Raspador do Tumblr
Confiado por profissionais de empresas líderes














Desbloqueie os dados do Tumblr com a Thunderbit
Extraia facilmente dados do Tumblr, como conteúdo de posts e número de curtidas.
Tenha a visão completa do Tumblr
As páginas de listagem do Tumblr mostram apenas trechos. Para enxergar o quadro completo, você precisa do conteúdo integral do post, dos detalhes do autor e de todos os dados relacionados. A Thunderbit visita automaticamente cada subpágina vinculada, extrai as informações e adiciona tudo como novas colunas, para que você capture facilmente post_id, post_date e muito mais sem cliques manuais.
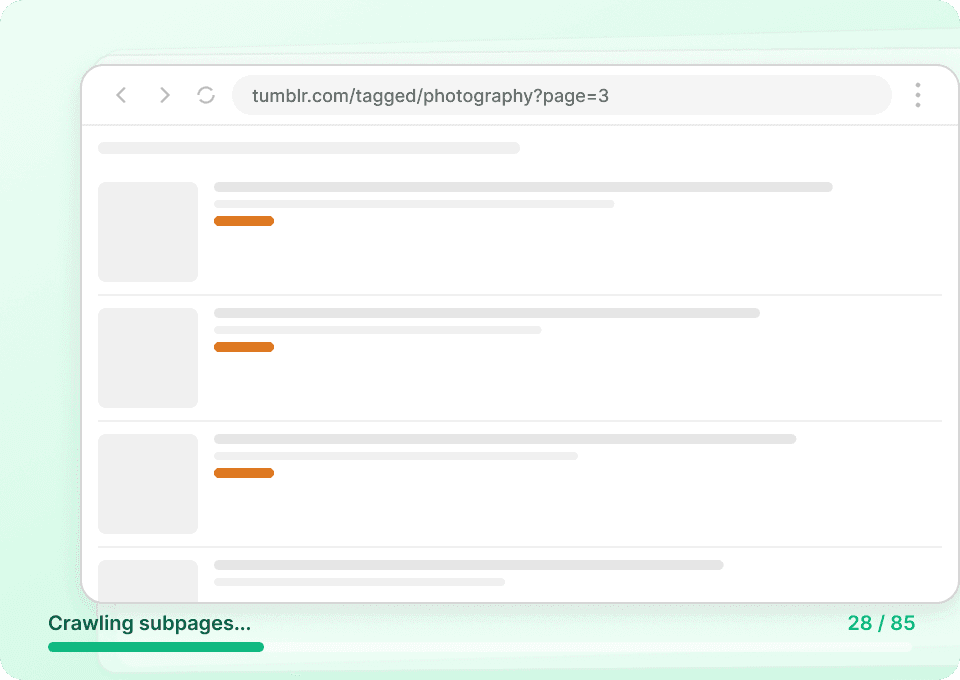
Automatize sua coleta de dados do Tumblr
Os dados do Tumblr estão sempre mudando. Fazer scraping manual dos mesmos blogs repetidamente dá trabalho. Com o scraping agendado da Thunderbit, você configura tarefas recorrentes no piloto automático. Receba dados atualizados, como like_count e post_content, diretamente no Google Sheets sem levantar um dedo.
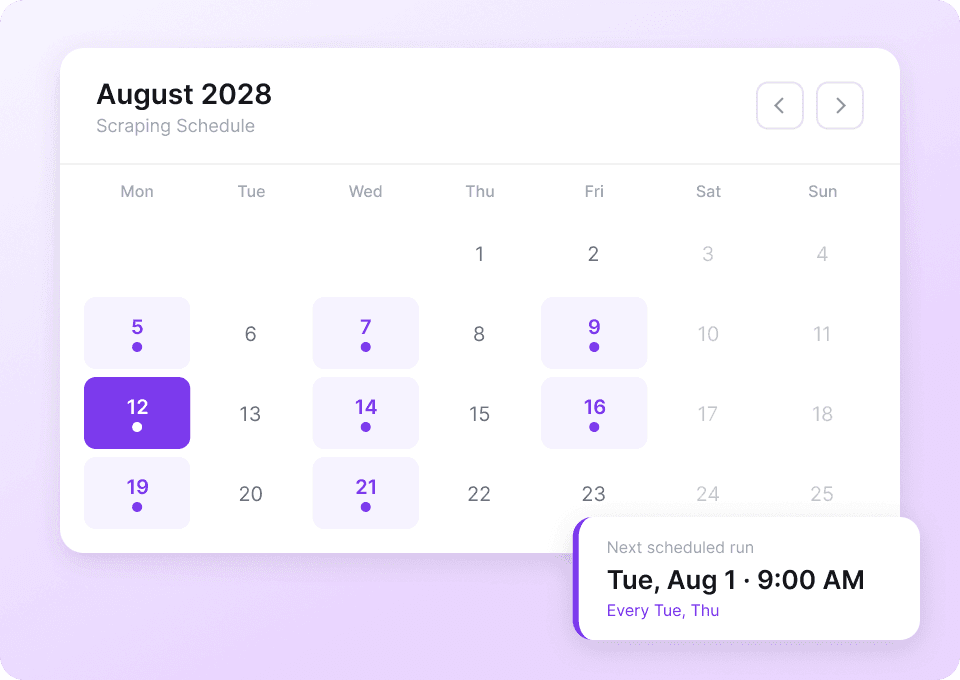
Extraia posts do Tumblr em dois cliques
Esqueça códigos complicados ou seletores CSS. A Thunderbit permite extrair dados do Tumblr em apenas dois cliques. Basta apontar para os dados desejados, e a IA semântica da Thunderbit identifica os campos relevantes, como post_type e post_author, e faz a extração. Sem programação para obter os dados de que você precisa no Tumblr.
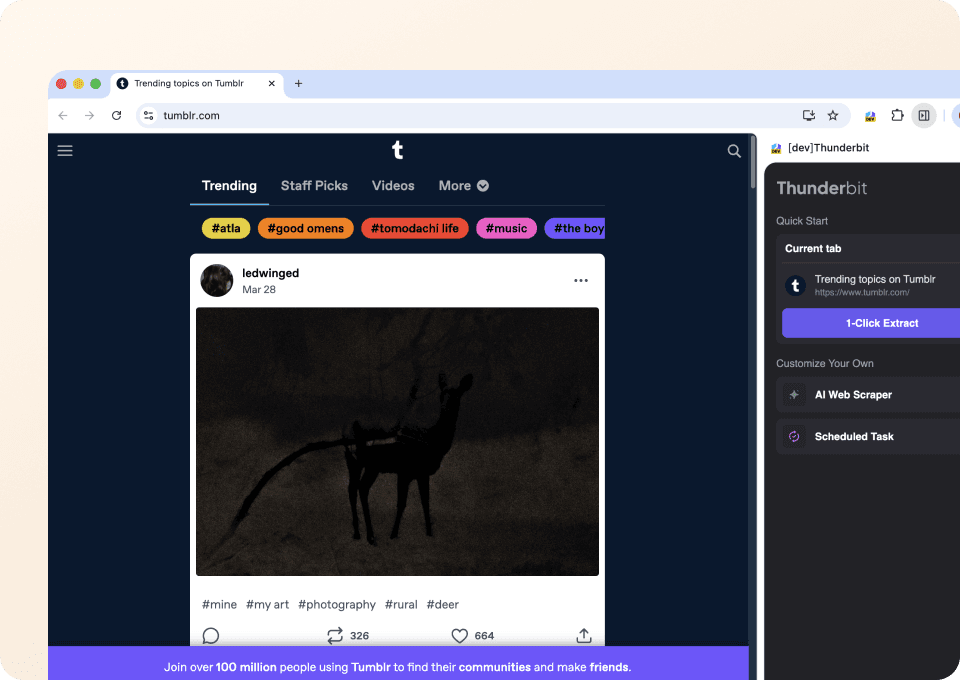
Por que a Thunderbit é diferente dos tumblr scrapers tradicionais?
Extraia dados do Tumblr sem esforço, mesmo quando os layouts mudam ou sofrem alterações inesperadas.
Scrapers tradicionais
O jeito antigo de fazer as coisasThunderbit AI
A abordagem mais inteligenteNão acredite só na nossa palavra
Veja o que nossos usuários dizem sobre o Thunderbit.







Perguntas frequentes
Relacionados casos de uso
Explore mais casos de uso do web scraper da Thunderbit.

Raspador Herold
O Raspador Herold da Thunderbit permite extrair dados dos resultados de busca de empresas e pessoas do Herold em apenas 2 cliques. Utilize sugestões inteligentes de campos com IA para coletar nomes de empresas, endereços, telefones, e-mails e muito mais para geração de leads, pesquisas ou marketing. Perfeito para equipes de vendas, profissionais de marketing e pesquisadores que precisam de dados estruturados do Herold.
Saiba mais ->
Raspador de Páginas Brancas
O Raspador Web White Pages da Thunderbit permite extrair dados de listas telefônicas e comerciais do White Pages com sugestões inteligentes de campos via IA. Colete nomes, telefones, endereços e sites para geração de leads, marketing ou pesquisas em poucos cliques.
Saiba mais ->
Raspador UpCity
O Raspador UpCity da Thunderbit permite extrair dados das listagens de agências de publicidade e avaliações de provedores do UpCity. Utilize sugestões de campos com IA para coletar rapidamente nomes de agências, localizações, avaliações, informações de contato e conteúdos detalhados de avaliações para análise ou pesquisa. Perfeito para profissionais de marketing, pesquisadores e empresários que precisam de dados estruturados do UpCity.
Saiba mais ->
Raspador Web UNIQLO
Extraia dados de produtos da UNIQLO, como nomes, preços e tamanhos disponíveis, em apenas 2 cliques com a extensão do Chrome da Thunderbit.
Saiba mais ->Raspador DialIndia
O Raspador DialIndia da Thunderbit permite extrair dados dos perfis comerciais e diretórios de viagens do DialIndia com sugestões de campos inteligentes por IA. Colete nomes de empresas, informações de contato, localizações e descrições para pesquisas, marketing ou geração de leads em poucos cliques.
Saiba mais ->Raspador Web Tradera
O Raspador Web Tradera da Thunderbit permite extrair dados de anúncios e páginas de produtos do Tradera de forma simples. Com sugestões inteligentes de campos via IA, você coleta nomes de produtos, preços, categorias, imagens e descrições para análise ou gestão de estoque. Ideal para vendedores de e-commerce, colecionadores e pesquisadores que buscam dados estruturados do Tradera.
Saiba mais ->Pronto para turbinar sua extração de dados?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
O teste grátis oferece créditos ilimitados para 8 páginas da web.