În 2015, „scraping” însemna să rogi un developer să-ți scrie un script în Python sau să-ți sacrifici weekendul ca să înveți XPath. În 2026, scrii „ia toate numele produselor și prețurile” și un AI face restul — genul ăla de magie pe care coreenii ar numi-o aproape 신세계 (o „lume nouă”).
Schimbarea asta a venit rapid. Peste se bazează acum pe web scraping. Piața a depășit și are toate șansele să se dubleze până în 2030.
Motorul principal? crawler web cu AI. Se adaptează când se schimbă layout-ul. Înțeleg conținutul paginii, nu doar tag-urile HTML. Și funcționează și pentru oameni care n-au scris niciodată o linie de cod — adică fix vibe-ul de 초보도 가능 („merge și pentru începători”).
Am petrecut luni întregi testând 15 astfel de instrumente. Iată concluziile mele — inclusiv de ce Thunderbit (da, compania pe care am cofondat-o) a ajuns pe primul loc.
De ce AI schimbă radical scraping-ul paginilor web: noua eră a instrumentelor Web Scraper
Să fim sinceri: web scraping-ul tradițional nu a fost gândit pentru utilizatorul obișnuit din business. Totul era despre cod, selectori și speranța că scriptul nu se va rupe la următoarea modificare de design a site-ului. AI-ul și LLM-urile au schimbat complet regulile jocului — 판이 바뀌었다 (s-a schimbat „tabla de joc”).
Iată cum:
- Instrucțiuni în limbaj natural: În loc să te lupți cu codul, îi spui AI-ului ce vrei. Instrumente precum interpretează instrucțiunile tale în engleză simplă și configurează extragerea pentru tine ().
- Învățare adaptivă: Scraper-ele cu AI se pot ale site-urilor, reducând bătăile de cap legate de mentenanță — 알아서 척척 (se descurcă singure, rapid).
- Gestionarea conținutului dinamic: Site-urile moderne iubesc JavaScript și infinite scroll. Instrumentele cu AI interacționează cu aceste elemente și capturează date pe care scraper-ele clasice le-ar rata.
- Ieșire structurată prin parsare AI: Scraper-ele bazate pe LLM chiar și livrează date curate, structurate.
- Evitarea automată a anti-bot: Scraper-ele cu AI pot și folosesc proxy/headless browsers pentru a evita blocările de IP.
- Fluxuri de lucru integrate pentru date: Cele mai bune instrumente nu doar extrag date — le și trimit acolo unde ai nevoie, cu export dintr-un click către Google Sheets, Airtable, Notion și altele ().
Rezultatul? Web scraping-ul a devenit o experiență de tip point-and-click (sau chiar ca un chat), ceea ce le permite echipelor de vânzări, marketing și operațiuni — nu doar developerilor — să folosească direct datele de pe web. Practic, crawling web a devenit 대화하듯이 (ca o conversație).
15 crawlere web cu AI care merită atenția ta în 2026
Hai să trecem prin cele mai bune 15 crawlere web cu AI, începând cu Thunderbit. Îți spun pe scurt funcțiile esențiale, cui i se potrivesc, prețurile și ce le diferențiază. Și da, voi fi sincer despre unde excelează fiecare (și unde poate nu) — 솔직히 말해서.
1. Thunderbit: AI Web Scraper pentru oricine
Evident că sunt puțin subiectiv, dar Thunderbit este AI Web Scraper-ul pe care mi-aș fi dorit să-l am acum câțiva ani. De ce e #1 pe lista asta:
- Extragere în limbaj natural: „Vorbești” cu Thunderbit. Descrii datele de care ai nevoie — „extrage toate numele produselor și prețurile de pe pagina asta” — iar AI-ul se ocupă de restul (). Fără cod, fără selectori, fără stres — 노코드로 끝 (gata fără cod).
- Crawling pe subpagini și pe mai multe niveluri: Thunderbit poate . De exemplu: extragi o listă de produse, apoi intri în fiecare produs pentru detalii — totul dintr-o singură rulare.
- Ieșire structurată instant: AI-ul , propune câmpuri relevante, normalizează formate și poate chiar rezuma sau categoriza text.
- Suport pentru surse variate: Thunderbit nu se limitează la HTML — poate extrage și din PDF-uri și imagini, folosind OCR integrat și vision AI ().
- Integrări pentru business: Export dintr-un click către Google Sheets, Airtable, Notion sau Excel (). Poți programa extrageri și trimite datele direct în fluxul de lucru al echipei.
- Șabloane gata făcute: Pentru site-uri precum Amazon, LinkedIn, Zillow etc., Thunderbit oferă pentru extragere dintr-un click.
- Ușor de folosit și accesibil: Interfața e point-and-click, cu un asistent intuitiv. Utilizatorii spun că pornesc în câteva minute — 금방 익숙해짐 (te prinzi repede).

Thunderbit este folosit de , inclusiv echipe de la Accenture, Grammarly și Puma. Echipele de vânzări îl folosesc pentru , agenții imobiliari agregă anunțuri, iar marketerii monitorizează concurența — fără să scrie o singură linie de cod.
Preț: Există un (până la 100 de pași/lună), iar planurile plătite pornesc de la 14,99 USD/lună. Chiar și planurile Pro sunt accesibile pentru persoane și echipe mici.
Thunderbit e cel mai apropiat lucru pe care l-am văzut de „transformarea web-ului într-o bază de date” — și e făcut pentru toată lumea, nu doar pentru ingineri.
2. Crawl4AI
Pentru cine: Developeri și echipe tehnice care construiesc pipeline-uri personalizate.
Crawl4AI este un framework open-source în Python, optimizat pentru viteză și crawling la scară mare, cu . E foarte rapid, suportă headless browsers pentru conținut dinamic și poate structura datele extrase pentru a fi ușor de folosit în fluxuri AI.
- Cel mai bun pentru: Developeri care au nevoie de un motor de crawling puternic și personalizabil.
- Preț: Gratuit (licență MIT). Trebuie să-l găzduiești și să-l rulezi singur.
3. ScrapeGraphAI
Pentru cine: Developeri și analiști care construiesc agenți AI sau pipeline-uri complexe de date.
ScrapeGraphAI este o bibliotecă Python open-source, bazată pe prompturi, care transformă site-urile în „grafuri” de date structurate folosind LLM-uri. Poți scrie prompturi precum „Extrage toate numele produselor, prețurile și ratingurile din primele 5 pagini”, iar instrumentul îți construiește workflow-ul de scraping ().
- Cel mai bun pentru: Utilizatori tehnici care vor scraping flexibil, controlat prin prompt.
- Preț: Gratuit pentru biblioteca open-source; API-ul cloud pornește de la 20 USD/lună.
4. Firecrawl
Pentru cine: Developeri care construiesc agenți AI sau pipeline-uri de date la scară mare.
Firecrawl este o platformă și un API orientate către AI, care transformă site-uri întregi în date „pregătite pentru LLM” (). Livrează Markdown sau JSON, gestionează conținut dinamic și se integrează cu framework-uri precum LangChain și LlamaIndex.
- Cel mai bun pentru: Developeri care trebuie să alimenteze modele AI cu date web live.
- Preț: Nucleul open-source e gratuit; planurile cloud pornesc de la 19 USD/lună.
5. Browse AI
Pentru cine: Utilizatori de business, growth hackers și analiști.
Browse AI este o platformă no-code cu . „Antrenezi” un robot făcând click pe datele dorite, iar AI-ul generalizează tiparul pentru extrageri viitoare. Gestionează login-uri, infinite scroll și poate monitoriza site-uri pentru schimbări.
- Cel mai bun pentru: Utilizatori non-tehnici care vor automatizare pentru colectare și monitorizare de date.
- Preț: Plan gratuit (50 credite/lună); planurile plătite pornesc de la 19 USD/lună.
6. LLM Scraper
Pentru cine: Developeri care vor ca AI-ul să facă parsarea.
LLM Scraper este o bibliotecă open-source JavaScript/TypeScript care îți permite să , iar un LLM extrage acele câmpuri din orice pagină web. E construit pe Playwright, suportă mai mulți furnizori LLM și poate genera cod reutilizabil.
- Cel mai bun pentru: Developeri care vor să transforme orice pagină în date structurate cu ajutorul LLM-urilor.
- Preț: Gratuit (licență MIT).
7. Reader (Jina Reader)
Pentru cine: Developeri care construiesc aplicații LLM, chatboți sau instrumente de sumarizare.
Jina Reader este un API care extrage , returnând Markdown sau JSON pregătit pentru LLM. E alimentat de un model AI propriu și poate genera inclusiv descrieri pentru imagini.
- Cel mai bun pentru: Obținerea rapidă de conținut lizibil pentru LLM-uri sau sisteme Q&A.
- Preț: API gratuit (nu ai nevoie de cheie pentru utilizare de bază).
8. Bright Data
Pentru cine: Companii mari și utilizatori profesioniști care au nevoie de scalare, conformitate și fiabilitate.
Bright Data este un nume greu în industria datelor web, cu o rețea uriașă de proxy-uri și . Oferă scrapers gata făcuți, un API general de Web Scraper și feed-uri de date „LLM-ready”.
- Cel mai bun pentru: Organizații care au nevoie de date web stabile, la scară.
- Preț: Bazat pe consum, premium. Există trial-uri.
9. Octoparse
Pentru cine: Utilizatori non-tehnici până la semi-tehnici.
Octoparse este un instrument no-code consacrat, cu și auto-detect asistat de AI. Gestionează login-uri, infinite scroll și exportă în mai multe formate.
- Cel mai bun pentru: Analiști, proprietari de afaceri mici sau cercetători.
- Preț: Are variantă gratuită; planurile plătite pornesc de la 119 USD/lună.
10. Apify
Pentru cine: Developeri și echipe tehnice care au nevoie de scraping/automatizare personalizată.
Apify este o platformă cloud pentru rularea scripturilor de scraping („actors”) și oferă un . E scalabil, se integrează cu AI și include management de proxy.
- Cel mai bun pentru: Developeri care vor să ruleze scripturi custom în cloud.
- Preț: Plan gratuit; planurile plătite bazate pe consum pornesc de la 49 USD/lună.
11. Zyte (Scrapy Cloud)
Pentru cine: Developeri și companii care au nevoie de scraping la nivel enterprise.
Zyte este compania din spatele Scrapy și oferă o platformă cloud cu . Include programare, proxy-uri și suport pentru proiecte mari.
- Cel mai bun pentru: Echipe de dezvoltare care rulează proiecte de scraping pe termen lung.
- Preț: Trial-uri gratuite până la planuri enterprise personalizate.
12. Webscraper.io
Pentru cine: Începători, jurnaliști și cercetători.
este o pentru extragere point-and-click. E simplă, gratuită pentru utilizare locală și are un serviciu cloud pentru joburi mai mari.
- Cel mai bun pentru: Sarcini rapide, ocazionale.
- Preț: Extensie gratuită; planurile cloud pornesc de la ~50 USD/lună.
13. ParseHub
Pentru cine: Utilizatori non-tehnici care au nevoie de mai multă putere decât oferă instrumentele de bază.
ParseHub este o aplicație desktop cu workflow vizual pentru scraping de conținut dinamic, inclusiv hărți și formulare. Poate rula proiecte în cloud și oferă API.
- Cel mai bun pentru: Marketeri digitali, analiști și jurnaliști.
- Preț: Plan gratuit (200 pagini/rulare); planurile plătite pornesc de la 189 USD/lună.
14. Diffbot
Pentru cine: Companii mari și firme AI care au nevoie de date web structurate, la scară.
Diffbot folosește computer vision și NLP pentru a din orice pagină web, oferind API-uri pentru articole, produse și un knowledge graph masiv.
- Cel mai bun pentru: Market intelligence, finanțe și date de antrenare pentru AI.
- Preț: Premium, de la ~299 USD/lună.
15. DataMiner
Pentru cine: Utilizatori non-tehnici, mai ales în vânzări, marketing și jurnalism.
DataMiner este o pentru extragere rapidă de date web, prin point-and-click. Are o bibliotecă de „rețete” predefinite și poate exporta direct în Google Sheets.
- Cel mai bun pentru: Sarcini rapide, precum exportul de tabele sau liste în spreadsheet.
- Preț: Plan gratuit (500 pagini/zi); Pro pornește de la ~19 USD/lună.
Compararea celor mai bune instrumente AI Web Scraper: care se potrivește nevoilor tale?
Iată o comparație la nivel înalt ca să-ți găsești varianta potrivită:
| Instrument | Utilizare AI/LLM | Ușurință în utilizare | Output/Integrare | Ideal pentru | Preț |
|---|---|---|---|---|---|
| Thunderbit | UI în limbaj natural; AI sugerează câmpuri | Cel mai ușor (chat no-code) | Export în Sheets, Airtable, Notion | Echipe non-tehnice | Plan gratuit; Pro ~30 USD/lună |
| Crawl4AI | Crawling pregătit pentru AI; integrare LLM | Greu (cod Python) | Bibliotecă/CLI; integrare prin cod | Devs care vor pipeline-uri rapide pentru date AI | Gratuit |
| ScrapeGraphAI | Pipeline-uri de scraping pe prompturi LLM | Mediu (puțin cod sau API) | API/SDK; output JSON | Devs/analiști care construiesc agenți AI | OSS gratuit; API 20+ USD/lună |
| Firecrawl | Crawling către Markdown/JSON „LLM-ready” | Mediu (API/SDK) | SDK-uri (Py, Node etc.); integrare LangChain | Devs care conectează date web live la AI | Gratuit + cloud plătit |
| Browse AI | Point & click asistat de AI | Ușor (no-code) | 7000+ integrări (Zapier) | Utilizatori non-tehnici care automatizează monitorizarea web | Gratuit 50 rulări; Plătit 19+ USD/lună |
| LLM Scraper | Folosește LLM-uri pentru parsare după schemă | Greu (cod TS/JS) | Bibliotecă; output JSON | Devs care vor ca AI-ul să facă parsarea | Gratuit (folosești propriul API LLM) |
| Reader (Jina) | Model AI extrage text/JSON | Ușor (apel API simplu) | REST API returnează Markdown/JSON | Devs care adaugă căutare/conținut web în LLM-uri | API gratuit |
| Bright Data | API-uri de scraping cu AI; rețea mare de proxy | Greu (API, tehnic) | API/SDK; stream-uri sau dataset-uri | Scală enterprise | Bazat pe consum |
| Octoparse | AI detectează automat liste | Moderat (aplicație no-code) | CSV/Excel, API pentru rezultate | Utilizatori semi-tehnici | Gratuit limitat; 59–166 USD/lună |
| Apify | Unele funcții AI (Actors, tutoriale AI) | Greu (scripturi) | API complet; integrare cu LangChain | Devs care vor scraping custom în cloud | Plan gratuit; pay-as-you-go |
| Zyte (Scrapy) | Extragere automată bazată pe ML; framework Scrapy | Greu (cod Python) | API, UI Scrapy Cloud; JSON/CSV | Echipe dev, proiecte pe termen lung | Preț personalizat |
| Webscraper.io | Fără AI (șabloane manuale) | Ușor (extensie browser) | Descărcare CSV, Cloud API | Începători, extrageri ocazionale | Extensie gratuită; Cloud ~50 USD/lună |
| ParseHub | Fără LLM explicit; builder vizual | Moderat (aplicație no-code) | JSON/CSV; API pentru rulări cloud | Non-devs care extrag din site-uri complexe | Gratuit 200 pagini; Plătit 189+ USD/lună |
| Diffbot | AI vision/NLP pentru orice pagină; knowledge graph | Ușor (apeluri API) | API-uri (Article/Prod/...) + interogare Knowledge Graph | Enterprise, date web structurate | De la ~299 USD/lună |
| DataMiner | Fără LLM; rețete din comunitate | Cel mai ușor (UI în browser) | Export Excel/CSV; Google Sheets | Utilizatori non-tehnici care exportă în spreadsheet | Gratuit limitat; Pro ~19 USD/lună |
Categorii de instrumente: de la „monștri” pentru developeri la Web Scraper-e prietenoase pentru business
Ca să fie mai ușor de înțeles lista, le putem grupa în câteva categorii:
1. Soluții puternice pentru developeri & open-source
- Exemple: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Puncte forte: Flexibilitate mare, scalare și personalizare. Excelente pentru pipeline-uri custom sau integrare cu modele AI.
- Compromisuri: Necesită abilități de programare și mai multă configurare.
- Scenarii: Construirea unui pipeline de date, scraping pe site-uri complexe sau integrare cu sisteme interne.
2. Agenți de scraping integrați cu AI
- Exemple: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Puncte forte: Micșorează distanța dintre „extragere” și „înțelegerea” datelor. Interfețele în limbaj natural le fac accesibile — 말로 하면 된다 (îi spui și gata).
- Compromisuri: Unele sunt încă în evoluție; pot oferi mai puțin control granular.
- Scenarii: Răspunsuri rapide sau dataset-uri, agenți autonomi, alimentarea LLM-urilor cu date live.
3. Scraper-e no-code/low-code, prietenoase pentru business
- Exemple: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Puncte forte: Ușor de folosit, necesită puțin sau deloc cod, bune pentru sarcini recurente în business.
- Compromisuri: Pot avea dificultăți pe site-uri foarte complexe sau la scară uriașă.
- Scenarii: Lead generation, monitorizarea concurenței, proiecte de research, extrageri punctuale.
4. Platforme și servicii enterprise pentru date
- Exemple: Bright Data, Diffbot, Zyte
- Puncte forte: Soluții end-to-end, servicii gestionate, conformitate și fiabilitate la scară.
- Compromisuri: Cost mai mare, onboarding mai complex.
- Scenarii: Pipeline-uri mari, always-on, market intelligence, date pentru antrenarea AI.
Cum alegi crawler-ul web cu AI potrivit pentru nevoile tale de scraping
Alegerea instrumentului potrivit poate părea copleșitoare, așa că iată ghidul meu pas cu pas:
- Clarifică obiectivele și cerințele de date: De pe ce site-uri ai nevoie de date? Ce anume? Cât de des? În ce volum? Ce vei face cu ele?
- Evaluează nivelul tău tehnic: Fără cod? Încearcă Thunderbit, Browse AI sau Octoparse. Cu puțin scripting? LLM Scraper sau DataMiner. Cu skill-uri solide de dev? Crawl4AI, Apify sau Zyte.
- Gândește-te la frecvență și scală: O singură dată? Folosește instrumente gratuite. Recurring? Caută funcții de programare. La scară mare? Soluții enterprise sau open-source rulat la scară.
- Buget și model de preț: Planurile gratuite sunt excelente pentru test. Abonament vs. pay-as-you-go depinde de nevoi.
- Trial și proof of concept: Testează câteva instrumente pe datele tale reale. Majoritatea au planuri gratuite.
- Mentenanță și suport: Cine repară dacă se schimbă site-ul? Instrumentele no-code cu AI pot corecta automat schimbări mici; open-source se bazează pe tine sau comunitate.
- Potrivește instrumentele cu scenariile: Echipa de vânzări extrage lead-uri? Thunderbit sau Browse AI. Cercetător colectează tweet-uri? DataMiner sau . Model AI are nevoie de articole de știri? Jina Reader sau Zyte. Construiești un site de comparații? Apify sau Zyte.
- Plan de rezervă: Uneori un instrument nu merge pe un anumit site. E bine să ai o alternativă — 플랜 B.
Instrumentul „corect” este cel care îți aduce datele de care ai nevoie cu cea mai mică fricțiune și în bugetul tău. Uneori, e o combinație.
Thunderbit vs. instrumentele clasice de Web Scraper: ce îl face diferit?
Hai să fim concreți despre ce îl diferențiază pe Thunderbit:
- Interfață în limbaj natural: Fără cod, fără acrobații point-and-click. Doar descrii ce vrei ().
- Zero configurare & sugestii de șabloane: Thunderbit detectează automat paginarea, subpaginile și chiar propune șabloane pentru site-uri comune ().
- Curățare și îmbogățire a datelor cu AI: Poți rezuma, categoriza, traduce și îmbogăți datele în timp ce le extragi ().
- Mai puține probleme de mentenanță: AI-ul Thunderbit rezistă la schimbări minore ale site-urilor, reducând „ruperea” extragerilor.
- Integrare cu instrumente de business: Export direct în Google Sheets, Airtable, Notion — fără bătăi de cap cu CSV-uri ().
- Timp până la valoare: De la idee la date în minute, nu în zile — 시간 절약 (economisești timp).
- Curba de învățare: Dacă poți naviga pe web și poți descrie ce ai nevoie, poți folosi Thunderbit.
- Adaptabilitate: Extragi din site-uri, PDF-uri, imagini și altele — cu același instrument.
Thunderbit nu e doar un scraper — e un asistent de date care se potrivește în workflow-ul tău, fie că ești în vânzări, marketing, ecommerce sau real estate.
Bune practici pentru scraping de pagini web cu instrumente AI Web Scraper
Ca să obții maximum din AI web scrapers, iată recomandările mele:
- Definește clar ce date vrei: Știi ce câmpuri îți trebuie, câte pagini și în ce format.
- Folosește sugestiile AI: Profită de detectarea câmpurilor și recomandările AI ca să nu ratezi date importante ().
- Începe cu un eșantion mic și validează: Testează pe puține pagini, verifică output-ul și ajustează.
- Gestionează conținutul dinamic: Asigură-te că instrumentul suportă interacțiuni (paginare, infinite scroll etc.).
- Respectă politicile site-ului: Verifică robots.txt, evită date sensibile și respectă rate limits.
- Integrează pentru automatizare: Folosește exporturi și webhooks ca să trimiți datele direct în workflow.
- Menține calitatea datelor: Verifică logic datele, aplică post-procesare și monitorizează erorile.
- Fii specific în prompturi: La instrumentele bazate pe AI, instrucțiunile clare dau rezultate mai bune — 구체적으로 (cât mai specific).
- Învață din comunitate: Forumurile și comunitățile sunt excelente pentru tips & troubleshooting.
- Rămâi la curent: Instrumentele AI evoluează rapid — urmărește funcțiile noi și îmbunătățirile.
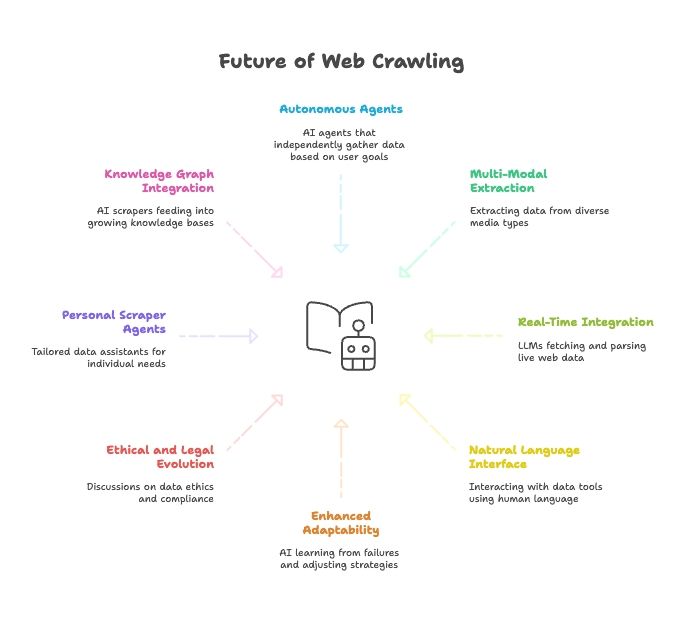
Viitorul web scraping-ului: AI, LLM-uri și ascensiunea agenților Web Scraper în limbaj natural
Privind înainte, convergența dintre AI și web scraping se accelerează:
- Agenți de scraping complet autonomi: În curând, îi vei spune unui agent AI obiectivul final, iar el va decide singur cum obține datele.
- Extragere multi-modală: Scraper-ele vor colecta date din text, imagini, PDF-uri și chiar video.
- Integrare în timp real cu modele AI: LLM-urile vor avea module integrate pentru a prelua și parsa date web live.
- Totul în limbaj natural: Vom „vorbi” cu instrumentele de date ca și cu oamenii, făcând colectarea și transformarea datelor accesibile tuturor — 누구나 쉽게 (ușor pentru oricine).
- Adaptabilitate mai bună: Scraper-ele cu AI vor învăța din eșecuri și își vor ajusta automat strategiile.
- Evoluție etică și legală: Vor exista tot mai multe discuții despre etică, conformitate și fair use.
- Agenți personali de scraping: Imaginează-ți un asistent personal care îți adună știri, joburi și altele, adaptate nevoilor tale.
- Integrare cu knowledge graphs: Scraper-ele cu AI vor alimenta continuu baze de cunoștințe în creștere, pentru AI mai inteligent.
Concluzia? Viitorul web scraping-ului merge mână în mână cu viitorul AI. Instrumentele devin mai inteligente, mai autonome și mai accesibile în fiecare zi — 점점 더 똑똑해진다.
Concluzie: cum deblochezi valoare pentru business cu crawler-ul web cu AI potrivit
Web scraping-ul a trecut de la o abilitate de nișă, tehnică, la o capabilitate esențială pentru business — datorită AI-ului. Cele 15 instrumente prezentate aici arată ce e posibil în 2026, de la soluții pentru developeri până la asistenți prietenoși pentru echipe.
Secretul real? Alegerea instrumentului potrivit poate crește dramatic valoarea pe care o obții din datele web. Pentru echipe non-tehnice, Thunderbit este cea mai simplă cale de a transforma web-ul într-o bază de date structurată, gata de analiză — fără cod, fără bătăi de cap, doar rezultate.
Așadar, fie că strângi lead-uri, monitorizezi concurența sau alimentezi următorul tău model AI, merită să-ți evaluezi nevoile, să testezi câteva instrumente și să vezi ce ți se potrivește. Iar dacă vrei să trăiești viitorul web scraping-ului chiar azi, . Insight-urile de care ai nevoie sunt la un prompt distanță.
Vrei mai mult? Intră pe pentru analize detaliate, tutoriale și noutăți despre extragerea de date cu AI.
Lecturi recomandate:
Întrebări frecvente (FAQs)
1. Ce este un crawler web cu AI și cu ce diferă de web scrapers tradiționale?
Un crawler web cu AI folosește procesarea limbajului natural și machine learning pentru a înțelege, extrage și structura date web. Spre deosebire de scraper-ele tradiționale, care cer cod manual și selectori XPath, instrumentele AI pot gestiona conținut dinamic, se adaptează la schimbări de layout și interpretează instrucțiuni în limbaj natural.
2. Cine ar trebui să folosească instrumente de AI web scraping precum Thunderbit?
Thunderbit este creat atât pentru utilizatori non-tehnici, cât și pentru cei tehnici. Este ideal pentru profesioniști din vânzări, marketing, operațiuni, research și ecommerce care vor să extragă date structurate din site-uri, PDF-uri sau imagini — fără să scrie cod.
3. Ce funcții îl fac pe Thunderbit să iasă în evidență față de alte crawlere web cu AI?
Thunderbit oferă interfață în limbaj natural, crawling pe mai multe niveluri, structurare automată a datelor, suport OCR și exporturi fără fricțiune către platforme precum Google Sheets și Airtable. Include și sugestii de câmpuri bazate pe AI și șabloane predefinite pentru site-uri populare.
4. Există opțiuni gratuite pentru AI web scraping în 2026?
Da. Multe instrumente precum Thunderbit, Browse AI și DataMiner au planuri gratuite cu utilizare limitată. Pentru developeri, opțiuni open-source precum Crawl4AI și ScrapeGraphAI oferă funcționalitate completă fără cost, însă necesită configurare tehnică.
5. Cum aleg crawler-ul web cu AI potrivit pentru nevoile mele?
Începe prin a-ți defini obiectivele de date, nivelul tehnic, bugetul și cerințele de scală. Dacă vrei o soluție no-code, ușor de folosit, Thunderbit sau Browse AI sunt alegeri excelente. Pentru nevoi custom sau la scară mare, instrumente precum Apify sau Bright Data sunt mai potrivite.