Se você já tentou obter exatamente os dados certos de um site — talvez uma lista de preços da concorrência, um catálogo de produtos ou um novo lote de leads de vendas — sabe bem como é: as ferramentas de scraping padrão entregam uns 80% do caminho, mas aqueles 20% finais? É aí que a mágica, e a frustração, acontecem. No mundo orientado por dados de hoje, as empresas não podem se contentar com “quase certo”. Serviços personalizados de extração de dados e de extração sob medida tornaram-se a espinha dorsal das operações modernas, com o mercado global de web scraping projetado para saltar de US$ 754 milhões em 2024 para . Se a sua estratégia de dados não inclui scraping personalizado, talvez você já esteja invisível no seu mercado.
Passei anos ajudando equipas — de startups enxutas a grandes empresas consolidadas — a irem além das maratonas de copiar e colar e de ferramentas frágeis e genéricas. A diferença? Dominar a extração personalizada de dados. Neste guia, vou mostrar o que a extração personalizada realmente significa, por que ela é essencial, como (o Raspador Web IA que a minha equipa e eu criámos) torna tudo radicalmente simples e como escolher o serviço de extração de dados certo para o seu negócio. Vou até partilhar algumas histórias de guerra — porque, convenhamos, todo nerd de dados tem algumas.
O que é Extração Personalizada? Desbloqueando o Poder dos Serviços Sob Medida de Extração de Dados
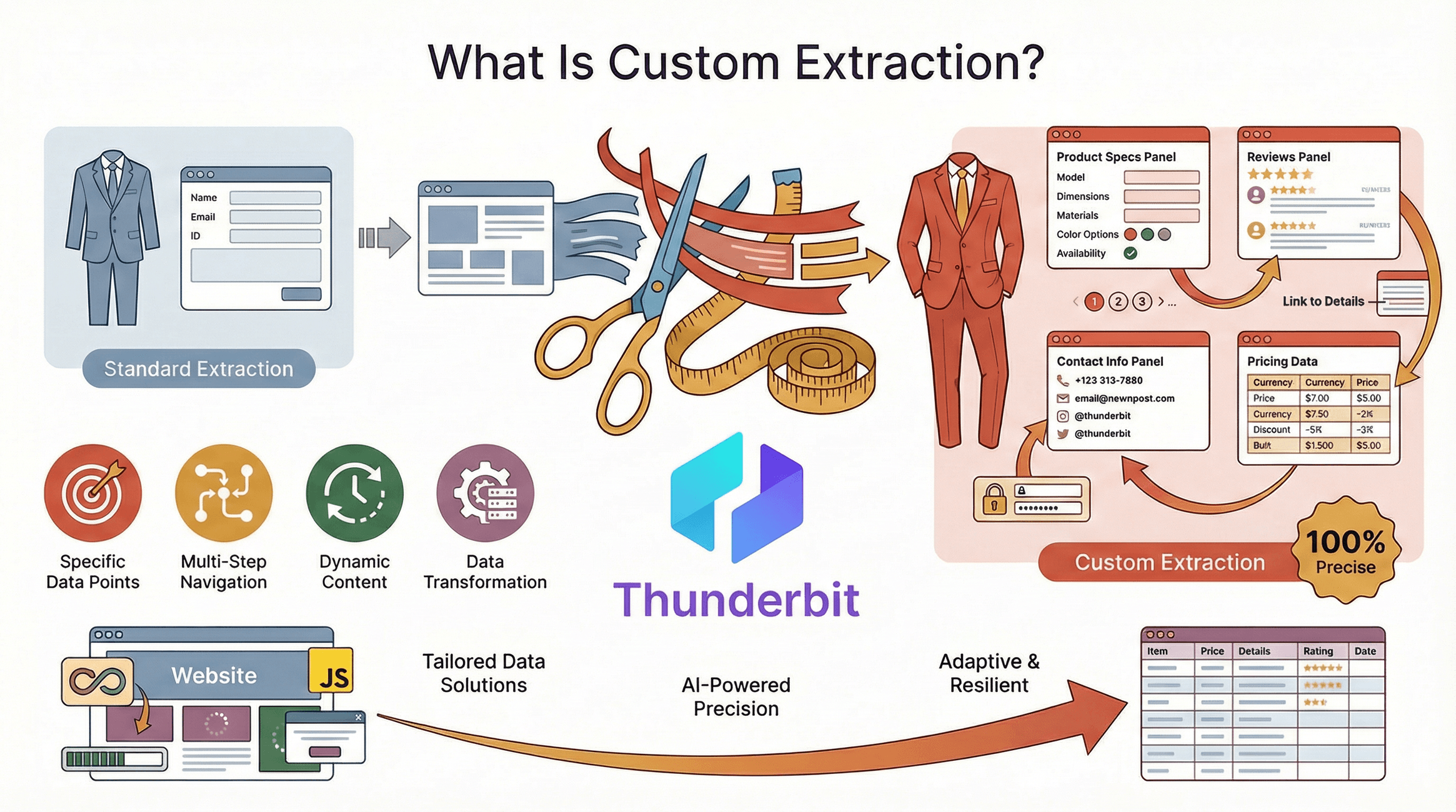 Vamos começar pelo básico: extração personalizada é obter exatamente os dados de que precisa, no formato que quer, dos sites que interessam ao seu negócio. Ao contrário das ferramentas de scraping padrão, que capturam o que for mais fácil ou visível, a extração personalizada de dados é precisa, adaptável e resiliente — mesmo quando os sites são complexos, dinâmicos ou mudam de layout a cada duas semanas.
Vamos começar pelo básico: extração personalizada é obter exatamente os dados de que precisa, no formato que quer, dos sites que interessam ao seu negócio. Ao contrário das ferramentas de scraping padrão, que capturam o que for mais fácil ou visível, a extração personalizada de dados é precisa, adaptável e resiliente — mesmo quando os sites são complexos, dinâmicos ou mudam de layout a cada duas semanas.
Pense nisto como encomendar um fato feito à medida em vez de comprar um pronto a vestir. Com a extração personalizada, não fica limitado aos campos ou modelos “padrão”. Pode:
- Selecionar pontos de dados específicos (como especificações de produto, avaliações ou informações de contacto)
- Lidar com navegação em várias etapas (paginação, subpáginas, logins)
- Adaptar-se a conteúdo dinâmico (rolagem infinita, dados carregados por JavaScript)
- Formatar, limpar ou transformar os dados à medida que são extraídos
Porque é que isto importa? Porque as necessidades reais de negócio raramente são simples. Talvez precise de extrair listagens de produtos e depois seguir cada link para captar especificações detalhadas e avaliações. Ou talvez queira monitorizar preços da concorrência em dezenas de páginas, mas apenas para certos SKUs. Ferramentas padrão falham, deixam dados escapar ou obrigam-no a virar um detetive amador de HTML. Já os serviços de extração personalizada são feitos para estes cenários — muitas vezes com ajuda de IA e processamento de linguagem natural.
Para uma análise mais profunda da diferença entre scraping personalizado e padrão, confira .
Por que os Serviços de Extração Personalizada de Dados Importam para o Crescimento do Negócio
Vamos ao prático. Porque é que se deveria importar com a extração personalizada de dados? Porque isto não é apenas uma atualização técnica — é um acelerador de negócio. Veja como os serviços de extração personalizada geram resultados reais:
| Necessidade de Negócio | Solução Personalizada de Scraping de Dados | Resultado/ROI Típico |
|---|---|---|
| Geração de Leads | Extraia contactos atualizados de diretórios, LinkedIn ou sites de avaliações | Até 80% de redução no tempo de pesquisa manual; listas de leads maiores e mais relevantes |
| Monitorização de Preços da Concorrência | Acompanhe preços e stock nos sites dos concorrentes, mesmo com layouts dinâmicos | Aumento de vendas acima de 4% com preços dinâmicos; melhoria de margem de até 15% |
| Inteligência de Mercado e Pesquisa | Agregue notícias, avaliações ou documentos regulatórios em escala | Crescimento de 50%+ no uso de dados; decisões mais rápidas e bem informadas |
| Atualização de Catálogo de Produtos | Puxe informações de produtos de várias fontes, lidando com subpáginas e variantes | Catálogos sempre atualizados; menos erros e menos atualizações manuais |
| Automação Operacional | Agende scrapes recorrentes para relatórios, compliance ou stock | 85% mais rapidez para levar dados ao mercado; 73% de redução nos custos de recolha |
(, )
A conclusão é simples: a extração personalizada não é luxo — é uma necessidade competitiva. As empresas que a dominam estão a superar rivais, a reagir mais depressa às mudanças do mercado e a descobrir insights que impulsionam o crescimento.
A abordagem da Thunderbit: extração personalizada de dados, do jeito mais simples
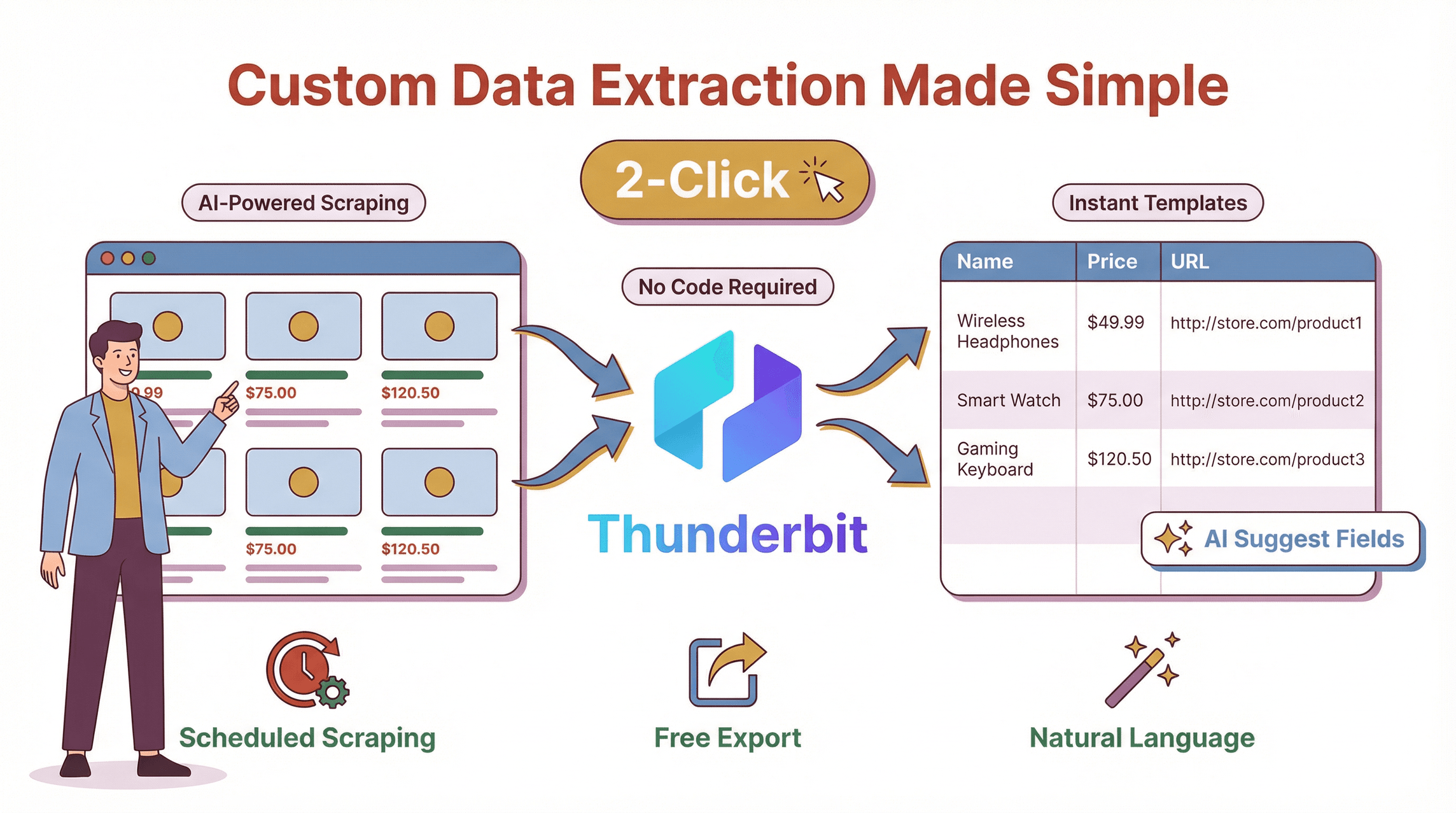
Agora, falando com sinceridade: criei a Thunderbit porque estava cansado de ver equipas a lutar com scrapers pesados, cheios de código, que partiam sempre que um site mudava um detalhe. A Thunderbit é uma pensada para tornar a extração personalizada de dados acessível a toda a gente — e não apenas a programadores.
O que distingue a Thunderbit:
- Sugestões de campos com IA: Clique em “AI Suggest Fields” e a Thunderbit analisa a página, recomendando as melhores colunas para extrair — como “Nome do Produto”, “Preço”, “URL da Imagem” ou “Email”. Sem adivinhação e sem mexer em seletores.
- Prompt em linguagem natural: Quer extrair uma data, traduzir uma descrição ou categorizar itens? Basta dizer em inglês simples. A IA descobre como fazer.
- Scraping em 2 cliques: Aceda ao site-alvo, abra a Thunderbit e clique em “Scrape”. Só isso. Sem código, sem modelos (a não ser que queira), sem dores de cabeça.
- Lida com páginas complexas: A Thunderbit consegue lidar com paginação, rolagem infinita, subpáginas e até conteúdo dinâmico carregado por JavaScript. Adapta-se à medida que os sites mudam.
- Scraping de subpáginas: Precisa de mais detalhes de cada item? A Thunderbit pode visitar automaticamente cada subpágina (como páginas de detalhes de produto) e enriquecer a sua tabela.
- Scraping agendado: Configure extrações recorrentes com linguagem natural (“todas as segundas-feiras às 9h”) e deixe a Thunderbit tratar do resto.
- Modelos instantâneos: Para sites populares como Amazon, Zillow ou LinkedIn, a Thunderbit oferece modelos de 1 clique — sem configuração.
- Exportação de dados gratuita: Exporte os seus dados para Excel, Google Sheets, Airtable, Notion, CSV ou JSON — sem paywall, sem limites.
A missão da Thunderbit é simples: deixar que os utilizadores de negócio descrevam o que querem e deixar a IA assumir o trabalho técnico pesado. É como ter um assistente de pesquisa com IA que nunca se cansa (e nunca reclama do café).
Passo a passo: usando a Thunderbit para scraping personalizado de dados
Vamos percorrer um fluxo real de extração personalizada com a Thunderbit. Vou usar um exemplo de catálogo de produtos, mas os passos são parecidos para leads, avaliações ou qualquer outra coisa.
Passo 1: Instale a Thunderbit
Acesse a e adicione-a ao navegador. Crie uma conta gratuita — não é necessário cartão de crédito no plano grátis.
Passo 2: Abra o site-alvo
Vá até a página que quer extrair (por exemplo, uma página de categoria com listagens de produtos).
Passo 3: Inicie a Thunderbit e use AI Suggest Fields
Clique no ícone da Thunderbit. Toque em “AI Suggest Fields” — a IA da Thunderbit vai analisar a página e sugerir colunas como “Nome do Produto”, “Preço”, “URL da Imagem” etc. Pode renomear, adicionar ou remover campos conforme necessário.
Passo 4: Personalize com prompts de IA por campo
Quer extrair algo específico? Para cada campo, pode adicionar uma instrução personalizada — como “extraia a data no formato YYYY-MM-DD” ou “traduza a descrição para espanhol”. A IA da Thunderbit aplicará a sua regra durante a extração.
Passo 5: Ative a paginação ou o scraping de subpáginas (se necessário)
Se os seus dados estiverem distribuídos por várias páginas, ative a Paginação. Se precisar de detalhes de subpáginas (como páginas de detalhes de produto), use o Scraping de Subpáginas — a Thunderbit visitará cada link e levará informações extra para a tabela.
Passo 6: Clique em “Scrape” e veja os dados fluírem
A Thunderbit vai extrair os seus dados, lidando automaticamente com navegação e formatação. Verá uma tabela de pré-visualização enquanto o processo acontece.
Passo 7: Exporte seus dados
Quando estiver satisfeito com o resultado, exporte diretamente para . Também pode descarregar em CSV ou JSON.
Pronto. Sem código, sem modelos (a não ser que queira), e sem aqueles momentos de “porque é que isto não está a funcionar?”. Para mais detalhes, confira .
Comparando a Thunderbit com outros serviços de extração de dados
Vamos ficar um pouco nerd agora. Como a Thunderbit se compara a outros serviços de extração de dados, como o Azure AI Document Intelligence ou scrapers tradicionais?
| Recurso / Critério | Thunderbit | Azure AI Document Intelligence | Scrapers Tradicionais (ex.: Octoparse, Scrapy) |
|---|---|---|---|
| Facilidade de uso | Sem código, orientado por IA, configuração em 2 cliques | Voltado a programadores, baseado em API | Curva de aprendizagem acentuada, muitas vezes exige código |
| Extração personalizada | Prompts em linguagem natural, IA por campo | Modelos de ML personalizados para documentos | Configuração manual, seletores, scripts |
| Lida com páginas web | Sim (HTML, dinâmico, subpáginas) | Não (focado em documentos/PDFs) | Sim, mas sofre com sites dinâmicos |
| Lida com documentos/PDFs | Sim (via navegador/modo PDF) | Sim (OCR, ML) | Às vezes, mas com limitações |
| Adaptabilidade | A IA adapta-se a mudanças de layout | O ML adapta-se a novos documentos | Parte-se com mudanças no site, exige atualizações |
| Agendamento | Integrado, em linguagem natural | Via API, precisa de integração | Às vezes, mas é complexo |
| Opções de exportação | Sheets, Excel, Airtable, Notion, CSV, JSON | API/JSON, precisa de integração | CSV, Excel, base de dados, varia |
| Suporte | SaaS moderno, responsivo | Corporativo, suporte formal | Comunidade ou fornecedor, varia |
| Preço | Plano grátis, créditos conforme uso | Baseado em uso, foco corporativo | Grátis (open source) ou planos mensais |
O ponto forte da Thunderbit é a extração de dados da web para utilizadores de negócio que querem poder sem sofrimento. O Azure é excelente para processamento de documentos em escala, mas não para rastrear sites. Scrapers tradicionais são poderosos nas mãos certas, mas exigem competências técnicas e manutenção constante.
Para uma comparação mais profunda, veja .
Como escolher o serviço certo de extração personalizada de dados para suas necessidades
Escolher um serviço de extração de dados não é só uma questão de funcionalidades — é uma questão de adequação. Aqui vai uma checklist para orientar a sua decisão:
- Qualidade e fiabilidade dos dados: Entrega dados precisos, limpos e completos? Dá para testar nos sites-alvo?
- Flexibilidade e personalização: Lida com os seus sites específicos, conteúdo dinâmico, logins ou subpáginas? Consegue definir campos ou transformações personalizadas?
- Conformidade e ética: Segue orientações legais e éticas? Respeita leis de privacidade e termos dos sites?
- Escalabilidade e desempenho: Aguenta o seu volume e frequência de dados? Oferece scraping na nuvem ou processamento paralelo?
- Integração e fluxo de trabalho: É possível exportar os dados para as suas ferramentas (Sheets, Excel, CRM etc.)? Tem agendamento ou automação?
- Suporte e documentação: Há suporte rápido e documentação clara? Existem tutoriais ou base de conhecimento?
- Segurança: Trata os seus dados de forma segura? As informações de login são encriptadas? Há certificações de conformidade?
- Custo: O preço é transparente e custo-efetivo para o seu caso? Existem taxas ocultas ou paywalls?
Teste cada opção na prática. Extraia um site real, exporte os dados e veja como isso se encaixa no seu fluxo de trabalho. Para mais dicas, confira .
Integrando o scraping personalizado de dados aos fluxos de trabalho da sua empresa
Extrair dados é só metade da batalha — o valor real vem de transformar isso numa parte das operações diárias. Veja como incorporar a extração personalizada de dados ao seu negócio:
- Automatize tarefas recorrentes: Use scraping agendado para manter os dados sempre atualizados — verificações diárias de preço, atualizações semanais de leads etc.
- Alimente as suas ferramentas com os dados: Exporte diretamente para . Use Zapier, Make ou n8n para automatizar ainda mais (por exemplo, enviar novos leads para o seu CRM).
- Configure alertas: Integre com Slack ou email para receber notificações sobre alterações importantes — como um concorrente a baixar preços ou o lançamento de um novo produto.
- Colabore na nuvem: Use bases de dados partilhadas (Airtable, Notion) para tornar os dados extraídos acessíveis entre equipas.
- Automatize de ponta a ponta: Combine scraping com ferramentas de BI (Tableau, Power BI) para dashboards em tempo real, ou dispare ações (como reajuste de preços) com base nos dados extraídos.
Para inspiração, confira .
Melhores práticas para maximizar o valor dos serviços de extração personalizada de dados
Quer tirar o máximo da sua iniciativa de extração personalizada? Aqui está o que aprendi — às vezes da forma mais difícil:
- Defina metas claras: Saiba exatamente de que dados precisa e porquê. Não extraia só porque pode — extraia com propósito.
- Comece pequeno, teste sempre: Faça pilotos pequenos, verifique os dados e escale quando tiver confiança.
- Monitore a qualidade dos dados: Faça verificações pontuais com frequência. Configure regras de validação ou alertas para anomalias.
- Otimize a frequência: Extraia com a frequência necessária, mas não mais do que isso. Excesso de scraping pode fazer com que seja bloqueado (e irritar a sua equipa de TI).
- Mantenha ética e conformidade: Respeite os termos dos sites, as leis de privacidade e as orientações éticas. Não extraia dados sensíveis ou restritos.
- Aproveite prompts de campo: Use prompts de IA para limpar, formatar ou enriquecer os dados durante a extração.
- Proteja os seus dados: Trate credenciais e dados extraídos com cuidado — use encriptação e controlos de acesso.
- Documente o processo: Registe o que está a ser extraído, de onde e com que frequência. Isso vai poupar dores de cabeça depois.
- Itere e melhore: Trate a extração personalizada como um processo evolutivo. Ajuste a sua abordagem conforme as necessidades mudam.
Para mais sobre boas práticas, veja .
Conclusão e principais aprendizados: eleve sua estratégia de dados com extração personalizada
Serviços de extração personalizada de dados e de scraping de dados não são só para fanáticos por dados — são ferramentas indispensáveis para qualquer empresa que queira agir depressa, manter a competitividade e tomar decisões mais inteligentes. A era de copiar e colar manualmente e de scripts frágeis acabou. Com ferramentas com IA como , qualquer pessoa pode dominar a extração personalizada — sem precisar programar.
O que deve lembrar:
- Extração personalizada = extração relevante. Obtenha os dados certos, não apenas mais dados.
- O valor de negócio é real. De vendas a operações e pesquisa de mercado, o scraping personalizado entrega ROI concreto.
- A facilidade de uso chegou. Ferramentas como a Thunderbit democratizam a extração de dados para todos.
- Integração é tudo. Faça com que os dados extraídos virem parte do fluxo de trabalho diário, não um silo.
- Escolha com cuidado. Combine a ferramenta com as suas necessidades — teste, compare e ajuste.
- Boas práticas fazem diferença. Metas claras, verificação de qualidade e padrões éticos mantêm a sua estratégia de dados forte.
Pronto para elevar o nível da sua estratégia de dados? e faça uma extração personalizada num problema real de negócio. Ou, se quiser ir ainda mais fundo, confira o para conteúdos aprofundados, tutoriais e as novidades em extração de dados com IA.
A web é uma mina de ouro de insights — a extração personalizada é a sua picareta. Boas extrações!
FAQs
1. O que é extração personalizada de dados e como ela difere do scraping padrão?
Extração personalizada de dados significa adaptar o seu scraping para capturar exatamente os dados de que precisa, no formato desejado, de qualquer site — mesmo que ele seja complexo ou dinâmico. Diferente das ferramentas padrão, que apanham o que for mais fácil, a extração personalizada adapta-se às necessidades do seu negócio e às mudanças de layout do site.
2. Quem mais se beneficia dos serviços de extração personalizada de dados?
Equipas de vendas (para leads), marketing (para monitorização da concorrência), operações (para automação), gestores de produto (para atualização de catálogos) e investigadores de mercado (para inteligência) veem ganhos enormes com a extração personalizada — especialmente quando as ferramentas padrão não dão conta.
3. Como a Thunderbit facilita a extração personalizada?
A Thunderbit usa IA para sugerir campos, lidar com navegação complexa (paginação, subpáginas) e permitir que descreva o que quer em inglês simples. Sem código, sem modelos (a não ser que queira), e exportação instantânea para as suas ferramentas favoritas.
4. O que devo procurar ao escolher um serviço de extração de dados?
Foque na qualidade dos dados, flexibilidade, conformidade, escalabilidade, opções de integração, suporte, segurança e custo. Teste cada serviço com necessidades reais antes de fechar.
5. Como posso integrar o scraping personalizado de dados aos fluxos de trabalho da minha empresa?
Automatize tarefas recorrentes, exporte dados para Sheets/Excel/Notion, configure alertas e use ferramentas de fluxo de trabalho como Zapier ou n8n. O objetivo: fazer com que os dados da web virem uma parte viva das operações diárias, não um projeto pontual.
Pronto para ver o que a extração personalizada pode fazer pelo seu negócio? e comece a transformar o caos da web em clareza para o negócio.
Saiba mais