Raspador do Goodreads
Confiado por profissionais de empresas líderes














Extraia dados do Goodreads em segundos, não em horas
Dois cliques para raspar dados do Goodreads
Cansado de copiar manualmente títulos de livros, nomes de autores, avaliações e contagem de páginas do Goodreads? A Thunderbit permite extrair dados em apenas dois cliques. Sem programação nem configuração complicada. Basta apontar para os dados desejados, e nossa IA detecta automaticamente os campos e os extrai.
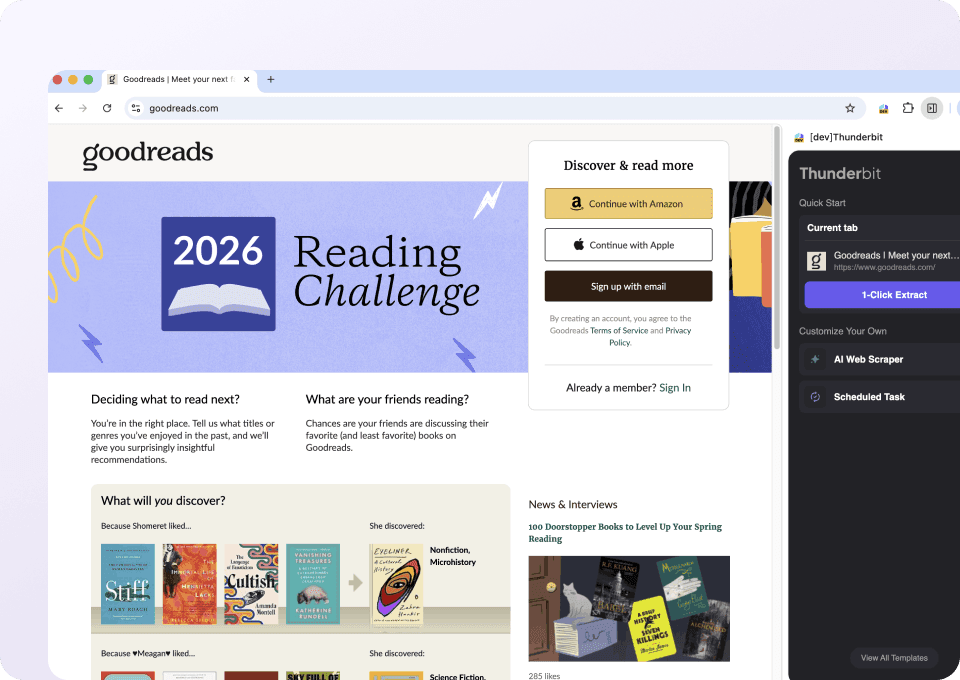
Dados do Goodreads limpos e prontos para usar
Os dados do Goodreads podem ser confusos. A Thunderbit limpa e estrutura automaticamente os dados enquanto os extrai. Imagine receber uma planilha do Google perfeitamente formatada com títulos de livros, autores, avaliação média, número de avaliações e número de páginas, tudo pronto para sua análise — sem mais limpeza manual.
Raspe centenas de páginas do Goodreads
Fazer scraping do Goodreads manualmente, uma página por vez, é tedioso e demorado. A Thunderbit pode raspar automaticamente centenas de páginas do Goodreads de uma só vez. Basta fornecer uma lista de URLs, e ela extrairá rapidamente e com eficiência os dados dos livros, autores ou qualquer outra informação de que você precise.

Fazer scraping do Goodreads está te desgastando?
Veja como a Thunderbit simplifica a extração de dados do Goodreads.
Raspadores tradicionais
O jeito antigo de fazer as coisasThunderbit
A abordagem mais inteligenteNão acredite só na nossa palavra
Veja o que nossos usuários dizem sobre o Thunderbit.







Perguntas frequentes
Relacionados casos de uso
Explore mais casos de uso do web scraper da Thunderbit.
Raspador PeopleWhiz
O Raspador PeopleWhiz da Thunderbit permite extrair dados de resultados de pesquisa e perfis do PeopleWhiz com sugestões de campos com IA. Reúna nomes, contatos, locais e muito mais para pesquisa, marketing ou geração de leads. Transforme dados do PeopleWhiz em conjuntos estruturados de forma rápida e eficiente.
Saiba mais ->
Raspador iBegin
O Raspador iBegin da Thunderbit permite extrair resultados de buscas e informações detalhadas de empresas diretamente do site iBegin. Com sugestões inteligentes de campos baseadas em IA, você coleta rapidamente nomes de empresas, contatos, endereços, avaliações e muito mais para geração de leads, pesquisas ou análises de marketing.
Saiba mais ->
Raspador United Airlines
Aponte e clique para coletar dados de voos da United Airlines, como número do voo, horário de chegada e aeroporto de partida — a IA do Thunderbit faz o resto.
Saiba mais ->
Raspador de Listagens de Negócios do TripAdvisor
O Raspador de Listagens de Negócios do TripAdvisor da Thunderbit permite extrair dados das listagens de empresas, central de recursos e fórum de proprietários do TripAdvisor. Utilize sugestões de campos com IA para coletar rapidamente nomes de recursos, URLs, descrições, tópicos de fóruns, autores e conteúdos de postagens para pesquisa, marketing ou análise.
Saiba mais ->
Raspador de Rakuten Travel
O Raspador Web Rakuten Travel da Thunderbit permite extrair dados das listagens e páginas de detalhes de hotéis do Rakuten Travel. Utilize sugestões inteligentes de campos com IA para coletar rapidamente nomes de hotéis, preços, avaliações, tipos de quarto e comodidades, seja para pesquisa ou planejamento de viagens. Perfeito para agentes de viagem, pesquisadores e empresas que precisam de dados estruturados do setor de turismo.
Saiba mais ->
Raspador Tieba
O Raspador Web Tieba da Thunderbit permite extrair dados do Baidu Tieba, incluindo tópicos em alta e categorias de fóruns. Aproveite sugestões inteligentes de campos com IA para coletar rapidamente nomes de tópicos, URLs, número de postagens e atividade de usuários, seja para pesquisa, marketing ou criação de conteúdo. Perfeito para analisar tendências e discussões nas redes sociais do Tieba.
Saiba mais ->Pronto para turbinar sua extração de dados?
Junte-se a mais de 100.000 profissionais que já usam o Thunderbit para automatizar seus fluxos de web scraping.
O teste grátis oferece créditos ilimitados para 8 páginas da web.