Se você está avaliando ferramentas de web scraping em 2026, provavelmente não quer uma aula de filosofia. Você quer uma lista curta em que possa confiar, uma forma rápida de separar ferramentas para usuários de negócios de stacks pesadas para engenharia e evidências reais suficientes para evitar comprar a opção errada. É isso que esta página entrega.
A resposta rápida
Se você só precisa da lógica de decisão, use isto:
- Escolha um Raspador Web IA se quiser o caminho mais rápido de um site para uma planilha, com configuração mínima.
- Escolha um scraper sem código se precisar de mais controle de tarefas, agendamento ou execuções em nuvem sem programar.
- Escolha uma plataforma de API se sua equipe precisar de renderização, rotação de proxy, tratamento anti-bot ou integração em um produto interno.
- Escolha uma biblioteca open source se quiser controle total e puder assumir manutenção, seletores, infraestrutura e falhas.
Este artigo mantém todas as 20 ferramentas, mas a lógica de recomendação é propositalmente simples: comece com a ferramenta mais leve que consiga dar conta do seu fluxo de trabalho de forma confiável e só avance na stack quando manutenção, bloqueios ou escala realmente obrigarem.
Tabela comparativa rápida: as melhores ferramentas de web scraping em 2026
Os preços e modelos de plano abaixo foram conferidos nas páginas oficiais de produto ou de preços em 8 de maio de 2026. Quando os fornecedores usam cobrança por uso ou orçamento personalizado para empresas, descrevo o modelo de preços em vez de fingir que existe um preço de tabela universalmente confiável.
| Ferramenta | Tipo | Melhor para | Por que entrou na lista de 2026 | Modelo de preços (verificado em maio de 2026) |
|---|---|---|---|---|
| Thunderbit | Raspador Web IA | Vendas, operações, ecommerce, imóveis | O caminho mais rápido para quem não programa; sugestão de campos por IA, subpáginas, exportação, fluxo no navegador + na nuvem | Plano gratuito, planos pagos, preços personalizados para empresas |
| Browse AI | Raspador Web IA | Usuários de negócios monitorando sites | Robôs sem código fortes, monitoramento e saídas no estilo planilha/API | Plano gratuito, planos pagos, nível premium gerenciado |
| Bardeen | Automação com IA + scraping | Operações de receita e fluxos no navegador | Melhor quando o scraping é só uma etapa dentro de uma automação mais ampla | Plano gratuito e planos pagos |
| Diffbot | Plataforma de extração com IA | Empresas e equipes de dados | Melhor opção quando você quer extração por IA e fluxos de dados estruturados em grande escala | Preços no estilo enterprise |
| Instant Data Scraper | Scraper leve de navegador | Usuários ocasionais e capturas rápidas de tabelas | Ainda é uma das formas mais simples de levar uma lista ou tabela visível para CSV rapidamente | Gratuito |
| Octoparse | Scraper sem código | Analistas e equipes de operações com tarefas recorrentes maiores | Construtor visual maduro com extração em nuvem, anti-bloqueio e modelos | Plano gratuito, pago a partir de US$ 69/mês, enterprise personalizado |
| ParseHub | Scraper low-code | Analistas que precisam de lógica e controle no desktop | Lógica de projeto flexível e navegação aninhada, com curva de aprendizado mais íngreme do que a de ferramentas mais novas com IA primeiro | Plano gratuito e planos pagos |
| Web Scraper | Scraper sem código | Iniciantes e trabalhos leves na nuvem | Bom ponto de entrada se você gosta de scraping baseado em sitemap e configuração centrada no navegador | Extensão gratuita, planos pagos na nuvem |
| Data Miner | Scraper de navegador | Pesquisadores e operadores de crescimento | Ainda é útil para extração rápida baseada em receitas dentro do navegador | Plano gratuito e planos pagos |
| Apify | Plataforma de API + Actors | Equipes técnicas e operadores híbridos | Ecossistema excelente de Actors com runtime personalizado quando você vai além das extensões de navegador | Plano gratuito, plano inicial a partir de US$ 29/mês mais uso, níveis pagos maiores |
| ScrapingBee | API de scraping | Desenvolvedores raspando sites pesados em JavaScript | Boa escolha quando você quer renderização e tratamento de proxy sem montar você mesmo a camada de navegador | Teste gratuito e planos pagos |
| ScraperAPI | API de scraping | Desenvolvedores escalando requisições rapidamente | API direta, créditos de teste, produtos estruturados e offload de infraestrutura mais simples | Teste de 7 dias com 5.000 créditos, pago a partir de US$ 49/mês |
| Bright Data | API corporativa + plataforma de proxy | Programas de alto volume e alta exigência de compliance | Stack de coleta de dados mais ampla quando desbloqueio, proxy e aquisição gerenciada importam mais do que simplicidade | Preços por uso e por produto |
| Oxylabs | API corporativa + plataforma de proxy | Equipes comprando scraping como infraestrutura | Forte para coleta em grande escala, especialmente cargas de trabalho de preço, SEO e pesquisa de mercado | A API Web Scraper começa em US$ 49/mês; preços de proxy mais amplos variam |
| Zyte | API + stack anti-bot | Equipes de desenvolvimento e dados | Boa opção se você quer extração API-first com bons recursos de navegador, rotação e anti-detecção | Teste com US$ 5 de crédito grátis, compromissos baseados em uso |
| Selenium | Automação de navegador open source | Automação no estilo QA e fluxos de interação complexos | Ainda útil quando a fidelidade da interação do usuário importa mais que a vazão do scraper | Gratuito e open source |
| BeautifulSoup4 | Parser open source | Iniciantes e parsing leve | Melhor como parser em uma stack simples, não como plataforma completa de scraping | Gratuito e open source |
| Scrapy | Framework de crawling open source | Crawlers personalizados em produção | Melhor equilíbrio entre poder e maturidade se você quiser assumir o pipeline internamente | Gratuito e open source |
| Puppeteer | Automação de navegador open source | Scraping com Node e scripts de navegador | Excelente se sua equipe já está confortável no ecossistema Chrome/Node | Gratuito e open source |
| Playwright | Automação de navegador open source | Automação moderna multi-navegador | Muitas vezes a escolha mais limpa para automação moderna com boa experiência de desenvolvimento | Gratuito e open source |
Como eu avaliei estas ferramentas
Usei quatro filtros:
- Tempo até o primeiro scrape bem-sucedido
Se um operador sem perfil técnico não consegue obter dados úteis rapidamente, isso importa. - Carga de manutenção
Configuração rápida não vale nada se o fluxo quebra toda vez que um site muda. - Teto de escala
Algumas ferramentas são ideais para 50 páginas por semana e péssimas para 5 milhões de requisições por mês. - Aderência ao fluxo de trabalho
A melhor ferramenta para uma equipe de operações de receita raramente é a melhor ferramenta para uma equipe de plataforma de dados.
O resultado não é um ranking universal. É uma página de decisão para escolher primeiro a classe certa de ferramenta e, depois, o produto certo dentro dessa classe.
De que tipo de ferramenta de web scraping você realmente precisa?
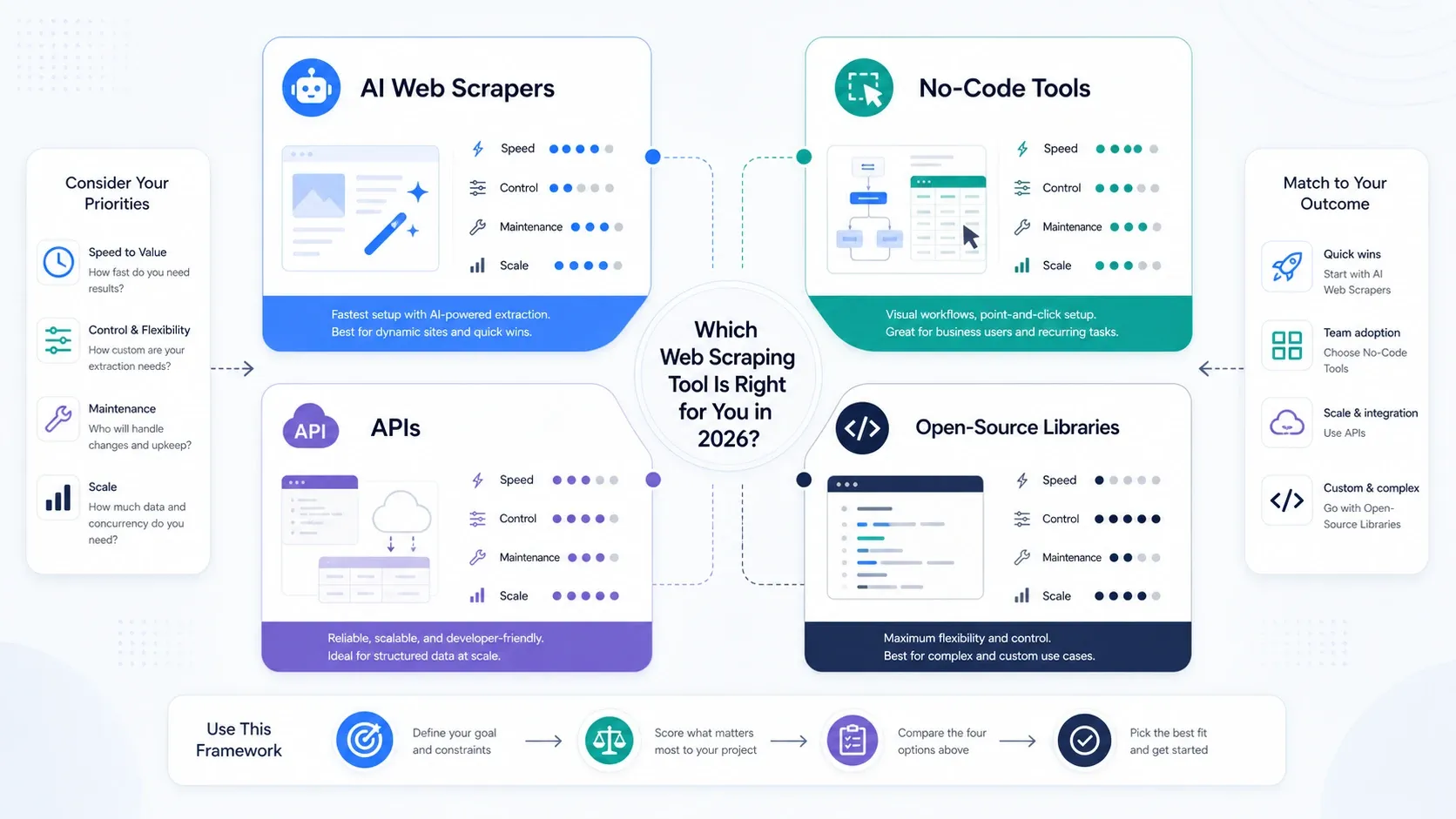
- Escolha Raspadores Web IA se seu objetivo principal for velocidade operacional.
- Escolha ferramentas sem código se você precisar de mais paginação, agendamento e controle de tarefas repetíveis.
- Escolha APIs e plataformas de scraping se renderização, rotação e capacidade de desbloqueio já forem o gargalo.
- Escolha bibliotecas open source se sua equipe valoriza mais controle do que conveniência e consegue dar suporte à stack internamente.
Se sua equipe ainda está decidindo se o scraping deve ficar com operações ou engenharia, comece primeiro com uma ferramenta de IA ou sem código. Você vai aprender o que realmente importa executando trabalhos reais, em vez de superprojetar a stack logo de início.
Melhores Raspadores Web IA para equipes de negócios
Estas são as ferramentas que eu olharia primeiro se o resultado desejado fosse dados prontos para planilha com o mínimo de configuração possível.
1. Thunderbit
O Thunderbit é a opção mais fácil aqui se sua equipe quer extrair dados estruturados sem aprender seletores, scripts de navegador ou infraestrutura de scraping. O fluxo de trabalho é baseado em sugestão de campos por IA, enriquecimento de subpáginas e exportação direta para as ferramentas que usuários de negócios já usam.
- Melhor para: vendas, operações, ecommerce, imóveis e outras equipes que trabalham muito no navegador.
- Por que se destaca: reduz o tempo de configuração melhor do que qualquer outra opção desta lista para quem não programa.
- Atenção: se você precisar de lógica profunda de crawler ou controle de engenharia altamente especializado, eventualmente vai avançar na stack.
- Modelo de preços: plano gratuito, planos pagos self-service e preços empresariais.
Se você quiser ver o fluxo real mais rápido antes de comparar mais ferramentas, este passo a passo é o melhor ponto de partida:
2. Browse AI
O Browse AI continua sendo uma ótima escolha para usuários de negócios que querem configuração com cliques e monitoramento recorrente. O modelo de robô é especialmente útil quando scraping e detecção de mudanças são igualmente importantes.
- Melhor para: monitorar páginas de preços, páginas de concorrentes e extração repetível de listas.
- Por que se destaca: onboarding refinado, robôs prontos e um caminho claro de site para planilha ou saída no estilo API.
- Atenção: tarefas complexas e de alto volume podem ficar caras ou operacionalmente inconvenientes mais rápido do que em stacks API-first.
- Modelo de preços: plano gratuito, planos pagos, nível premium/gerenciado.
3. Bardeen
O Bardeen é mais interessante quando o scraping é só uma ação dentro de um fluxo mais amplo de automação no navegador. Se você está levando dados para CRMs, planilhas ou fluxos de saída, o lado da automação pesa mais do que a profundidade bruta do scraping.
- Melhor para: operações de receita, fluxos de leads e automação de tarefas nativas do navegador.
- Por que se destaca: narrativa de automação de fluxo mais forte do que ferramentas de extração pura.
- Atenção: não é a melhor opção quando o próprio scraping é complexo e crítico para a operação.
- Modelo de preços: plano gratuito e planos pagos.
4. Diffbot
O Diffbot está aqui para equipes que precisam de extração com IA em escala empresarial, não para quem procura o caminho mais barato ou simples. Faz mais sentido quando qualidade de dados estruturados e ingestão em grande escala importam mais do que controle manual.
- Melhor para: equipes de dados corporativas, inteligência de conteúdo e programas de extração em larga escala.
- Por que se destaca: extração em estilo visão computacional e forte orientação para saídas estruturadas.
- Atenção: exagerado para equipes pequenas e pouco conveniente se o caso de uso for leve.
- Modelo de preços: planos no estilo enterprise e venda personalizada.
5. Instant Data Scraper
O Instant Data Scraper ainda merece espaço porque há muitas situações em que você só precisa da tabela, diretório ou lista visível, e precisa disso agora. Não é uma plataforma, mas muitas vezes é o suficiente.
- Melhor para: extração pontual, listas rápidas de leads, diretórios simples e tabelas visíveis.
- Por que se destaca: quase zero atrito nas páginas certas.
- Atenção: automação limitada, profundidade limitada e pouca aderência a fluxos avançados.
- Modelo de preços: gratuito.
Melhores ferramentas de web scraping sem código para tarefas repetíveis
Quando a tarefa deixa de ser um scrape ocasional, construtores visuais e execução em nuvem passam a importar.
6. Octoparse
O Octoparse continua sendo uma das plataformas sem código mais fortes se você precisa de execuções em nuvem, cobertura de modelos e um gerenciamento de tarefas mais sofisticado do que uma extensão de navegador consegue oferecer.
- Melhor para: analistas, equipes de preços e operadores executando tarefas recorrentes de coleta.
- Por que se destaca: construtor de tarefas maduro, extração em nuvem, recursos anti-bloqueio e um grande ecossistema de modelos.
- Atenção: é mais poderoso do que ferramentas de navegador com IA primeiro, mas isso também significa mais sobrecarga de configuração.
- Modelo de preços: plano gratuito, pago a partir de US$ 69/mês, enterprise personalizado.
7. ParseHub
O ParseHub ainda é relevante para usuários que querem mais controle do que um scraper de IA, mas não querem criar uma base de código. Ele recompensa paciência, não velocidade.
- Melhor para: analistas e operadores com curiosidade técnica que toleram uma curva de aprendizado mais íngreme.
- Por que se destaca: lógica de navegação flexível e mais controle do que ferramentas leves de navegador.
- Atenção: a experiência do produto parece mais pesada do que a de concorrentes mais novos, especialmente para equipes de negócios em ritmo acelerado.
- Modelo de preços: plano gratuito e planos pagos.
8. Web Scraper
O Web Scraper ainda é um ponto de entrada razoável se você gosta do modelo de sitemap e quer algo que comece no navegador e depois evolua para agendamento na nuvem.
- Melhor para: iniciantes, projetos por hobby e tarefas menores e repetíveis.
- Por que se destaca: fluxo de sitemap acessível e adoção fácil com foco no navegador.
- Atenção: ele começa a ficar limitante quando você precisa de uma lógica de extração mais adaptativa.
- Modelo de preços: extensão gratuita para navegador e planos pagos na nuvem.
9. Data Miner
O Data Miner é melhor entendido como um utilitário de extração rápida, e não como uma plataforma completa de scraping. Ainda assim, merece um lugar porque o trabalho baseado em receitas é útil para muitas tarefas de pesquisa e prospecção.
- Melhor para: pesquisadores, equipes de growth e exportações rápidas diretamente do navegador.
- Por que se destaca: modelo de receitas, baixo atrito e exportação fácil no navegador.
- Atenção: não é a ferramenta certa para scraping sério em escala de plataforma.
- Modelo de preços: plano gratuito e planos pagos.
Melhores plataformas de API quando escala e bloqueio viram o problema real
Esta é a camada em que as equipes de engenharia param de pensar “como faço para raspar esta página?” e começam a pensar “como faço para tornar isso confiável em grande volume?”
10. Apify
O Apify é a plataforma mais flexível deste grupo se você quiser tanto um marketplace de scrapers reutilizáveis quanto um lugar para rodar seu próprio código. Ele faz a ponte entre descoberta sem código e execução por desenvolvedores melhor do que a maioria dos concorrentes.
- Melhor para: equipes híbridas, scraping conduzido por desenvolvedores e fluxos de automação reutilizáveis.
- Por que se destaca: ecossistema de Actors + runtime personalizado dá um alcance incomum.
- Atenção: quando você parte para o customizado, volta ao território de engenharia e a vantagem de simplicidade diminui.
- Modelo de preços: plano gratuito, plano inicial a partir de US$ 29/mês mais uso, níveis de uso maiores e enterprise.
11. ScrapingBee
O ScrapingBee é uma boa escolha quando sua necessidade real é “me entregue a página renderizada e assuma a infraestrutura complicada para mim”. Ele funciona bem para alvos pesados em JavaScript.
- Melhor para: desenvolvedores raspando sites dinâmicos com pouca disposição para lidar com infraestrutura.
- Por que se destaca: API simples para renderização, proxies e automação de navegador.
- Atenção: é um serviço de infraestrutura, então você ainda precisa cuidar de parsing, lógica de retry e qualidade a jusante.
- Modelo de preços: teste e planos pagos.
12. ScraperAPI
O ScraperAPI continua sendo uma das maneiras mais fáceis de terceirizar a gestão de proxy e a taxa de sucesso das requisições quando você quer escalar rápido.
- Melhor para: desenvolvedores que precisam sair de protótipo para volume rapidamente.
- Por que se destaca: API direta, créditos de teste, produtos estruturados e níveis de escala.
- Atenção: como todo produto API-first, ele não elimina a necessidade de julgamento de engenharia em torno de parsing e validação de dados.
- Modelo de preços: teste de 7 dias com 5.000 créditos, pago a partir de US$ 49/mês.
13. Bright Data
A Bright Data é a opção mais robusta quando capacidade de desbloqueio, inventário de proxies e aquisição gerenciada importam mais do que a simplicidade da ferramenta.
- Melhor para: programas corporativos, coleta em larga escala com foco em compliance e aquisição de dados gerenciada.
- Por que se destaca: amplitude de produtos de proxy, scraper, navegador e datasets.
- Atenção: cara e fácil de comprar além da necessidade se seu fluxo principal ainda for relativamente simples.
- Modelo de preços: preços por uso e por produto em APIs, proxies e serviços gerenciados.
14. Oxylabs
A Oxylabs continua sendo uma opção forte para equipes que compram scraping como infraestrutura, e não como ferramenta de navegador. Ela é especialmente relevante quando confiabilidade e maturidade de compra importam.
- Melhor para: coleta corporativa, monitoramento de preços, monitoramento de SEO e pesquisa de mercado.
- Por que se destaca: narrativa de infraestrutura robusta, profundidade de proxies e uma jornada de compra mais clara para empresas.
- Atenção: não é ideal se sua equipe quer um fluxo casual self-service.
- Modelo de preços: a API Web Scraper começa em US$ 49/mês; outros produtos variam por unidade e uso.
15. Zyte
A Zyte ainda merece consideração séria de equipes de desenvolvimento e dados que querem anti-detecção, ações de navegador, renderização de JavaScript e IPs rotativos por trás de uma única proposta API-first.
- Melhor para: equipes técnicas construindo sistemas de extração repetíveis.
- Por que se destaca: ações de navegador, renderização de JavaScript, rotação de IPs e postura anti-bot em uma única stack.
- Atenção: melhor para equipes com responsabilidade de engenharia do que para operadores sem perfil técnico.
- Modelo de preços: teste com US$ 5 de crédito grátis e compromissos mensais baseados em uso.
Melhores bibliotecas open source para desenvolvedores que querem controle total
Se você quer assumir a stack de scraping do início ao fim, estes são os blocos de construção mais úteis em 2026.
16. Selenium
O Selenium ainda é útil quando você precisa de fidelidade de interação no estilo QA, fluxos de automação legados em navegador ou controle muito explícito do fluxo do usuário.
- Melhor para: automações com muita interação, sobreposição com QA e sites em que o comportamento do navegador importa mais do que a taxa de crawl.
- Por que se destaca: ecossistema maduro e amplo suporte a navegadores.
- Atenção: mais pesado e mais lento do que ferramentas de navegador mais novas para muitas cargas de trabalho de scraping.
- Modelo de preços: gratuito e open source.
17. BeautifulSoup4

O BeautifulSoup não é uma plataforma completa de scraping, mas continua sendo uma das formas mais fáceis de fazer parsing de HTML bagunçado em fluxos leves.
- Melhor para: iniciantes, scripts rápidos e tarefas centradas em parser.
- Por que se destaca: API simples e baixa carga mental.
- Atenção: combine com ferramentas de requests, navegador ou crawler; sozinho, ele é apenas um parser.
- Modelo de preços: gratuito e open source.
18. Scrapy
O Scrapy ainda é a melhor resposta quando você precisa de um verdadeiro framework de crawler em vez de um punhado de scripts.
- Melhor para: crawlers personalizados em produção e pipelines de dados sob responsabilidade interna.
- Por que se destaca: alta performance, pipelines, middleware e extensibilidade de longo prazo.
- Atenção: há custo real de engenharia, e alvos pesados em JavaScript muitas vezes exigem ferramentas complementares.
- Modelo de preços: gratuito e open source.
19. Puppeteer
O Puppeteer continua sendo uma boa opção para equipes focadas em Node que querem controle direto sobre Chromium e scripts de navegador.
- Melhor para: scraping em Node, capturas de tela e tarefas de automação de navegador.
- Por que se destaca: controle direto e poderoso do comportamento do Chromium.
- Atenção: cobertura de navegadores mais limitada que a do Playwright e ainda consome muitos recursos em escala.
- Modelo de preços: gratuito e open source.
20. Playwright
O Playwright é minha recomendação padrão para automação moderna de navegador se sua equipe escreve código e quer uma abstração mais nova que o Selenium.
- Melhor para: automação moderna de navegador, sites pesados em JavaScript e equipes que se importam com boa ergonomia para desenvolvedores.
- Por que se destaca: modelo forte multi-navegador, comportamento confiável de espera e APIs limpas.
- Atenção: você ainda assume infraestrutura de navegador, concorrência, mudanças de seletores e validação de dados.
- Modelo de preços: gratuito e open source.
Minha lista curta por tipo de equipe
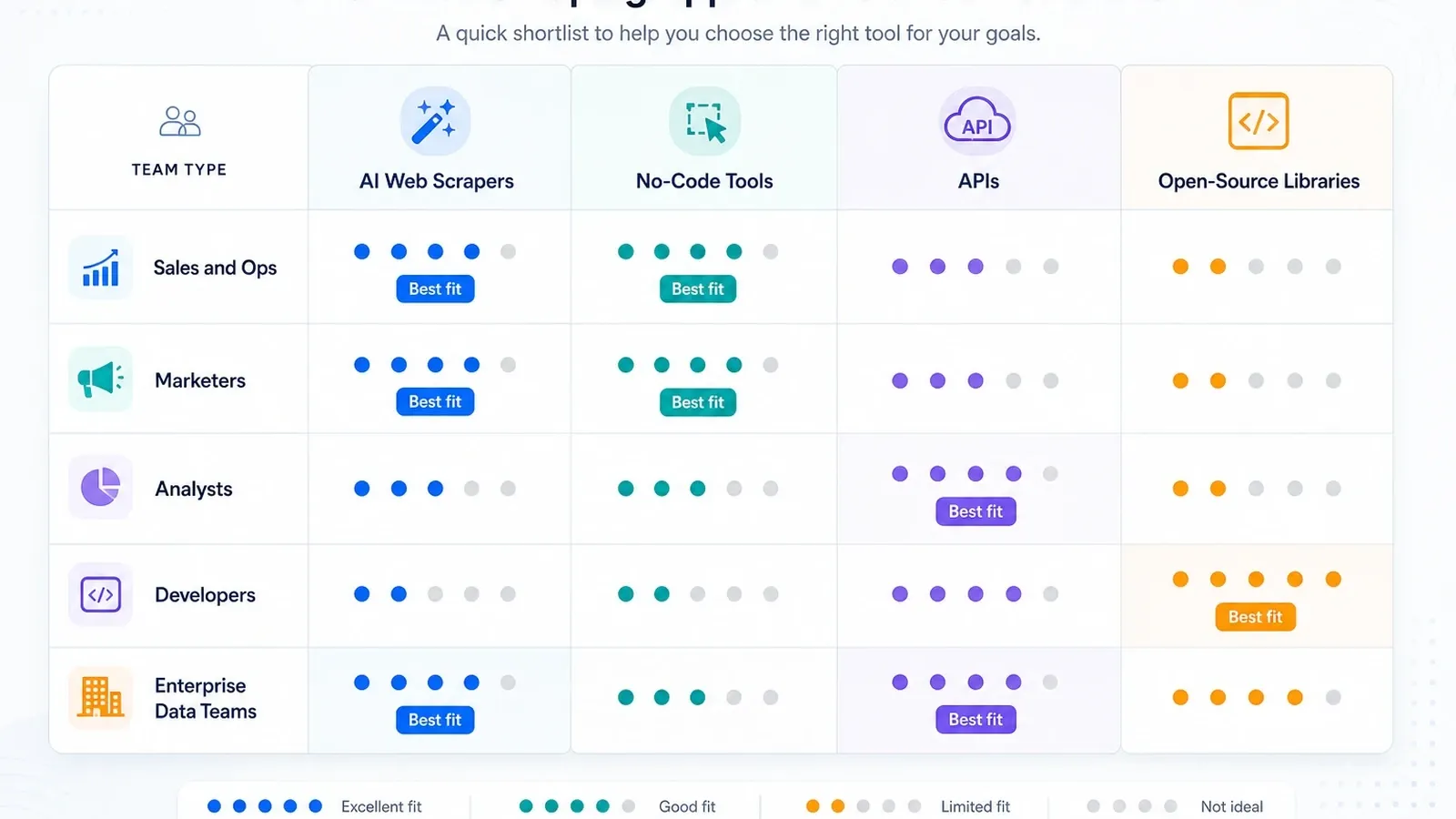
- Equipes de vendas e operações: comece com o Thunderbit e, depois, veja o Browse AI se monitoramento importar mais do que enriquecimento de subpáginas.
- Analistas e equipes de pesquisa: Octoparse primeiro, se as tarefas recorrentes forem maiores do que ferramentas de extensão de navegador conseguem lidar confortavelmente.
- Equipes de GTM com muita automação: Bardeen, se o scraping for só uma etapa em um fluxo mais amplo.
- Equipes de desenvolvimento criando ferramentas internas: Apify, Zyte, ScraperAPI ou Playwright, dependendo de quanto controle de stack você quer.
- Programas de dados enterprise: Bright Data, Oxylabs, Diffbot e Zyte são as conversas sérias sobre infraestrutura.
Quando avançar na stack
Use esta regra:
- Fique com ferramentas de IA até esbarrar em limites de repetibilidade ou casos extremos.
- Avance para ferramentas sem código quando agendamento, paginação, anti-bloqueio ou execuções em nuvem importarem mais do que a simplicidade de um clique.
- Avance para APIs quando taxa de desbloqueio, renderização de JavaScript e concorrência virarem os verdadeiros gargalos.
- Avance para bibliotecas open source quando o custo da abstração do fornecedor ficar maior que o custo de assumir toda a stack.
A maioria das equipes avança na stack cedo demais. Esse é um dos erros mais comuns que vejo.
Conclusão
Para a maioria das equipes sem perfil técnico, a resposta certa em 2026 não é “o scraper mais poderoso”. É a ferramenta que leva dados precisos para o próximo fluxo de trabalho com a menor manutenção possível. É por isso que ferramentas AI-first continuam vencendo para operadores, enquanto APIs e stacks open source seguem sendo a melhor opção para equipes técnicas com requisitos claros de escala.
Se você quer o caminho mais curto de uma página para uma saída estruturada, comece com o Thunderbit. Se você já sabe que sua tarefa exige infraestrutura pesada, vá direto para as camadas de API e desenvolvedor. Só não confunda complexidade com sofisticação.
FAQs
1. Qual é a melhor ferramenta de web scraping para usuários sem perfil técnico em 2026?
Para a maioria dos usuários sem perfil técnico, ferramentas AI-first como Thunderbit e Browse AI oferecem o caminho mais rápido para dados úteis porque reduzem o trabalho com seletores, o atrito de configuração e a sobrecarga de manutenção.
2. O que devo escolher se meus sites usam muito JavaScript ou bloqueiam requisições de forma agressiva?
Avance para ScrapingBee, ScraperAPI, Zyte, Bright Data, Oxylabs, Playwright ou Selenium, dependendo de você querer um serviço gerenciado ou controle direto de engenharia.
3. Ferramentas sem código ainda são relevantes agora que os Raspadores Web IA estão melhores?
Sim. Ferramentas sem código como Octoparse e ParseHub ainda importam quando você precisa de controle mais explícito sobre lógica de tarefas, execução em nuvem e gerenciamento de trabalhos repetíveis.
4. Quais ferramentas fazem mais sentido para equipes de engenharia?
Apify, Zyte, ScraperAPI, Scrapy, Playwright, Puppeteer e Selenium são as escolhas mais naturais quando os desenvolvedores são donos do fluxo de trabalho.
5. Como devo fazer uma lista curta rapidamente sem pesquisar demais?
Primeiro escolha o tipo de ferramenta, não o fornecedor. Decida se você precisa de simplicidade com IA, controle sem código, infraestrutura por API ou responsabilidade open source. Depois compare os produtos dentro dessa camada.
Leitura relacionada