
Sejamos honestos: a web é um lugar selvagem — muito selvagem. Todos os dias, sinto-me como se estivesse à frente de uma mangueira digital de alta pressão: notícias, avaliações, listas de produtos, tweets, negócios imobiliários, enfim — tudo a jorrar num fluxo confuso e desestruturado. E, se está a gerir um negócio, tentar dar sentido a este caos pode parecer procurar uma agulha num palheiro... enquanto o palheiro arde. (Já passei por isso. Não é nada divertido.)
Mas aqui está o ponto: no meio de toda essa desarrumação online, há ouro puro — insights que podem impulsionar vendas, ultrapassar concorrentes e automatizar as tarefas aborrecidas que ninguém quer fazer. É aqui que entra o web scraping. Com as ferramentas certas, pode transformar esta montanha de dados web desestruturados em folhas de cálculo organizadas e acionáveis, prontas para a sua próxima grande jogada. E, como alguém que passou anos em SaaS e automação, posso dizer: web scraping já não é só para programadores. É para qualquer pessoa que queira trabalhar de forma mais inteligente, e não mais difícil.
Significado de Web Scraping: Transformando o Caos Online em Dados Utilizáveis

Então, afinal, o que é web scraping? Vamos deixar o jargão de lado e falar de forma direta: web scraping é o processo de usar software para extrair informações específicas de sites e convertê-las em formatos estruturados — pense em Excel, Google Sheets ou numa base de dados. Imagine ter um assistente digital que copia, sem parar, exatamente a informação de que precisa de milhares de páginas da web e a organiza por si. Em resumo, isso é web scraping.
Também poderá ouvir o termo “data scraping”. Aqui vai a diferença: data scraping é um termo amplo para recolher dados de qualquer fonte (sites, PDFs, imagens, e por aí fora). Web scraping refere-se especificamente à extração de dados de sites na internet. Por outras palavras, todo web scraping é data scraping, mas nem todo o data scraping é web scraping. (É como dizer que todo o quadrado é um retângulo, mas nem todo o retângulo é um quadrado.)
Se quiser uma definição mais formal, web scraping é “data scraping usado para extrair dados de sites” (Wikipedia). Mas, na prática, é apenas automação para pesquisa online — chega de copiar e colar até doerem os dedos.
Por que o Web Scraping é Importante para as Empresas Modernas
O que é Data Scraping e Como Fazer em 2025 Get Started Free
Vamos falar de negócios. Porque é que o web scraping é tão importante agora? Porque a internet está afogada em dados desestruturados — cerca de 80% a 90% de todos os novos dados são desestruturados, desde publicações nas redes sociais a listas de produtos. A IDC prevê que o volume global de dados chegará aos 175 zettabytes até 2025 — são muitos zeros.
E o mais importante: 60% a 80% do tempo dos colaboradores é desperdiçado apenas a encontrar e preparar dados, e não a analisá-los. É como contratar um chef para descascar batatas o dia inteiro em vez de cozinhar. Como disse Michael Shulman, Head of Machine Learning da Kensho: “Como a maior parte dos dados do mundo é desestruturada, a capacidade de os analisar e agir sobre eles representa uma enorme oportunidade.”
O web scraping inverte este jogo. Em vez de passar horas a vasculhar sites manualmente, automatiza o processo — recolhendo dados em tempo real de qualquer parte da web. Não admira que 71% das empresas de serviços financeiros e mais de metade das empresas de retalho/e-commerce já usem web scraping para dados externos. Dados não são apenas o novo petróleo — são a nova moeda, e o web scraping é a forma de rentabilizá-los.
Casos de Uso Comuns de Web Scraping em Vários Setores
Web scraping não é uma solução de um truque só. É usado em todo o lado — de equipas de vendas a analistas imobiliários. Aqui ficam alguns exemplos reais:
- Leads de Vendas e Prospetação B2B: Extraia vagas de emprego ou diretórios de empresas para criar listas de leads novas e segmentadas. Uma empresa de SaaS viu um aumento de 40% em leads qualificados ao automatizar este processo.
- Preços e Monitorização de Produtos no E-commerce: Os retalhistas extraem preços e stock dos sites dos concorrentes, ajustando os próprios preços quase em tempo real. O resultado? Mais vendas e clientes fiéis.
- Anúncios Imobiliários: Agregadores e investidores extraem de sites imobiliários anúncios, preços e tendências — ajudando a identificar propriedades subvalorizadas e bairros em crescimento (case study).
- Viagens e Hotelaria: Extraia de sites de companhias aéreas e hotéis tarifas, disponibilidade e avaliações — alimentando ferramentas de comparação de preços e análise de sentimento.
- Finanças e Investimento: Fundos hedge extraem tudo, desde documentos da SEC a avaliações de produtos, em busca de sinais de dados alternativos. 71% das empresas financeiras já usam web scraping nas suas operações.
No fim de contas: se houver dados valiosos na web, há uma forma de os extrair e transformá-los em valor para o negócio.
Como o Web Scraping Funciona: Do Site à Planilha
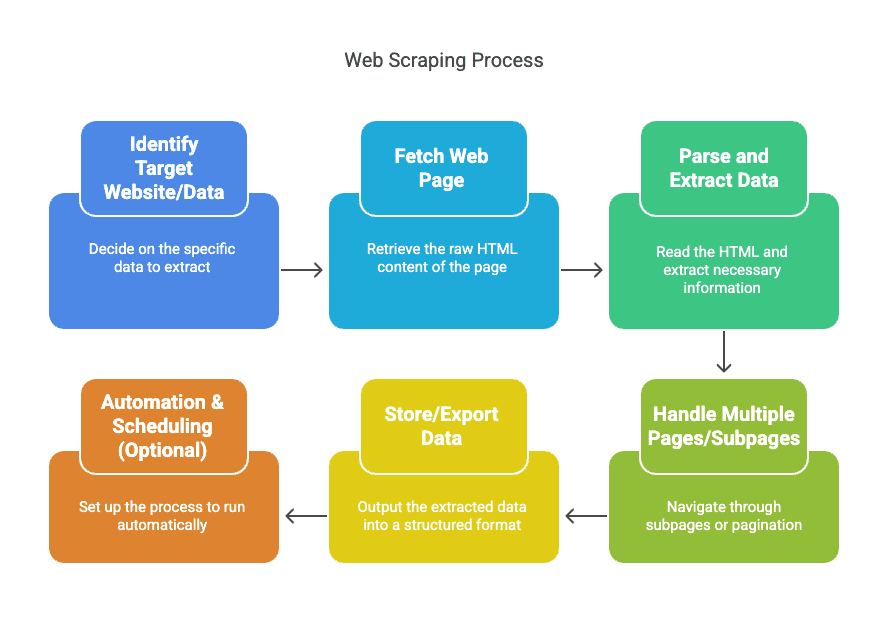
Vamos desmistificar o processo. Web scraping não é magia — é um pipeline. Normalmente, funciona assim:
- Identificar o site/dado-alvo: Decida o que quer (por exemplo, nomes e preços de produtos de xyz).
- Buscar a página da web: O scraper recupera o HTML bruto, exatamente como o seu navegador faz.
- Analisar e extrair os dados: A ferramenta lê o HTML e puxa a informação de que precisa (como preços, nomes e avaliações).
- Lidar com várias páginas/subpáginas: Os scrapers podem seguir links para subpáginas ou avançar automaticamente pela paginação.
- Armazenar/exportar os dados: Exporte tudo para um formato estruturado — CSV, Excel, Google Sheets ou uma base de dados.
- Automação e agendamento (opcional): Configure para correr segundo um horário, mantendo os seus dados sempre atualizados sem esforço.
Fazer isto manualmente levaria uma eternidade (e muito café). Com web scraping, automatiza todo o processo — transformando horas de trabalho braçal em minutos.
O Papel das Ferramentas de Scraping e dos Serviços de Web Scraping
Agora, vamos falar de ferramentas. Há um buffet de opções por aí, desde extensões de navegador a plataformas na nuvem e software de desktop. Aqui vai um resumo rápido:
- Extensões de navegador: Ferramentas leves, de apontar e clicar, que vivem no seu navegador. Ótimas para tarefas rápidas e simples.
- Software de desktop: Aplicações completas com interface visual — lidam com logins, scroll infinito e muito mais.
- Plataformas na nuvem: Executam scrapers em servidores remotos — ideais para tarefas em grande escala e sempre ativas.
- Código personalizado: Para quem é mais técnico — escreva os seus próprios scripts para ter o máximo de controlo (mas também o máximo de dores de cabeça).
Por que usar estas ferramentas em vez de copiar e colar? Três motivos: velocidade, escala e fiabilidade. Um bom scraper pode processar milhares de páginas no tempo que demora a aquecer o almoço no micro-ondas. Além disso, recebe dados limpos e estruturados — sem erros de digitação, sem detalhes perdidos.
Dados Estruturados vs. Desestruturados: Por que o Web Scraping é Essencial
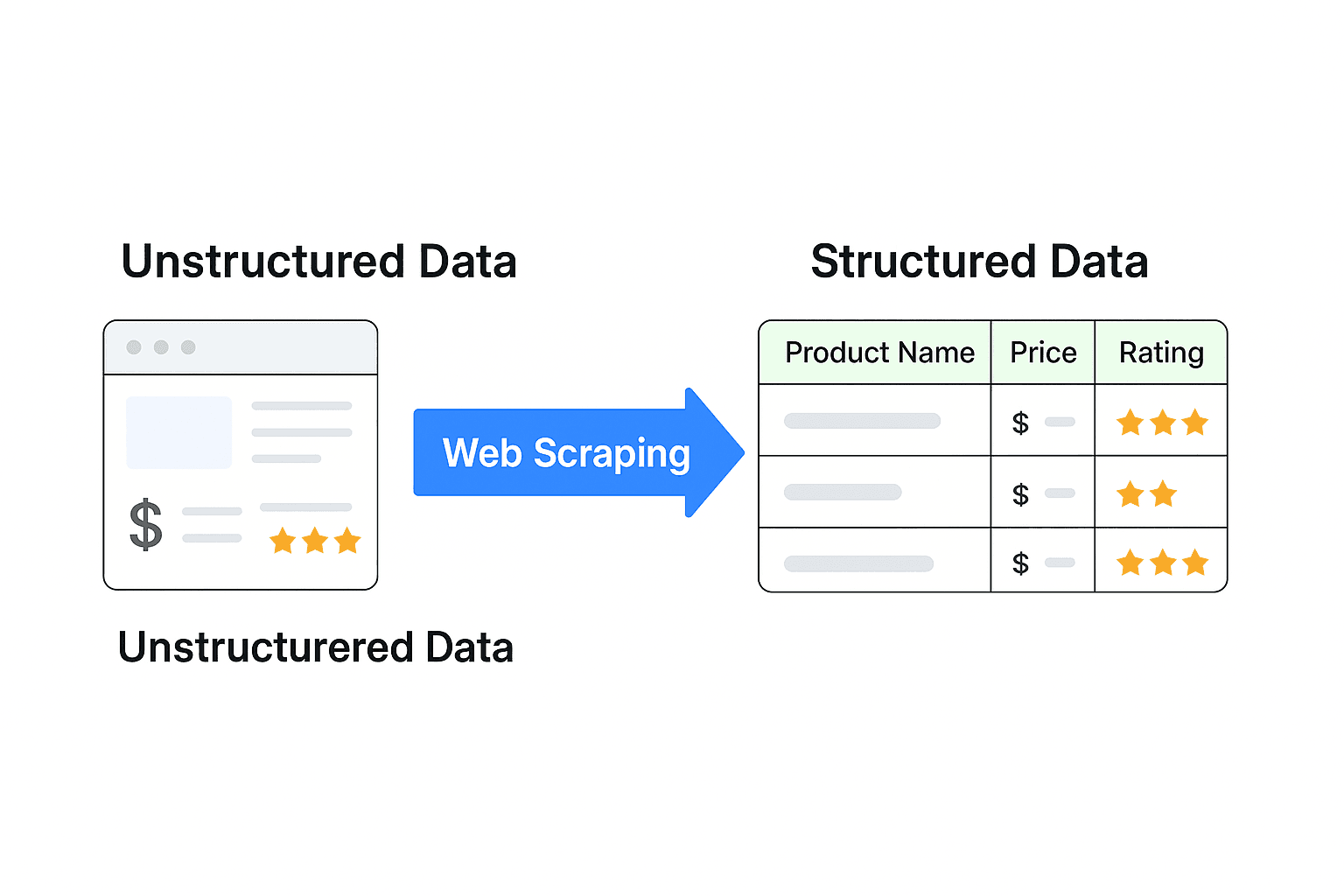
Aqui está o cerne da questão: a maior parte dos dados da web é desestruturada. Foi feita para humanos, não para máquinas. Pense numa página de produto com imagens, avaliações e preços misturados. Não pode simplesmente lançar isso no Excel e começar a analisar.
Dados estruturados — como uma folha de cálculo com colunas para “Nome do Produto”, “Preço” e “Avaliação” — é o que alimenta análises, dashboards e tomadas de decisão. O web scraping é a ponte que transforma conteúdo web confuso em informação limpa e acionável.
E aqui vai um dado impressionante: apenas cerca de 50% dos dados desestruturados de uma organização chegam a ser analisados. O resto? Potencial desperdiçado. O web scraping ajuda a desbloquear esse valor.
Tipos de Soluções de Web Scraping: Com Código, Sem Código e com IA
Vamos dividir as opções:
- Soluções baseadas em código: Escreva scripts em Python (usando bibliotecas como BeautifulSoup ou Scrapy), JavaScript ou R. Máxima flexibilidade, mas vai precisar de alguma capacidade de programação — e de paciência quando os sites mudarem e o script partir.
- Soluções sem código: Ferramentas visuais (extensões de navegador, apps de desktop, plataformas na nuvem) que permitem configurar scrapes com cliques, não com código. Perfeitas para utilizadores de negócio que só querem resultados.
- Scrapers com IA: Os novos favoritos do momento. Estas ferramentas usam IA para detetar automaticamente o que extrair, adaptar-se a mudanças no site e até extrair dados de PDFs ou imagens. A Thunderbit é um ótimo exemplo disso.
Como alguém que já viveu os dois lados — a escrever código e a usar ferramentas sem código — posso dizer: para a maioria dos utilizadores de negócio, scrapers sem código ou com IA são o melhor caminho. Por que lutar com código quando pode obter o mesmo resultado em dois cliques?
Principais Recursos para Procurar numa Ferramenta de Scraping
Extraia dados de qualquer site usando IA Get Started Free
Nem todo o scraper é igual. Veja o que considero essencial (e o que recomendo para qualquer equipa de negócio):
- Facilidade de utilização: Consegue começar sem ler um manual do tamanho de um romance?
- Deteção de campos com IA: A ferramenta sugere automaticamente o que extrair?
- Suporte a subpáginas e paginação: Lida com listas de várias páginas e acede a páginas de detalhe?
- Opções de exportação: Consegue enviar os dados diretamente para Excel, Google Sheets, Airtable ou Notion?
- Agendamento: Dá para configurar e esquecer — com scraping automático à sua hora?
- Reconhecimento de tipos de dados: Identifica e-mails, telefones, imagens e muito mais?
- Modelos para sites populares: Extração com 1 clique para Amazon, Zillow, Instagram etc.
Para equipas de vendas, e-commerce e operações, estas funcionalidades significam menos trabalho manual, menos erros e muito mais tempo dedicado ao que realmente importa.
Thunderbit: o Web Scraper com IA Mais Simples para Todos
Certo, hora da propaganda sem vergonha — mas só porque acredito mesmo no que estamos a construir na Thunderbit.
A Thunderbit é uma extensão Chrome de web scraping com IA, pensada para utilizadores de negócio, não apenas desenvolvedores. Veja o que a torna diferente:
- Sugestão de campos por IA: Basta clicar em “AI Suggest Fields” e a Thunderbit lê a página, recomenda as melhores colunas e configura tudo por si. Acabou a adivinhação ou a mexer em seletores.
- Scraping em 2 cliques: Abra a página, deixe a IA sugerir os campos, clique em “Scrape”. Pronto. É mesmo tão simples assim.
- Subpáginas e paginação: A IA da Thunderbit deteta e extrai automaticamente subpáginas e listas paginadas — sem configuração extra.
- Scheduled Scraper: Quer monitorizar preços ou leads todos os dias? Basta descrever o agendamento (“todos os dias de manhã às 9h”), adicionar os URLs e a Thunderbit trata do resto.
- Exportação instantânea: Envie os seus dados diretamente para Excel, Google Sheets, Airtable ou Notion — sem taxas escondidas, sem burocracia.
- Extratores especializados: Extração com 1 clique de e-mails, telefones e imagens — completamente grátis.
- AI Autofill: Use IA para preencher formulários online e automatizar fluxos de trabalho, não apenas para extrair dados.
- Análise de documentos e imagens: Faça upload de PDFs, ficheiros Word, Excel ou imagens — a IA da Thunderbit extrai tabelas e estrutura os dados por si.
E sim, há um plano gratuito (extraia até 6 páginas), por isso pode testar sem risco. Se precisar de mais, os planos pagos começam em US$ 15/mês para 500 linhas — muito mais acessível do que a maioria das ferramentas empresariais.
Não acredite apenas em mim. Os utilizadores já nos disseram coisas como: “A Thunderbit é, sem dúvida, o web scraper mais fácil que já usei. Passei de horas a escrever scripts para extrair sites inteiros em minutos — com apenas alguns cliques.” É o tipo de feedback que faz valer todas as madrugadas a programar.
Quer ver a Thunderbit em ação? Veja o nosso canal no YouTube ou leia mais no blog da Thunderbit.
Experimente gratuitamente a extensão Chrome da Thunderbit
Melhores Práticas de Web Scraping para Equipas Não Técnicas
Web scraping é poderoso, mas um pouco de cuidado ajuda muito. Aqui ficam as minhas principais dicas para começar:
- Respeite as políticas dos sites: Verifique sempre os termos de serviço e o robots.txt do site. Limite-se a dados públicos e use-os de forma responsável.
- Não sobrecarregue os servidores: Seja educado — não bombardeie um site com pedidos. A maioria das ferramentas permite definir taxas de crawl ou atrasos.
- Comece pequeno: Teste o seu scraper em poucas páginas primeiro. Garanta que está a obter os dados desejados antes de escalar.
- Lide com a paginação: Não se esqueça de extrair todas as páginas, não apenas a primeira.
- Valide os seus dados: Limpe e confirme os resultados — remova duplicados, corrija a formatação e verifique se nada ficou em falta.
- Mantenha a organização: Documente o que foi extraído, quando e de onde. Isso vai poupar dores de cabeça mais tarde.
- Verifique se existem APIs: Às vezes, existe uma API oficial que fornece os dados de forma mais fácil e fiável do que extrair o HTML.
- Monitorize alterações: Os sites mudam. Se o seu scraper deixar de funcionar, talvez seja altura de atualizar a configuração (ou deixar a IA tratar disso).
- Use a ferramenta certa: Se uma ferramenta não estiver a funcionar, experimente outra. Não tenha medo de testar.
- Seja ético: Só porque pode extrair algo não significa que deve. Respeite a privacidade e a propriedade dos dados.
Para se aprofundar, consulte o nosso guia: O que é Data Scraping e Como Fazer em 2025.
Conclusão: Desbloquear Valor de Negócio com Web Scraping

Vamos fechar. A web está a transbordar de dados valiosos, mas a maior parte deles está presa em formatos desestruturados. O web scraping é a chave que desbloqueia esses dados — transformando caos em clareza e trabalho braçal em crescimento.
Quer seja em vendas, e-commerce, imobiliário ou operações, o web scraping pode ajudá-lo a:
- Gerar leads mais novos e de melhor qualidade
- Monitorizar concorrentes e mercados em tempo real
- Automatizar fluxos de trabalho aborrecidos e poupar horas por semana
- Tomar decisões mais inteligentes, rápidas e orientadas por dados
E graças às ferramentas modernas — especialmente soluções com IA como a Thunderbit — não precisa de ser programador nem cientista de dados para começar. Basta escolher um projeto, testar uma ferramenta (a nossa extensão Chrome é um ótimo ponto de partida) e ver o quanto mais consegue fazer quando deixa a automação fazer o trabalho pesado.
Num mundo em que “dados são o novo petróleo”, o web scraping é a sua bomba. Por isso, siga em frente — transforme essa mangueira de dados online num fluxo constante de insights e veja o seu negócio prosperar.
Boa raspagem! E, se um dia ficar bloqueado, já sabe onde me encontrar (ou, pelo menos, onde encontrar a Thunderbit).
Comece a fazer scraping com a IA da Thunderbit
Perguntas Frequentes
1. O que é web scraping, em termos simples?
Web scraping é usar software para puxar automaticamente dados específicos de sites — como preços, avaliações ou vagas — e transformá-los em algo útil, como uma folha de cálculo. Pense nisto como contratar um estagiário robô para fazer todo o trabalho aborrecido de copiar e colar por si, 24 horas por dia, 7 dias por semana.
2. Preciso saber programar para usar isto?
Não mais. Graças a ferramentas sem código e com IA como a Thunderbit, pode extrair dados de sites com alguns cliques — sem Python, sem depuração, sem problema. Se consegue navegar na web, consegue fazer scraping da web.
3. Que tipo de dados posso extrair?
Praticamente qualquer coisa pública online:
- Listagens e preços de produtos
- Imóveis
- Vagas de emprego
- Diretórios de empresas
- Biografias de redes sociais
- Tabelas e imagens em PDFs (sim, até essas)
Se estiver online e visível, há forma de o extrair.
4. Web scraping é legal?
Em geral, sim — desde que esteja a extrair dados públicos de forma responsável. Não sobrecarregue servidores, respeite os termos de serviço e evite extrair informações pessoais ou protegidas por login. Na dúvida, seja ético e mantenha tudo limpo.
Leia Mais
- 3 Formas de o Web Scraping Impulsionar o Crescimento do Negócio
- Estudo de Caso: Como um Retalhista Usou Scraping para Aumentar as Vendas
- Por que os Dados Externos São o Futuro da Estratégia Competitiva
Experimente o AI Web Scraper Get Started Free




