O universo digital não para de mudar — e a web vai junto nessa velocidade. Depois de anos mergulhado em SaaS e automação, percebi uma coisa: muitas vezes, o melhor jeito de evoluir é aprendendo com o que já está funcionando. Seja para analisar concorrentes, criar um produto novo ou só garantir um backup do seu próprio site, a habilidade de clonar qualquer site — capturando conteúdo, estrutura ou até funcionalidades — pode dar um gás enorme para times de negócios. E com o avanço de ferramentas com IA como o , aquilo que antes era só para devs agora está disponível para qualquer um com um navegador na mão.
Mas vamos ser realistas: clonar um site vai muito além de clicar em “Salvar Como” e achar que está resolvido. Os sites de hoje são dinâmicos, cheios de interatividade e, às vezes, parecem até sabão molhado de tão difíceis de pegar. Neste guia, vou te mostrar o que realmente significa “clonar qualquer site”, por que isso faz diferença para negócios, os perrengues que aparecem no caminho e — o mais importante — como fazer isso de um jeito seguro, eficiente e dentro da lei usando ferramentas modernas como o Thunderbit.
Clonar Qualquer Site: O Que Isso Quer Dizer na Prática?
Vamos direto ao ponto. Quando falamos em “clonar um site”, isso pode envolver várias coisas:
- Clonar o visual: Recriar o site com a mesma cara e experiência do original.
- Clonar o conteúdo: Copiar textos, imagens, informações de produtos e tudo que aparece na tela.
- Clonar funcionalidades: Replicar recursos como buscas, formulários ou elementos interativos.
Para a maioria dos profissionais de negócios, o que importa mesmo é copiar o conteúdo e os dados visíveis — aquilo que dá para ver e analisar, sem precisar do código-fonte ou da lógica interna. É como tirar uma foto da “fachada” pública do site e transformar em dados organizados para análise, prototipagem ou arquivamento.
E antes que você pense besteira: clonar não é sinônimo de roubo ou plágio. Na real, a maioria dos usos é totalmente legítima — como pesquisa de mercado, prototipagem rápida ou backup offline para compliance. O objetivo é ganhar tempo e tirar insights do que já funciona, não copiar na cara dura ou desrespeitar direitos de ninguém.
Por Que Clonar Qualquer Site? Usos Que Fazem a Diferença no Negócio
Você pode até se surpreender com a quantidade de times que usam clonagem de sites no dia a dia. Olha só alguns exemplos:
| Aplicação | Descrição & Benefício para o Negócio |
|---|---|
| Monitoramento de Preços de Concorrentes | Extraia páginas de produtos dos concorrentes para acompanhar preços e estoque. Permite precificação dinâmica — um varejista do Reino Unido teve um aumento de 4% nas vendas. |
| Geração de Leads & Enriquecimento de CRM | Clone diretórios ou páginas do LinkedIn para captar leads. Automatizando, é possível economizar até 80% do tempo. |
| Reaproveitamento de Conteúdo | Duplique FAQs, posts de blog ou avaliações para curar insights ou adaptar informações para seu público. |
| Prototipagem Rápida & Design | Clone o front-end de sites existentes para acelerar novos projetos — prototipe em dias, não semanas. |
| Backup & Arquivamento | Crie cópias completas de sites para compliance ou registro histórico. |
E isso é só o começo. Pesquisadores podem clonar páginas de redes sociais para analisar tendências, especialistas em SEO copiam estruturas de sites para estudar offline, e quase dependem de dados extraídos da web para funcionar. O segredo está na agilidade e nos insights — em vez de perder tempo coletando dados manualmente ou refazendo layouts, você pega tudo de uma vez.
Os Desafios de Clonar Qualquer Site: Não É Só Copiar e Colar
Se clonar site fosse só “Copiar > Colar”, todo mundo já fazia. Mas quem já tentou sabe que a história é outra.
Por Que Só Copiar Não Resolve
- Conteúdo Dinâmico: Muitos sites carregam dados via JavaScript, então um simples “Salvar página” pode te deixar só com um esqueleto vazio ().
- APIs e Scripts: Parte do conteúdo só aparece depois que a página carrega, puxado por APIs. Copiar o HTML não pega esses dados.
- Login Obrigatório: Se o conteúdo está atrás de login, só uma ferramenta que entende sessões autenticadas resolve.
- Barreiras Anti-Scraping: Sites podem usar CAPTCHAs, limitar acessos ou detectar bots para bloquear automações.
- Limites Legais e Éticos: Só porque dá para copiar, não quer dizer que pode. Direitos autorais e termos de uso são coisa séria.
Ou seja, clonar site envolve tanto desafios técnicos quanto éticos. Não basta pegar os dados — tem que fazer do jeito certo e com responsabilidade.
Comparando Ferramentas para Clonar Sites: Do Manual à Força da IA
Vamos falar de ferramentas. Existem alguns jeitos principais de clonar um site, cada um com seus prós e contras:
| Método | Facilidade de Uso | Precisão | Conteúdo Dinâmico | Opções de Exportação | Conformidade Legal | Manutenção |
|---|---|---|---|---|---|---|
| Cópia/Download Manual | Moderada | Baixa | Ruim | HTML/CSS/JS | Depende do usuário | Alta (quebra fácil) |
| Web Scraping Tradicional | Baixa | Alta* | Boa* | CSV/Excel/JSON | Depende do usuário | Alta (frágil) |
| Ferramentas com IA (Thunderbit) | Muito Alta | Alta | Excelente | Excel/Sheets/Notion | Amigável | Baixa |
*Se você souber configurar direitinho.
Cópia/Download Manual
Ferramentas como HTTrack ou o “Salvar Como” do navegador funcionam para sites estáticos simples, mas são e não dão conta de sites dinâmicos. O resultado? Imagens faltando, estilos quebrados e uma pasta cheia de arquivos bagunçados.
Web Scraping Tradicional
Aqui entram scripts (Python, BeautifulSoup, etc.) ou scrapers visuais onde você define o que extrair. É poderoso, mas . E se o site muda, o scraper quebra — manutenção é um saco.
Ferramentas com IA (Thunderbit)
Aqui está o pulo do gato. O usa IA para “entender” a página, sem você precisar mapear cada campo. Só clicar em “AI Sugerir Campos”, deixar a IA identificar os dados e pronto. Ele lida com conteúdo dinâmico, navegação entre páginas e exporta direto para Excel, Google Sheets, Airtable ou Notion. E foi feito para quem não é técnico — nada de código.
Quer saber mais sobre extensões de 웹 스크래퍼 para Chrome? Veja .
Passo a Passo: Como Clonar Qualquer Site com o Thunderbit
Pronto para colocar a mão na massa? Veja como eu clono qualquer site usando o Thunderbit, passo a passo.
Passo 1: Instale e Configure o Thunderbit
Acesse o e crie sua conta gratuita. Depois, instale a . É igual instalar qualquer outra extensão — rapidinho.
Depois de instalar, o ícone do Thunderbit aparece na barra do Chrome. Clique, faça login e comece seu primeiro projeto. Dica: fixe o ícone para facilitar. Se for extrair dados de um site que exige login, faça login antes de começar — o Thunderbit funciona com a sessão ativa do navegador.
Passo 2: Use IA para Identificar e Estruturar os Dados
Acesse o site que você quer clonar (por exemplo, a página de produtos de um concorrente). Abra o painel lateral do Thunderbit e inicie um novo projeto de extração. O diferencial: clique em “AI Sugerir Colunas” (ou “AI Sugerir Campos”) e a IA do Thunderbit analisa a página, sugerindo automaticamente campos como Nome do Produto, Preço, URL da Imagem, Avaliação e outros.
Você pode revisar, ajustar ou adicionar colunas do jeito que quiser. Quer pegar um campo extra, tipo “Disponibilidade” ou “SKU”? Só adicionar, e a IA tenta preencher. Não precisa saber nada de HTML — a IA faz o trabalho pesado.
Passo 3: Extraia e Exporte os Dados do Site
Com as colunas definidas, clique em “Extrair” (ou “Iniciar”). O Thunderbit vai coletar todos os dados dos campos selecionados, linha por linha. Se a página tiver vários itens (tipo uma lista de produtos), ele pega tudo.
E se tiver paginação ou rolagem infinita? O Thunderbit resolve a maioria dos casos sozinho — se tiver botão “Próximo” ou carregamento por rolagem, ele segue. Em casos mais chatos, talvez você precise rolar manualmente ou ajustar as configs, mas para a maioria dos sites de negócios, é tranquilo.
No final, seus dados aparecem em uma tabela organizada. Exportar é fácil: direto para Excel, Google Sheets, Airtable ou Notion. Chega de malabarismo com CSV — só dados prontos para usar.
Para mais detalhes, confira o .
Potencialize Sua Cópia: Extração de Subpáginas para Clonagem Completa
Aqui é onde o Thunderbit brilha: extração de subpáginas. Muitos sites mostram só resumos na página principal (tipo nomes e preços), mas os detalhes — descrições, especificações, avaliações — ficam em subpáginas.
A extração de subpáginas do Thunderbit vai além. Ative esse recurso e a IA segue os links da página principal para cada página de detalhe, pegando informações extras e juntando tudo no seu conjunto de dados. Por exemplo, ao clonar a categoria “jaquetas de inverno” de um e-commerce, o Thunderbit pode acessar cada página de produto e extrair materiais, disponibilidade, avaliações de clientes e mais — entregando uma cópia completa e organizada de toda a linha de produtos.
Isso economiza um tempão para times de negócios. Seja para montar uma lista de leads, arquivar uma base de conhecimento ou analisar um catálogo inteiro, a extração de subpáginas garante que nada fique de fora.
Para ver na prática, confira a .
Garantindo Conformidade: Clone Qualquer Site de Forma Legal e Segura
Vamos ao que interessa: É legal clonar qualquer site?
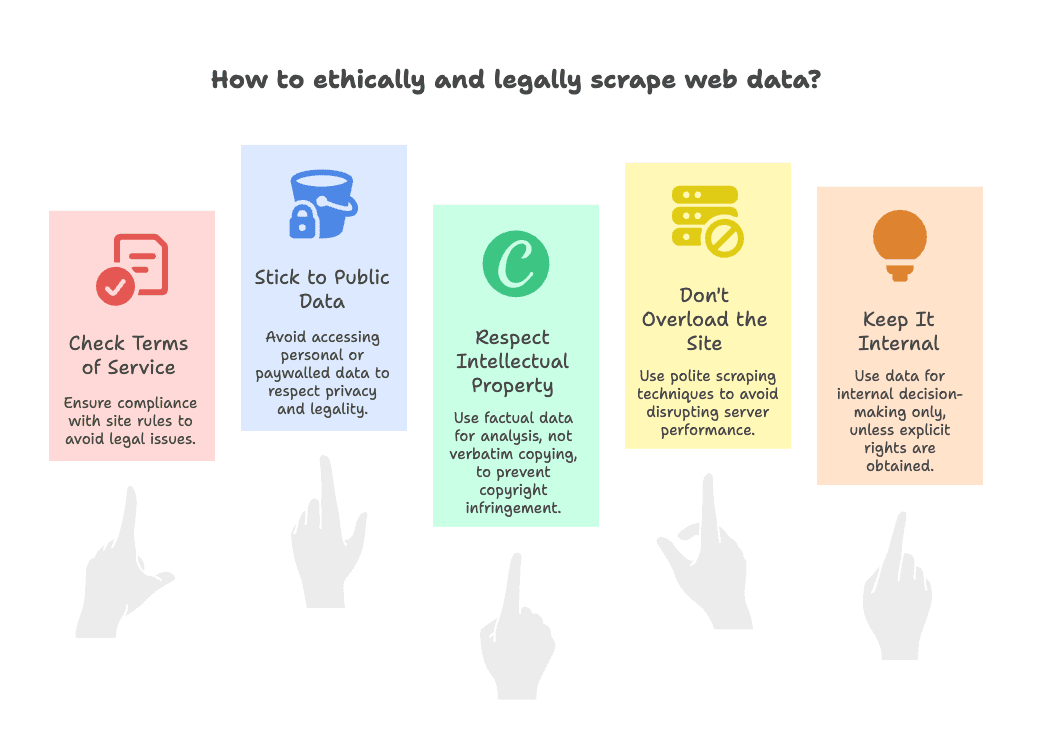
Resposta rápida: geralmente sim, desde que você siga algumas regrinhas. Olha meu checklist de conformidade:
- Confira os Termos de Uso: Alguns sites proíbem a extração de dados. Se for o caso, use os dados só internamente, nada de republicar ().
- Pegue Só Dados Públicos: Extraia só o que está visível sem login. Evite dados pessoais, e-mails ou conteúdos atrás de paywall ().
- Respeite a Propriedade Intelectual: Dados factuais (preços, nomes de produtos) geralmente são liberados. Copiar conteúdo criativo (posts, imagens) pode dar problema de direitos autorais — use para análise, não para criar um site clone ().
- Não Sobrecarregue o Site: Faça extrações de forma educada — nada de milhares de acessos em segundos. O Thunderbit já limita a taxa, mas sempre seja cuidadoso ().
- Uso Interno Sempre: Salvo autorização, use os dados clonados só para decisões internas, não para redistribuir.
O Thunderbit facilita a conformidade ao permitir exportação direta para plataformas seguras como Google Sheets ou Airtable, mantendo os dados organizados e só para uso da sua equipe. Para mais dicas legais, veja .
Dicas Avançadas: Como Tirar o Máximo do Thunderbit ao Clonar Sites
Depois de pegar o jeito, olha algumas estratégias para turbinar sua clonagem de sites:
- Sites Dinâmicos e Interativos: Para conteúdos que aparecem só depois de clicar (tipo “Ver Todas as Avaliações”), faça a ação manualmente e depois rode o Thunderbit. A IA pega o que está visível. Para rolagem infinita, vá rolando aos poucos ou use o suporte de paginação ().
- Prompts Personalizados de IA: Dê nomes específicos para as colunas — tipo “Autor (texto após Por:)” ou “Resumo dos Prós”. A IA do Thunderbit entende o contexto, então nomes claros funcionam como mini-instruções ().
- IA para Transformação de Dados: Use o Resumo com IA do Thunderbit ou integre com ferramentas como ChatGPT para analisar, categorizar ou traduzir dados em tempo real ().
- Agendamento para Clonagens Recorrentes: Programe extrações automáticas para monitorar sites ao longo do tempo — ótimo para acompanhar preços de concorrentes ou novas vagas ().
- Extração em Massa de URLs: Passe uma lista de URLs para o Thunderbit e ele extrai de todas automaticamente — perfeito se você já tem os links.
- Modelos para Sites Populares: Use modelos prontos do Thunderbit para sites como Amazon ou Zillow e personalize como quiser ().
- Casos Especiais: Se aparecer CAPTCHA ou layout estranho, tente rodar o scraper em duas etapas ou ajustar as colunas. A IA do Thunderbit é robusta, mas uma revisão rápida sempre ajuda.
Para fluxos de trabalho ainda mais avançados, confira as .
Conclusão & Principais Lições: Clone Qualquer Site com Segurança
Clonar qualquer site não é mais coisa só de desenvolvedor — é uma técnica acessível que empodera times de vendas, marketing e operações. O que você precisa lembrar:
- Valor para o Negócio: Clonagem de sites traz ROI real — seja para superar concorrentes, economizar tempo ou tomar decisões mais inteligentes ().
- Desafios & Soluções: Sites modernos são complexos, mas ferramentas como o Thunderbit tornam a clonagem precisa, rápida e fácil — mesmo para quem não é técnico.
- Vantagem Thunderbit: Com recursos como “AI Sugerir Colunas” e extração de subpáginas, o Thunderbit transforma horas de trabalho manual em poucos cliques.
- Conformidade é Essencial: Sempre clone de forma responsável — use só dados públicos, respeite PI e utilize os dados para análise ou decisões internas.
- Vá Além: Com dicas avançadas e integrações, o Thunderbit encara até os sites e fluxos mais desafiadores.
Então, da próxima vez que você topar com a página de produtos de um concorrente, um diretório de leads ou uma base de conhecimento que gostaria de analisar — lembre: você tem as ferramentas para clonar os dados desse site com confiança. Use esse poder com responsabilidade e que seus projetos orientados por dados voem alto.
Perguntas Frequentes
1. É legal clonar qualquer site para uso empresarial?
Na maioria dos casos, sim — se você ficar só nos dados públicos, respeitar a propriedade intelectual e usar os dados internamente. Sempre confira os termos de uso do site e evite extrair conteúdos pessoais ou protegidos por direitos autorais sem permissão. Para mais detalhes, veja .
2. Qual a diferença entre clonar e fazer scraping de um site?
Clonar normalmente é copiar o conteúdo, estrutura ou design de um site, enquanto scraping é o processo de extrair dados específicos. Com ferramentas como o Thunderbit, a linha fica tênue — você pode extrair e estruturar dados para “clonar” só as partes que precisa.
3. O Thunderbit lida com conteúdo dinâmico e subpáginas?
Sim! A IA do Thunderbit foi feita para lidar com conteúdo dinâmico (dados carregados via JavaScript) e pode seguir links para extrair subpáginas, juntando tudo em um único conjunto de dados. É um dos jeitos mais fáceis de conseguir uma cópia completa de um site.
4. Como exportar os dados clonados para Excel ou Google Sheets?
Depois de extrair com o Thunderbit, você pode exportar os dados direto para Excel, Google Sheets, Airtable ou Notion em poucos cliques. Não precisa formatar nada — os dados já ficam prontos para análise ou compartilhamento.
5. Quais dicas avançadas para clonar sites mais complexos?
Use prompts personalizados de IA para extrair campos específicos, agende extrações regulares para monitoramento contínuo e aproveite os recursos de extração em massa e modelos do Thunderbit para ganhar eficiência. Em sites interativos, faça as ações manualmente antes de extrair e sempre revise os dados para garantir precisão.