A internet está cheia de informações — tanto que o mercado global de softwares de raspagem de dados deve chegar a . Seja você um analista de negócios, alguém do marketing ou só um curioso, saber como extrair dados de um site já virou uma habilidade indispensável. E, se você é como eu, provavelmente quer fugir do famoso copiar e colar e ir direto ao ponto: insights práticos, planilhas organizadas e, quem sabe, um pouco de automação.
É aí que o Python entra em cena. Ele é tipo o canivete suíço para quem mexe com dados — fácil para quem está começando, mas robusto o suficiente para lidar desde uma página simples até milhares delas. Neste tutorial, vou te mostrar o básico do raspador web com Python, como lidar com sites dinâmicos e ainda apresentar o , nosso Raspador Web IA sem código, que deixa a extração de dados tão fácil quanto pedir delivery. Seja para aprender a programar ou para encontrar um atalho, você está no lugar certo.
O que é Web Scraping e Por que Usar Python para Extrair Dados de um Site?
Web scraping é o processo automatizado de coletar informações de sites e transformar tudo em um formato organizado — tipo planilhas, arquivos CSV ou bancos de dados — para análise ou uso nos negócios (). Em vez de copiar e colar manualmente, um raspador simula o que um humano faria, só que muito mais rápido e em grande escala.
Por que isso é tão valioso? Porque hoje, decisões baseadas em dados são o que movem as empresas. usam dados (muitos deles extraídos via scraping) para definir preços, fazer pesquisas de mercado e gerar leads. Imagina monitorar preços de concorrentes todo dia, juntar anúncios de imóveis ou montar uma lista personalizada de contatos — tudo sem esforço manual.
E por que Python? Olha só por que ele é o queridinho para web scraping:
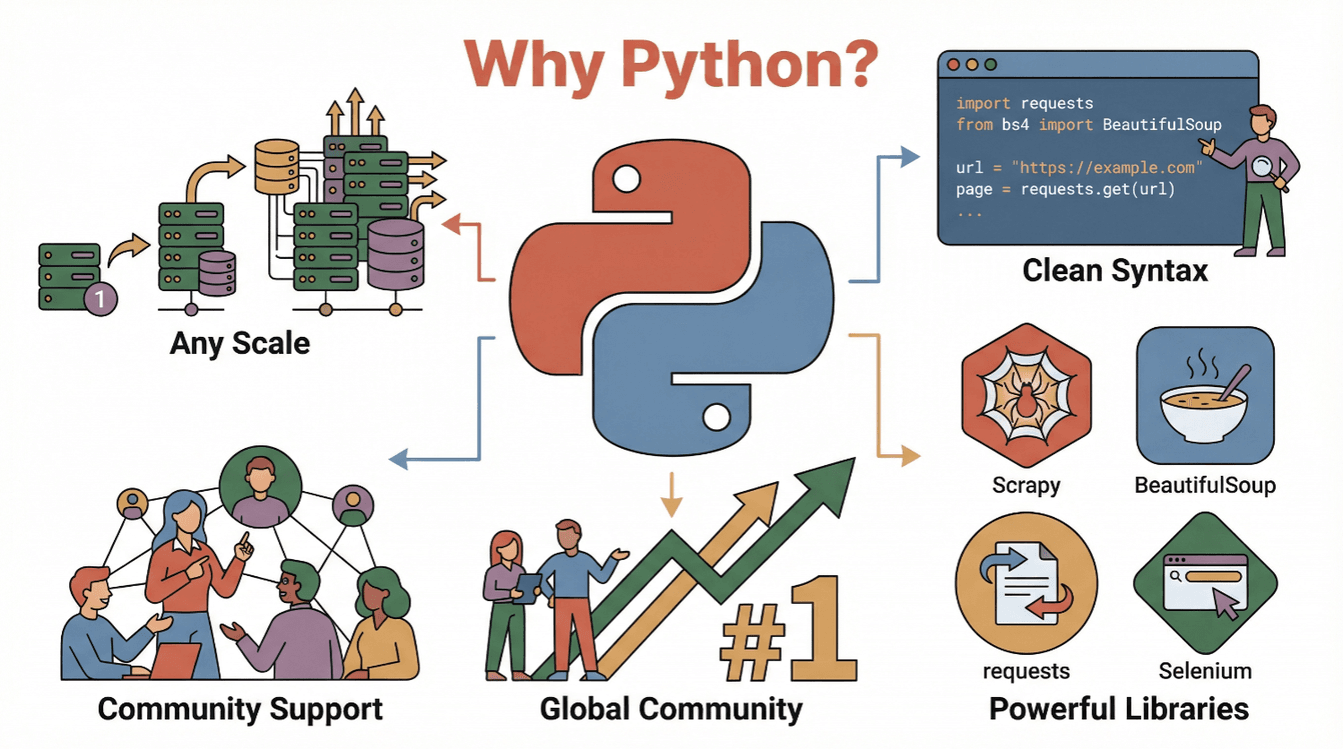
- Leitura fácil e simplicidade: A sintaxe do Python é clara e direta, o que facilita muito na hora de escrever e entender scripts de scraping ().
- Ecossistema completo: Bibliotecas como
requests,BeautifulSoup,ScrapyeSeleniumdeixam a extração, o parsing e a automação de ações no navegador muito mais simples. - Comunidade ativa: Python é , então não faltam tutoriais, fóruns e exemplos de código para te ajudar.
- Escalabilidade: Python vai bem desde scripts simples até raspadores robustos para grandes volumes de dados.
Resumindo: Python é seu passaporte para o universo dos dados online, seja você iniciante ou já um analista experiente.
Primeiros Passos: O Básico do Tutorial de Web Scraping com Python
Antes de colocar a mão no código, bora entender o passo a passo para extrair dados de um site usando Python:
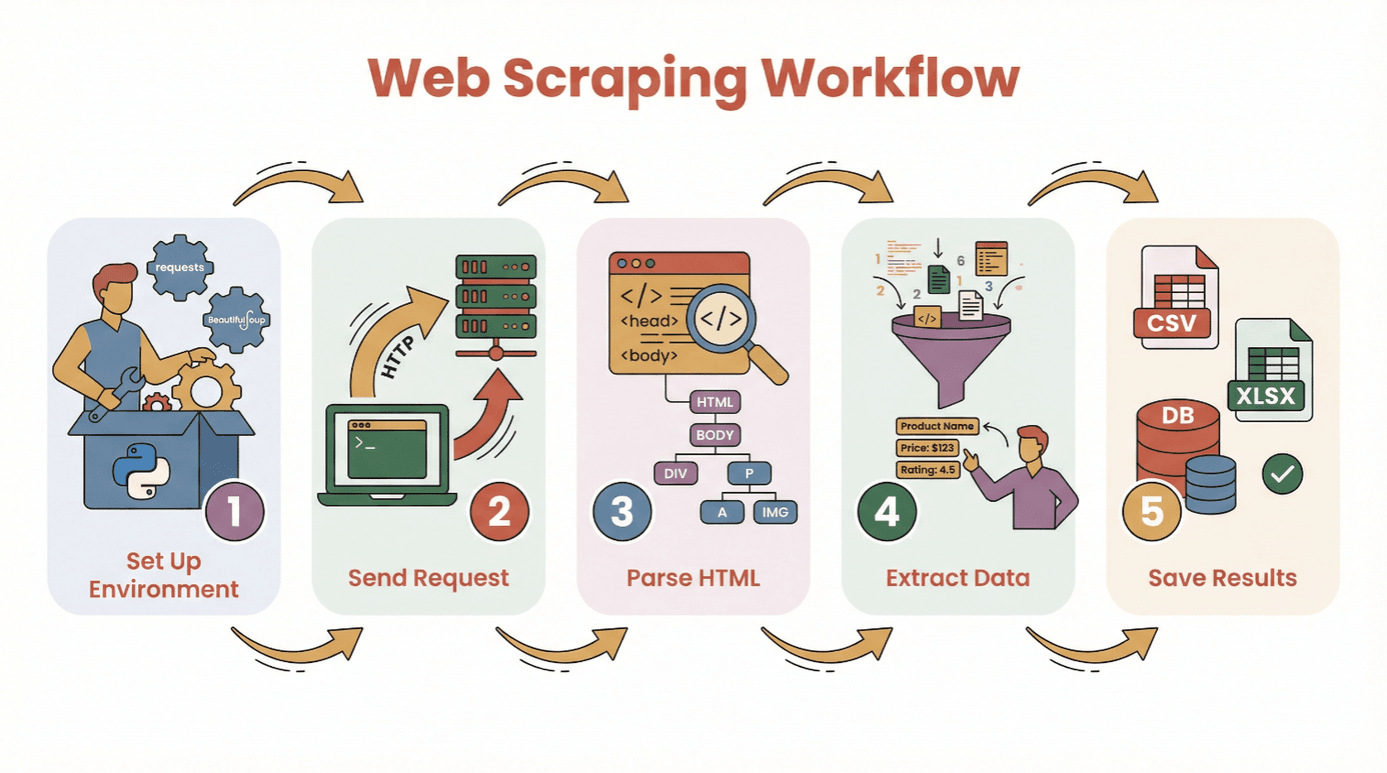
- Prepare seu ambiente: Instale o Python e as bibliotecas necessárias (
requests,BeautifulSoup, etc.). - Faça uma requisição: Use Python para buscar o conteúdo HTML da página desejada.
- Faça o parsing do HTML: Utilize um parser para navegar pela estrutura da página.
- Extraia os dados: Encontre e colete as informações que você precisa.
- Salve os resultados: Armazene os dados em CSV, Excel ou banco de dados para análise.
Você não precisa ser um expert em programação para começar. Se já sabe instalar o Python e rodar um script, está no caminho certo. Para quem está começando do zero, recomendo usar um ou um Jupyter notebook, mas até um editor de texto simples resolve.
Principais bibliotecas:
requests— para buscar páginas webBeautifulSoup— para analisar o HTMLpandas— para salvar e limpar dados (opcional, mas muito útil)
Qual Biblioteca Python Usar? BeautifulSoup, Scrapy ou Selenium?
Nem toda ferramenta de scraping em Python é igual. Dá uma olhada nesse resumo das três mais populares:
| Ferramenta | Melhor Para | Pontos Fortes | Limitações |
|---|---|---|---|
| BeautifulSoup | Páginas simples e estáticas; iniciantes | Fácil de usar, configuração mínima, ótima documentação | Não indicada para grandes volumes ou conteúdo dinâmico |
| Scrapy | Crawling em larga escala, múltiplas páginas | Rápida, assíncrona, pipelines integrados, gerencia crawling e armazenamento | Curva de aprendizado maior, exagero para tarefas pequenas, não executa JS |
| Selenium | Sites dinâmicos/JavaScript, automação | Executa JS, simula ações do usuário, suporta login e cliques | Mais lenta, consome mais recursos, configuração mais complexa |
BeautifulSoup: O Básico para Análise de HTML
BeautifulSoup é perfeito para quem está começando ou para projetos pequenos. Permite analisar HTML e extrair elementos com poucas linhas de código. Se o site é estático (sem carregamento via JavaScript), BeautifulSoup + requests já resolvem.
Exemplo:
1import requests
2from bs4 import BeautifulSoup
3url = "https://example.com"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
7print(titles)Quando usar: Scraping pontual, blogs simples, páginas de produtos ou diretórios.
Scrapy: Para Crawling em Larga Escala
Scrapy é um framework completo para navegar por sites inteiros ou lidar com milhares de páginas. É assíncrono (ou seja, rápido), tem pipelines para limpeza/armazenamento de dados e segue links automaticamente.
Exemplo:
1import scrapy
2class ProductSpider(scrapy.Spider):
3 name = "products"
4 start_urls = ["https://example.com/products"]
5 def parse(self, response):
6 for item in response.css('div.product'):
7 yield {
8 'name': item.css('h2::text').get(),
9 'price': item.css('span.price::text').get()
10 }Quando usar: Projetos grandes, crawlers agendados ou quando precisa de velocidade e estrutura.
Selenium: Para Sites Dinâmicos e com JavaScript
Selenium controla um navegador real (tipo Chrome ou Firefox), então consegue lidar com sites que carregam dados via JavaScript, exigem login ou interações como cliques.
Exemplo:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3driver = webdriver.Chrome()
4driver.get("https://example.com/login")
5driver.find_element(By.NAME, "username").send_keys("myuser")
6driver.find_element(By.NAME, "password").send_keys("mypassword")
7driver.find_element(By.XPATH, "//button[@type='submit']").click()
8dashboard = driver.find_element(By.ID, "dashboard").text
9print(dashboard)
10driver.quit()Quando usar: Redes sociais, sites de ações, páginas com scroll infinito ou que parecem vazias ao ver o código-fonte.
Passo a Passo: Como Extrair Dados de um Site Usando Python (Tutorial para Iniciantes)
Vamos ver um exemplo prático usando requests e BeautifulSoup. Vamos raspar um site de livros para pegar títulos, autores e preços.
Passo 1: Preparando o Ambiente Python
Primeiro, instale as bibliotecas necessárias:
1pip install requests beautifulsoup4 pandasDepois, importe no seu script:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pdPasso 2: Fazendo a Requisição ao Site
Busque o conteúdo HTML:
1url = "http://books.toscrape.com/catalogue/page-1.html"
2response = requests.get(url)
3if response.status_code == 200:
4 html = response.text
5else:
6 print(f"Falha ao acessar a página: \{response.status_code\}")Passo 3: Analisando o HTML
Crie o objeto BeautifulSoup:
1soup = BeautifulSoup(html, 'html.parser')Encontre todos os livros:
1books = soup.find_all('article', class_='product_pod')
2print(f"Encontrados {len(books)} livros nesta página.")Passo 4: Extraindo os Dados
Percorra cada livro e colete as informações:
1data = []
2for book in books:
3 title = book.h3.a['title']
4 price = book.find('p', class_='price_color').text
5 data.append({"Título": title, "Preço": price})Passo 5: Salvando os Dados para Análise
Converta para DataFrame e salve:
1df = pd.DataFrame(data)
2df.to_csv('books.csv', index=False)Agora você tem um arquivo CSV pronto para análise!
Dicas para Resolver Problemas:
- Se os resultados vierem vazios, confira se os dados são carregados via JavaScript (veja a próxima seção).
- Sempre inspecione a estrutura do HTML com as ferramentas do navegador.
- Trate dados ausentes com
get_text(strip=True)e verificações condicionais.
Lidando com Conteúdo Dinâmico: Extraindo Dados de Sites com JavaScript
Muitos sites modernos usam JavaScript para carregar dados. Às vezes, o que você vê no navegador não está no HTML inicial. Se seu raspador não encontra nada, pode ser esse o caso.
Como resolver:
- Selenium: Simula um navegador real, espera o conteúdo carregar e pode clicar ou rolar a página.
- Playwright/Puppeteer: Alternativas mais avançadas, mas com a mesma ideia (navegadores headless).
Mini Guia Selenium:
- Instale o Selenium e o driver do navegador (ex: ChromeDriver).
- Use "waits" explícitos para aguardar o carregamento.
- Extraia o HTML renderizado e analise com BeautifulSoup, se necessário.
Exemplo:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.support.ui import WebDriverWait
4from selenium.webdriver.support import expected_conditions as EC
5driver = webdriver.Chrome()
6driver.get("https://example.com/dynamic")
7WebDriverWait(driver, 10).until(
8 EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
9)
10html = driver.page_source
11soup = BeautifulSoup(html, 'html.parser')
12# Extraia os dados normalmente
13driver.quit()Quando usar Selenium?
- Se
requests.get()retorna HTML sem dados, mas você vê os dados no navegador. - Se o site tem scroll infinito, pop-ups ou exige login.
Facilitando o Web Scraping com IA: Usando Thunderbit para Extrair Dados de um Site
Vamos ser sinceros — às vezes você só quer os dados, sem se preocupar com código. É aí que o faz a diferença. O Thunderbit é uma extensão do Chrome com IA que permite extrair dados de qualquer site em poucos cliques — sem precisar programar.
Como funciona o Thunderbit:
- Instale a .
- Abra o site desejado.
- Clique no ícone do Thunderbit e selecione “IA Sugerir Campos.” A IA analisa a página e sugere quais dados extrair (ex: nomes de produtos, preços, e-mails).
- Ajuste os campos se necessário e clique em “Raspar.”
- Exporte os dados direto para Excel, Google Sheets, Notion ou Airtable.
Por que o Thunderbit é incrível:
- Não exige programação. Qualquer pessoa pode usar (até minha mãe, que ainda me liga para pedir ajuda com o Wi-Fi).
- Lida com subpáginas e paginação. Precisa extrair detalhes de vários produtos em diferentes páginas? O Thunderbit navega e junta tudo para você.
- Instruções em linguagem natural. Basta dizer o que quer (“extrair todos os títulos e preços”) e a IA faz o resto.
- Modelos prontos para sites populares. Amazon, Zillow, LinkedIn e outros — um clique e pronto.
- Exportação gratuita de dados. Baixe como CSV, Excel ou envie direto para suas ferramentas favoritas.
O Thunderbit já é usado por mais de , e o plano gratuito permite raspar até 6 páginas (ou 10 com bônus de teste). Para empresas, é um baita ganho de tempo — e para quem é técnico, é ótimo para prototipar antes de criar um raspador Python personalizado.
Depois do Scraping: Limpando e Analisando Dados com Pandas e NumPy
Extrair dados é só o começo. Dados brutos da web costumam vir bagunçados — duplicados, valores ausentes, formatos estranhos. É aí que as bibliotecas pandas e NumPy do Python brilham.
Tarefas comuns de limpeza:
- Remover duplicados:
df.drop_duplicates(inplace=True) - Tratar valores ausentes:
df.fillna('Desconhecido')oudf.dropna() - Converter tipos de dados:
df['Preço'] = df['Preço'].str.replace('R$','').astype(float) - Analisar datas:
df['Data'] = pd.to_datetime(df['Data']) - Filtrar outliers:
df = df[df['Preço'] > 0]
Análises básicas:
- Estatísticas resumidas:
df.describe() - Agrupar por categoria:
df.groupby('Categoria')['Preço'].mean() - Gráficos rápidos:
df['Preço'].hist()oudf.groupby('Categoria')['Preço'].mean().plot(kind='bar')
Para operações matemáticas avançadas ou manipulação rápida de arrays, use o NumPy. Mas para a maioria dos casos de negócios, o pandas já resolve quase tudo.
Dica: Se está começando com pandas, confira o guia .
Boas Práticas e Dicas para Web Scraping com Python
Web scraping é poderoso, mas exige responsabilidade. Olha meu checklist para raspar dados de forma ética e eficiente:
- Respeite o robots.txt e os Termos de Uso. Sempre confira se o site permite scraping ().
- Não sobrecarregue os servidores. Adicione intervalos entre as requisições (
time.sleep(2)) e simule o comportamento humano. - Use headers realistas. Defina um User-Agent para parecer um navegador comum.
- Trate erros com cuidado. Use try/except e tente novamente em caso de falha.
- Alterne proxies se necessário. Para scraping em larga escala, use pools de proxies para evitar bloqueios de IP.
- Seja ético e siga a lei. Não raspe dados pessoais ou conteúdos protegidos sem permissão.
- Documente seu processo. Anote o que foi raspado, de onde e quando.
- Prefira APIs oficiais quando disponíveis. Às vezes, é melhor do que raspar HTML.
Para mais dicas, confira o .
Conclusão & Principais Aprendizados
Fazer web scraping com Python é uma baita ferramenta para transformar o caos da internet em dados organizados e úteis. Seja usando código (requests, BeautifulSoup, Scrapy ou Selenium) ou uma solução sem código como o , você pode extrair dados de sites e descobrir novos insights.
Lembre-se:
- Comece simples — raspe uma página antes de partir para projetos grandes.
- Escolha a ferramenta certa para sua necessidade (BeautifulSoup para o básico, Scrapy para escala, Selenium para sites dinâmicos, Thunderbit para quem não quer programar).
- Limpe e analise seus dados com pandas e NumPy.
- Sempre raspe de forma ética e responsável.
Pronto para começar? Escolha um projeto pequeno — como raspar manchetes do dia ou uma lista de produtos — e veja como é rápido transformar uma página web em uma planilha organizada. E se quiser pular o código, e deixe a IA fazer o trabalho pesado.
Para mais tutoriais, dicas e novidades sobre web scraping, acesse o .
Perguntas Frequentes
1. O que é web scraping e por que Python é tão usado para isso?
Web scraping é a extração automatizada de dados de sites. Python é popular nessa área por sua sintaxe simples, bibliotecas poderosas (como BeautifulSoup, Scrapy e Selenium) e uma comunidade ativa ().
2. Qual biblioteca Python devo usar para web scraping?
Use BeautifulSoup para páginas simples e estáticas; Scrapy para crawling em larga escala ou múltiplas páginas; e Selenium para sites dinâmicos ou com muito JavaScript. Cada uma tem vantagens dependendo do seu objetivo ().
3. Como lidar com sites que carregam dados via JavaScript?
Para conteúdo gerado por JavaScript, use Selenium (ou Playwright) para simular um navegador e aguardar o carregamento antes de extrair os dados. Às vezes, é possível encontrar um endpoint de API analisando o tráfego de rede.
4. O que é Thunderbit e como ele facilita o web scraping?
é uma extensão do Chrome com IA que permite extrair dados de qualquer site sem programar. Ele sugere campos, lida com subpáginas e paginação, e exporta os dados direto para Excel, Google Sheets, Notion ou Airtable.
5. Como limpar e analisar dados extraídos no Python?
Use pandas para remover duplicados, tratar valores ausentes, converter tipos de dados e fazer análises. NumPy é ótimo para operações numéricas. Para visualização, pandas integra com Matplotlib para gráficos rápidos ().
Boas raspagens — e que seus dados estejam sempre limpos, organizados e prontos para uso.
Saiba Mais