Raspador Web IDCrawl
Confiado por profissionais de empresas líderes














Dados do Idcrawl que continuam utilizáveis
Use o idcrawl para extrair dados com mais rapidez, limpeza e escala com o Thunderbit.
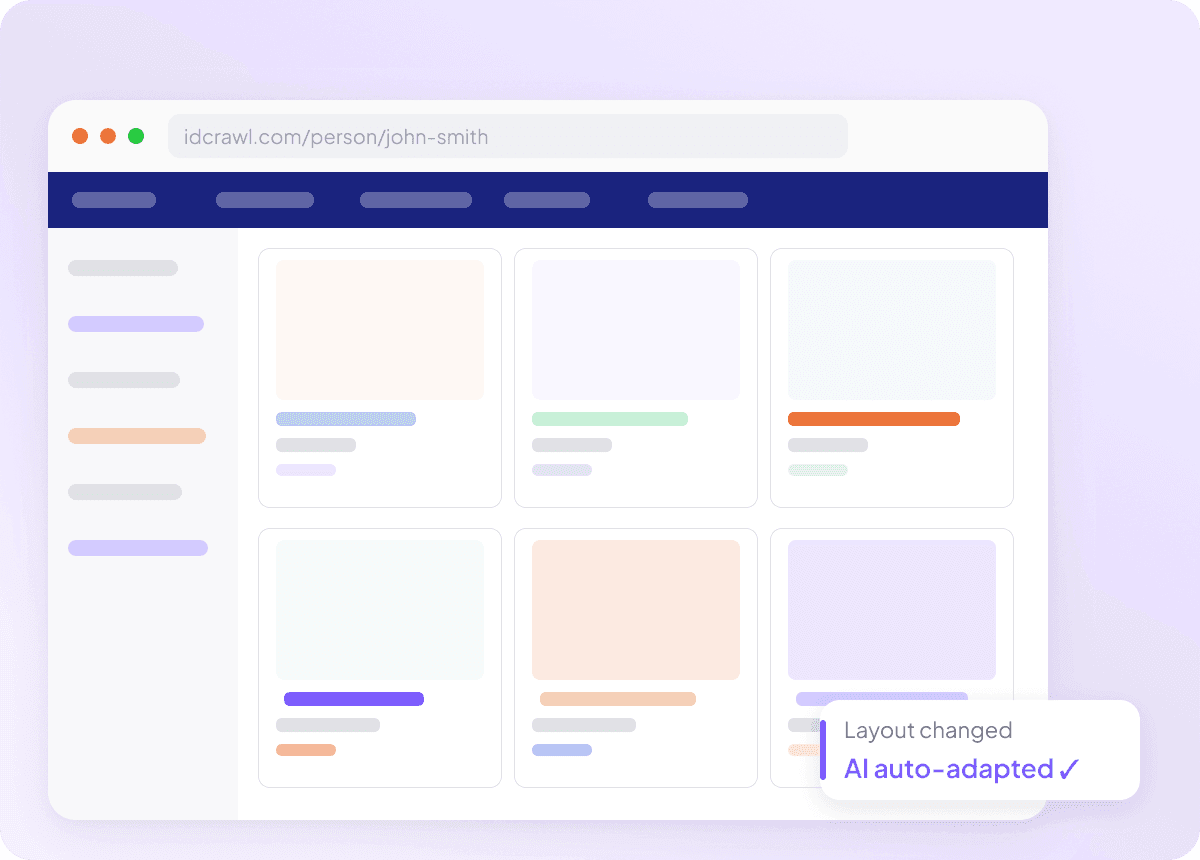
Se adapta quando o Idcrawl muda
Raspadores que quebram a cada atualização do site não servem para nada, especialmente quando você está tentando extrair nome completo, cargo, nome da empresa, endereço de e-mail, número de telefone e perfil do LinkedIn do idcrawl. O Thunderbit lê a página pelo significado, não por seletores fixos, então consegue se adaptar quando o layout muda. Você gasta menos tempo corrigindo raspadores e mais tempo obtendo os dados de que precisa.
Dados limpos desde o início
Dados brutos são só o começo do trabalho real, e os resultados do idcrawl muitas vezes precisam de limpeza antes de serem úteis. O Thunderbit estrutura e formata os dados durante a extração, então o que você exporta já está limpo e pronto para uso. Isso significa menos organização, menos retrabalho e uma entrega mais fluida para a sua equipe.
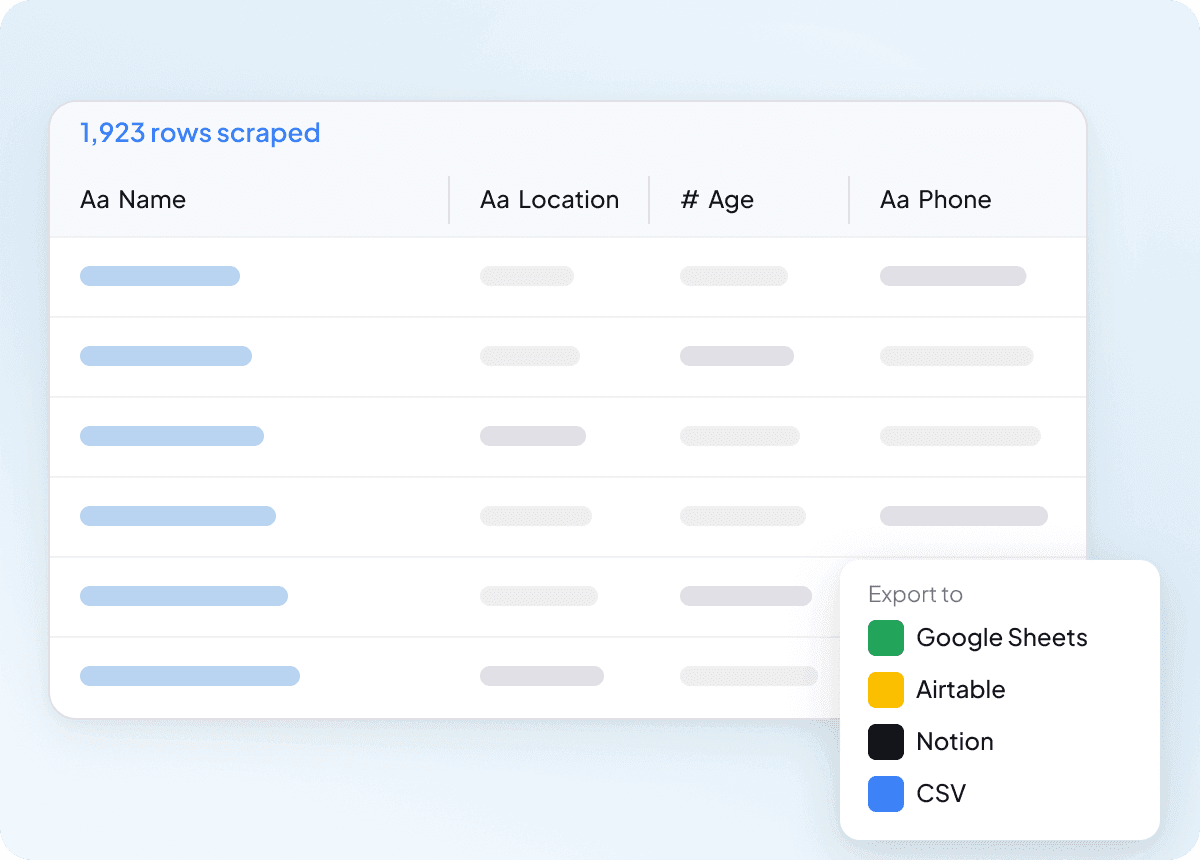
Extraia em massa do Idcrawl de uma só vez
Extrair uma página do idcrawl por vez não escala quando você precisa de uma lista longa de contatos. O Thunderbit pode extrair em massa centenas de páginas de uma só vez, para que você possa fornecer uma lista de URLs e extrair nome completo, cargo, nome da empresa, endereço de e-mail, número de telefone e perfil do LinkedIn em todas elas. É uma forma muito mais fácil de transformar uma grande lista em dados utilizáveis.

Por que o Thunderbit é diferente dos raspadores de idcrawl tradicionais?
Uma forma mais simples de extrair dados do idcrawl sem correções constantes.
Raspadores tradicionais
O jeito antigo de fazer as coisasThunderbit IA
A abordagem mais inteligenteNão acredite só na nossa palavra
Veja o que nossos usuários dizem sobre o Thunderbit.







Perguntas frequentes
Relacionados casos de uso
Explore mais casos de uso do web scraper da Thunderbit.

Raspador Amarillas.com
O Raspador Web Amarillas.com da Thunderbit permite extrair dados estruturados do Amarillas.com, incluindo listagens de motéis e restaurantes. Aproveite sugestões inteligentes de campos com IA para coletar rapidamente nomes de empresas, endereços, telefones, avaliações e comentários para pesquisas, marketing ou geração de leads.
Saiba mais ->
Raspador Web HKTVmall
Colete nomes de produtos, preços e até avaliações de clientes em listas da HKTVmall com apenas alguns cliques — sem configurações complexas.
Saiba mais ->Raspador Web Tradera
O Raspador Web Tradera da Thunderbit permite extrair dados de anúncios e páginas de produtos do Tradera de forma simples. Com sugestões inteligentes de campos via IA, você coleta nomes de produtos, preços, categorias, imagens e descrições para análise ou gestão de estoque. Ideal para vendedores de e-commerce, colecionadores e pesquisadores que buscam dados estruturados do Tradera.
Saiba mais ->
Raspador ReverseAustralia
O Raspador Web ReverseAustralia da Thunderbit permite extrair dados das páginas de reclamações e comentários do ReverseAustralia. Utilize sugestões inteligentes de campos com IA para coletar rapidamente números de telefone, descrições de reclamações, textos de comentários, nomes de usuários e muito mais para análise ou pesquisa. Perfeito para profissionais de marketing, pesquisadores e empresas que buscam dados estruturados de feedback.
Saiba mais ->Raspador Substack
Obtenha contagens de assinantes do Substack, títulos de artigos e descrições de publicações em uma planilha limpa — sem código, a IA faz a estruturação.
Saiba mais ->Raspador DialIndia
O Raspador DialIndia da Thunderbit permite extrair dados dos perfis comerciais e diretórios de viagens do DialIndia com sugestões de campos inteligentes por IA. Colete nomes de empresas, informações de contato, localizações e descrições para pesquisas, marketing ou geração de leads em poucos cliques.
Saiba mais ->Pronto para turbinar sua extração de dados?
Junte-se a mais de 100.000 profissionais que já usam o Thunderbit para automatizar seus fluxos de web scraping.
O teste grátis oferece créditos ilimitados para 8 páginas da web.