Fala-se muito sobre decisões orientadas por dados, mas pouca gente lembra o quanto coletar essas informações pode ser puxado e cansativo. Se você já tentou buscar dados manualmente, sabe bem como isso pode ser desgastante. Já vi várias empresas emperrarem suas estratégias por causa de processos de coleta de dados pouco eficientes. Se esse é o seu caso, este artigo traz soluções inovadoras para te ajudar.
💡 Aqui, vamos mergulhar no universo do data scraping e mostrar como ele está evoluindo com a tecnologia. Vamos analisar as limitações dos métodos antigos, destacar as vantagens do data scraping com IA e compartilhar dicas práticas para aplicar no seu dia a dia.
O que é Data Scraping?
Data scraping, ou , é o processo de extrair informações organizadas de páginas da internet usando ferramentas (normalmente, os dados vão para tabelas). É uma maneira super eficiente de juntar grandes volumes de dados em pouco tempo. Por exemplo, dá para puxar dados públicos do para prospectar clientes, extrair SKUs de e-commerce da para revenda ou análise de mercado, ou ainda coletar avaliações de redes sociais como o para entender melhor o perfil do consumidor.
A Transformação Tecnológica do Data Scraping
Antigamente, coletar dados era coisa para quem manjava de tecnologia (ou exigia muito copiar e colar na mão). Mas agora, em 2025, a IA mudou esse jogo. Data scraping deixou de ser exclusividade de programadores ou de automações básicas.
Por que os Métodos Tradicionais Não Dão Mais Conta
Os sites de hoje trazem novos desafios: carregamento dinâmico de conteúdo (com frameworks tipo React/Vue), dados multimodais (texto, vídeo, imagens) e estruturas de dados nada padronizadas (vários modelos numa mesma página). Pesquisas recentes apontam três grandes problemas dos :
-
Custo de Manutenção Alto Raspadores web tradicionais exigem manutenção manual constante (cerca de 3 a 5 horas por mês para cada site). Quando um site muda ou atualiza seu framework, 60% dos seletores XPath param de funcionar. Ferramentas com IA, graças a modelos de linguagem e inteligência de código, conseguem se adaptar automaticamente a 90% das mudanças estruturais, cortando o custo de manutenção em até 80%. Em sites modernos feitos com React/Vue, a IA mantém a estabilidade da raspagem entendendo o contexto, mesmo quando mudam os nomes das classes.
-
Limitação na Variedade de Dados Métodos antigos só pegam dados estruturados, deixando de fora informações valiosas como:
- Dados que estão em imagens
- Texto dentro de artigos
- Dados não estruturados, sem tags HTML
-
Problemas de Qualidade dos Dados Esses métodos têm dificuldade com conteúdo dinâmico, o que resulta em dados incompletos ou errados:
- Em listas paginadas (tipo catálogos de produtos), raspadores tradicionais pegam só 30-50% do conteúdo da primeira página.
- Em páginas com rolagem infinita (feeds de redes sociais), mais de 60% dos dados importantes ficam de fora.
- Alta taxa de erro ao alinhar dados não estruturados (listas desalinhadas).
É aí que ferramentas com IA, como o Thunderbit, fazem toda a diferença. Veja os principais benefícios a seguir.
A Ascensão do Data Scraping com IA
Em 2025, a IA — especialmente os grandes modelos de linguagem (LLMs) — já mostrou a que veio. Esses modelos entendem e geram linguagem natural, fazem análises complexas e entregam soluções muito mais eficientes. Várias ferramentas de data scraping já usam LLMs para superar as limitações dos métodos antigos. Depois de testar 13 nos últimos meses, minha dica é o .
Veja por que o Thunderbit se destaca:
-
Interação Revolucionária: Você pode digitar comandos em linguagem natural, e o sistema monta automaticamente um plano de raspagem, reduzindo em 87% o tempo de configuração comparado às ferramentas tradicionais.
-
Vantagens do Scraping Localizado: Como extensão de navegador, o Thunderbit oferece:
- Raspagem instantânea de dados
- Raspagem de páginas dinâmicas e com rolagem infinita
- Raspagem de páginas que pedem login
-
Processamento Multimodal Avançado: O Thunderbit lida com vários tipos de dados, como:
- Extração de texto em artigos
- Extração de tabelas financeiras de PDFs
- Reconhecimento de dados em várias imagens e organização em tabelas
- Raspagem e resumo de legendas de vídeos
Com o Thunderbit, você resolve facilmente diferentes cenários de coleta de dados. Veja como usar na prática.
Como Fazer Data Scraping com IA
Siga estes quatro passos para aproveitar tudo do :
-
Instale a Extensão no Navegador Entre no site do Thunderbit e baixe a extensão na Chrome Web Store. Depois de instalar, fixe o ícone na barra do navegador.
-
Cadastre-se e Ganhe Créditos Grátis Faça o cadastro pela extensão para receber créditos de teste. Com eles, você pode experimentar recursos como raspagem com IA, preenchimento automático de formulários e resumos inteligentes. Vale a pena testar no playground gratuito antes de usar os créditos para ver como a ferramenta funciona na prática.
-
Inicie a Raspagem Inteligente Abra um template na barra lateral do Thunderbit. Use descrições em linguagem natural para escolher o tipo de dado e o formato de extração desejado, ou ajuste outros detalhes. Depois, clique em "raspar" para começar a coleta.
Recursos Avançados de Scraping (Plano Pro)
Ao assinar o (ou iniciar o teste gratuito), você libera recursos como:

-
Processamento Multimodal de Dados Dá conta de cenários complexos como (relatórios financeiros, manuais), extração de dados de imagens (etiquetas de preço, fichas técnicas) e raspagem de legendas de vídeos. O sistema padroniza automaticamente dados não estruturados.
-
Raspagem Profunda de Subpáginas Permite acessar todos os sublinks de uma página (como /páginas de avaliações), reconhecendo dados relacionados e integrando-os automaticamente à tabela principal. Perfeito para catálogos de e-commerce, listas de imóveis e muito mais.
-
Biblioteca de Templates Prontos Use na hora para mais de 30 plataformas como , e , que se adaptam automaticamente a mudanças na estrutura das páginas. Novos usuários economizam em média 83% do tempo de configuração.
-
Raspagem em Massa Execute várias tarefas de raspagem ao mesmo tempo, com suporte à importação de listas de URLs para coleta em lote.
-
Paginação Inteligente Reconhece e raspa automaticamente conteúdos paginados (incluindo botões "carregar mais" e navegação por páginas), inclusive em páginas com rolagem infinita. Testado para raspar mais de 200 páginas de listas de produtos.
Guia Prático Thunderbit
Cenário 1: Coleta de Dados Imobiliários
Se você é corretor de imóveis e precisa reunir informações do Zillow, ou investidor em busca de oportunidades, um raspador web confiável é seu melhor aliado. O raspador IA do Thunderbit permite extrair facilmente dados essenciais do Zillow, mantendo você atualizado e competitivo. Confira o vídeo tutorial de como raspar o Zillow com o Thunderbit.
Cenário 2: Prospecção de Talentos e Clientes
Se você trabalha com RH buscando talentos ou é vendedor atrás de novos leads, um raspador web eficiente pode ser um grande diferencial. O Thunderbit permite extrair dados importantes do , facilitando a busca de profissionais e a gestão de leads. Depois de usar, você vai perceber que as buscas manuais e o copiar-e-colar ficaram no passado. Veja o tutorial de como raspar dados do LinkedIn com o Thunderbit.
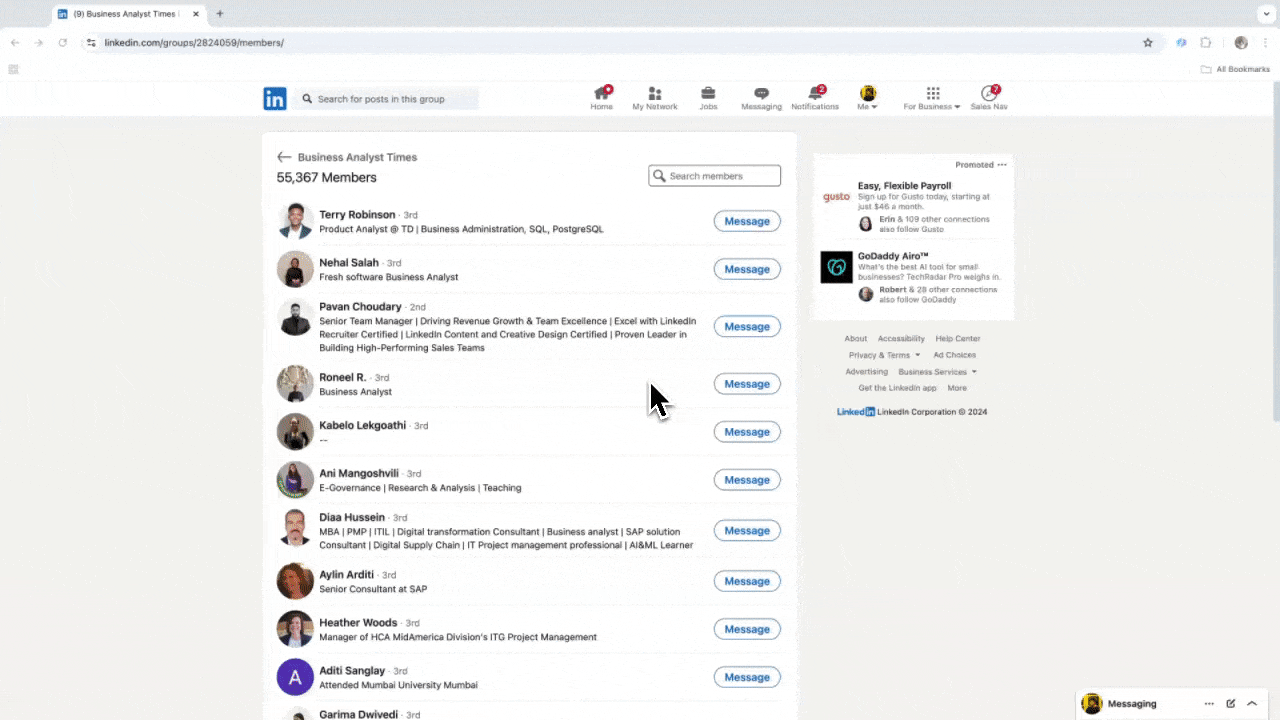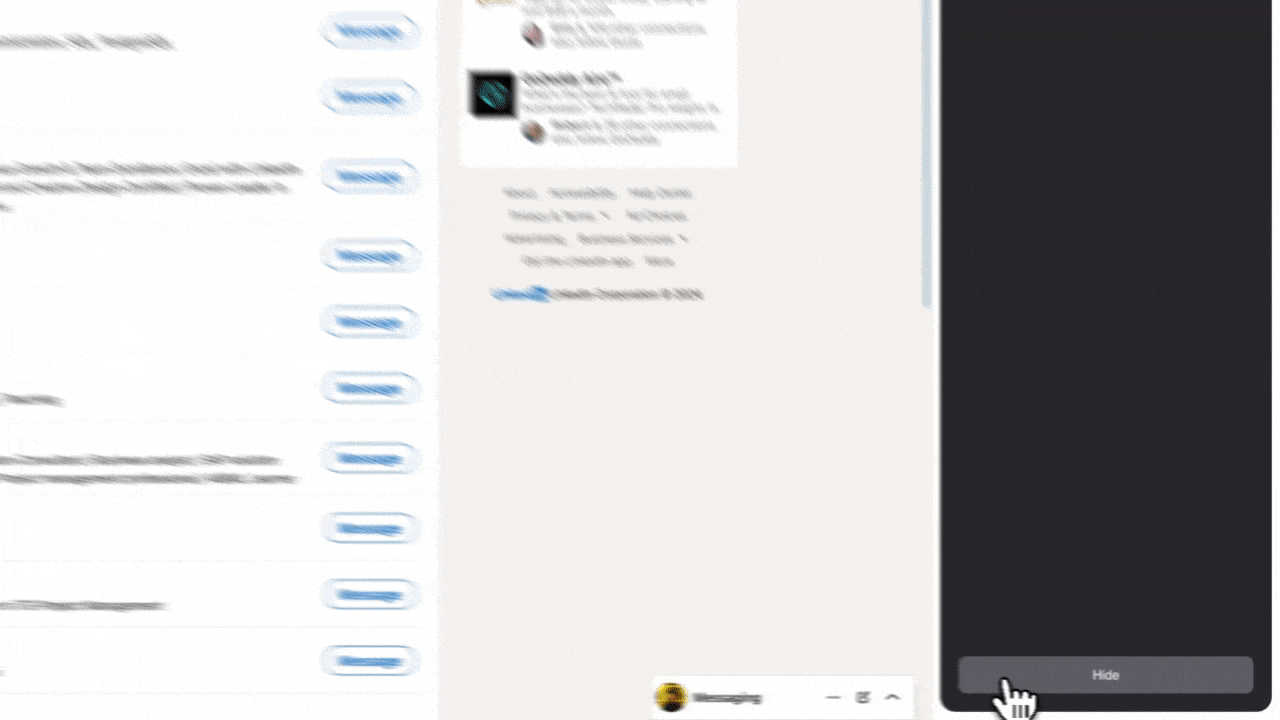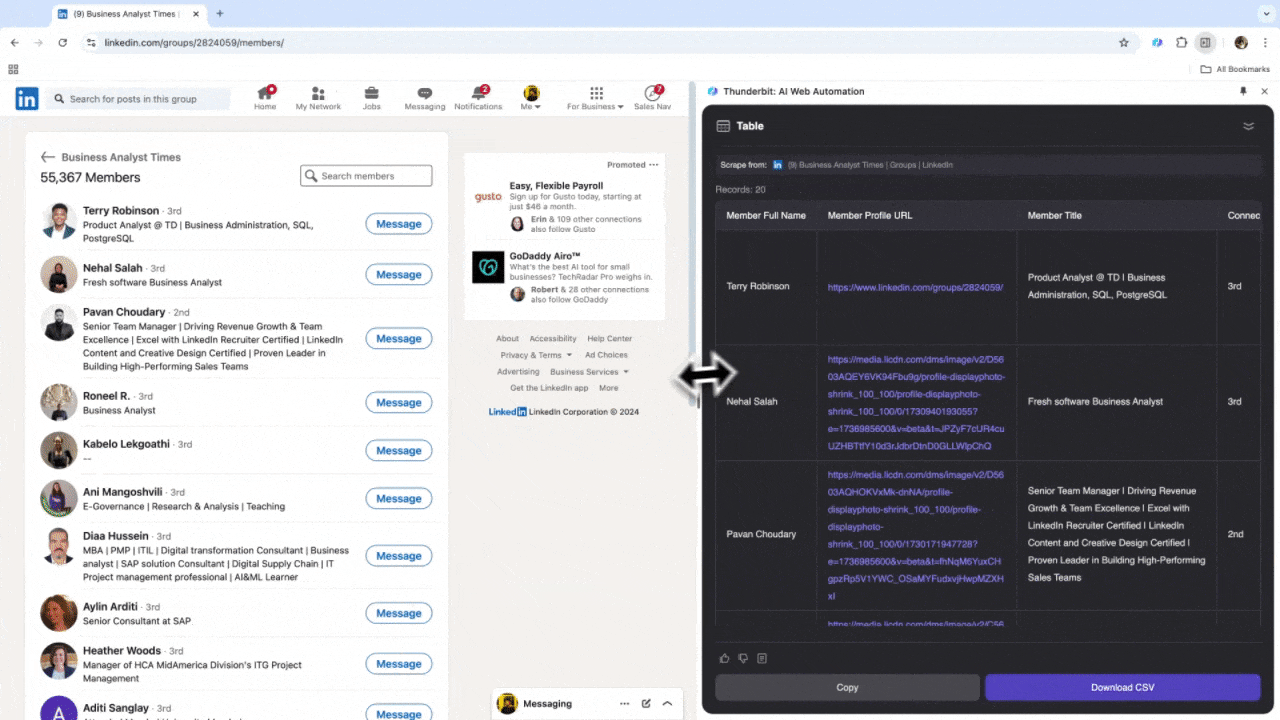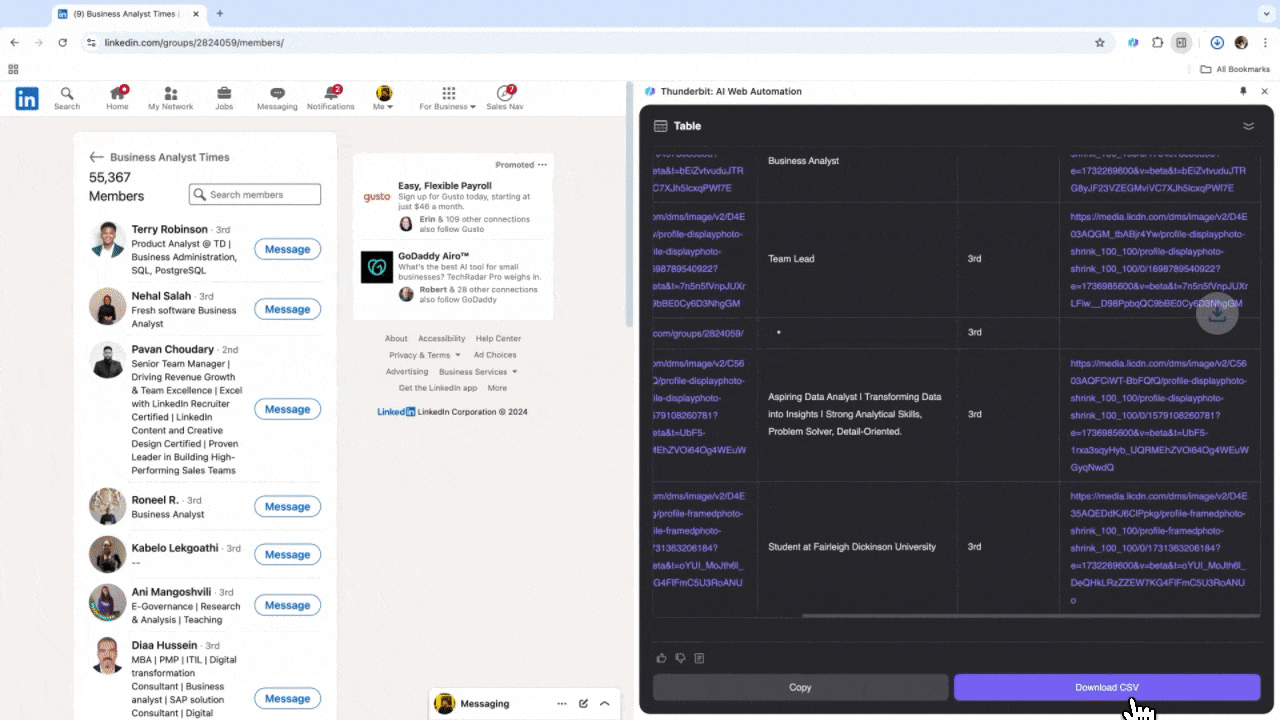
Cenário 3: Análise de Mercado e Prospecção de Clientes
Se você é empreendedor coletando dados geográficos para análise de mercado, ou vendedor buscando leads de negócios locais, um raspador web pode transformar sua rotina. O Thunderbit permite extrair facilmente dados do , ajudando você a tomar decisões mais assertivas e otimizar sua abordagem.
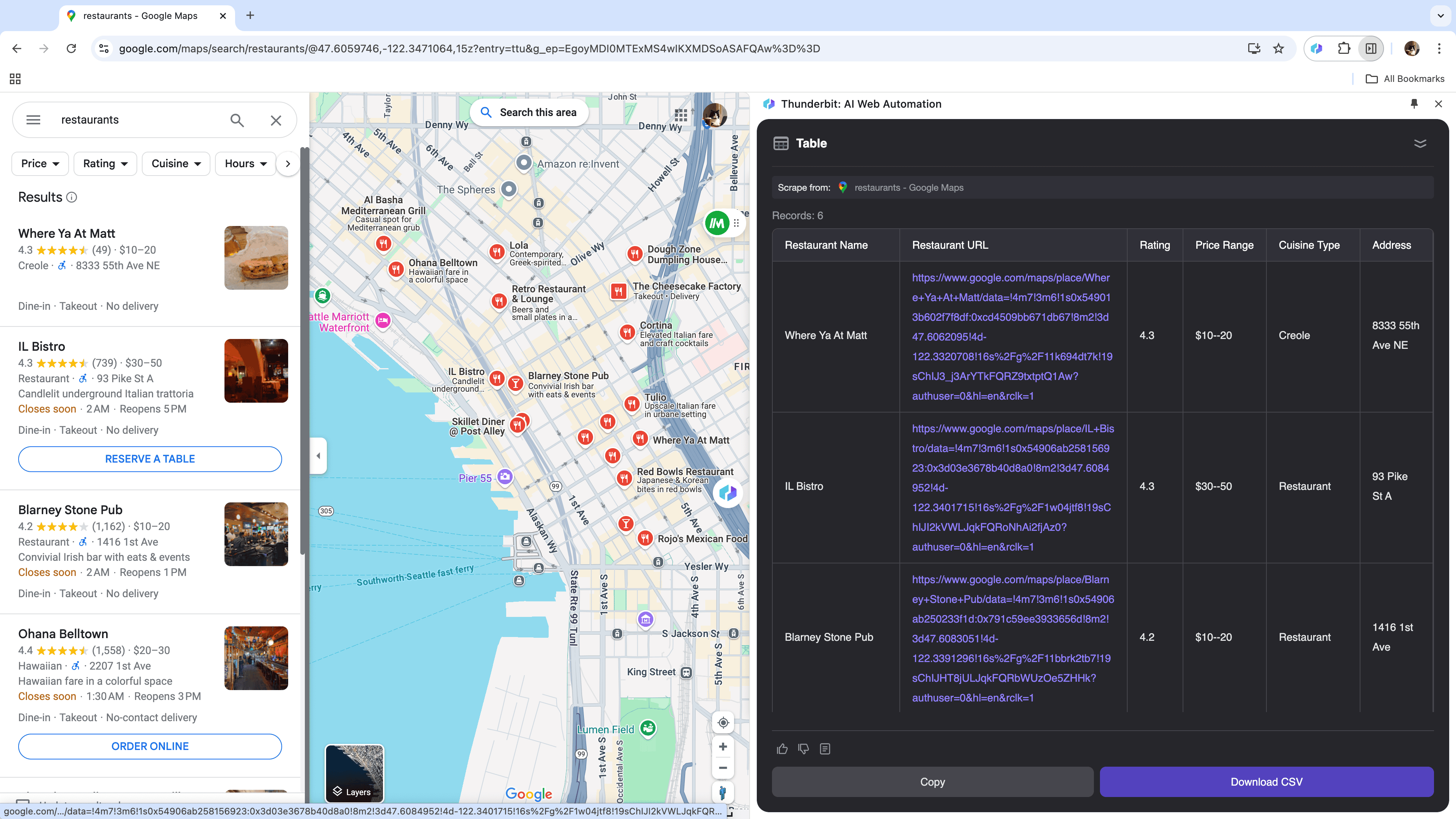
Cenário 4: Análise de Dados de E-commerce
Se você vende online e quer monitorar concorrentes ou acompanhar tendências, o Thunderbit é a ferramenta ideal! Ele coleta facilmente dados de produtos da , incluindo descrições detalhadas, preços e .
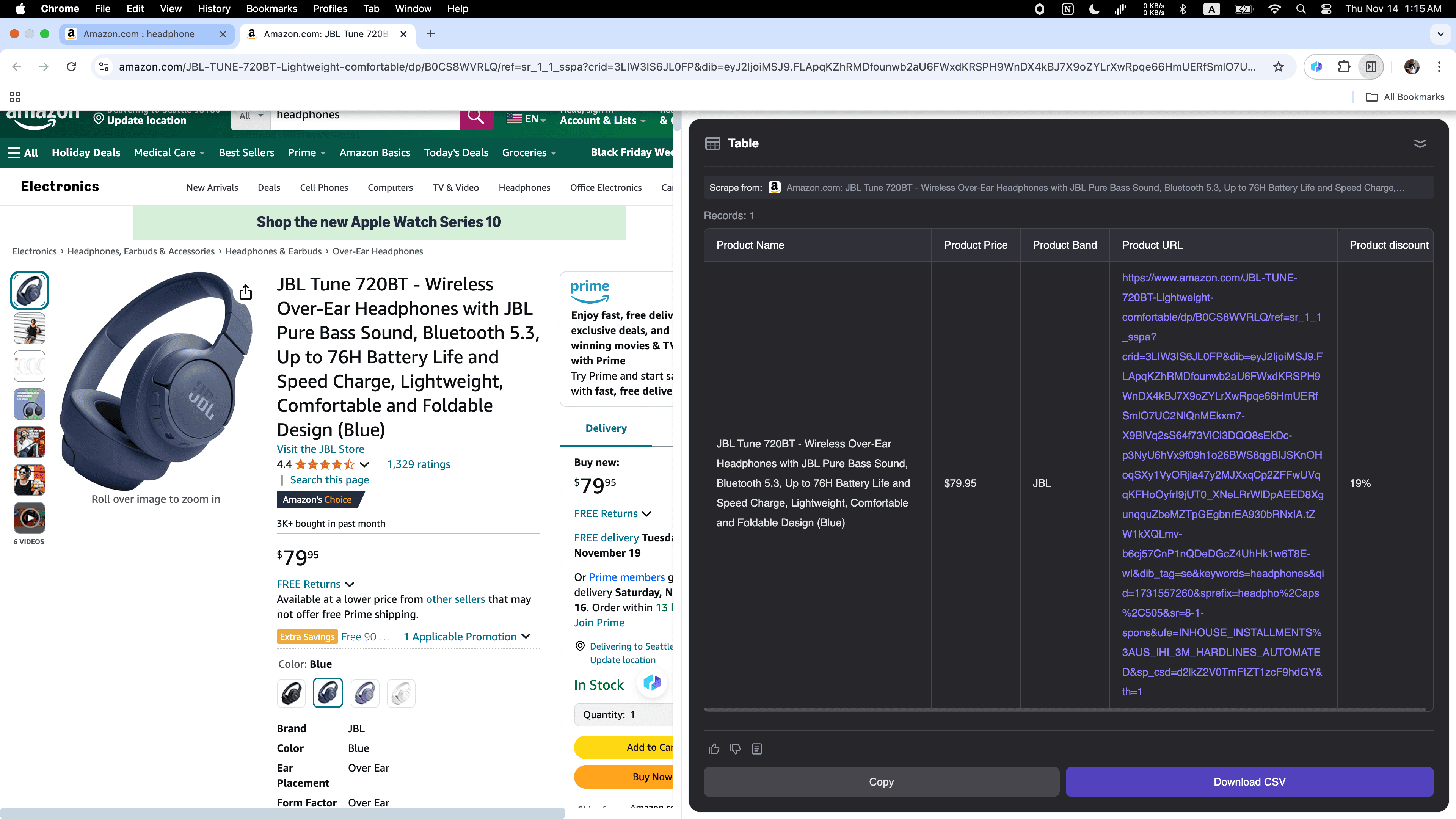
O raspador web IA Thunderbit está mudando a forma como empresas coletam dados, tornando tudo mais rápido, simples e eficiente. Seja para buscar imóveis, encontrar clientes ou analisar tendências de mercado, o uso de IA em raspagem de dados economiza horas de trabalho e elimina tarefas repetitivas. Aproveite o poder da IA e veja sua produtividade decolar. Pronto para começar? Experimente o Thunderbit e dê o primeiro passo para uma coleta de dados mais inteligente.
Dicas Exclusivas de Limpeza de Dados
Com raspadores tradicionais, o verdadeiro desafio começa depois da coleta: limpar os dados. O Thunderbit usa IA para limpar os dados já durante a raspagem, reduzindo em até 83% o trabalho de pós-processamento, graças a recursos inovadores:
Dica 1: Alinhamento Inteligente de Campos
Ao lidar com dados de várias fontes (como LinkedIn e Zillow ao mesmo tempo), a IA do Thunderbit faz o mapeamento semântico automaticamente:
- Identifica correspondências de campos entre diferentes fontes (ex: "price" ↔ "preço" ↔ "Price")
- Une campos parecidos (ex: "área" e "metros quadrados")
- Padroniza dados entre plataformas (ex: "cargo atual" do LinkedIn e "status do imóvel" do Zillow como tags)
Dica 2: Preenchimento Contextual
Com a compreensão de contexto dos grandes modelos de linguagem, o Thunderbit atinge taxa de preenchimento de 99%:
- Preenchimento de endereço: completa cidade/estado a partir do CEP (ex: 10001 → Nova York, NY)
- Inferência de carreira: sugere experiências profissionais com base na formação do LinkedIn
Dica 3: Otimização de Dados
- Tradução automática (suporta 12 idiomas, incluindo português, inglês, chinês e japonês)
- Resumo inteligente (condensa uma descrição de 500 palavras em três pontos-chave)
- Unificação de unidades (converte automaticamente pés quadrados ↔ metros quadrados, Fahrenheit ↔ Celsius)
- Padronização de formatos (datas em AAAA-MM-DD, moeda em USD)
Dica 4: Verificação de Qualidade
- Correção automática de erros: ajusta formatos (ex: telefone +01 138-1234-5678 → +113812345678)
- Validação lógica: garante que "ano de construção" seja anterior à "última reforma"
Dica 5: Tagueamento com IA
Gera tags inteligentes automaticamente via processamento de linguagem natural:
- Tags de sentimento (classifica avaliações como positivas/negativas/neutras)
- Tags de valor de negócio (marca "clientes potenciais"/"imóveis para acompanhamento")
- Tags de setor (classifica perfis do LinkedIn como "tecnologia|finanças|saúde")
Desafios do Data Scraping
Apesar dos benefícios, é importante ficar atento aos desafios do data scraping. Questões legais são fundamentais — legislações como GDPR e CCPA impõem regras rígidas para coleta de dados, exigindo atenção à privacidade. Muitos sites usam proteções como Cloudflare para bloquear raspagens via restrição de IP.
O Futuro do Data Scraping na Era da IA
A evolução da IA está tornando a raspagem de dados uma solução intuitiva para empresas. Imagine digitar só o domínio (tipo zillow.com) e o pedido ("raspar todos os imóveis de Nova York"), e ver a IA mapear automaticamente todos os dados relevantes — de detalhes dos imóveis a tendências de preços — sem precisar configurar nada manualmente. Esses sistemas inteligentes vão integrar os dados coletados direto nos fluxos de trabalho, alimentando CRMs com leads do LinkedIn ou enviando métricas de e-commerce para dashboards analíticos. O reconhecimento avançado de padrões vai permitir monitoramento proativo de estoques e tendências de mercado. E, o mais importante, a IA vai garantir conformidade automática, ajustando parâmetros em tempo real para seguir as normas e mantendo rastreabilidade.
Essa revolução com IA democratiza o acesso à inteligência de mercado e muda a relação das empresas com dados web. Quem apostar em soluções como o Thunderbit desde já vai sair na frente na hora de tomar decisões baseadas em dados.
Perguntas Frequentes
-
O que é o Thunderbit? é uma extensão inteligente para navegador baseada em grandes modelos de linguagem (LLM), criada para as demandas modernas de coleta de dados. Oferece e processamento multimodal, extraindo dados de páginas dinâmicas, PDFs, imagens e vídeos. Como solução local, lida com páginas que exigem login (como LinkedIn) e se adapta automaticamente a mudanças em frameworks modernos.
-
Como funciona o raspador web IA do Thunderbit? O raspador IA do Thunderbit usa inteligência artificial para extrair dados estruturados de sites. O usuário pode clicar em "Sugerir Colunas com IA" para que a IA indique como raspar o site, e depois em "Raspar" para coletar os dados. Ele processa dados de qualquer site, PDF ou imagem em apenas dois cliques.
-
Qual a diferença entre raspagem de listas e de subpáginas? A raspagem de listas é otimizada para cenários paginados (como listas de produtos), reconhecendo a lógica de paginação e coletando milhares de registros. A raspagem de subpáginas usa estrutura em árvore (ex: imóveis do Zillow → páginas de detalhes → plantas), criando relações entre tabelas principais e secundárias por associação semântica.
-
Pessoas sem conhecimento técnico podem usar o Thunderbit? O Thunderbit tem interface baseada em linguagem natural: basta descrever o que precisa (ex: "nome, e-mail, telefone") e o sistema gera o plano de raspagem. Nossos testes mostram que 85% dos usuários concluem a primeira coleta em menos de 10 minutos, sem precisar saber programação web.
-
Quais tipos de dados o Thunderbit consegue processar? O Thunderbit reconhece diversos tipos de dados:
- Dados estruturados: tabelas, listas (ex: especificações de produtos Amazon)
- Dados não estruturados: textos de avaliações, PDFs (reconhecimento automático)
- Dados multimodais: etiquetas de preço em imagens, extração de legendas de vídeos
- Dados dinâmicos: conteúdo com rolagem infinita, imagens carregadas sob demanda
- Dados relacionados: mapeamento entre páginas (ex: contatos do LinkedIn → informações da empresa)
-
Como começar a usar o Thunderbit? Saiba mais sobre nossas ou explore nossa para começar agora mesmo.
Saiba Mais: