da — mai ales folosind instrumente cu randare reală în browser, suport pentru sesiune și throttling. Niciun instrument nu trebuie tratat ca o garanție universală. Cloud scraping cu IP-uri rotative funcționează bine pentru paginile publice de catalog; browser scraping cu sesiunea ta curentă merge mai bine când regiunea, login-ul sau pop-up-urile afectează datele.
Ce date pot extrage de pe paginile de produs Temu?
Câmpurile publice comune includ titlul produsului, URL-ul, prețul curent, prețul inițial, procentul de discount, URL-urile imaginilor, evaluarea stelelor, numărul de recenzii, numărul de vândute, numele vânzătorului/magazinului, informații despre livrare, categoria, specificațiile produsului, variantele (culori, mărimi) și marcajul temporal al scrapingului. Câmpurile exacte disponibile depind de tipul paginii (listare vs. detalii) și de regiune.
Am nevoie de proxy-uri pentru a face scraping Temu?
Pentru o extragere manuală în mod browser la scară mică (câteva pagini odată), poate nu. Pentru colectare în cloud, programată sau la volum mare, proxy-urile sau infrastructura gestionată anti-block sunt de obicei necesare. Instrumente precum Thunderbit, Bright Data și ScraperAPI includ gestionarea proxy-urilor în platformele lor, ca să nu trebuiască să o configurezi separat.
Dacă vrei să aprofundezi subiecte conexe, consultă ghidurile noastre despre , , și . Poți urmări și tutoriale pe .
Află mai multe