
Ce limbaj de programare ar trebui să folosești pentru web scraping? Depinde de proiect — și am văzut 개발자 care au ajuns la nervi și au abandonat după ce au ales prost din start.
Piața de software pentru web scraping a ajuns la . Când alegi limbajul potrivit, livrezi mai repede și ai mai puțină mentenanță. Când îl alegi pe cel greșit, ajungi cu scrapers care se rup din senin și cu weekenduri arse pe debugging.
Construiesc de ani buni instrumente de automatizare. Mai jos sunt șapte limbaje pe care le-am folosit pentru scraping — cu fragmente de cod, compromisuri spuse pe șleau și momentele în care e mai bine să sari peste programare și să folosești în schimb.
Cum am ales cel mai bun limbaj pentru web scraping
În web scraping, limbajele nu sunt toate „la fel, doar cu altă sintaxă”. Am văzut proiecte care au prins viteză (și altele care s-au făcut praf) în funcție de câteva criterii esențiale:
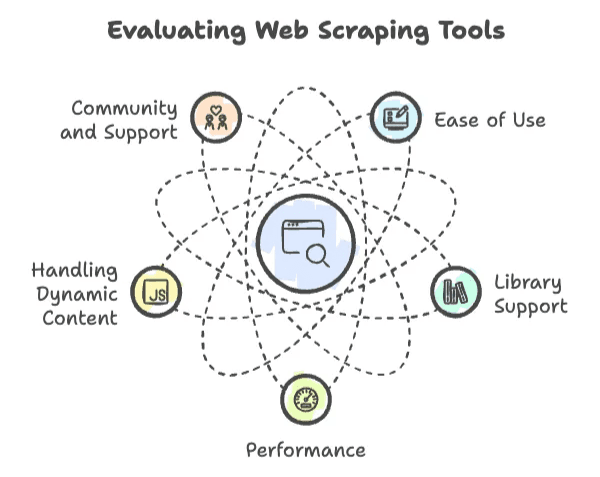
- Ușurință în utilizare: Cât de repede poți porni? Sintaxa e prietenoasă sau ai nevoie de „doctorat” doar ca să afișezi „Hello, World”?
- Suport de biblioteci: Există biblioteci solide pentru cereri HTTP, parsare HTML și conținut dinamic? Sau trebuie să reinventezi roata de la zero?
- Performanță: Poate duce scraping pentru milioane de pagini sau gâfâie după câteva sute?
- Gestionarea conținutului dinamic: Site-urile moderne iubesc JavaScript. Ține pasul limbajul ales?
- Comunitate și suport: Când te blochezi (și se va întâmpla), există o comunitate care să te scoată din groapă?
Pe baza acestor criterii — și a multor teste făcute noaptea târziu — iată cele șapte limbaje pe care le acoper:
- Python: alegerea standard atât pentru începători, cât și pentru profesioniști.
- JavaScript & Node.js: campionul conținutului dinamic.
- Ruby: sintaxă curată, scripturi rapide.
- PHP: simplitate pe server.
- C++: când ai nevoie de viteză brută.
- Java: pregătit pentru enterprise și scalare.
- Go (Golang): rapid și excelent pe concurență.
Iar dacă te gândești „Shuai, eu nu vreau să scriu cod deloc”, rămâi până la final pentru Thunderbit.
Web scraping în Python: puterea prietenoasă pentru începători
Începem cu preferatul publicului: Python. Dacă întrebi o sală plină de oameni de date „Care e cel mai bun limbaj pentru web scraping?”, o să auzi Python repetat ca un refren la un concert Taylor Swift.
De ce Python?
- Sintaxă ușor de învățat: Poți citi codul Python cu voce tare și aproape sună ca engleza.
- Ecosistem de biblioteci imbatabil: De la pentru parsare HTML, la pentru crawling la scară mare, pentru HTTP și pentru automatizare în browser — Python le are pe toate.
- Comunitate uriașă: Peste doar despre web scraping.
Exemplu de cod Python: extragerea titlului unei pagini
1import requests
2from bs4 import BeautifulSoup
3response = requests.get("<https://example.com>")
4soup = BeautifulSoup(response.text, 'html.parser')
5title = soup.title.string
6print(f"Page title: {title}")Puncte forte:
- Dezvoltare rapidă și prototipare.
- O mulțime de tutoriale și răspunsuri.
- Excelent pentru analiză de date — colectezi cu Python, analizezi cu pandas, vizualizezi cu matplotlib.
Limitări:
- Mai lent decât limbajele compilate pentru joburi uriașe.
- Pentru site-uri foarte dinamice poate deveni greoi (deși Selenium și Playwright ajută).
- Nu e ideal dacă vrei să scrapezi milioane de pagini „la viteză de fulger”.
Concluzia:
Dacă ești la început sau vrei să obții rezultate rapid, Python este cea mai bună alegere pentru web scraping — fără discuție. .
JavaScript & Node.js: scraping ușor pentru site-uri dinamice
Dacă Python e briceagul elvețian, JavaScript (și Node.js) e bormașina — mai ales când vrei să scrapezi site-uri moderne, încărcate cu JavaScript.
De ce JavaScript/Node.js?
- Nativ pentru conținut dinamic: Rulează în browser, deci „vede” ce vede utilizatorul — chiar dacă pagina e construită cu React, Angular sau Vue.
- Async din start: Node.js poate gestiona sute de cereri simultan.
- Familiar pentru web devs: Dacă ai construit un site, deja știi ceva JavaScript.
Biblioteci cheie:
- : automatizare Headless Chrome.
- : automatizare multi-browser.
- : parsare HTML în stil jQuery pentru Node.
Exemplu Node.js: extragerea titlului cu Puppeteer
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
6 const title = await page.title();
7 console.log(`Page title: ${title}`);
8 await browser.close();
9})();Puncte forte:
- Gestionează natural conținutul randat de JavaScript.
- Foarte bun pentru infinite scroll, pop-up-uri și site-uri interactive.
- Eficient pentru scraping concurent, la scară mare.
Limitări:
- Programarea async poate fi dificilă pentru începători.
- Browserele headless consumă multă memorie dacă rulezi prea multe simultan.
- Mai puține instrumente de analiză de date față de Python.
Când e JavaScript/Node.js cea mai bună alegere pentru web scraping?
Când site-ul țintă e dinamic sau vrei să automatizezi acțiuni în browser. .
Ruby: sintaxă elegantă pentru scripturi rapide de scraping
Ruby nu e doar pentru aplicații Rails și „poezie” în cod. E o opțiune bună pentru web scraping — mai ales dacă îți place ca programarea să curgă frumos, ca un vibe de 깔끔하게.
De ce Ruby?
- Sintaxă expresivă și ușor de citit: Poți scrie un scraper în Ruby aproape la fel de simplu ca o listă de cumpărături.
- Excelent pentru prototipare: Se scrie repede și se ajustează ușor.
- Biblioteci importante: pentru parsare, pentru automatizarea navigării.
Exemplu Ruby: extragerea titlului unei pagini
1require 'open-uri'
2require 'nokogiri'
3html = URI.open("<https://example.com>")
4doc = Nokogiri::HTML(html)
5title = doc.at('title').text
6puts "Page title: #{title}"Puncte forte:
- Foarte lizibil și concis.
- Potrivit pentru proiecte mici, scripturi „one-off” sau dacă folosești deja Ruby.
Limitări:
- Mai lent decât Python sau Node.js pentru volume mari.
- Mai puține biblioteci dedicate și suport comunitar mai redus pentru scraping.
- Nu e ideal pentru site-uri încărcate cu JavaScript (deși poți folosi Watir sau Selenium).
Când se potrivește cel mai bine:
Dacă ești Rubyist sau vrei să „arunci” rapid un script, Ruby e o plăcere. Pentru scraping masiv și dinamic, există opțiuni mai bune.
PHP: simplitate pe server pentru extragerea datelor web
PHP poate părea o amintire din web-ul de început, dar încă e foarte folosit — mai ales dacă vrei să colectezi date direct pe server, gen „merge și gata”, 딱.
De ce PHP?
- Rulează aproape oriunde: Majoritatea serverelor web au deja PHP.
- Integrare ușoară cu aplicații web: Colectezi și afișezi datele în același flux.
- Biblioteci cheie: pentru HTTP, pentru request-uri, pentru automatizare cu browser headless.
Exemplu PHP: extragerea titlului unei pagini
1<?php
2$ch = curl_init("<https://example.com>");
3curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
4$html = curl_exec($ch);
5curl_close($ch);
6$dom = new DOMDocument();
7@$dom->loadHTML($html);
8$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
9echo "Page title: $title\n";
10?>Puncte forte:
- Ușor de pus în producție pe servere web.
- Bun pentru scraping ca parte dintr-un flux web.
- Rapid pentru sarcini simple, server-side.
Limitări:
- Suport mai limitat pentru scraping avansat.
- Nu e gândit pentru concurență mare sau scraping la scară.
- Site-urile cu mult JavaScript sunt mai greu de gestionat (deși Panther ajută).
Când se potrivește cel mai bine:
Dacă stack-ul tău e deja PHP sau vrei să colectezi și să afișezi date pe site, PHP e o alegere pragmatică. .
C++: web scraping de înaltă performanță pentru proiecte mari
C++ e „mașina de forță” a limbajelor. Dacă ai nevoie de viteză brută și control total și nu te sperie munca manuală (și un pic de 고생), C++ poate livra.
De ce C++?
- Extrem de rapid: Depășește majoritatea limbajelor la sarcini CPU-bound.
- Control fin: Memorie, thread-uri, optimizări de performanță.
- Biblioteci cheie: pentru HTTP, pentru parsare.
Exemplu C++: extragerea titlului unei pagini
1#include <curl/curl.h>
2#include <iostream>
3#include <string>
4size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
5 std::string* html = static_cast<std::string*>(userp);
6 size_t totalSize = size * nmemb;
7 html->append(static_cast<char*>(contents), totalSize);
8 return totalSize;
9}
10int main() {
11 CURL* curl = curl_easy_init();
12 std::string html;
13 if(curl) {
14 curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
15 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
16 curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
17 CURLcode res = curl_easy_perform(curl);
18 curl_easy_cleanup(curl);
19 }
20 std::size_t startPos = html.find("<title>");
21 std::size_t endPos = html.find("</title>");
22 if(startPos != std::string::npos && endPos != std::string::npos) {
23 startPos += 7;
24 std::string title = html.substr(startPos, endPos - startPos);
25 std::cout << "Page title: " << title << std::endl;
26 } else {
27 std::cout << "Title tag not found" << std::endl;
28 }
29 return 0;
30}Puncte forte:
- Viteză greu de egalat pentru scraping masiv.
- Bun pentru integrarea scraping-ului în sisteme cu performanță ridicată.
Limitări:
- Curba de învățare abruptă (ia-ți cafeaua).
- Management manual al memoriei.
- Puține biblioteci „high-level”; nu e ideal pentru conținut dinamic.
Când se potrivește cel mai bine:
Când trebuie să scrapezi milioane de pagini sau performanța e critică. Altfel, riști să petreci mai mult timp depanând decât colectând date.
Java: soluții de web scraping pregătite pentru enterprise
Java e calul de bătaie din lumea enterprise. Dacă construiești ceva care trebuie să ruleze mult timp, să proceseze multă informație și să reziste în producție (진짜 튼튼하게), Java e o alegere sigură.
De ce Java?
- Robust și scalabil: Potrivit pentru proiecte mari, care rulează continuu.
- Tipare puternice și gestionare bună a erorilor: Mai puține surprize în producție.
- Biblioteci cheie: pentru parsare, pentru automatizare în browser, pentru HTTP.
Exemplu Java: extragerea titlului unei pagini
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3public class ScrapeTitle {
4 public static void main(String[] args) throws Exception {
5 Document doc = Jsoup.connect("<https://example.com>").get();
6 String title = doc.title();
7 System.out.println("Page title: " + title);
8 }
9}Puncte forte:
- Performanță bună și concurență.
- Excelent pentru codebase-uri mari, ușor de întreținut.
- Suport bun pentru conținut dinamic (prin Selenium sau HtmlUnit).
Limitări:
- Sintaxă mai „vorbăreață”; necesită mai mult setup decât limbajele de scripting.
- Prea mult pentru scripturi mici, ocazionale.
Când se potrivește cel mai bine:
Scraping la nivel enterprise sau când ai nevoie de fiabilitate și scalare pe termen lung.
Go (Golang): web scraping rapid și concurent
Go e relativ nou, dar deja se impune — mai ales pentru scraping rapid, cu multe cereri în paralel. Dacă vrei ceva „curat” și eficient, 느낌이 좋아.
De ce Go?
- Viteză de limbaj compilat: Aproape de C++.
- Concurență integrată: Goroutines fac scraping-ul paralel foarte simplu.
- Biblioteci cheie: pentru scraping, pentru parsare.
Exemplu Go: extragerea titlului unei pagini
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly"
5)
6func main() {
7 c := colly.NewCollector()
8 c.OnHTML("title", func(e *colly.HTMLElement) {
9 fmt.Println("Page title:", e.Text)
10 })
11 err := c.Visit("<https://example.com>")
12 if err != nil {
13 fmt.Println("Error:", err)
14 }
15}Puncte forte:
- Foarte rapid și eficient pentru scraping la scară.
- Ușor de livrat (un singur binar).
- Excelent pentru crawling concurent.
Limitări:
- Comunitate mai mică decât Python sau Node.js.
- Mai puține biblioteci „high-level”.
- Pentru site-uri cu mult JavaScript ai nevoie de setup suplimentar (Chromedp sau Selenium).
Când se potrivește cel mai bine:
Când ai nevoie de scraping la scară sau când Python nu mai face față ca performanță. .
Comparație între cele mai bune limbaje pentru web scraping
Să le punem cap la cap. Iată o comparație „side-by-side” ca să alegi mai ușor cel mai bun limbaj pentru web scraping în 2026:
| Limbaj/Instrument | Ușurință în utilizare | Performanță | Suport de biblioteci | Gestionarea conținutului dinamic | Cel mai bun scenariu de utilizare |
|---|---|---|---|---|---|
| Python | Foarte ridicată | Moderată | Excelent | Bună (Selenium/Playwright) | General, începători, analiză de date |
| JavaScript/Node.js | Medie | Ridicată | Puternic | Excelentă (nativ) | Site-uri dinamice, scraping async, web devs |
| Ruby | Ridicată | Moderată | Decent | Limitată (Watir) | Scripturi rapide, prototipare |
| PHP | Medie | Moderată | Acceptabil | Limitată (Panther) | Server-side, integrare în aplicații web |
| C++ | Scăzută | Foarte ridicată | Limitat | Foarte limitată | Critic pe performanță, scară masivă |
| Java | Medie | Ridicată | Bun | Bună (Selenium/HtmlUnit) | Enterprise, servicii long-running |
| Go (Golang) | Medie | Foarte ridicată | În creștere | Moderată (Chromedp) | Scraping rapid, concurent |
Când să sari peste cod: Thunderbit ca soluție no-code pentru web scraping
Să fim sinceri: uneori vrei doar datele — fără cod, fără debugging și fără durerile de cap de tipul „de ce nu merge selectorul ăsta?”. Aici intră în scenă .
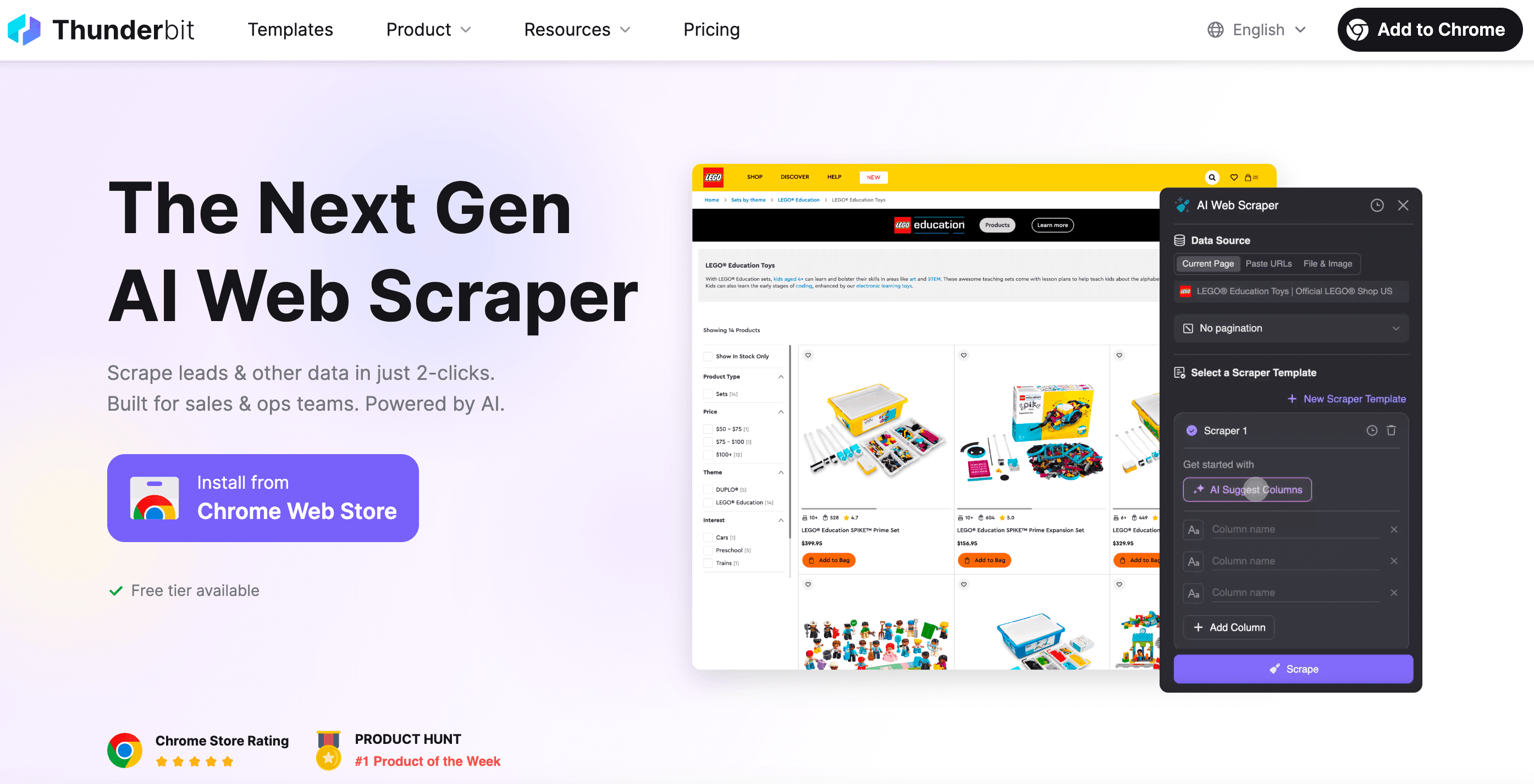
Ca co-fondator Thunderbit, mi-am dorit să construiesc un instrument care face web scraping-ul la fel de simplu ca o comandă de mâncare. Iată ce diferențiază Thunderbit:
- Setare în 2 click-uri: Apeși „AI Suggest Fields” și „Scrape”. Fără bătăi de cap cu request-uri HTTP, proxy-uri sau trucuri anti-bot.
- Șabloane inteligente: Un singur scraper template se poate adapta la mai multe layout-uri de pagină. Nu trebuie să rescrii scraper-ul de fiecare dată când se schimbă site-ul.
- Scraping în browser și în cloud: Alegi între scraping în browser (ideal pentru site-uri cu login) sau în cloud (foarte rapid pentru date publice).
- Gestionează conținut dinamic: AI-ul Thunderbit controlează un browser real — deci poate lucra cu infinite scroll, pop-up-uri, autentificări și altele.
- Export oriunde: Descarci în Excel, Google Sheets, Airtable, Notion sau copiezi direct în clipboard.
- Fără mentenanță: Dacă se schimbă site-ul, rulezi din nou sugestia AI. Gata cu sesiunile de debugging la miezul nopții.
- Programare și automatizare: Rulezi scrapers după un program — fără cron jobs, fără configurare de server.
- Extractoare specializate: Ai nevoie de emailuri, numere de telefon sau imagini? Thunderbit are extractoare „one-click” și pentru asta.
Și partea cea mai bună? Nu trebuie să știi nici măcar o linie de cod. Thunderbit e făcut pentru utilizatori business, marketeri, echipe de vânzări, profesioniști din imobiliare — oricine are nevoie de date, rapid.
Vrei să vezi Thunderbit la lucru? sau intră pe pentru demo-uri.
Concluzie: cum alegi cel mai bun limbaj pentru web scraping în 2026
Web scraping-ul în 2026 e mai accesibil — și mai puternic — ca oricând. Iată ce am învățat după ani de automatizări „în tranșee”:
- Python rămâne cea mai bună opțiune dacă vrei să începi repede și să ai multe resurse la îndemână.
- JavaScript/Node.js e greu de bătut pentru site-uri dinamice, pline de JavaScript.
- Ruby și PHP sunt excelente pentru scripturi rapide și integrare web, mai ales dacă le folosești deja.
- C++ și Go sunt aliații tăi când ai nevoie de viteză și scalare.
- Java e alegerea clasică pentru proiecte enterprise, pe termen lung.
- Iar dacă vrei să eviți complet programarea? e arma ta secretă.
Înainte să te apuci, întreabă-te:
- Cât de mare e proiectul?
- Trebuie să gestionez conținut dinamic?
- Cât de confortabil sunt tehnic?
- Vreau să construiesc eu soluția sau doar să obțin datele?
Testează un snippet de mai sus sau încearcă Thunderbit pentru următorul proiect. Iar dacă vrei să aprofundezi, intră pe pentru mai multe ghiduri, tips & tricks și povești reale din scraping.
Spor la scraping — și fie ca datele tale să fie mereu curate, structurate și la un click distanță.
P.S. Dacă te trezești vreodată blocat într-o vizuină de iepure de web scraping la 2 dimineața, amintește-ți: există mereu Thunderbit. Sau cafea. Sau ambele.
Întrebări frecvente
1. Care este cel mai bun limbaj de programare pentru web scraping în 2026?
Python rămâne prima alegere datorită sintaxei ușor de citit, bibliotecilor puternice (precum BeautifulSoup, Scrapy și Selenium) și comunității mari. E potrivit atât pentru începători, cât și pentru profesioniști, mai ales când combini scraping-ul cu analiza de date.
2. Ce limbaj e cel mai bun pentru site-uri cu mult JavaScript?
JavaScript (Node.js) este alegerea principală pentru site-uri dinamice. Instrumente precum Puppeteer și Playwright îți oferă control complet asupra browserului, astfel încât poți interacționa cu conținut încărcat prin React, Vue sau Angular.
3. Există o opțiune no-code pentru web scraping?
Da — este un AI Web Scraper no-code care se ocupă de tot, de la conținut dinamic până la programare. Apeși „AI Suggest Fields” și începi să colectezi. E ideal pentru echipe de vânzări, marketing sau operațiuni care au nevoie rapid de date structurate.
Află mai multe: