Raspador Pixiv
Confiado por profissionais de empresas líderes














Extração de dados do Pixiv de forma simples
Extraia dados do Pixiv, como títulos, autores e detalhes de seção, sem copiar e colar manualmente.
Extraia dados do Pixiv em massa e em escala
Coletar dados do Pixiv manualmente, página por página, fica lento rapidamente, especialmente quando você precisa de dezenas ou centenas de títulos, resumos de artigos, autores, datas de publicação, fontes da notícia e seções. A Thunderbit permite extrair uma lista de URLs de uma só vez, para você passar de algumas páginas para um grande conjunto de registros do Pixiv sem perder tempo com trabalho repetitivo.

Capture detalhes completos das subpáginas do Pixiv
As páginas de listagem no Pixiv geralmente mostram apenas o básico, enquanto os detalhes reais ficam dentro de cada subpágina de artigo ou postagem. A Thunderbit visita cada subpágina vinculada e recupera a visão completa, entregando dados mais ricos, como resumo do artigo, autor, data de publicação, fonte da notícia e seção, em uma estrutura limpa.
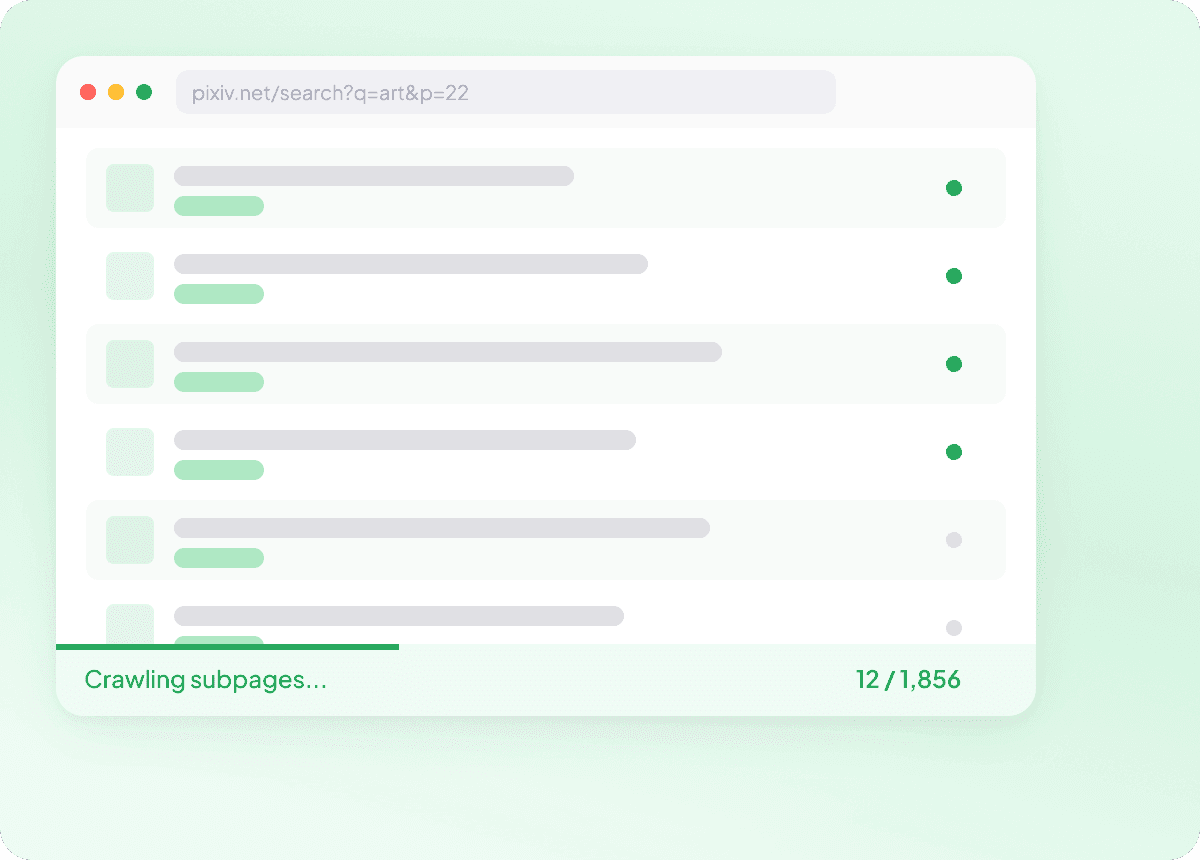
Mantenha os dados do Pixiv sempre atualizados no piloto automático
O conteúdo do Pixiv pode mudar diariamente, e acompanhar isso manualmente significa verificar as mesmas páginas repetidamente. Com a extração agendada, a Thunderbit funciona no piloto automático e entrega dados novos do Pixiv para a sua planilha em intervalos recorrentes, para que o acompanhamento de títulos, autores e seções permaneça atualizado sem esforço.
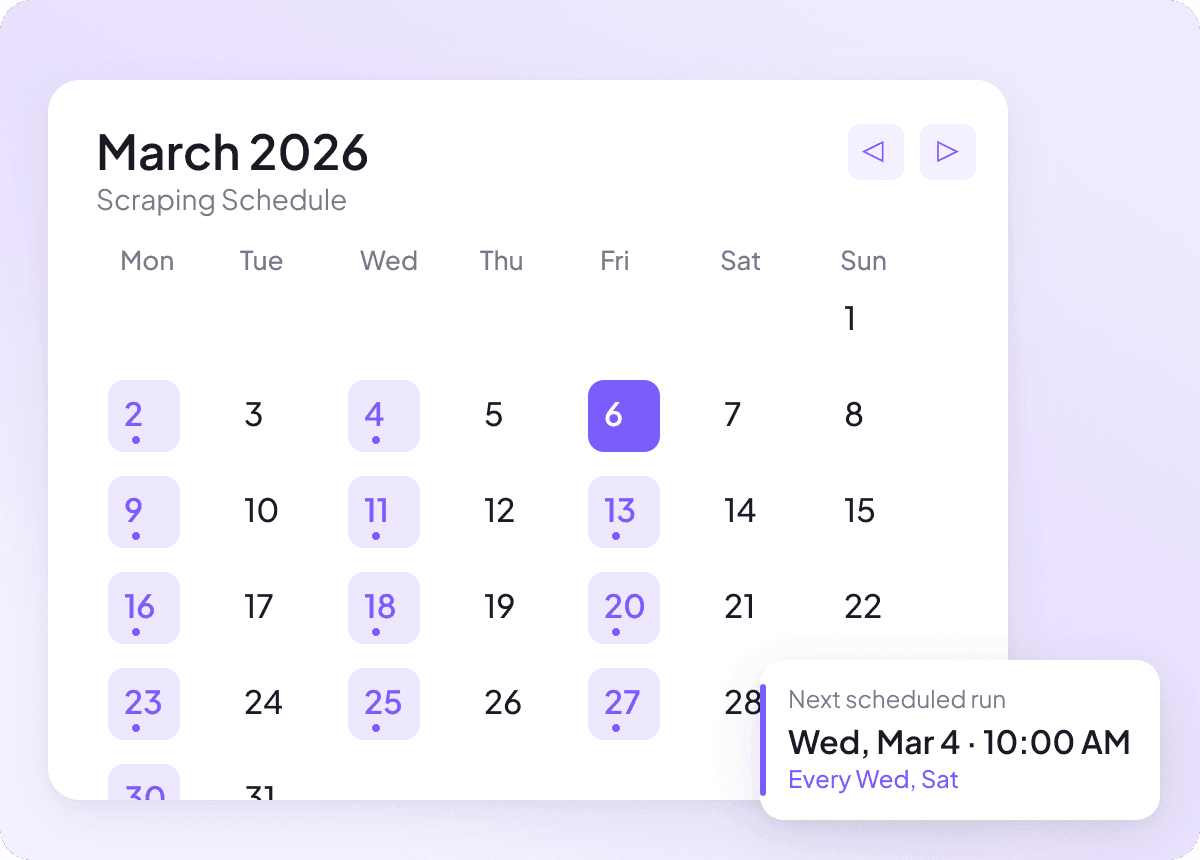
Por que a Thunderbit é diferente dos raspadores de Pixiv tradicionais?
Uma maneira mais simples de extrair o Pixiv sem seletores frágeis nem limpeza.
Raspadores tradicionais
A forma antiga de fazer as coisasThunderbit IA
A abordagem mais inteligenteNão acredite só na nossa palavra
Veja o que nossos usuários dizem sobre o Thunderbit.








Perguntas frequentes
Relacionados casos de uso
Explore mais casos de uso do web scraper da Thunderbit.

Raspador Web UNIQLO
Extraia dados de produtos da UNIQLO, como nomes, preços e tamanhos disponíveis, em apenas 2 cliques com a extensão do Chrome da Thunderbit.
Saiba mais ->Raspador DialIndia
O Raspador DialIndia da Thunderbit permite extrair dados dos perfis comerciais e diretórios de viagens do DialIndia com sugestões de campos inteligentes por IA. Colete nomes de empresas, informações de contato, localizações e descrições para pesquisas, marketing ou geração de leads em poucos cliques.
Saiba mais ->
Raspador UpCity
O Raspador UpCity da Thunderbit permite extrair dados das listagens de agências de publicidade e avaliações de provedores do UpCity. Utilize sugestões de campos com IA para coletar rapidamente nomes de agências, localizações, avaliações, informações de contato e conteúdos detalhados de avaliações para análise ou pesquisa. Perfeito para profissionais de marketing, pesquisadores e empresários que precisam de dados estruturados do UpCity.
Saiba mais ->Raspador Web Tradera
O Raspador Web Tradera da Thunderbit permite extrair dados de anúncios e páginas de produtos do Tradera de forma simples. Com sugestões inteligentes de campos via IA, você coleta nomes de produtos, preços, categorias, imagens e descrições para análise ou gestão de estoque. Ideal para vendedores de e-commerce, colecionadores e pesquisadores que buscam dados estruturados do Tradera.
Saiba mais ->
Raspador Web HKTVmall
Colete nomes de produtos, preços e até avaliações de clientes em listas da HKTVmall com apenas alguns cliques — sem configurações complexas.
Saiba mais ->
Raspador Tieba
O Raspador Web Tieba da Thunderbit permite extrair dados do Baidu Tieba, incluindo tópicos em alta e categorias de fóruns. Aproveite sugestões inteligentes de campos com IA para coletar rapidamente nomes de tópicos, URLs, número de postagens e atividade de usuários, seja para pesquisa, marketing ou criação de conteúdo. Perfeito para analisar tendências e discussões nas redes sociais do Tieba.
Saiba mais ->Pronto para turbinar sua extração de dados?
Junte-se a mais de 100.000 profissionais que já usam o Thunderbit para automatizar seus fluxos de web scraping.
O teste grátis oferece créditos ilimitados para 8 páginas da web.