
Se está à procura de uma ferramenta de web scraping, é muito provável que já tenha encontrado o Webscraper io. É um dos nomes mais conhecidos na área da extração de dados, com centenas de milhares de utilizadores e a reputação de ser uma solução “no-code”. Mas será mesmo a melhor opção para utilizadores empresariais — sobretudo para quem não é técnico? E se estiver à procura de algo ainda mais simples, rápido e intuitivo?
Passei bastante tempo a investigar, testar e comparar ferramentas de web scraping para uso empresarial. Nesta análise aprofundada, vou mostrar-lhe o que o Webscraper io oferece de facto, para quem funciona melhor, onde se destaca e — igualmente importante — onde fica aquém. Também vou partilhar feedback real de utilizadores em plataformas como G2, Trustpilot e Capterra, para que possa ver o que as pessoas adoram — e o que as frustra.
E se for um utilizador empresarial que só quer obter dados de websites com o mínimo de complicações possível, vou apresentar-lhe o Thunderbit, um raspador Web IA que está a mudar o jogo para equipas não técnicas. Vou mostrar-lhe como o Thunderbit se compara com o Webscraper io e porque pode ser a escolha mais inteligente para o seu fluxo de trabalho.
O que é o Webscraper io?
O Webscraper io é uma empresa de extração de dados web fundada em 2017 e sediada na Letónia. O seu produto principal é a extensão de browser Web Scraper, disponível para Chrome e Firefox. A extensão permite-lhe criar “sitemaps” — basicamente, instruções sobre que dados recolher e como navegar num website — através de uma interface point-and-click. A ideia é que não precise de escrever código nem de mexer em scripts complexos: basta clicar nos elementos que quer e a ferramenta trata do resto.
Mas o Webscraper io não é apenas uma extensão de browser. Para necessidades mais avançadas, oferece um serviço Cloud Scraper. Isto permite executar tarefas de scraping nos seus servidores, agendar tarefas recorrentes, usar IPs proxy para evitar bloqueios e exportar dados para armazenamento na cloud ou via API. A plataforma cloud foi pensada para scraping automatizado e em maior escala — como monitorização de preços em e-commerce, agregação de imobiliário ou pesquisa de mercado em larga escala.
Produtos principais:
- Extensão de browser Web Scraper: scraping local e gratuito com interface visual.
- Web Scraper Cloud: scraping pago na cloud com agendamento, API, proxies e integrações.
Funcionalidades principais:
- Interface point-and-click para selecionar dados (sem necessidade de XPath/CSS manual)
- Lida com websites dinâmicos (JavaScript, AJAX, paginação)
- Navegação multinível através de sitemaps
- Exportação de dados para CSV, Excel, JSON ou via API/webhooks
- Agendamento e automação na cloud
- Suporte a proxies para scraping em grande escala
- Integrações com Dropbox, Google Sheets, Amazon S3 e muito mais
Resumindo, o Webscraper io pretende ser uma solução completa para extração de dados web, quer seja um empreendedor em nome individual ou uma empresa com grandes necessidades de dados.
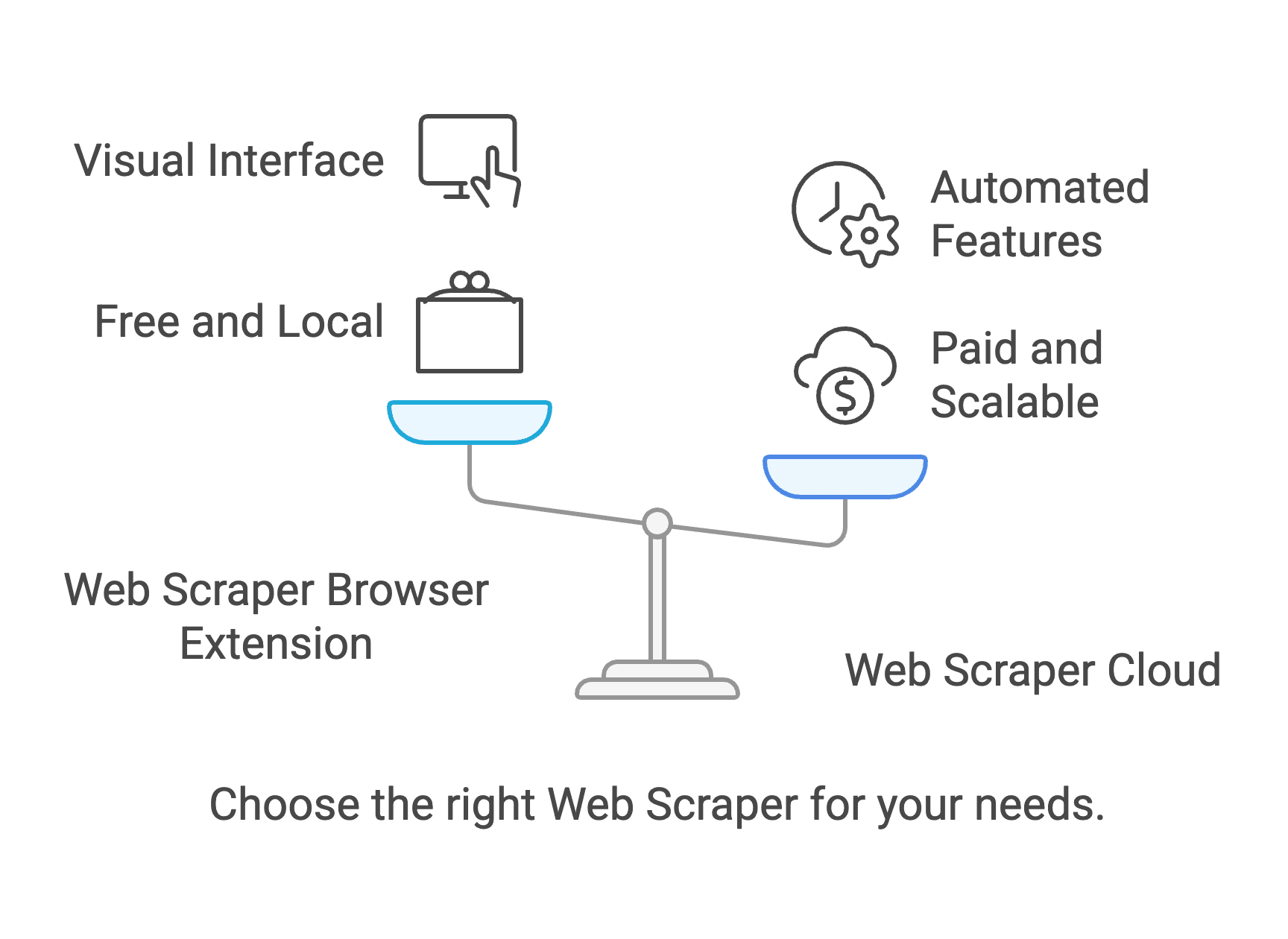
Para quem é o Webscraper io?
O Webscraper io posiciona-se como uma solução no-code — ou seja, não precisa de ser programador para o utilizar. Esse é um grande argumento para utilizadores empresariais que querem automatizar a recolha de dados sem contratar um programador ou aprender Python.
Os utilizadores típicos incluem:
- Analistas de dados que precisam de reunir grandes conjuntos de dados para investigação ou relatórios
- Profissionais de marketing a acompanhar concorrentes, preços ou avaliações de clientes
- Gestores de e-commerce a monitorizar listagens de produtos, inventário ou preços
- Profissionais do setor imobiliário a agregar dados de imóveis
- Investigadores e jornalistas a recolher dados públicos para análise
- Equipas de SEO e marketing digital a extrair palavras-chave, rankings ou conteúdo
Em teoria, qualquer pessoa que precise de transformar conteúdo de websites em dados estruturados — sem programar — deveria conseguir usar o Webscraper io.
Mas há um senão: apesar de a ferramenta ser “no-code”, nem sempre é “sem complicações”. Como vou explicar na secção de feedback dos utilizadores, existe uma curva de aprendizagem, e alguns utilizadores empresariais consideram o processo de configuração mais complexo do que esperavam.
Plano de preços
Uma das razões que atrai as pessoas para o Webscraper io é o seu modelo freemium. A extensão de browser é totalmente gratuita para scraping local, o que é ótimo para experimentar ou para tarefas pequenas.
Mas se quiser automatizar, escalar ou usar funcionalidades avançadas, vai precisar de um plano cloud pago. Eis como os preços se dividem, em maio de 2026 (retirado de webscraper.io/pricing — eles alteram isto ocasionalmente, por isso confirme antes de avançar):
| Plano | Preço/Mês | Créditos de URL | Tarefas Paralelas | Retenção de Dados | Funcionalidades Principais |
|---|---|---|---|---|---|
| Gratuito (Extensão) | $0 | Ilimitados (apenas local) | 1 | n/d | Scraping local, exportação CSV/Excel, suporte da comunidade |
| Project | $50 | 5.000 | 2 | 30 dias | Scraping na cloud, agendamento, exportação JSON, proxies de datacenter, integrações |
| Professional | $100 | 20.000 | 3 | 30 dias | Todas as funcionalidades do Project + acesso à API, agendador, parser |
| Scale | a partir de $200 | Ilimitados (baseado no uso) | 2+ (personalizável) | 60 dias | Todas as funcionalidades do Pro + monitorização da qualidade dos dados, complemento de proxy residencial (~$2,5/GB) |
| Enterprise | Personalizado | Personalizado | Personalizado | Personalizado | Volume personalizado, suporte dedicado, contactar vendas |
Todos os planos pagos incluem um teste gratuito de 7 dias (sem cartão de crédito). A extensão gratuita de browser é uma boa forma de testar, mas se precisar de automação, agendamento ou scraping em larga escala, vai ter de pagar.
Alguns pontos a ter em conta:
- O plano gratuito só funciona localmente — o seu computador tem de estar ligado, e não pode agendar tarefas a partir da extensão.
- Os créditos de URL são repostos todos os meses. Um crédito = uma página carregada (não uma linha), por isso um crawl de 100 páginas consome 100 créditos, mesmo que só extraia 1 registo por página.
- O plano Scale parece ilimitado no papel, mas os proxies residenciais são cobrados separadamente (cerca de $2,50/GB na última verificação) e as contas grandes de largura de banda/proxy acumulam-se rapidamente. Se estiver a fazer crawling em grande volume, estime o custo dos proxies antes de subscrever.
- O acesso à API e o agendador estão reservados ao plano Professional e superiores — o plano Project de $50 não os inclui. É útil saber isto se o único motivo para atualizar for automação.
Para pequenas empresas, o plano Project de $50/mês costuma ser o ponto de partida. Para scraping de alto volume com necessidade de proxies, os custos podem subir rapidamente — eu faria as contas com a calculadora do Scale antes de o encarar como uma despesa fixa de $200/mês.
Feedback dos utilizadores sobre o Webscraper io
Gosto sempre de consultar avaliações reais de utilizadores antes de recomendar qualquer ferramenta. Foi isto que encontrei ao analisar G2, Trustpilot e Capterra:
Resumo das avaliações (verificado em maio de 2026)
- G2: ~4,4/5 — base de avaliações pequena, por isso cada avaliação individual pesa bastante
- Capterra: 4,7/5 em cerca de 7 avaliações — pontuação alta, mas amostra muito reduzida; convém ter cautela
- Trustpilot: ~4,0/5 em cerca de 29 avaliações — melhor do que antigamente, mas ainda é a plataforma mais mista das três
Sinceramente, estes números são demasiado pequenos para tirar conclusões definitivas. São indicativos, não são a verdade absoluta. As pontuações altas no G2 e no Capterra apontam para uma base real de fãs entre os utilizadores que ficaram tempo suficiente para aprender a ferramenta. O misto de avaliações no Trustpilot tende a mostrar as pessoas que desistiram cedo por causa da curva de aprendizagem. Ambos os sinais são reais.
Vamos ver aquilo de que as pessoas gostam — e com o que têm dificuldade.
O que os utilizadores gostam
1. Interface point-and-click:
Muitos utilizadores adoram poder selecionar dados visualmente, sem escrever código. “Só precisa de alguns cliques”, disse um avaliador, “e consegue extrair dados de praticamente qualquer website.” Isto poupa imenso tempo em comparação com a criação de scripts personalizados.
2. Gratuito para começar:
A extensão de browser é “GRÁTIS GRÁTIS GRÁTIS!”, como um utilizador entusiasmado escreveu. Para tarefas pequenas ou projetos pontuais, consegue fazer muita coisa sem gastar um cêntimo.
3. Lida com sites complexos:
O Webscraper io consegue extrair conteúdo dinâmico, lidar com paginação e navegar em sites multinível. Os utilizadores valorizam o facto de funcionar em sites com JavaScript ou AJAX, que muitos raspadores básicos não conseguem tratar.
4. Opções de exportação de dados:
Pode exportar para CSV, Excel, JSON ou até enviar dados para Google Sheets ou Dropbox. Isto facilita muito levar os dados para onde precisa.
5. Preço razoável em relação ao valor:
Pelas funcionalidades que oferece, muitos utilizadores sentem que os planos pagos são justos — especialmente quando comparados com contratar um programador ou usar ferramentas empresariais mais caras.
Onde os utilizadores têm dificuldades
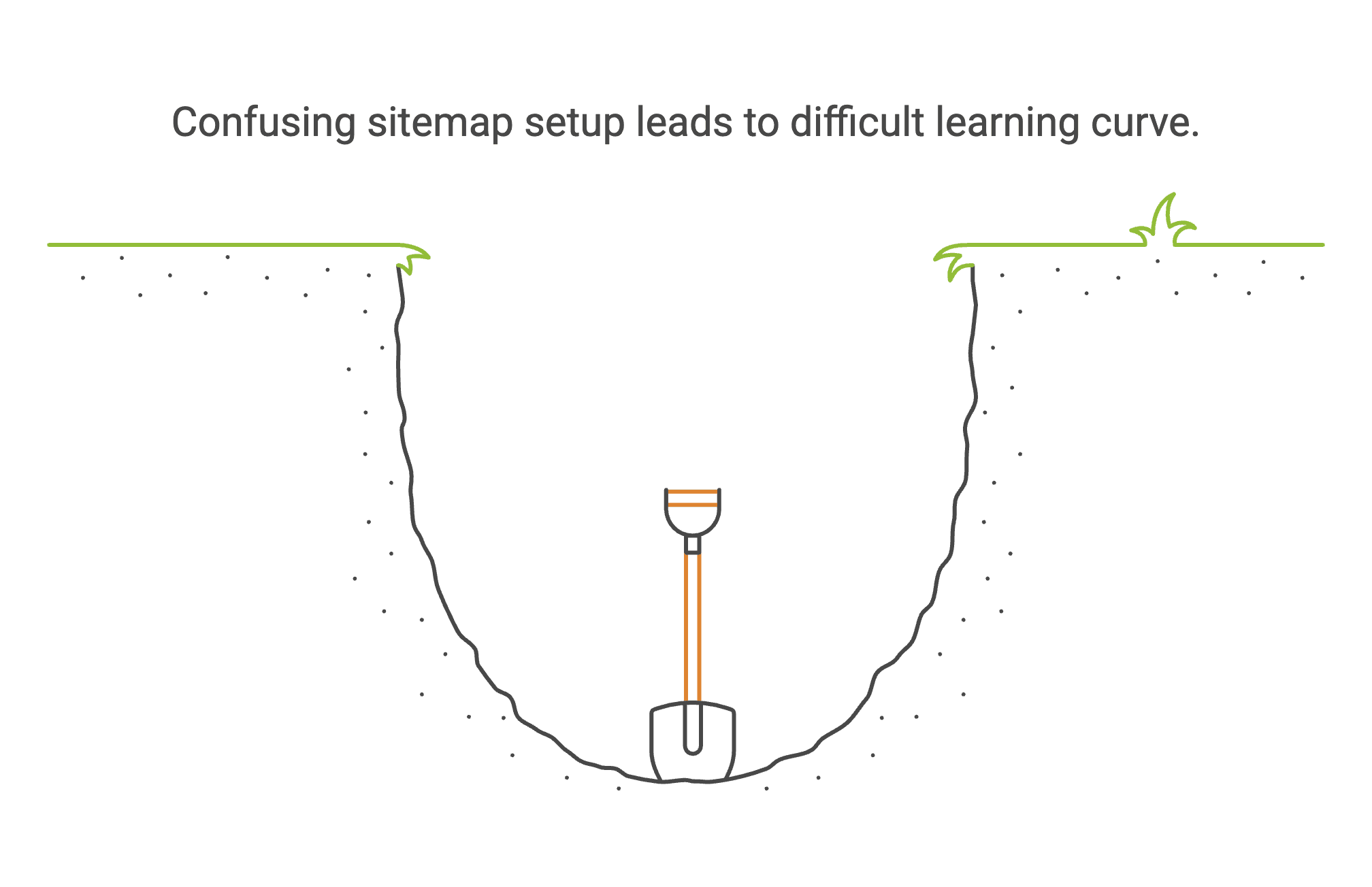
Apesar da promessa “no-code”, muitos utilizadores dizem que o Webscraper io não é tão fácil quanto parece. Eis o que fui vendo nas avaliações:
-
A configuração do sitemap é confusa:
É preciso criar um “sitemap” que diz ao scraper como navegar e o que extrair. Para iniciantes, isto pode ser pouco intuitivo. Um avaliador do G2 disse: “Isto exige algum tempo para aprender. Recomendo ver tutoriais e trabalhar com um colega para perceber a hierarquia.”
-
É preciso tentativa e erro:
Se não selecionar os elementos certos ou falhar um passo, o scraper pode não funcionar — ou pode devolver resultados vazios. Resolver estes problemas pode parecer programação, mesmo sem estar a escrever scripts.
-
A documentação existe, mas…
Embora existam guias e vídeos, alguns utilizadores gostavam de melhor orientação dentro da aplicação ou suporte em tempo real. Se ficar preso, muitas vezes tem de procurar em fóruns ou esperar por respostas por email.
Exemplo do mundo real
Um utilizador empresarial partilhou que tentou fazer scraping num site imobiliário para obter listagens de imóveis. Depois de horas de tentativa e erro, conseguiu finalmente pôr o scraper a funcionar — só para descobrir que as colunas de dados estavam trocadas na exportação. Teve de voltar atrás, ajustar o sitemap e executar novamente a tarefa. “Não é tão plug-and-play como eu esperava”, disse. “É preciso paciência e uma mentalidade lógica.”
Outro avaliador referiu que configurou um scraper para um site de e-commerce, mas este continuava a falhar metade dos produtos por causa do infinite scroll. Teve de entrar nas definições avançadas e adicionar atrasos personalizados — algo que um utilizador não técnico talvez não conseguisse descobrir.
Conclusão sobre a análise do Webscraper io
Então, o Webscraper io é uma boa ferramenta para utilizadores empresariais? A resposta é: depende do seu à-vontade com tecnologia e da sua disponibilidade para aprender.
Vantagens:
- Gratuito para começar, planos pagos acessíveis
- Lida com websites complexos e dinâmicos
- Opções flexíveis de exportação e integração
- Escalável para trabalhos grandes
Desvantagens:
- Curva de aprendizagem acentuada para utilizadores não técnicos
- A configuração pode ser confusa e demorada
- Interface básica, nem sempre fácil de usar
- Suporte limitado, a menos que pague
- Não é verdadeiramente “plug-and-play” para principiantes
Se for analista de dados ou utilizador avançado e estiver disposto a investir tempo para aprender a ferramenta, o Webscraper io pode ser um recurso poderoso. Mas se for um profissional de negócios ocupado e só quiser extrair dados de websites — sem lutar com sitemaps, seletores ou depuração — há opções mais fáceis.
E isso leva-me ao Thunderbit.
Thunderbit: O Raspador Web IA mais fácil para utilizadores empresariais
O Thunderbit é uma extensão Chrome de raspador Web com IA concebida especificamente para utilizadores empresariais — equipas de vendas, profissionais de marketing, agentes imobiliários, operadores de e-commerce e qualquer pessoa que precise de dados, rapidamente. O que distingue o Thunderbit é o foco na simplicidade, automação e ausência de curva de aprendizagem.
Extrair dados de qualquer website com IA Get Started Free
Raspadores Web IA significam basicamente isto: o ChatGPT lê o website inteiro e depois extrai o conteúdo com base no que precisa.
O que torna o Thunderbit diferente?
-
“Sugerir colunas” com IA
Basta clicar em “AI Suggest Columns” e a IA do Thunderbit analisa o website e recomenda as melhores colunas a extrair. Não precisa de criar sitemaps nem de descobrir seletores. Pode ajustar as colunas se quiser, mas, na maior parte das vezes, funciona logo à primeira. -
Scraping em 2 cliques
Depois de definir as colunas, basta carregar em “Scrape”. É só isso. O Thunderbit recolhe os dados e estrutura-os para si — sem configuração manual, sem tentativa e erro. -
Scraping de subpáginas
Precisa de extrair dados de várias páginas ou subpáginas (como detalhes de produtos, avaliações ou listagens)? A IA do Thunderbit pode visitar automaticamente cada subpágina e enriquecer a sua tabela — sem necessidade de configuração extra. -
Modelos pré-construídos para sites populares
Vai fazer scraping a Amazon, Zillow, Instagram, Shopify ou outras grandes plataformas? O Thunderbit oferece modelos de 1 clique que permitem exportar dados instantaneamente, sem qualquer configuração. -
Exportação de dados gratuita
Exporte os dados recolhidos para Excel, Google Sheets, Airtable ou Notion — gratuitamente. Ao contrário de algumas ferramentas, o Thunderbit não cobra extra pela exportação de dados. -
Preenchimento automático com IA (completamente gratuito)
O Thunderbit não serve apenas para scraping — também pode preencher formulários online e automatizar fluxos de trabalho com IA. Basta selecionar o contexto e premir Enter; a IA trata do resto. -
Raspador Agendado
Precisa de automatizar tarefas de scraping recorrentes? O Thunderbit permite agendar trabalhos de scraping em qualquer intervalo — basta descrever o horário, introduzir os URLs e está pronto. -
Extratores gratuitos de email, telefone e imagem
Extraia endereços de email, números de telefone ou imagens de qualquer website com 1 clique — sem custo adicional. -
Parser de imagem/documento
Precisa de extrair tabelas de PDFs, documentos Word, ficheiros Excel ou imagens? Basta carregar o ficheiro, deixar a IA sugerir a estrutura e clicar em “Scrape”.
Experimentar o Raspador Web IA do Thunderbit gratuitamente
Para quem é o Thunderbit?
O Thunderbit foi criado para utilizadores empresariais que querem resultados, não dores de cabeça. Se trabalha em vendas, marketing, imobiliário, e-commerce ou em qualquer função em que precise de transformar conteúdo web em dados estruturados — sem programação nem configuração complexa — o Thunderbit é para si.
Também é ideal para equipas que querem:
- Poupar tempo em tarefas repetitivas de recolha de dados
- Automatizar geração de leads, monitorização de preços ou pesquisa de mercado
- Exportar dados diretamente para as suas ferramentas favoritas (Excel, Sheets, Notion, Airtable)
- Evitar a frustração de depurar sitemaps ou seletores
Preços do Thunderbit
O Thunderbit usa um sistema de créditos — 1 crédito equivale a 1 linha de saída. Eis como os planos se organizam:
| Escalão | Preço Mensal | Preço Anual (por mês) | Total Anual | Créditos/Mês | Créditos/Ano |
|---|---|---|---|---|---|
| Gratuito | $0 | $0 | $0 | 6 páginas | N/A |
| Starter | $15 | $9 | $108 | 500 | 5.000 |
| Pro 1 | $38 | $16,5 | $199 | 3.000 | 30.000 |
| Pro 2 | $75 | $33,8 | $406 | 6.000 | 60.000 |
| Pro 3 | $125 | $68,4 | $821 | 10.000 | 120.000 |
| Pro 4 | $249 | $137,5 | $1.650 | 20.000 | 240.000 |
- Escalão gratuito: faça scraping até 6 páginas (independentemente do número de linhas por página)
- Teste gratuito: 10 páginas grátis
- Sem custo extra pela exportação de dados
- Todas as funcionalidades incluídas em todos os planos (sem paywall para modelos, preenchimento automático por IA ou extratores)
Pode descarregar a extensão Thunderbit para Chrome aqui e ver aqui os detalhes completos dos preços.
Thunderbit vs Webscraper io: comparação lado a lado
Vamos pôr o Thunderbit e o Webscraper io frente a frente, para ver exatamente onde cada ferramenta se destaca — e onde o Thunderbit leva vantagem para utilizadores empresariais.
| Funcionalidade | Thunderbit | Webscraper io |
|---|---|---|
| Facilidade de utilização | ⚡ scraping com IA em 2 cliques, sem configuração necessária | 🧩 requer configuração de sitemap, curva de aprendizagem para iniciantes |
| Sugerir colunas com IA | 🤖 Sim – deteção e estruturação automática de colunas | 🛠️ Não – seleção e configuração manuais |
| Modelos pré-construídos | 🧵 Sim – 1 clique para Amazon, Zillow, Instagram, Shopify, etc. | 🏗️ Não – é preciso criar sitemaps para cada site |
| Scraping de subpáginas | 🛰️ Sim – a IA visita subpáginas automaticamente | 🪜 requer configuração manual |
| Exportação de dados | 📤 Gratuito para Excel, Google Sheets, Airtable, Notion | 💾 Gratuito localmente, pago na cloud; integrações limitadas |
| Extratores de email/telefone/imagem | 📧📞🖼️ Sim – 1 clique, grátis | 🔧 Não – é necessário configurar manualmente |
| Parser de imagem/documento | 📄 Sim – extrai tabelas de PDF, Word, Excel, imagens | 🌐 Não – apenas páginas web |
| Preenchimento automático com IA | ✍️ Sim – grátis, automatiza o preenchimento de formulários e fluxos de trabalho | 🚫 Não |
| Raspador Agendado | ⏰ Sim – agendamento simples em linguagem natural | 📆 Sim – mas apenas em planos cloud pagos |
| Suporte de browser | 🌐 Extensão Chrome | 🌐 Extensão Chrome/Firefox |
| Curva de aprendizagem | 🟢 Mínima – concebido para utilizadores não técnicos | 🔴 Acentuada para iniciantes, exige paciência |
| Suporte | 📬 Email e documentação, equipa responsiva | 🧑🤝🧑 suporte da comunidade (gratuito), email (pago) |
| Preços | 💸 escalão gratuito, planos pagos acessíveis, sem taxas de exportação | 💰 extensão gratuita, planos cloud pagos, taxas de exportação na cloud |
| Melhor para | 🧑💼 utilizadores empresariais, vendas, marketing, imobiliário, e-commerce, não programadores | 👨🔬 utilizadores avançados, analistas de dados, quem esteja disposto a aprender |
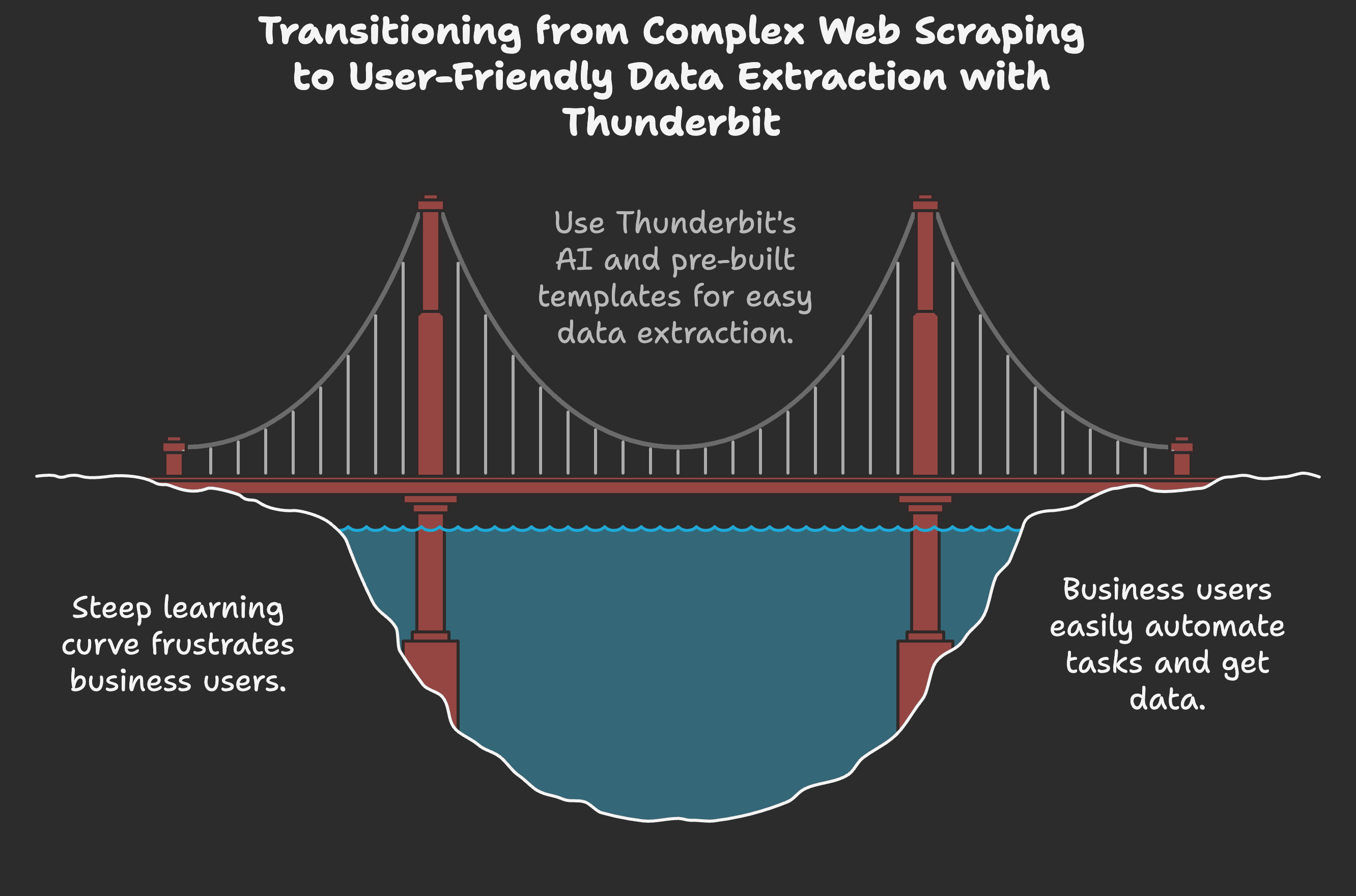
Conclusão: porque o Thunderbit é a escolha mais inteligente para utilizadores empresariais
Depois de testar ambas as ferramentas e ler centenas de avaliações de utilizadores, esta é a minha opinião sincera:
- O Webscraper io é uma ferramenta poderosa e flexível, capaz de lidar com tarefas de scraping complexas. Mas não é tão “no-code” como afirma — há uma curva de aprendizagem real, e os principiantes acabam muitas vezes frustrados. Se for analista de dados ou programador, vai apreciar o controlo. Mas se for um utilizador empresarial que só quer resultados, pode acabar por dar mais trabalho do que vale.
- O Thunderbit foi criado para pessoas que querem poupar tempo, automatizar tarefas repetitivas e obter dados estruturados — sem complicações. A funcionalidade de IA “Sugerir colunas”, o scraping em 2 cliques e os modelos pré-construídos fazem dele o raspador Web mais fácil que já usei. Não precisa de ver tutoriais, depurar sitemaps ou preocupar-se com seletores. Basta apontar, clicar e obter os seus dados.
Se já está farto de lutar com ferramentas complexas, ou se já experimentou o Webscraper io e o achou demasiado complicado, recomendo vivamente que experimente o Thunderbit. Pode descarregar a extensão Chrome gratuitamente, fazer scraping até 6 páginas sem custo e ver por si próprio como o web scraping pode ser muito mais simples.
Pronto para trabalhar de forma mais inteligente, e não mais difícil? Registe-se no Thunderbit e sinta a diferença.
Começar já a fazer scraping com o Thunderbit
FAQ
Q1: O Thunderbit é mesmo mais fácil de usar do que o Webscraper io?
Sem dúvida. A funcionalidade de IA “Sugerir colunas” e o scraping em 2 cliques do Thunderbit significam que não precisa de criar sitemaps nem de descobrir seletores. Foi concebido para utilizadores empresariais que querem resultados, não uma curva de aprendizagem.
Q2: Posso usar o Thunderbit gratuitamente?
Sim! O escalão gratuito permite-lhe fazer scraping até 6 páginas, e o teste gratuito dá-lhe 10 páginas. Não há custos para exportar dados para Excel, Google Sheets, Airtable ou Notion.
Q3: Que tipos de websites o Thunderbit consegue fazer scraping?
O Thunderbit consegue fazer scraping de praticamente qualquer website, incluindo sites dinâmicos, subpáginas e até extrair dados de PDFs, imagens e documentos. Também oferece modelos de 1 clique para plataformas populares como Amazon, Zillow, Instagram e Shopify.
Q4: Como é que o Thunderbit lida com tarefas de scraping recorrentes?
O Raspador Agendado do Thunderbit permite automatizar tarefas de scraping em qualquer intervalo. Basta descrever o agendamento, introduzir os URLs e o Thunderbit trata do resto.
Leia mais
Se quiser saber mais sobre web scraping, automação e produtividade com IA, veja estes recursos:
- O que é data scraping e como fazê-lo em 2025
- Automação com IA: uma nova era na eficiência e inovação empresarial
- Web scraping (Wikipedia)
- Automação de processos robóticos (Wikipedia)
Para mais dicas, tutoriais e comparações, visite o Thunderbit Blog.
Experimente o Raspador Web IA Get Started Free




