Linkuri moarte. Pagini orfane. O pagină de „test” din 2019 pe care Google a reușit, cumva, s-o bage la index. Dacă ai în grijă un site, știi prea bine cât de iritant poate deveni.
Un crawler bun îți prinde toate problemele astea din zbor — și îți „desenează” site-ul cap-coadă, ca să poți repara lucrurile pe bune. Doar că mulți amestecă „web crawler” cu „web scraper”. Nu sunt același lucru.
Am pus la treabă 10 crawlere gratuite pe site-uri reale. Unele sunt beton pentru audituri SEO. Altele sunt mai potrivite pentru extragere de date. Mai jos ai ce a mers — și ce n-a mers.
Ce este un crawler de site? Bazele pe înțelesul tuturor
Să fie clar de la început: un crawler de site nu e același lucru cu un web scraper. Da, lumea le folosește ca și cum ar fi sinonime, dar în realitate sunt două unelte diferite. Imaginează-ți crawler-ul ca pe „cartograful” site-ului tău: intră peste tot, urmărește fiecare link și îți construiește o hartă cu toate paginile. Misiunea lui e descoperirea: găsește URL-uri, înțelege arhitectura site-ului și indexează conținutul. Fix asta fac motoarele de căutare (gen Google) cu boții lor și tot asta folosesc și tool-urile SEO ca să-ți verifice sănătatea site-ului ().
Un web scraper, în schimb, e „minerul” de date. Nu-l interesează să aibă harta completă — el vrea doar „aurul”: prețuri, nume de companii, recenzii, emailuri, orice îți trebuie. Scraper-ele extrag câmpuri specifice din paginile pe care crawler-ele le descoperă ().
O analogie rapidă:
- Crawler: omul care ia la pas fiecare culoar dintr-un supermarket și face inventarul tuturor produselor.
- Scraper: omul care se duce direct la raftul cu cafea și notează prețul fiecărui sortiment bio.
De ce contează diferența? Pentru că dacă vrei doar să găsești toate paginile de pe site (de exemplu, pentru un audit SEO), ai nevoie de un crawler. Dacă vrei să extragi toate prețurile produselor de pe site-ul unui competitor, ai nevoie de un scraper — sau, ideal, de un instrument care le face pe ambele.
De ce să folosești un web crawler online? Beneficii cheie pentru business
De ce să-ți bați capul cu un crawler? Pentru că web-ul nu se micșorează, dimpotrivă. În fapt, peste ca să-și optimizeze site-urile, iar unele instrumente SEO ajung să parcurgă .
Iată ce poți scoate dintr-un crawler:
- Audituri SEO: găsești linkuri rupte, titluri lipsă, conținut duplicat, pagini orfane și multe altele ().
- Verificare linkuri & QA: prinzi erori 404 și bucle de redirect înainte să le vadă utilizatorii ().
- Generare sitemap: îți face automat sitemap-uri XML pentru motoare de căutare și planificare ().
- Inventar de conținut: primești lista completă a paginilor, ierarhia lor și metadatele.
- Conformitate & accesibilitate: verifici fiecare pagină pentru WCAG, SEO și conformitate legală ().
- Performanță & securitate: semnalezi pagini lente, imagini prea mari sau probleme de securitate ().
- Date pentru AI & analiză: trimiți datele crawl-uite către tool-uri de analiză sau AI ().
Un tabel rapid care leagă cazurile de utilizare de rolurile din business:
| Caz de utilizare | Ideal pentru | Beneficiu / rezultat |
|---|---|---|
| SEO & audit de site | Marketing, SEO, antreprenori | Identifici probleme tehnice, optimizezi structura, crești în clasamente |
| Inventar de conținut & QA | Content managers, webmasters | Auditezi sau migrezi conținut, prinzi linkuri/imagini stricate |
| Generare lead-uri (scraping) | Vânzări, business development | Automatizezi prospectarea, alimentezi CRM-ul cu lead-uri noi |
| Inteligență competitivă | E-commerce, product managers | Monitorizezi prețuri, produse noi, schimbări de stoc |
| Sitemap & clonare structură | Dezvoltatori, DevOps, consultanți | Clonezi structura pentru redesign sau backup |
| Agregare de conținut | Cercetători, media, analiști | Colectezi date din mai multe site-uri pentru analiză sau trenduri |
| Cercetare de piață | Analiști, echipe de training AI | Strângi seturi mari de date pentru analiză sau antrenarea modelelor AI |
()
Cum am ales cele mai bune instrumente gratuite de crawling pentru site-uri
Am stat până târziu în noapte (și am băut mai multă cafea decât mi-ar plăcea să recunosc) testând crawlere, răsfoind documentație și rulând scanări „de probă”. Astea au fost criteriile mele:
- Capabilități tehnice: poate duce site-uri moderne (JavaScript, autentificare, conținut dinamic)?
- Ușurință în utilizare: e ok pentru non-tehnici sau îți cere vrăjitorie în linia de comandă?
- Limitările planului gratuit: e chiar gratuit sau doar o degustare?
- Accesibilitate online: e tool cloud, aplicație desktop sau bibliotecă de cod?
- Funcții speciale: are ceva aparte — gen extragere cu AI, sitemap-uri vizuale sau crawling bazat pe evenimente?
Am testat fiecare instrument, am verificat feedback-ul utilizatorilor și am comparat funcțiile la milimetru. Dacă un tool m-a făcut să-mi vină să arunc laptopul pe geam, n-a prins loc pe listă.
Tabel comparativ rapid: cele mai bune 10 crawlere gratuite dintr-o privire
| Instrument & tip | Funcții principale | Cel mai bun caz de utilizare | Cerințe tehnice | Detalii plan gratuit |
|---|---|---|---|---|
| BrightData (Cloud/API) | Crawling enterprise, proxy-uri, randare JS, rezolvare CAPTCHA | Colectare de date la scară mare | Ajută ceva experiență tehnică | Trial gratuit: 3 scrapers, 100 înregistrări fiecare (aprox. 300 total) |
| Crawlbase (Cloud/API) | Crawling prin API, anti-bot, proxy-uri, randare JS | Devs care au nevoie de infrastructură backend | Integrare API | Gratuit: ~5.000 apeluri API timp de 7 zile, apoi 1.000/lună |
| ScraperAPI (Cloud/API) | Rotire proxy, randare JS, crawling async, endpoint-uri predefinite | Devs, monitorizare prețuri, date SEO | Setup minim | Gratuit: 5.000 apeluri API timp de 7 zile, apoi 1.000/lună |
| Diffbot Crawlbot (Cloud) | Crawling + extragere cu AI, knowledge graph, randare JS | Date structurate la scară, AI/ML | Integrare API | Gratuit: 10.000 credite/lună (aprox. 10k pagini) |
| Screaming Frog (Desktop) | Audit SEO, analiză link/meta, sitemap, extragere custom | Audituri SEO, administratori de site | Aplicație desktop, GUI | Gratuit: 500 URL-uri per crawl, doar funcțiile de bază |
| SiteOne Crawler (Desktop) | SEO, performanță, accesibilitate, securitate, export offline, Markdown | Devs, QA, migrare, documentație | Desktop/CLI, GUI | Gratuit & open-source, 1.000 URL-uri în raportul GUI (configurabil) |
| Crawljax (Java, OpenSrc) | Crawling bazat pe evenimente pentru site-uri cu mult JS, export static | Devs, QA pentru aplicații web dinamice | Java, CLI/config | Gratuit & open-source, fără limite |
| Apache Nutch (Java, OpenSrc) | Distribuit, bazat pe plugin-uri, integrare Hadoop, căutare custom | Motoare de căutare proprii, crawling la scară mare | Java, linie de comandă | Gratuit & open-source, doar costuri de infrastructură |
| YaCy (Java, OpenSrc) | Crawling & căutare peer-to-peer, confidențialitate, indexare web/intranet | Căutare privată, descentralizare | Java, interfață în browser | Gratuit & open-source, fără limite |
| PowerMapper (Desktop/SaaS) | Sitemap-uri vizuale, accesibilitate, QA, compatibilitate browser | Agenții, QA, cartografiere vizuală | GUI, ușor | Trial: 30 zile, 100 pagini (desktop) sau 10 pagini (online) per scanare |
BrightData: crawler cloud de nivel enterprise

BrightData e „artileria grea” când vine vorba de crawling. E o platformă cloud cu o rețea masivă de proxy-uri, randare JavaScript, rezolvare CAPTCHA și un IDE pentru crawl-uri custom. Dacă faci colectare de date la scară mare — de exemplu, urmărești prețuri pe sute de site-uri e-commerce — infrastructura BrightData e greu de bătut ().
Puncte forte:
- Se descurcă excelent cu site-uri „încuiate”, cu protecții anti-bot
- Scalabil pentru nevoi enterprise
- Template-uri gata făcute pentru site-uri populare
Limitări:
- Nu are plan gratuit permanent (doar trial: 3 scrapers, 100 înregistrări fiecare)
- Poate fi overkill pentru audituri simple
- Curba de învățare e mai abruptă pentru non-tehnici
Dacă ai nevoie de crawling la scară mare, BrightData e ca și cum ai închiria o mașină de Formula 1. Doar să nu te aștepți să fie gratis după „test drive” ().
Crawlbase: web crawler gratuit prin API, pentru dezvoltatori

Crawlbase (fost ProxyCrawl) e gândit pentru crawling programatic. Lovești API-ul cu un URL și primești HTML-ul — iar în spate el se ocupă de proxy-uri, geotargetare și CAPTCHA ().
Puncte forte:
- Rată mare de succes (99%+)
- Bun pentru site-uri încărcate cu JavaScript
- Excelent pentru integrare în aplicații sau fluxuri interne
Limitări:
- Cere integrare API sau SDK
- Plan gratuit: ~5.000 apeluri API timp de 7 zile, apoi 1.000/lună
Dacă ești developer și vrei crawling (și poate scraping) la scară, fără să-ți bați capul cu administrarea proxy-urilor, Crawlbase e o alegere solidă ().
ScraperAPI: crawling dinamic, fără bătăi de cap

ScraperAPI e genul de API „dă-mi pagina și atât”. Îi dai un URL, iar el gestionează proxy-uri, browsere headless și măsuri anti-bot, apoi îți livrează HTML-ul (sau date structurate pentru anumite site-uri). E foarte bun pentru pagini dinamice și are un free tier destul de generos ().
Puncte forte:
- Super simplu pentru dezvoltatori (un singur apel API)
- Se ocupă de CAPTCHA, blocări IP, JavaScript
- Gratuit: 5.000 apeluri API timp de 7 zile, apoi 1.000/lună
Limitări:
- Nu-ți dă rapoarte vizuale de crawling
- Dacă vrei să urmărești linkuri, trebuie să-ți scrii singur logica de crawl
Dacă vrei să bagi crawling în cod în câteva minute, ScraperAPI e alegerea naturală.
Diffbot Crawlbot: descoperire automată a structurii site-ului

Diffbot Crawlbot intră în zona „smart”. Nu doar parcurge pagini — folosește AI ca să clasifice paginile și să extragă date structurate (articole, produse, evenimente etc.) în JSON. E ca un intern-robot care chiar pricepe ce citește ().
Puncte forte:
- Extragere cu AI, nu doar crawling
- Se descurcă cu JavaScript și conținut dinamic
- Gratuit: 10.000 credite/lună (aprox. 10k pagini)
Limitări:
- Mai mult pentru dezvoltatori (integrare API)
- Nu e un tool SEO vizual — e mai degrabă pentru proiecte de date
Dacă ai nevoie de date structurate la scară, mai ales pentru AI sau analytics, Diffbot e foarte puternic.
Screaming Frog: crawler SEO desktop gratuit

Screaming Frog e clasicul crawler desktop pentru audituri SEO. În varianta gratuită, scanează până la 500 de URL-uri per rulare și îți dă cam tot: linkuri rupte, meta tag-uri, conținut duplicat, sitemap-uri și altele ().
Puncte forte:
- Rapid, complet și foarte respectat în SEO
- Fără cod — bagi URL-ul și îi dai drumul
- Gratuit până la 500 URL-uri per crawl
Limitări:
- Doar desktop (nu există variantă cloud)
- Funcțiile avansate (randare JS, programare scanări) cer licență plătită
Dacă iei SEO în serios, Screaming Frog e aproape „must-have” — doar că nu te aștepta să-ți scaneze gratis un site cu 10.000 de pagini.
SiteOne Crawler: export static și documentație

SiteOne Crawler e briceagul elvețian pentru audituri tehnice. E open-source, cross-platform și poate să parcurgă, să auditeze și chiar să exporte site-ul în Markdown pentru documentație sau utilizare offline ().
Puncte forte:
- Acoperă SEO, performanță, accesibilitate, securitate
- Exportă site-uri pentru arhivare sau migrare
- Gratuit & open-source, fără limite de utilizare
Limitări:
- Mai tehnic decât unele tool-uri strict GUI
- Raportul GUI e limitat implicit la 1.000 URL-uri (configurabil)
Dacă ești developer, QA sau consultant și vrei vizibilitate serioasă (și îți place open-source), SiteOne e o mică bijuterie.
Crawljax: crawler Java open-source pentru pagini dinamice
Crawljax e un specialist: e făcut pentru aplicații web moderne, pline de JavaScript, simulând interacțiuni reale (clickuri, completări de formulare etc.). E bazat pe evenimente și poate chiar să genereze o versiune statică a unui site dinamic ().
Puncte forte:
- Excelent pentru SPA-uri și site-uri cu mult AJAX
- Open-source și extensibil
- Fără limite de utilizare
Limitări:
- Cere Java și ceva programare/configurare
- Nu e pentru utilizatori non-tehnici
Dacă trebuie să parcurgi o aplicație React sau Angular ca un utilizator real, Crawljax e omul (sau unealta) potrivită.
Apache Nutch: crawler distribuit, scalabil

Apache Nutch e „veteranul” crawler-elor open-source. E construit pentru crawling masiv, distribuit — genul de setup de care ai nevoie dacă vrei să-ți faci propriul motor de căutare sau să indexezi milioane de pagini ().
Puncte forte:
- Poate scala până la miliarde de pagini cu Hadoop
- Foarte configurabil și extensibil
- Gratuit & open-source
Limitări:
- Curba de învățare e abruptă (Java, linie de comandă, configurații)
- Nu e pentru site-uri mici sau utilizare ocazională
Dacă vrei crawling la scară mare și nu te sperie terminalul, Nutch e unealta potrivită.
YaCy: crawler și motor de căutare peer-to-peer
YaCy e un crawler și motor de căutare descentralizat, altfel decât restul. Fiecare instanță parcurge și indexează site-uri, iar dacă te conectezi la rețeaua peer-to-peer, poți partaja indexurile cu alții ().
Puncte forte:
- Focus pe confidențialitate, fără server central
- Bun pentru căutare privată sau intranet
- Gratuit & open-source
Limitări:
- Calitatea rezultatelor depinde de acoperirea rețelei
- Cere puțină configurare (Java, UI în browser)
Dacă te atrage descentralizarea sau vrei propriul motor de căutare, YaCy e o opțiune chiar interesantă.
PowerMapper: generator de sitemap vizual pentru UX și QA

PowerMapper pune accent pe vizualizarea structurii site-ului. Îți parcurge site-ul și îți generează sitemap-uri interactive, plus verifică accesibilitatea, compatibilitatea cu browserele și elemente SEO de bază ().
Puncte forte:
- Sitemap-urile vizuale sunt excelente pentru agenții și designeri
- Verifică accesibilitatea și conformitatea
- Interfață ușoară, fără cerințe tehnice
Limitări:
- Doar trial (30 zile, 100 pagini desktop / 10 pagini online per scanare)
- Versiunea completă e plătită
Dacă trebuie să prezinți o hartă a site-ului clienților sau să verifici conformitatea, PowerMapper e foarte practic.
Cum alegi crawler-ul gratuit potrivit pentru nevoile tale
Cu atâtea opțiuni, cum alegi fără să pierzi vremea? Uite ghidul meu rapid:
- Pentru audituri SEO: Screaming Frog (site-uri mici), PowerMapper (vizual), SiteOne (audituri profunde)
- Pentru aplicații web dinamice: Crawljax
- Pentru crawling la scară mare sau căutare custom: Apache Nutch, YaCy
- Pentru dezvoltatori care au nevoie de API: Crawlbase, ScraperAPI, Diffbot
- Pentru documentație sau arhivare: SiteOne Crawler
- Pentru enterprise, cu trial: BrightData, Diffbot
Factori importanți de luat în calcul:
- Scalabilitate: cât de mare e site-ul sau jobul de crawling web?
- Ușurință în utilizare: ești ok cu cod sau vrei „point-and-click”?
- Export de date: ai nevoie de CSV, JSON sau integrare cu alte tool-uri?
- Suport: există comunitate sau documentație bună când te blochezi?
Când crawling-ul se întâlnește cu scraping-ul: de ce Thunderbit e o alegere mai inteligentă
Realitatea e simplă: cei mai mulți oameni nu fac crawling web doar ca să obțină hărți frumoase. De cele mai multe ori, ținta finală e să ajungi la date structurate — fie că vorbim de liste de produse, informații de contact sau inventare de conținut. Aici intră în scenă .
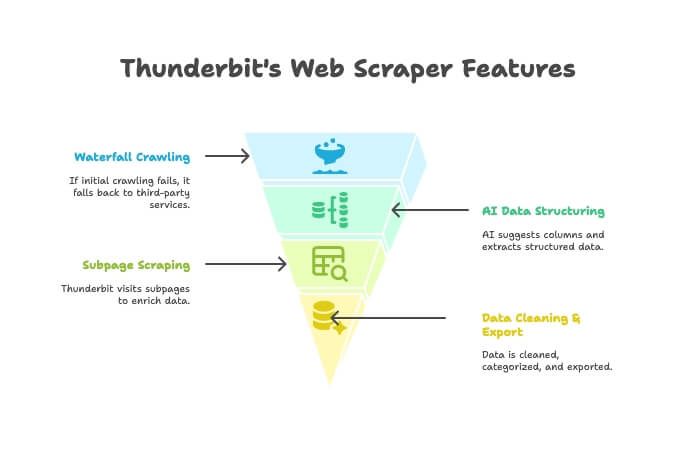
Thunderbit nu e doar crawler sau doar scraper — e o extensie Chrome cu AI care le combină pe ambele. Practic, funcționează așa:
- AI Crawler: Thunderbit explorează site-ul, ca un crawler.
- Waterfall Crawling: dacă motorul Thunderbit nu poate accesa pagina (de exemplu, din cauza unor protecții anti-bot), trece automat la servicii terțe de crawling — fără setări manuale.
- Structurare de date cu AI: după ce obține HTML-ul, AI-ul Thunderbit îți propune coloanele potrivite și extrage date structurate (nume, prețuri, emailuri etc.) fără să scrii selectori.
- Scraping pe subpagini: ai nevoie de detalii din fiecare pagină de produs? Thunderbit poate vizita automat fiecare subpagină și îți îmbogățește tabelul.
- Curățare & export: poate rezuma, categoriza, traduce și exporta datele în Excel, Google Sheets, Airtable sau Notion dintr-un click.
- Fără cod: dacă știi să folosești un browser, poți folosi Thunderbit. Fără programare, fără proxy-uri, fără dureri de cap.
Când merită Thunderbit în locul unui crawler tradițional?
- Când vrei un spreadsheet curat și utilizabil — nu doar o listă de URL-uri.
- Când vrei să automatizezi tot fluxul (crawl, extragere, curățare, export) într-un singur loc.
- Când îți prețuiești timpul și nervii.
Poți și să vezi de ce tot mai mulți utilizatori business fac trecerea.
Concluzie: cum să profiți la maximum de crawlerele gratuite pentru site-uri
Crawler-ele de site au evoluat enorm. Indiferent dacă ești marketer, developer sau doar vrei să-ți ții site-ul „în formă”, există un instrument gratuit (sau măcar gratuit de încercat) pentru tine. De la platforme enterprise precum BrightData și Diffbot, la „comori” open-source ca SiteOne și Crawljax, până la tool-uri vizuale precum PowerMapper, opțiunile sunt mai diverse ca oricând.
Dar dacă vrei o cale mai smart și mai integrată de la „am nevoie de datele astea” la „uite spreadsheet-ul”, merită să încerci Thunderbit. E gândit pentru utilizatori business care vor rezultate, nu doar rapoarte.
Gata să începi crawling-ul? Instalează un instrument web crawler, rulează o scanare și vezi ce ți-a scăpat. Iar dacă vrei să treci de la crawling la date utilizabile în două clickuri, .
Pentru mai multe analize și ghiduri practice, intră pe .
Întrebări frecvente
Care e diferența dintre un crawler de site și un web scraper?
Un crawler descoperă și cartografiază toate paginile unui site (ca un cuprins). Un scraper extrage câmpuri specifice (precum prețuri, emailuri sau recenzii) din acele pagini. Crawler-ele găsesc, scraper-ele extrag ().
Care crawler gratuit e cel mai potrivit pentru utilizatori non-tehnici?
Pentru site-uri mici și audituri SEO, Screaming Frog e ușor de folosit. Pentru cartografiere vizuală, PowerMapper e foarte bun (în perioada de trial). Thunderbit e cel mai simplu dacă obiectivul tău este să obții date structurate și vrei o experiență fără cod, direct în browser.
Există site-uri care blochează crawlerele?
Da — unele site-uri folosesc fișiere robots.txt sau măsuri anti-bot (CAPTCHA, blocări IP) ca să oprească crawlerele. Instrumente precum ScraperAPI, Crawlbase și Thunderbit (cu waterfall crawling) pot trece adesea peste aceste bariere, dar fă crawling responsabil și respectă regulile site-ului ().
Crawlerele gratuite au limite de pagini sau funcții?
De cele mai multe ori, da. De exemplu, versiunea gratuită Screaming Frog e limitată la 500 URL-uri per crawl; trial-ul PowerMapper la 100 pagini. Tool-urile bazate pe API au de obicei limite lunare de credite. Instrumentele open-source precum SiteOne sau Crawljax nu au, în general, limite „hard”, dar ești limitat de hardware.
Este legal și conform cu confidențialitatea să folosești un web crawler?
În general, crawling web pe pagini publice este legal, însă verifică întotdeauna termenii de utilizare ai site-ului și robots.txt. Nu parcurge date private sau protejate prin parolă fără permisiune și ține cont de legislația privind confidențialitatea dacă extragi date personale ().