Raspador Substack

Confiado por profissionais de empresas líderes














Desbloqueie os dados do Substack com a Thunderbit
Envie dados do Substack diretamente para seus aplicativos
Pare de copiar e colar manualmente detalhes de publicações do Substack, como nome do autor, título do artigo e contagem de assinantes. Com a Thunderbit, um único clique envia os dados extraídos diretamente para Google Sheets, Notion ou Airtable. Analise tendências de publicações e desempenho de conteúdo sem o trabalho manual cansativo.
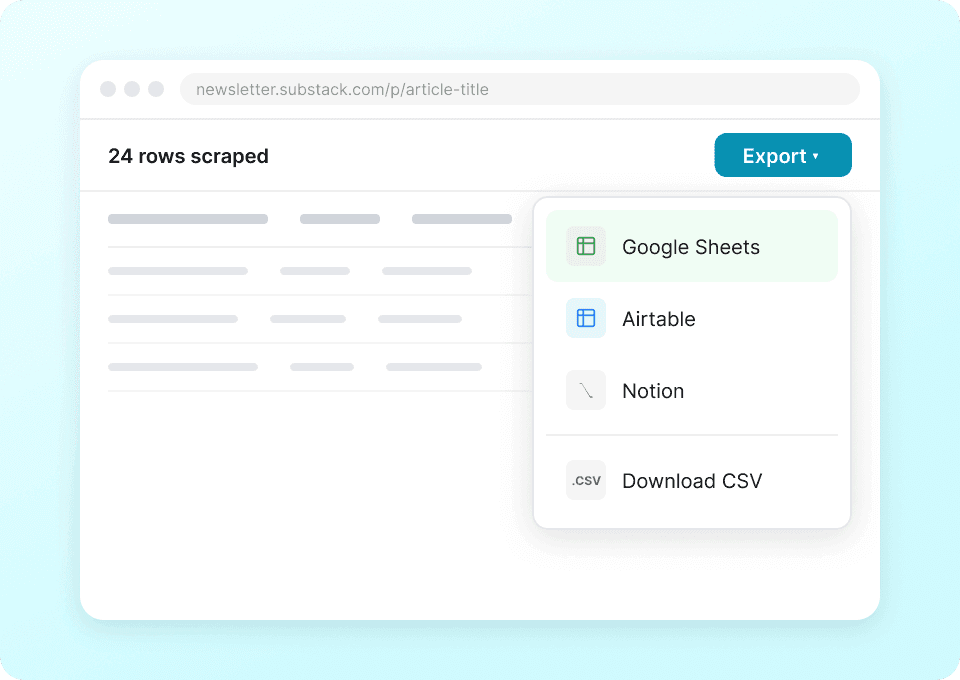
Um único raspador para o Substack e muito mais
Não fique preso usando um raspador diferente para cada site. A Thunderbit funciona no Substack imediatamente, e inclui mais de 50 modelos prontos para outras plataformas populares. Extraia descrições de publicações, conteúdo de artigos e muito mais, e depois use a mesma ferramenta para coletar dados de qualquer outro lugar.
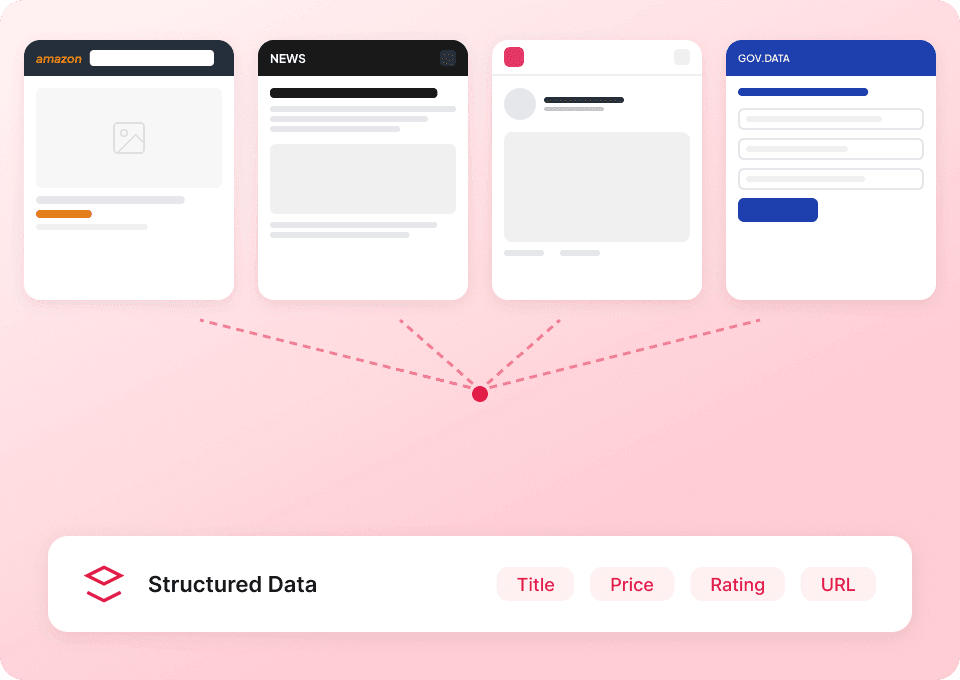
Tenha a história completa do Substack
As páginas de listagem de publicações do Substack mostram apenas resumos. A Thunderbit visita automaticamente cada subpágina de artigo para extrair o conteúdo completo, entregando um conjunto de dados completo. Obtenha o título completo do artigo, nome do autor, nome da publicação e conteúdo do artigo de uma só vez.
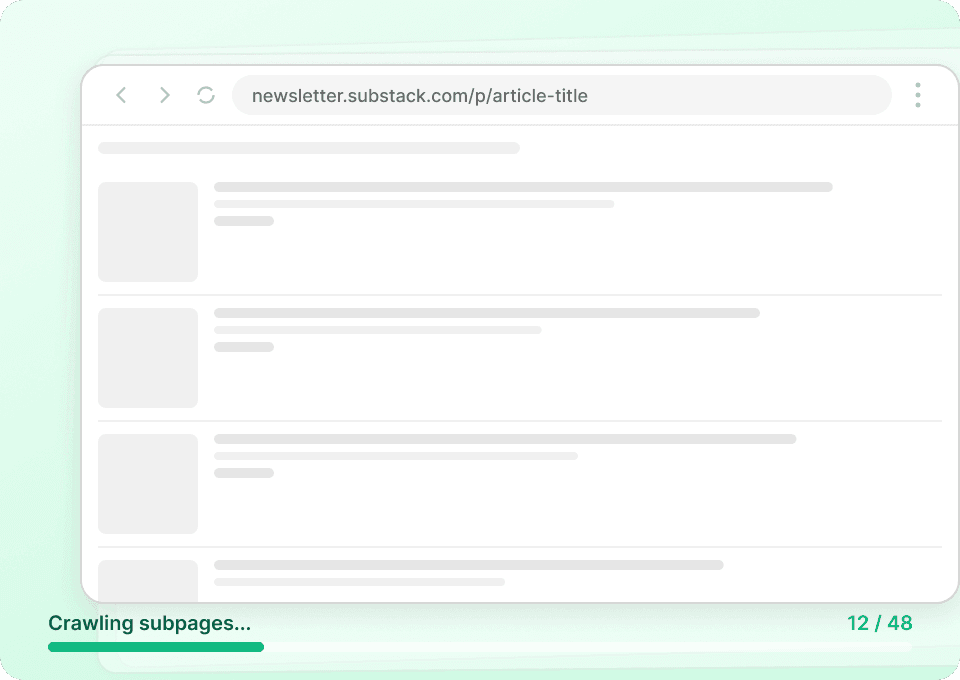
Tem dificuldade para extrair dados do Substack com eficiência?
Veja por que a Thunderbit supera os raspadores tradicionais para dados do Substack.
Raspadores tradicionais
A maneira antiga de fazer as coisasThunderbit
A abordagem mais inteligenteNão acredite só na nossa palavra
Veja o que nossos usuários dizem sobre a Thunderbit.








Perguntas frequentes
Relacionados casos de uso
Explore mais casos de uso do web scraper da Thunderbit.

Raspador iBegin
O Raspador iBegin da Thunderbit permite extrair resultados de buscas e informações detalhadas de empresas diretamente do site iBegin. Com sugestões inteligentes de campos baseadas em IA, você coleta rapidamente nomes de empresas, contatos, endereços, avaliações e muito mais para geração de leads, pesquisas ou análises de marketing.
Saiba mais ->
Raspador Tieba
O Raspador Web Tieba da Thunderbit permite extrair dados do Baidu Tieba, incluindo tópicos em alta e categorias de fóruns. Aproveite sugestões inteligentes de campos com IA para coletar rapidamente nomes de tópicos, URLs, número de postagens e atividade de usuários, seja para pesquisa, marketing ou criação de conteúdo. Perfeito para analisar tendências e discussões nas redes sociais do Tieba.
Saiba mais ->
Raspador Web UNIQLO
Extraia dados de produtos da UNIQLO, como nomes, preços e tamanhos disponíveis, em apenas 2 cliques com a extensão do Chrome da Thunderbit.
Saiba mais ->Raspador PeopleWhiz
O Raspador PeopleWhiz da Thunderbit permite extrair dados de resultados de pesquisa e perfis do PeopleWhiz com sugestões de campos com IA. Reúna nomes, contatos, locais e muito mais para pesquisa, marketing ou geração de leads. Transforme dados do PeopleWhiz em conjuntos estruturados de forma rápida e eficiente.
Saiba mais ->
Raspador Amarillas.com
O Raspador Web Amarillas.com da Thunderbit permite extrair dados estruturados do Amarillas.com, incluindo listagens de motéis e restaurantes. Aproveite sugestões inteligentes de campos com IA para coletar rapidamente nomes de empresas, endereços, telefones, avaliações e comentários para pesquisas, marketing ou geração de leads.
Saiba mais ->
Raspador de Listagens de Negócios do TripAdvisor
O Raspador de Listagens de Negócios do TripAdvisor da Thunderbit permite extrair dados das listagens de empresas, central de recursos e fórum de proprietários do TripAdvisor. Utilize sugestões de campos com IA para coletar rapidamente nomes de recursos, URLs, descrições, tópicos de fóruns, autores e conteúdos de postagens para pesquisa, marketing ou análise.
Saiba mais ->Pronto para turbinar sua extração de dados?
Junte-se a mais de 100.000 profissionais que já usam a Thunderbit para automatizar seus fluxos de web scraping.
O teste grátis oferece créditos ilimitados para 8 páginas.