Îți spun un secret: odată credeam că web scraping-ul e rezervat hackerilor cu hanorac sau data scientist-ilor cu mai multe monitoare decât bun-simț. Dar, în zilele noastre, extragerea datelor dintr-un site web e la fel de obișnuită în business ca o cafea de dimineață — cu diferența că, din fericire, nu trebuie să știi Python și nici să bei trei espresso înainte de prânz. De fapt, odată cu apariția uneltelor de AI web scraper, chiar și cei care cred că „HTML” e un nou sendviș de la Subway pot extrage date structurate din web-ul sălbatic.
Dacă ți s-a întâmplat vreodată să copiezi și să lipești rânduri cu informații despre produse, lead-uri de vânzări sau liste de prețuri într-un spreadsheet, nu ești singur. Aproape folosesc acum web scraping pentru insight-uri de piață și monitorizarea concurenței. Iar cum piața software-ului de web scraping este estimată să ajungă la , un lucru e clar: extragerea datelor web nu mai este doar pentru elita tech. Așadar, fie că ești în vânzări, marketing sau pur și simplu vrei să nu mai introduci date manual, acest ghid este pentru tine. Îți voi arăta bazele, voi compara abordările tradiționale cu cele bazate pe AI și îți voi explica cum să începi — fără hanorac obligatoriu.
Bazele Web Scraper-ului: Ce înseamnă să extragi date dintr-un site web?
Să începem simplu. Un web scraper este doar un instrument (sau un script, sau o extensie de Chrome) care colectează automat date din site-uri web. Gândește-te la el ca la un stagiar super-rapid, care nu se plânge niciodată de sarcinile repetitive. În loc să copiezi și să lipești informații rând cu rând, un web scraper face totul în câteva secunde și nici măcar nu cere pauză de cafea.
Există două tipuri principale de date cu care te vei întâlni:
- Date structurate: sunt datele ordonate, pregătite pentru spreadsheet — de exemplu tabele cu nume de produse, prețuri sau emailuri. Sunt organizate, etichetate și ușor de analizat.
- Date nestructurate: acesta e vestul sălbatic — articole de blog, recenzii, imagini sau orice altceva care nu se potrivește perfect în rânduri și coloane. Majoritatea proiectelor de web scraping încearcă să transforme datele nestructurate în date structurate, astfel încât să poți să le folosești efectiv.
Dacă ai copiat vreodată un tabel dintr-un site web în Excel, felicitări — ai făcut web scraping manual. Acum imaginează-ți asta pentru 10.000 de pagini. (Nu face asta, de fapt. Pentru asta există web scraper-ele.)
De ce să extragi date din site-uri web? Beneficii cheie pentru business
Deci, de ce să te obosești să extragi date de la bun început? Răspunsul scurt: afacerile funcționează pe bază de date, iar web-ul este cea mai mare bază de date din lume. Fie că lucrezi în vânzări, marketing, ecommerce sau imobiliare, extragerea datelor web îți poate oferi un avantaj serios.
Iată câteva dintre cele mai comune cazuri de utilizare în business:
| Caz de utilizare | Descriere | Exemplu de ROI/beneficiu |
|---|---|---|
| Generare de lead-uri | Colectarea informațiilor de contact, a emailurilor sau a listelor de companii din directoare ori rețele sociale | Echipele de vânzări economisesc ore și găsesc lead-uri mai calificate |
| Monitorizarea prețurilor | Urmărirea prețurilor concurenților, a stocurilor sau a promoțiilor în timp real | Comercianții ajustează prețurile dinamic, crescând vânzările cu 4% |
| Cercetare de piață | Agregarea recenziilor, știrilor sau sentimentului din social media pentru a observa tendințe | Marketerii își adaptează campaniile la insight-uri de consum în timp real |
| Analiza concurenței | Monitorizarea cataloagelor de produse, lansărilor sau conținutului rivalilor | Companiile reacționează mai rapid la schimbările pieței |
| Intelligence în imobiliare | Extragerea listărilor de proprietăți, a prețurilor și a disponibilității | Agenții și investitorii detectează oportunități înaintea pieței |
De fapt, din Marea Britanie și Europa folosesc strategii de prețuri dinamice bazate pe scraping-ul prețurilor concurenților. Iar companii precum John Lewis și ASOS au înregistrat creșteri măsurabile ale vânzărilor folosind date web pentru decizii mai inteligente.
Uneltele tradiționale de Web Scraper: Cum funcționează?
Să revenim la varianta „clasică” de extragere a datelor — înainte ca AI-ul să-și flexeze mușchii. Web scraper-ele tradiționale sunt de obicei scripturi (adesea scrise în Python) sau extensii de browser care urmează un set de reguli pentru a colecta datele dorite.
Iată cum decurge, de regulă, procesul:
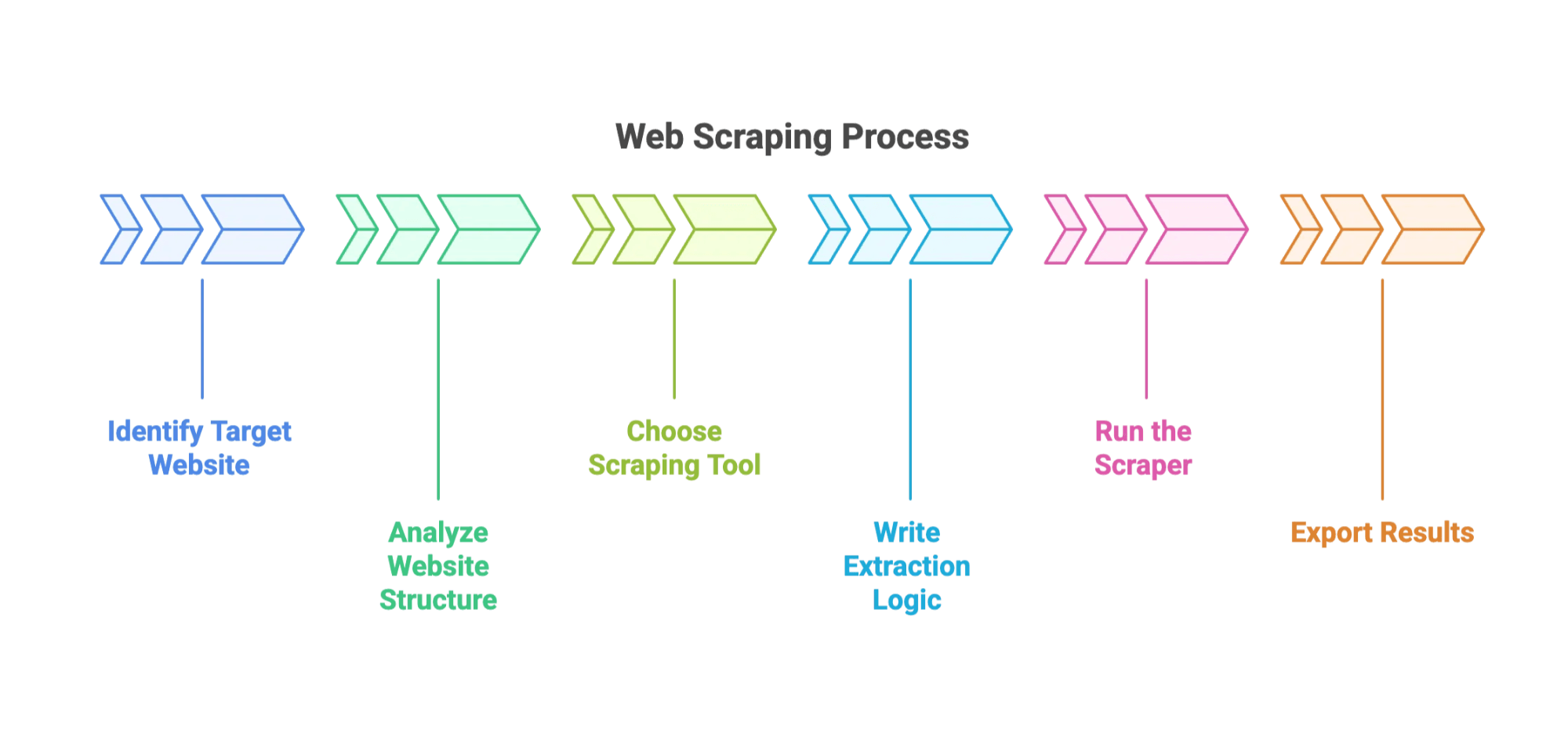
- Identifică site-ul țintă și câmpurile de date.
- Analizează structura site-ului. (Asta înseamnă să te uiți prin HTML cu Developer Tools din browser. E ca arheologia digitală.)
- Alege instrumentul: opțiunile populare includ , sau pluginuri de browser.
- Scrie logica de extragere: spune-i instrumentului cum să găsească datele — de obicei prin CSS selectors sau XPath.
- Rulează scraper-ul: urmărește cum colectează datele de pe mai multe pagini.
- Exportă rezultatele: de obicei în CSV, JSON sau direct în Excel.
Pas cu pas: extragerea datelor cu un web scraper tradițional
Să spunem că vrei să extragi listări de produse dintr-un site de ecommerce. Iată un ghid ușor pentru începători:
- Pasul 1: Instalează Python și biblioteca BeautifulSoup.
- Pasul 2: Folosește browserul pentru a inspecta pagina de produs. Găsește tagurile HTML care conțin numele produsului și prețul.
- Pasul 3: Scrie un script scurt ca să preia pagina, să parseze HTML-ul și să extragă câmpurile relevante.
- Pasul 4: Parcurge mai multe pagini (gestionând paginarea).
- Pasul 5: Exportă datele într-un fișier CSV.
Sună simplu, dar crede-mă — primul tău script probabil va da eroare cel puțin o dată. (Prima mea încercare a extras 500 de rânduri cu „None” pentru că am scris greșit numele unei clase. Ups.)
Provocări comune cu soluțiile tradiționale de Web Scraper
Aici lucrurile devin mai complicate:
- Schimbări ale site-ului: chiar și o mică modificare în aspectul site-ului poate strica scraper-ul. se strică în fiecare săptămână din cauza schimbărilor.
- Măsuri anti-bot: CAPTCHA, blocări de IP și limitări de rată te pot opri complet. Va trebui să gestionezi proxy-uri, întârzieri și, uneori, chiar să rezolvi CAPTCHA-uri.
- Sunt necesare competențe tehnice: trebuie să știi puțin cod și HTML/CSS.
- Mentenanță: scraper-ele au nevoie de supraveghere și actualizări constante.
- Date dezordonate: vei petrece timp curățând formate inconsistente, valori lipsă sau codări ciudate.
Pentru un începător, poate părea că încerci să coci un tort în timp ce rețeta se schimbă mereu și cuptorul te mai și blochează afară din când în când.
Intră în scenă AI Web Scraper-ul: extragerea datelor devine accesibilă
Acum vine partea distractivă. AI web scraper-ele schimbă regulile jocului (ups, aproape am folosit expresia interzisă). În loc să scrii cod sau să te chinui cu selectors, poți pur și simplu să-i spui instrumentului ce vrei, în engleză simplă. AI-ul se ocupă de restul.
Thunderbit (adică noi!) este un exemplu excelent al acestei noi generații. Cu , poți extrage date structurate din orice site web folosind limbaj natural — fără să scrii cod. Fie că lucrezi în vânzări, marketing sau ecommerce, poți colecta datele de care ai nevoie în minute, nu în zile.
AI Web Scraper Thunderbit: cum simplifică extragerea datelor
Lasă-mă să-ți arăt cum îți face Thunderbit viața mai ușoară:
- AI Suggest Fields: dă click pe „AI Suggest Fields” și Thunderbit citește site-ul, recomandă nume de coloane și chiar sugerează cum să extragi fiecare câmp.
- Subpage Scraping: ai nevoie de mai multe detalii? Thunderbit poate vizita fiecare subpagină (de exemplu pagini individuale de produs) și îți îmbogățește automat tabelul cu date.
- Șabloane instant: pentru site-uri populare precum Amazon sau Zillow, poți folosi șabloane predefinite — fără configurare.
- Export gratuit de date: exportă datele în Excel, Google Sheets, Airtable sau Notion. Descarcă în CSV sau JSON. Fără taxe ascunse.
- Scheduled Scraping: setează extrageri recurente ca să-ți păstrezi datele proaspete — excelent pentru monitorizarea prețurilor sau actualizări de lead-uri.
- AI Autofill: lasă AI-ul să completeze formulare online pentru tine (da, chiar și acel formular de onboarding pentru furnizori de 10 pagini).
- Extractoare de email, telefon și imagini: ia informații de contact sau imagini cu un singur click.
Și partea cea mai bună? Nu trebuie să știi deloc programare. Extensia Chrome Thunderbit este disponibilă , iar mai multe detalii găsești pe .
Compararea soluțiilor tradiționale cu cele AI Web Scraper
Să vedem cum se compară cele două abordări:
| Aspect | Web Scraper tradițional | AI Web Scraper (Thunderbit) |
|---|---|---|
| Ușurință în utilizare | Necesită cod sau configurare complexă | Fără cod, interfață în limbaj natural |
| Adaptabilitate | Se strică ușor la schimbările site-ului | AI-ul se adaptează automat la schimbările de layout |
| Mentenanță | Ridicată — necesită actualizări frecvente | Redusă — AI-ul gestionează majoritatea schimbărilor |
| Competențe tehnice | Necesită programare și cunoașterea HTML | Gândit pentru utilizatori de business |
| Viteză de configurare | De la ore la zile | Minute |
| Procesarea datelor | Necesită curățare manuală | AI-ul curăță și structurează automat datele |
| Cost | Gratuit (open source), dar consumă mult timp | Planuri accesibile, opțiuni gratuite de export |
Pentru majoritatea utilizatorilor de business, mai ales începători, AI web scraper-ele precum Thunderbit sunt alegerea clară pentru viteză, simplitate și fiabilitate. Uneltele tradiționale încă au un rol în proiectele foarte personalizate sau la scară mare — dar pentru 95% dintre cazuri, AI-ul este soluția potrivită.
Ghid pas cu pas: cum să extragi date dintr-un site web ca începător
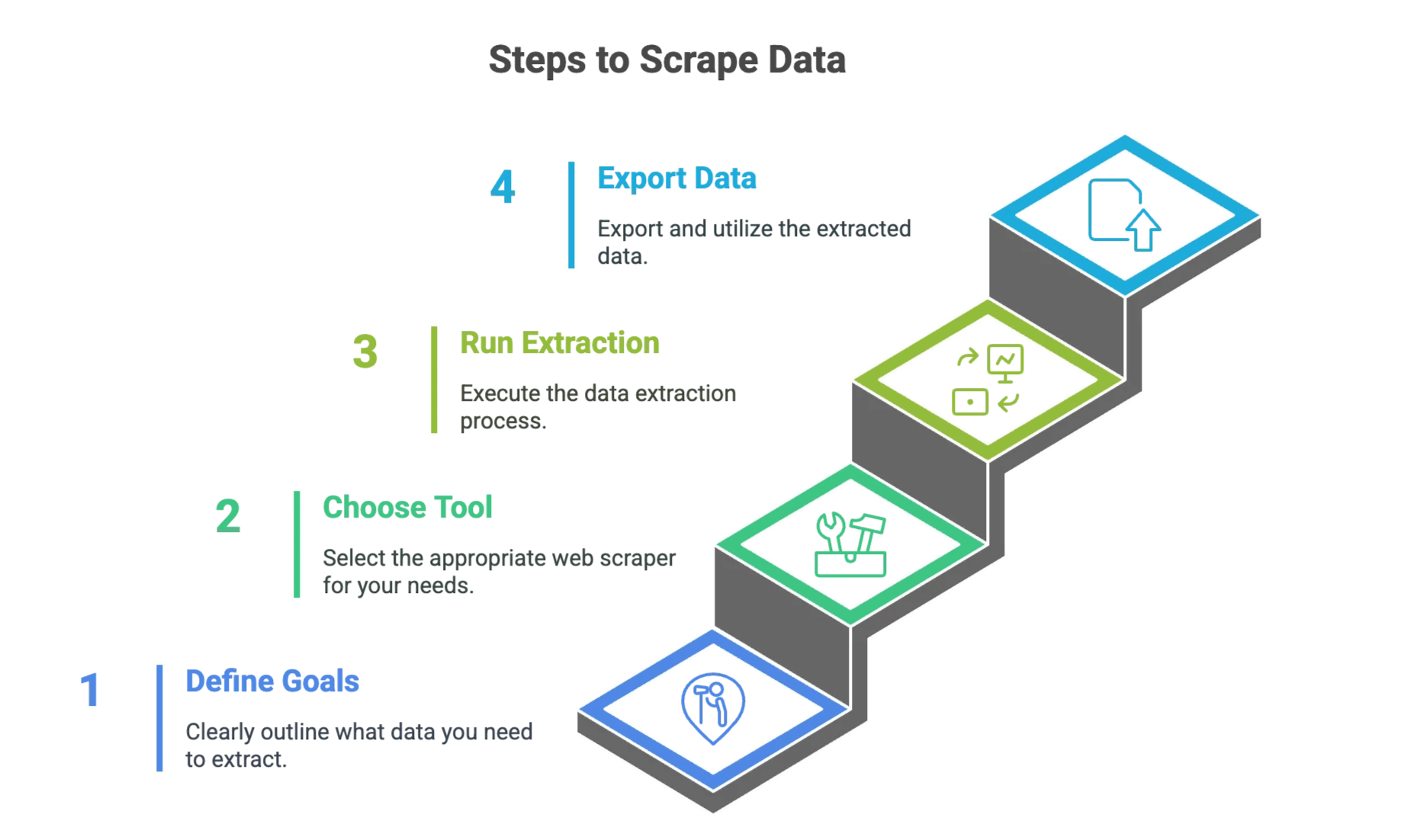
Pasul 1: Definește-ți obiectivele de extragere a datelor
Înainte să începi, clarifică ce ai nevoie. Întreabă-te:
- Ce site-uri vreau să extrag?
- Ce câmpuri de date sunt importante? (de exemplu: nume produs, preț, email, telefon)
- Cât de des am nevoie de aceste date? (o singură dată sau recurent?)
Fă o listă de verificare. De exemplu: „Vreau să colectez numele produselor, prețurile și ratingurile de pe primele 5 pagini din .”
Pasul 2: Alege instrumentul potrivit de Web Scraper
Iată un flux rapid de decizie:
- Te simți confortabil cu codul și vrei control total? Încearcă un instrument tradițional precum BeautifulSoup sau Scrapy.
- Vrei viteză, simplitate și fără cod? Mergi pe un AI web scraper precum .
Dacă nu ești sigur, începe cu AI. Poți oricând să aprofundezi mai târziu.
Pasul 3: Configurează și rulează extragerea datelor
Abordarea tradițională
- Instalează instrumentul: configurează Python și bibliotecile necesare.
- Inspectează site-ul: folosește DevTools din browser ca să găsești structura HTML.
- Scrie scriptul: definește cum găsești și extragi fiecare câmp de date.
- Testează pe o singură pagină: asigură-te că obții datele corecte.
- Extinde: adaugă paginare sau bucle pentru mai multe pagini.
- Exportă datele: salvează-le în CSV sau JSON.
Abordarea AI (Thunderbit)
- Instalează extensia Chrome Thunderbit: .
- Deschide site-ul țintă: navighează la pagina pe care vrei să o extragi.
- Dă click pe „AI Suggest Fields”: Thunderbit va citi pagina și va sugera coloane.
- Verifică previzualizarea: vezi dacă datele arată corect. Ajustează coloanele dacă e nevoie.
- Dă click pe „Scrape”: Thunderbit colectează datele pentru tine.
- Exportă datele: descarcă în Excel, Google Sheets, Airtable sau Notion.
Pentru un ghid vizual, vezi .
Pasul 4: Exportă și folosește datele
După ce ai datele:
- Exportă în instrumentul tău preferat: Excel, Google Sheets, Airtable, Notion, CSV sau JSON.
- Integrează-le în fluxul tău de lucru: folosește-le pentru prospectare în vânzări, analiză de prețuri, cercetare de piață sau orice are nevoie businessul tău.
- Curăță și validează: chiar și cu AI, e bine să verifici prin sondaj exactitatea datelor.
Sfaturi pentru o extragere reușită a datelor: evită capcanele frecvente
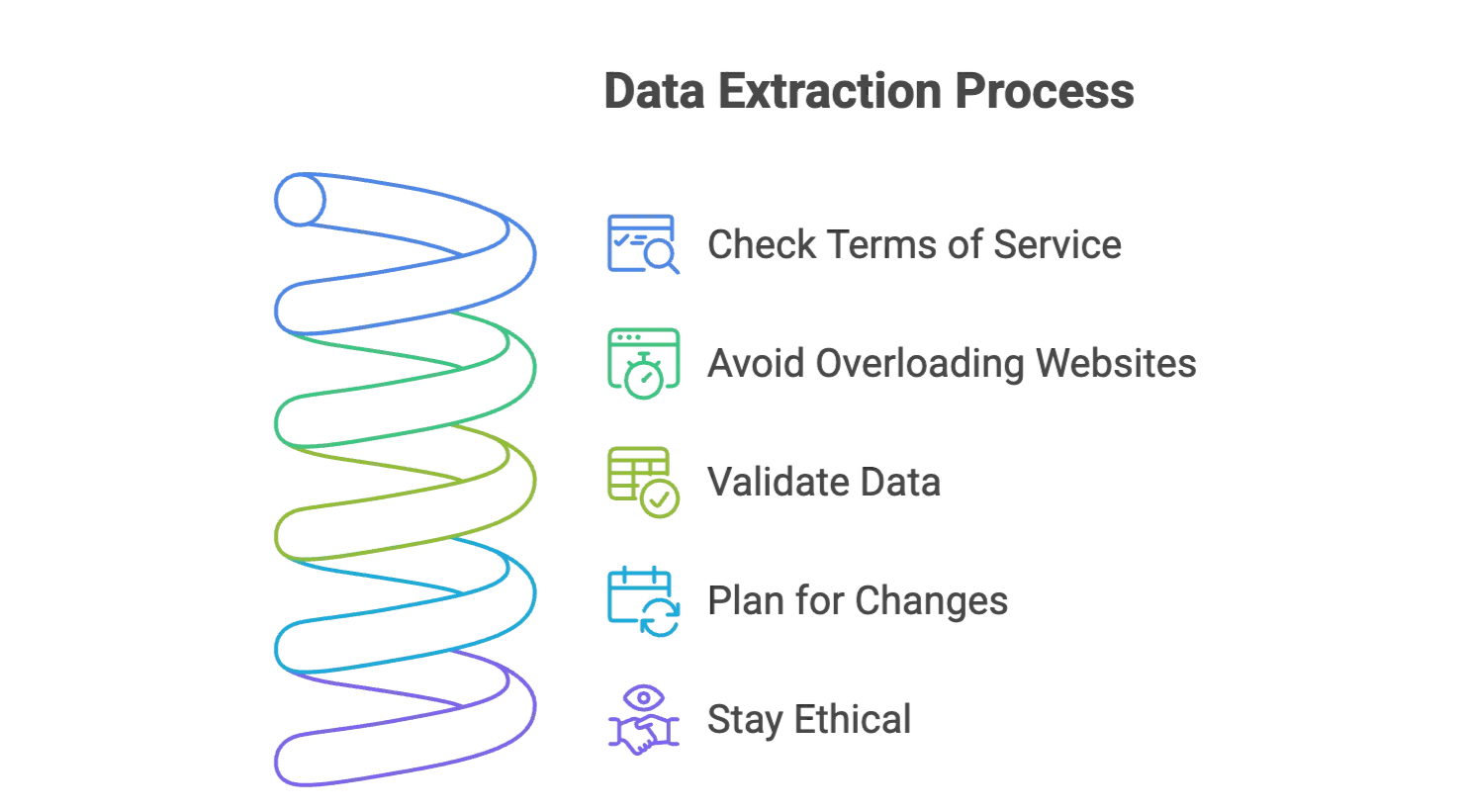
- Verifică termenii de utilizare ai site-ului: asigură-te că ai voie să extragi datele. Rămâi la informații publice și evită datele personale sensibile.
- Nu supraîncărca site-urile: adaugă întârzieri între cereri (în uneltele tradiționale) sau lasă Thunderbit să gestioneze asta pentru tine.
- Validează datele: verifică întotdeauna un eșantion din rezultate pentru acuratețe.
- Pregătește-te pentru schimbări: site-urile se actualizează tot timpul. AI scraper-ele precum Thunderbit se adaptează automat, dar e bine să monitorizezi schimbările majore.
- Rămâi etic: extrage doar ce ai nevoie și oferă credit dacă folosești datele în rapoarte sau publicații.
Pentru mai multe sfaturi, vezi și .
Concluzie și idei principale
Web scraping-ul a parcurs un drum lung — de la zilele scripturilor scrise manual până la uneltele moderne, bazate pe AI și prietenoase cu începătorii. Diferențele principale?

- Scraper-ele tradiționale oferă control, dar cer cod, mentenanță și răbdare.
- AI web scraper-ele precum fac extragerea datelor accesibilă pentru toată lumea, cu comenzi în limbaj natural, previzualizări instant și funcții puternice precum extragerea pe subpagini și extragerea programată.
Dacă ești nou în web scraping, nu te lăsa intimidat. Niciodată instrumentele nu au fost mai ușor de folosit, iar valoarea pentru business este incontestabilă. Fie că vrei să generezi lead-uri, să monitorizezi prețuri sau pur și simplu să nu mai copiezi și să nu mai lipești date, AI web scraper-ele sunt noul tău cel mai bun prieten.
Așa că, data viitoare când te uiți la un munte de date web, amintește-ți: nu ai nevoie de doctorat în informatică — și nici măcar de hanorac. Ai nevoie doar de un obiectiv clar, de instrumentul potrivit și poate de o cafea bună.
Ești gata să încerci singur? și vezi cât de ușoară poate fi extragerea datelor web.
Curios să afli mai mult? Aruncă o privire pe pentru analize detaliate despre scraping-ul Amazon, Google, PDF-uri și multe altele. Spor la scraping!
FAQ
Î1: Este legal web scraping-ul? R: Da, extragerea datelor publice este în general legală în multe țări. Totuși, verifică întotdeauna termenii de utilizare ai site-ului și evită extragerea datelor sensibile sau personale.
Î2: Pot extrage date de pe site-uri care necesită autentificare? R: Da, dar este mai complicat și poate încălca politicile site-ului. Vei avea nevoie de gestionarea sesiunii sau de unelte de scraping autentificate, iar implicațiile legale trebuie verificate cu atenție.
Î3: Cum pot extrage date de pe site-uri cu mult JavaScript? R: Folosește instrumente care suportă randarea dinamică, cum ar fi browsere headless sau AI scraper-e care simulează interacțiuni umane și parcurg conținutul randat prin JavaScript.
Î4: Care sunt cele mai bune practici ca să nu fiu blocat? R: Folosește limitarea ratei, întârzieri aleatorii, rotirea user-agent-ului și evită scraping-ul agresiv. Scraper-ele bazate pe AI gestionează adesea automat aceste strategii.
Citește mai mult
-
Prezentare generală a ghidurilor legale, statisticilor din industrie și bunelor practici etice.
-
Tendințe, creștere de piață și rolul AI în extragerea datelor web (2024–2025).
-
Învață cum să interpretezi fișierele robots.txt pentru a ghida scraping-ul etic și legal.