
Se você já tentou extrair dados de um site que só mostra o conteúdo conforme você vai descendo a página, esconde preços atrás de login ou vive mudando o visual, sabe bem o perrengue que é. Os raspadores estáticos já não dão mais conta do recado. Para ter uma ideia, mais de já usam raspagem de dados para buscar informações alternativas, e automatizam o monitoramento de preços dos concorrentes. Mas olha só: a maior parte desses dados está em sites dinâmicos, cheios de JavaScript e protegidos por interações de usuário. É aí que entra a automação com navegador headless — e ferramentas como o Puppeteer.
Falando como alguém que já passou anos desenvolvendo automações e IA (e, claro, raspando muitos sites para times de vendas e operações), posso dizer que o Puppeteer chega onde raspadores tradicionais não chegam. Mas também sei que programar pode ser um baita obstáculo para muita gente de negócios. Por isso, neste guia, vou te mostrar o que é o Puppeteer scraper, como usar para raspagem de dados e quando vale mais a pena apostar em algo ainda mais simples — tipo o , nosso raspador web IA sem código.
O que é o Puppeteer Scraper? Visão Geral
 Vamos do começo. O é uma biblioteca open-source do Node.js criada pelo Google, que permite controlar o Chrome ou Chromium em modo headless usando JavaScript. Em outras palavras: é como ter um robô que abre páginas, clica em botões, preenche formulários, rola a tela e — o mais importante — extrai dados, tudo sem aparecer nada na sua tela.
Vamos do começo. O é uma biblioteca open-source do Node.js criada pelo Google, que permite controlar o Chrome ou Chromium em modo headless usando JavaScript. Em outras palavras: é como ter um robô que abre páginas, clica em botões, preenche formulários, rola a tela e — o mais importante — extrai dados, tudo sem aparecer nada na sua tela.
Por que o Puppeteer é diferente?
- Ele consegue renderizar conteúdo dinâmico — ou seja, espera o JavaScript carregar, igualzinho a um usuário real.
- Pode simular ações humanas: clicar, digitar, rolar a página e até lidar com pop-ups.
- É perfeito para raspar sites onde os dados só aparecem depois de alguma ação, tipo listas de e-commerce, feeds de redes sociais ou dashboards.
Comparando com outras ferramentas:
- Selenium: O clássico da automação de navegador. Funciona em vários browsers e linguagens, mas é mais pesado e tradicional. Ótimo para testes em múltiplos navegadores, mas o Puppeteer é mais ágil para projetos em Chrome/Node.js.
- Thunderbit: Aqui está o pulo do gato. O Thunderbit é um raspador web IA sem código, que roda direto no seu navegador. Em vez de escrever scripts, é só clicar em “Sugerir Campos com IA” e deixar a inteligência artificial identificar o que extrair. Ideal para quem quer resultado sem programar (já já falo mais sobre isso).
Resumindo: Puppeteer = controle total (para quem programa). Thunderbit = praticidade máxima (para quem não quer programar).
Por que a Raspagem Web com Puppeteer é Importante para Empresas
Vamos falar a real: raspagem de dados não é mais coisa só de hacker ou cientista de dados. Times de vendas, operações, marketing e até imobiliárias usam dados da web para sair na frente. E com tanta informação estratégica escondida em sites dinâmicos, o Puppeteer muitas vezes é a chave para acessar esses dados.
Olha só alguns exemplos práticos:
| Caso de Uso | Quem se Beneficia | Impacto / ROI |
|---|---|---|
| Geração de leads | Vendas, Desenvolvimento | Automatiza listas de prospecção; economiza 8+ horas/semana por representante (case study) |
| Monitoramento de preços | E-commerce, Produto | Acompanhamento em tempo real dos concorrentes; uma empresa economizou US$ 3,8 milhões/ano (fonte) |
| Pesquisa de mercado | Marketing, Estratégia, Finanças | 67% dos consultores usam dados raspados; até 890% de ROI em alguns casos (fonte) |
| Agregação imobiliária | Corretores, Analistas | Raspa 50+ páginas de imóveis em minutos, não horas (fonte) |
| Monitoramento de compliance | Operações, Jurídico | Automatiza o acompanhamento; uma seguradora evitou US$ 50 milhões em multas (fonte) |
E não dá pra esquecer: gastam um quarto da semana em tarefas repetitivas como coleta de dados. Automatizar isso com raspagem web não é só diferencial — é vantagem competitiva.
Começando: Como Configurar seu Puppeteer Scraper
Bora colocar a mão na massa? Veja como rodar o Puppeteer em menos de 10 minutos (se você já manja um pouco de JavaScript):
1. Instale o Node.js
O Puppeteer roda em Node.js. Baixe a versão LTS mais recente em .
2. Crie uma nova pasta para o projeto
Abra o terminal e rode:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Instale o Puppeteer
1npm install puppeteerIsso já baixa uma versão do Chromium compatível (cerca de 100MB).
4. Crie seu primeiro script
Crie um arquivo chamado scrape.js:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Page title:', title);
8 await browser.close();
9})();Execute com:
1node scrape.jsSe aparecer “Page title: Example Domain”, parabéns — você já automatizou o Chrome!
Criando seu Primeiro Script de Raspagem Web com Puppeteer
Vamos pra prática. Suponha que você queira raspar citações do (um site de teste para raspadores).
Passo 1: Acesse a página
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Passo 2: Extraia os dados
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Passo 3: Lide com a paginação
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Extraia as citações como acima
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Passo 4: Salve em JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Pronto — um raspador básico com Puppeteer que navega, extrai, pagina e salva os dados.
Técnicas Avançadas com Puppeteer Scraper: Lidando com Conteúdo Dinâmico
A maioria dos sites reais não é tão simples quanto uma lista estática. Veja como encarar os desafios:
1. Esperando elementos dinâmicos
1await page.waitForSelector('.product-list-item');Assim você garante que o conteúdo que quer já carregou antes de tentar capturar.
2. Simulando ações do usuário
- Clicar em um botão:
await page.click('#load-more'); - Digitar em um campo:
await page.type('#search', 'laptop'); - Rolar para carregar mais (scroll infinito):
1let previousHeight = await page.evaluate('document.body.scrollHeight'); 2while (true) { 3 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 4 await page.waitForTimeout(1500); 5 const newHeight = await page.evaluate('document.body.scrollHeight'); 6 if (newHeight === previousHeight) break; 7 previousHeight = newHeight; 8}
3. Lidando com login
1await page.goto('https://exampleshop.com/login');
2await page.type('#login-username', 'meuusuario');
3await page.type('#login-password', 'minhasenha');
4await page.click('#login-button');
5await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Trabalhando com dados carregados via AJAX Às vezes, os dados não estão no DOM, mas vêm de uma chamada de API. Você pode interceptar as respostas de rede assim:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Processar dados
5 }
6});Exemplo Prático: Raspando Dados de Produtos em um Site de E-commerce
Vamos juntar tudo. Imagine que você quer raspar nomes, preços e imagens de produtos de um site de e-commerce (exemplo) depois de fazer login.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Passo 1: Login
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'meuusuario');
9 await page.type('#login-password', 'minhasenha');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Passo 2: Vá para a página da categoria
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Passo 3: Extraia os produtos
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Passo 4: Salve em JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Esse script faz login, navega, raspa e salva — tudo no automático. Se precisar de algo mais avançado, dá pra adicionar laços para paginação ou até clicar em cada produto para pegar mais detalhes.
Thunderbit: Tornando o Puppeteer Scraper Mais Simples com IA
Se você chegou até aqui e pensou: “Legal, mas não quero programar toda vez que precisar de um novo conjunto de dados”, você não está sozinho. Foi exatamente por isso que criamos o .
O que faz o Thunderbit ser diferente?
- Zero código: Só instalar a , abrir a página e clicar em “Sugerir Campos com IA”.
- Detecção inteligente de campos: O Thunderbit lê a página e já sugere as melhores colunas pra extrair — tipo “Nome do Produto”, “Preço”, “Imagem” e por aí vai.
- Lida com conteúdo dinâmico: Scroll infinito, pop-ups, subpáginas? A IA do Thunderbit resolve, clicando em paginação ou visitando cada página de produto pra enriquecer seus dados.
- Exportação instantânea: Jogue seus dados direto no Excel, Google Sheets, Notion ou Airtable com um clique. Exportação sem custo extra.
- Modelos prontos para sites populares: Precisa raspar Amazon, Zillow ou LinkedIn? O Thunderbit já tem modelos prontos — sem dor de cabeça.
- Raspagem na nuvem ou no navegador: Para grandes volumes, o Thunderbit pode raspar até 50 páginas de uma vez na nuvem.
Já vi gente sair do “queria tanto esses dados” para “tá aqui minha planilha” em menos de cinco minutos. E o melhor: não precisa se preocupar se o site mudar — a IA do Thunderbit se adapta sozinha.
Puppeteer vs. Thunderbit: Qual Ferramenta de Raspagem Web Escolher?
E aí, qual usar? Veja como costumo orientar os times:
| Fator | Puppeteer (Com Código) | Thunderbit (Sem Código, IA) |
|---|---|---|
| Facilidade de uso | Exige conhecimento de JavaScript e DOM | Clique e pronto, IA sugere os campos |
| Velocidade de setup | Horas ou dias para tarefas complexas | Minutos — basta instalar e usar |
| Controle/Flexibilidade | Máximo: programe qualquer lógica personalizada, integre com outros sistemas | Alto para casos padrão; menos indicado para fluxos muito customizados |
| Conteúdo dinâmico | Script manual para waits, cliques, scrolls | IA lida automaticamente com conteúdo dinâmico, paginação e subpáginas |
| Manutenção | Você mantém os scripts — precisa atualizar quando o site muda | IA se adapta a mudanças de layout; menos manutenção para o usuário |
| Exportação de dados | Você escreve a lógica de exportação | Exportação com um clique para Excel, Sheets, Notion, Airtable, CSV, JSON |
| Melhor para | Desenvolvedores, raspagens customizadas ou em larga escala | Usuários de negócios, projetos rápidos, equipes não técnicas |
| Custo | Gratuito (exceto seu tempo e infraestrutura) | Plano gratuito disponível; planos pagos por créditos (veja Preços Thunderbit) |
Resumindo:
- Use o Puppeteer se você precisa de controle total, manja de programação ou quer integrar a raspagem em um sistema maior.
- Use o Thunderbit se quer resultado rápido, sem programar, ou precisa empoderar colegas não técnicos.
Na prática, já vi equipes usando os dois: Thunderbit para agilidade e prototipagem, Puppeteer para integrações profundas ou casos bem específicos.
Checklist: Como Conduzir um Projeto de Raspagem Web com Puppeteer
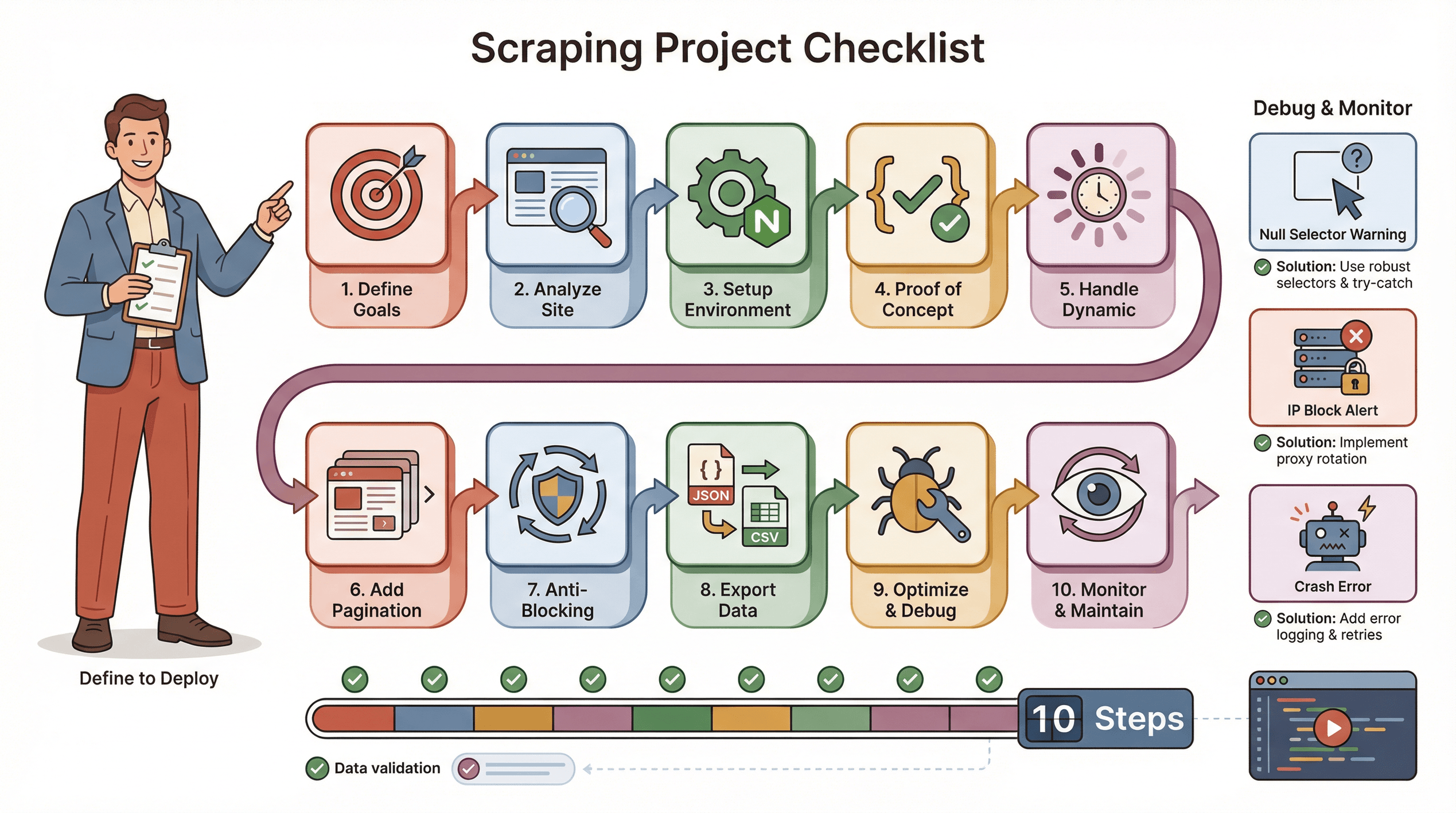 Aqui vai meu checklist para garantir um projeto de raspagem com Puppeteer sem dor de cabeça:
Aqui vai meu checklist para garantir um projeto de raspagem com Puppeteer sem dor de cabeça:
- Defina seus objetivos: Que dados você precisa? Onde estão?
- Analise o site: É dinâmico? Precisa de login? Tem bloqueio anti-bot?
- Prepare o ambiente: Node.js, Puppeteer e bibliotecas extras.
- Faça um teste inicial: Comece por uma página, acerte os seletores.
- Lide com conteúdo dinâmico: Use
waitForSelector, simule cliques/scrolls quando necessário. - Adicione paginação ou laços: Raspe todas as páginas, não só uma.
- Implemente táticas anti-bloqueio: Aleatorize delays, defina User-Agent real, use proxies se precisar.
- Exporte e valide os dados: Salve em JSON/CSV, confira se está tudo certo.
- Otimize e trate erros: Use try/catch, registre o progresso, trate dados ausentes.
- Monitore e mantenha: Sites mudam — esteja pronto pra atualizar seu script.
Dicas para resolver problemas:
- Se os seletores retornam null, revise o HTML e use waits.
- Se for bloqueado, diminua a velocidade, troque de IP ou use plugins de stealth.
- Se o script travar, veja se tem vazamento de memória ou exceções não tratadas.
Conclusão & Principais Aprendizados
A raspagem web virou habilidade essencial para times orientados por dados. O Puppeteer te dá o poder de extrair informações até dos sites mais dinâmicos e cheios de JavaScript — mas exige conhecimento técnico e manutenção constante. Pra quem quer pular a parte do código e ir direto ao dado, o Thunderbit traz uma alternativa sem código, com IA, rápida, flexível e surpreendentemente robusta.
Minha dica:
- Se você é técnico e precisa de personalização profunda, comece pelo Puppeteer.
- Se busca agilidade, simplicidade e menos manutenção, experimente o (a é um ótimo começo).
- Para a maioria dos times, combinar as duas ferramentas resolve 99% das necessidades de dados web.
Quer ver mais guias como esse? Dá uma olhada no para tutoriais, comparativos e novidades sobre raspagem web com IA.
Perguntas Frequentes
1. O que é o Puppeteer scraper e por que ele é usado para raspagem web?
Puppeteer é uma biblioteca Node.js que permite controlar o Chrome em modo headless via JavaScript. Ele é usado para raspagem web porque consegue carregar conteúdo dinâmico, simular ações do usuário e extrair dados de sites que raspadores tradicionais não conseguem acessar.
2. Como o Puppeteer se compara ao Selenium e ao Thunderbit?
O Selenium funciona com vários navegadores e linguagens, mas é mais pesado. O Puppeteer é otimizado para Chrome/Node.js e costuma ser mais rápido em muitas tarefas de raspagem. Já o Thunderbit é uma solução sem código, movida por IA, que permite a qualquer pessoa raspar dados com poucos cliques.
3. Quais os principais benefícios do Puppeteer para negócios?
Automatizar a coleta de dados economiza tempo, reduz erros e permite insights em tempo real para vendas, marketing, operações e mais. Os usos vão de geração de leads a monitoramento de preços e pesquisa de mercado.
4. Quais os maiores desafios ao raspar com Puppeteer?
Os principais desafios são lidar com conteúdo dinâmico, evitar bloqueios anti-bot e manter os scripts quando os sites mudam. É preciso programar para gerenciar esperas, simular interações e tratar erros.
5. Quando devo usar Thunderbit em vez de Puppeteer?
Use o Thunderbit se quiser evitar programação, precisa de resultados rápidos ou quer empoderar colegas não técnicos. É ideal para tarefas padrão de raspagem, projetos rápidos ou quando você só quer exportar dados para Excel ou Google Sheets sem complicação.
Quer experimentar uma forma mais inteligente de raspar dados? ou confira mais guias no . Boas raspagens!
Saiba Mais