Raspador de Notícias

Confiado por profissionais de empresas líderes














Dados de notícias, capturados mais rápido
Extraia dados limpos de notícias a partir de artigos, listagens e fontes sem o trabalho manual.
Obtenha o detalhe completo do artigo
As páginas de listagem de notícias só mostram um teaser. A Thunderbit visita cada subpágina do artigo e traz o quadro completo, incluindo título, resumo do artigo, autor, data de publicação, fonte da notícia e seção. Isso permite passar de uma simples lista de matérias para um conjunto de dados completo em menos etapas.
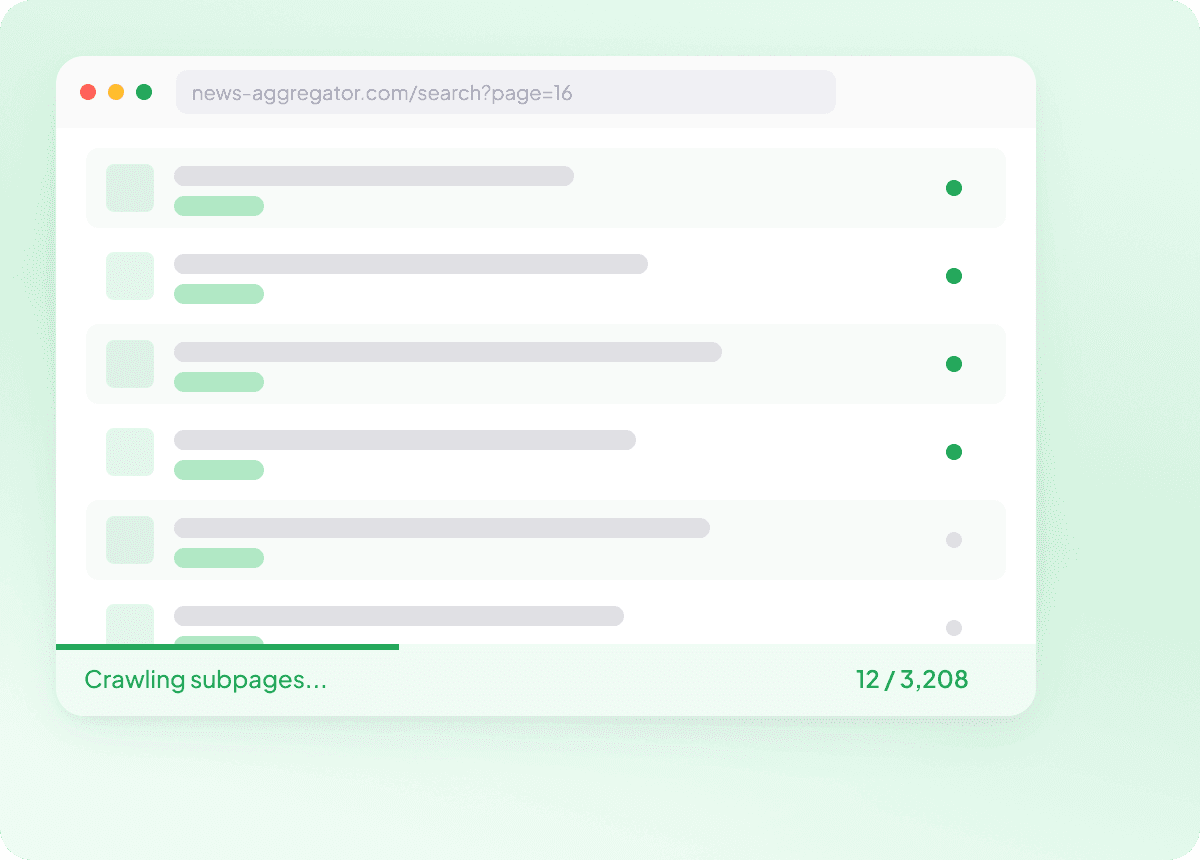
Extraia em massa listas de URLs de Notícias
Extrair notícias uma página de cada vez fica lento rapidamente. Com a Thunderbit, você pode fornecer uma lista de URLs de artigos e extrair em massa centenas de páginas de uma só vez, para que cada matéria seja capturada com os campos de que você precisa. É uma forma prática de coletar grandes conjuntos de dados de notícias sem repetir o mesmo trabalho.

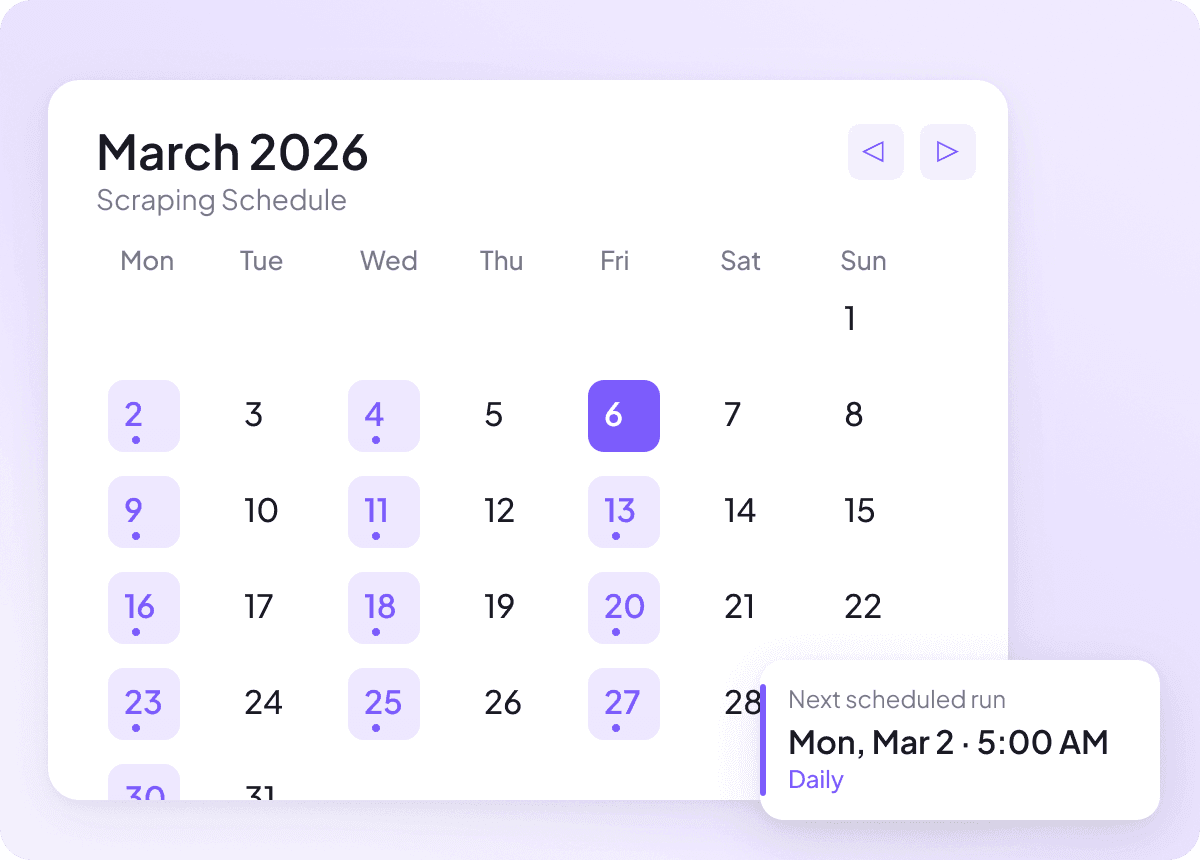
Mantenha os dados de Notícias sempre atualizados
As notícias mudam todos os dias, e dados desatualizados não servem para nada. Configure a extração agendada para que a Thunderbit funcione no piloto automático e mantenha sua planilha atualizada com títulos, resumos, autores, datas de publicação, fontes e seções recentes. Você recebe atualizações recorrentes sem precisar se lembrar da tarefa.
Por que a Thunderbit é diferente dos raspadores de notícias tradicionais?
Uma forma mais rápida de coletar dados de notícias desorganizados sem que tudo quebre o tempo todo.
Raspadores tradicionais
A forma antiga de fazer as coisasThunderbit IA
A abordagem mais inteligenteNão acredite só na nossa palavra
Veja o que nossos usuários dizem sobre a Thunderbit.







Perguntas frequentes
Relacionados casos de uso
Explore mais casos de uso do web scraper da Thunderbit.

Raspador ReverseAustralia
O Raspador Web ReverseAustralia da Thunderbit permite extrair dados das páginas de reclamações e comentários do ReverseAustralia. Utilize sugestões inteligentes de campos com IA para coletar rapidamente números de telefone, descrições de reclamações, textos de comentários, nomes de usuários e muito mais para análise ou pesquisa. Perfeito para profissionais de marketing, pesquisadores e empresas que buscam dados estruturados de feedback.
Saiba mais ->Raspador Substack
Obtenha contagens de assinantes do Substack, títulos de artigos e descrições de publicações em uma planilha limpa — sem código, a IA faz a estruturação.
Saiba mais ->
Raspador de Rakuten Travel
O Raspador Web Rakuten Travel da Thunderbit permite extrair dados das listagens e páginas de detalhes de hotéis do Rakuten Travel. Utilize sugestões inteligentes de campos com IA para coletar rapidamente nomes de hotéis, preços, avaliações, tipos de quarto e comodidades, seja para pesquisa ou planejamento de viagens. Perfeito para agentes de viagem, pesquisadores e empresas que precisam de dados estruturados do setor de turismo.
Saiba mais ->
Raspador UpCity
O Raspador UpCity da Thunderbit permite extrair dados das listagens de agências de publicidade e avaliações de provedores do UpCity. Utilize sugestões de campos com IA para coletar rapidamente nomes de agências, localizações, avaliações, informações de contato e conteúdos detalhados de avaliações para análise ou pesquisa. Perfeito para profissionais de marketing, pesquisadores e empresários que precisam de dados estruturados do UpCity.
Saiba mais ->Raspador DialIndia
O Raspador DialIndia da Thunderbit permite extrair dados dos perfis comerciais e diretórios de viagens do DialIndia com sugestões de campos inteligentes por IA. Colete nomes de empresas, informações de contato, localizações e descrições para pesquisas, marketing ou geração de leads em poucos cliques.
Saiba mais ->Raspador Web Tradera
O Raspador Web Tradera da Thunderbit permite extrair dados de anúncios e páginas de produtos do Tradera de forma simples. Com sugestões inteligentes de campos via IA, você coleta nomes de produtos, preços, categorias, imagens e descrições para análise ou gestão de estoque. Ideal para vendedores de e-commerce, colecionadores e pesquisadores que buscam dados estruturados do Tradera.
Saiba mais ->Pronto para turbinar sua extração de dados?
Junte-se a mais de 100.000 profissionais que já usam a Thunderbit para automatizar seus fluxos de web scraping.
O teste grátis oferece créditos ilimitados para 8 páginas.