
“Você pode ter dados sem informação, mas não pode ter informação sem dados.” —
Estimativas recentes apontam que já existem mais de de sites na internet, com algo em torno de 2 milhões de novos posts saindo do forno todos os dias. Esse marzão de dados esconde insights valiosos para guiar decisões — mas tem um porém: cerca de disso é conteúdo não estruturado, ou seja, precisa de um “trato” extra para virar algo realmente útil. É aí que entram as ferramentas de web scraping, que viraram item obrigatório para quem quer aproveitar dados online.
Se você está começando agora, termos como e podem dar aquela travada no começo. Só que, na era da IA, ficou bem mais de boa. As ferramentas modernas de raspagem com IA ajudam você a começar sem exigir um conhecimento técnico pesado. Elas deixam você coletar e organizar dados rapidinho — sem precisar programar.
As melhores ferramentas e softwares de Web Scraping
- para um raspador com IA fácil de usar e com resultados excelentes
- para monitoramento em tempo real e extração em massa
- para automação no-code com muitas integrações
- para raspagem visual mais “profissional”
- para raspagem no-code potente, com foco em evitar bloqueios e detecção de bots
- para API avançada de extração com IA e knowledge graphs
Experimente usar IA para Web Scraping
Teste agora: você pode clicar, explorar e executar o fluxo enquanto assiste.
Como funciona o Web Scraping?
Web scraping é, no fim das contas, coletar dados de sites. Você dá instruções para uma ferramenta, e ela extrai textos, imagens ou qualquer coisa que você precise de uma página e organiza tudo em formato de tabela. Isso quebra um galho enorme em várias situações — de acompanhar preços em e-commerces a juntar dados para pesquisa ou simplesmente montar uma planilha caprichada no Excel ou no Google Sheets.
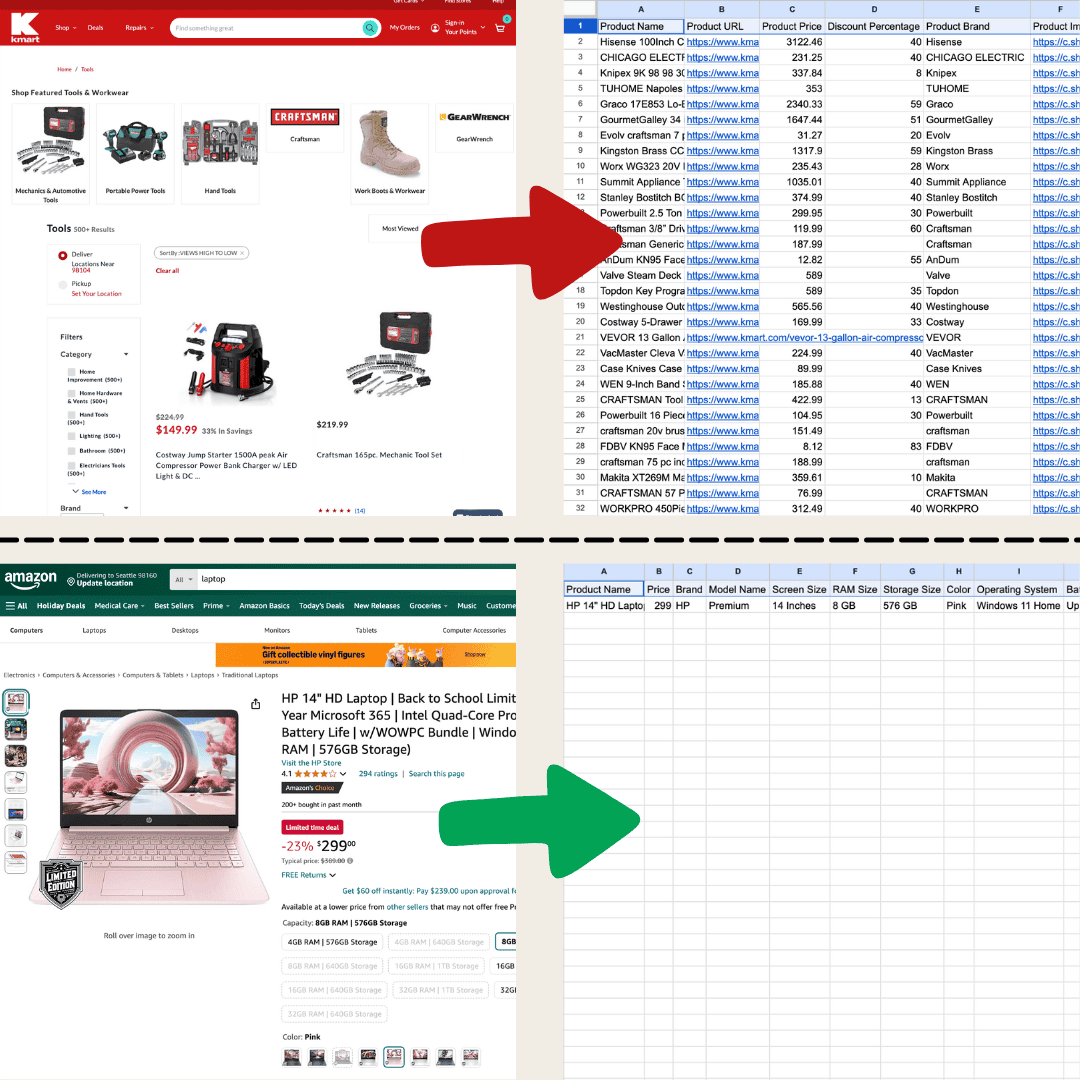 Eu fiz isso com o Thunderbit usando o Raspador Web IA.
Eu fiz isso com o Thunderbit usando o Raspador Web IA.
Existem alguns jeitos de fazer isso. No nível mais básico, dá para copiar e colar manualmente — mas isso vira um trampo gigante quando tem muito dado. Por isso, a maioria das pessoas acaba indo por um destes três caminhos: raspadores tradicionais, raspadores com IA ou código personalizado.
Raspadores tradicionais funcionam definindo regras bem específicas do que capturar com base na estrutura da página. Por exemplo, você configura para pegar nomes de produtos ou preços a partir de determinadas tags HTML. Eles costumam funcionar melhor em sites que mudam pouco, porque qualquer mexida no layout geralmente obriga você a ajustar o raspador.
 Aprender a usar um raspador tradicional leva tempo — e normalmente você precisa de dezenas de cliques para concluir a configuração.
Aprender a usar um raspador tradicional leva tempo — e normalmente você precisa de dezenas de cliques para concluir a configuração.
Raspadores com IA são, na prática, isto: o ChatGPT “lê” o site inteiro e extrai o conteúdo conforme a sua necessidade. Ele pode fazer extração, tradução e resumo ao mesmo tempo. Essas ferramentas usam processamento de linguagem natural para analisar e entender o layout do site — o que ajuda a lidar melhor com mudanças. Se o site reorganizar seções, por exemplo, um Raspador Web IA pode se adaptar sem você precisar reconfigurar tudo. Por isso, são ótimos para sites que mudam com frequência ou têm estruturas mais complexas.
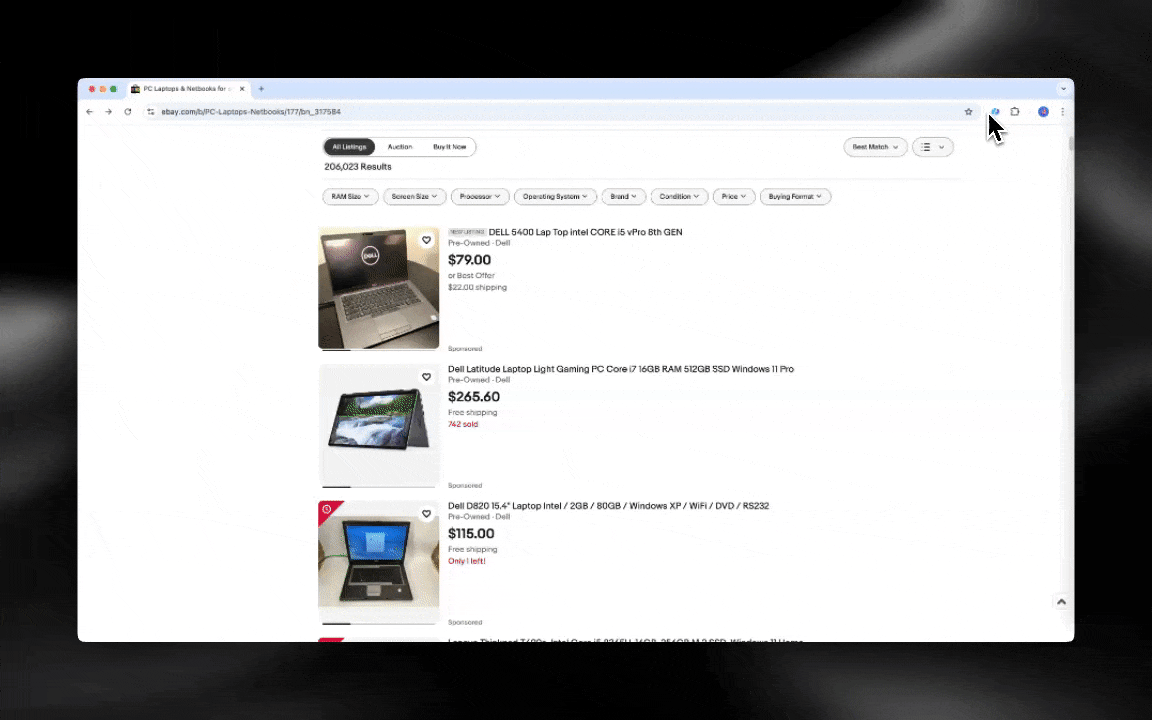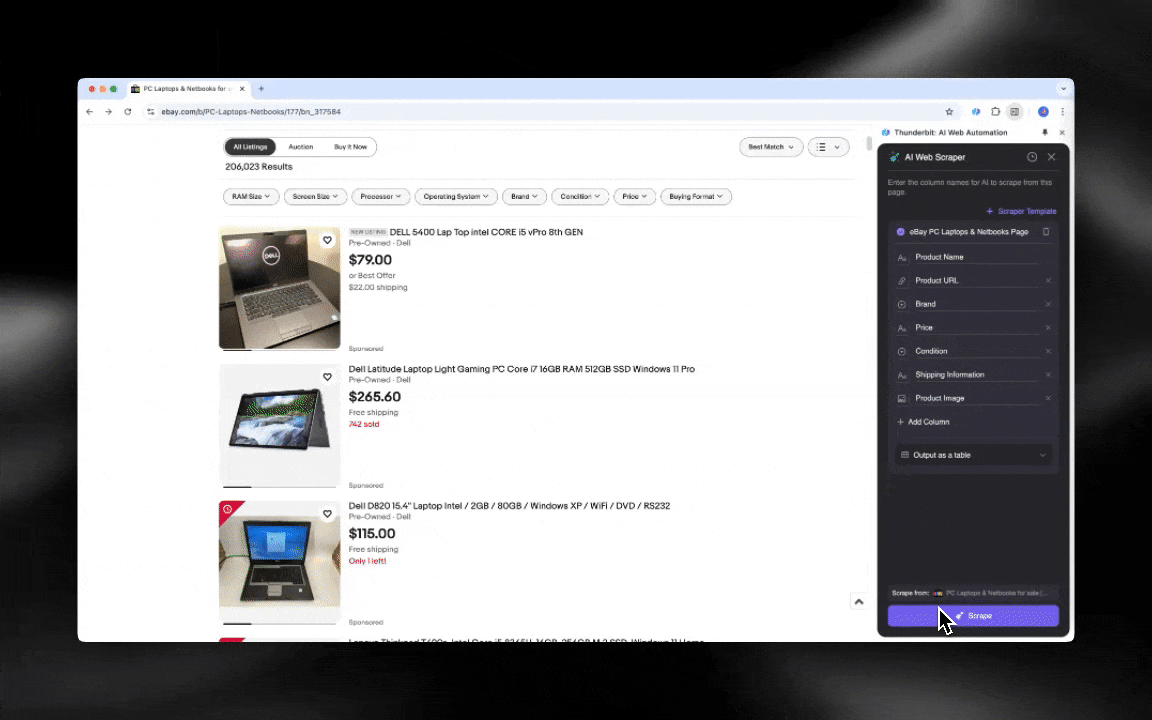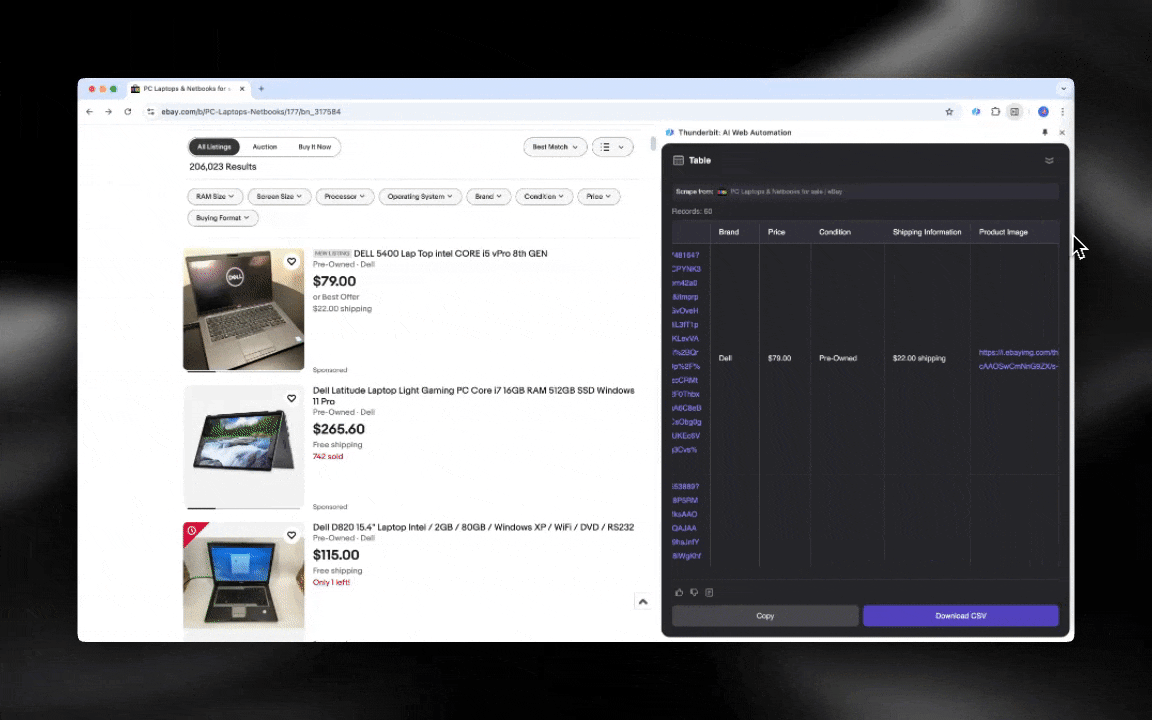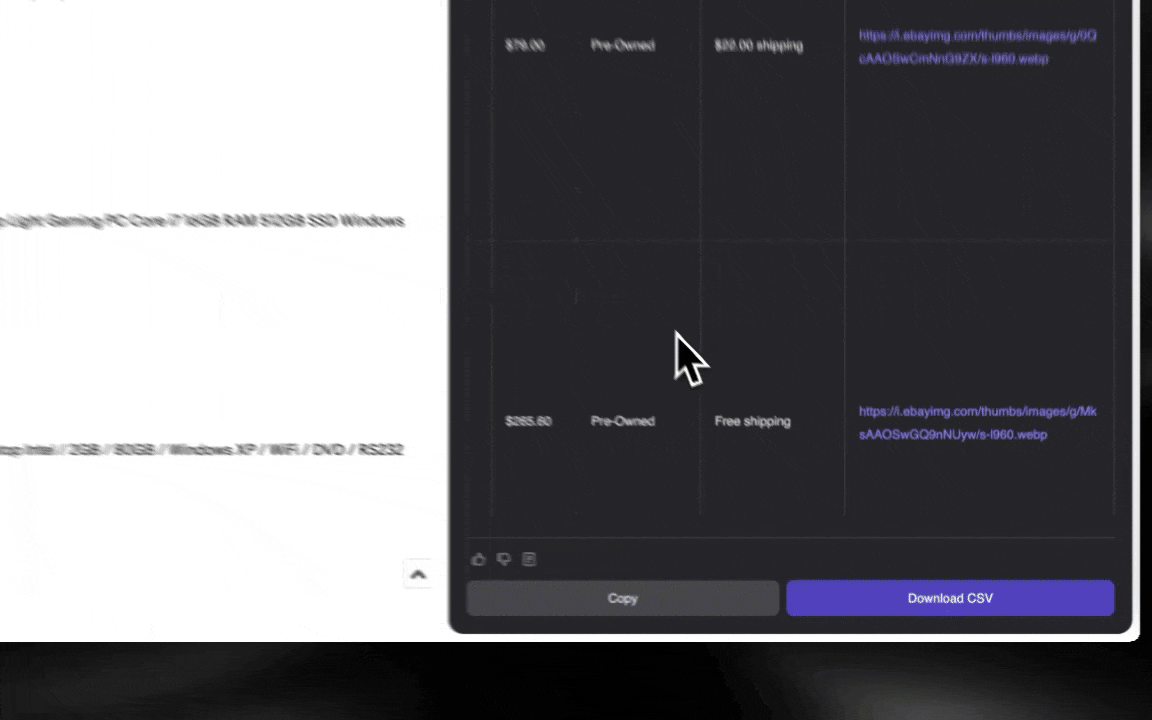 Com um Raspador Web IA, você começa rápido e obtém dados detalhados em poucos cliques.
Com um Raspador Web IA, você começa rápido e obtém dados detalhados em poucos cliques.
Qual escolher? Depende. Se você se sente à vontade mexendo com código ou precisa coletar grandes volumes em um site muito popular, raspadores tradicionais podem ser bem eficientes. Mas se você está começando ou quer algo que acompanhe atualizações do site sem dor de cabeça, um Raspador Web IA costuma ser a melhor escolha. Dá uma olhada na tabela abaixo para cenários mais específicos.
| Cenário | Melhor escolha |
|---|---|
| Raspagem leve em páginas como diretórios, lojas online ou qualquer site com listas | Raspador Web IA |
| A página tem menos de 200 linhas de dados e criar um raspador tradicional levaria tempo demais | Raspador Web IA |
| Você precisa que os dados saiam em um formato específico para enviar a outro sistema (ex.: contatos para importar no HubSpot) | Raspador Web IA |
| Sites muito usados em grande escala, como dezenas de milhares de páginas de produtos da Amazon ou anúncios do Zillow | Raspador Web tradicional |
As melhores ferramentas e softwares de Web Scraping (visão geral)
| Ferramenta | Preço | Principais recursos | Vantagens | Desvantagens |
|---|---|---|---|---|
| Thunderbit | A partir de US$ 9/mês, com plano grátis | Raspador Web IA, detecta e formata dados automaticamente, suporta vários formatos, exportação em 1 clique, interface simples. | Sem código, suporte de IA, integrações com apps como Google Sheets | Em grande escala pode ficar mais lento; recursos avançados podem custar mais |
| Browse AI | A partir de US$ 48,75/mês, com plano grátis | Interface no-code, monitoramento em tempo real, extração em massa, integração de fluxos. | Fácil de usar, integra com Google Sheets e Zapier | Páginas complexas exigem configuração extra; extrações em massa podem gerar timeouts |
| Bardeen AI | A partir de US$ 60/mês, com plano grátis | Automação no-code, integra com 130+ apps, MagicBox transforma tarefas em fluxos. | Muitas integrações, escalável para empresas | Curva de aprendizado para iniciantes; configuração pode levar tempo |
| Web Scraper | Grátis localmente; US$ 50/mês na nuvem | Criação visual de tarefas, suporta sites dinâmicos (AJAX/JavaScript), raspagem na nuvem. | Funciona bem em sites dinâmicos | Para melhor configuração, exige mais conhecimento técnico |
| Octoparse | A partir de US$ 119/mês, com plano grátis | Raspagem no-code, detecção automática de elementos, nuvem com agendamento, biblioteca de templates. | Recursos fortes para sites dinâmicos; lida com restrições | Sites complexos exigem aprendizado |
| Diffbot | A partir de US$ 299/mês | API de extração, API sem regras, NLP para texto não estruturado, knowledge graph amplo. | Extração com IA muito forte; integrações via API; escala grande | Curva de aprendizado para não técnicos; tempo de configuração |
O melhor Web Scraper na era da IA
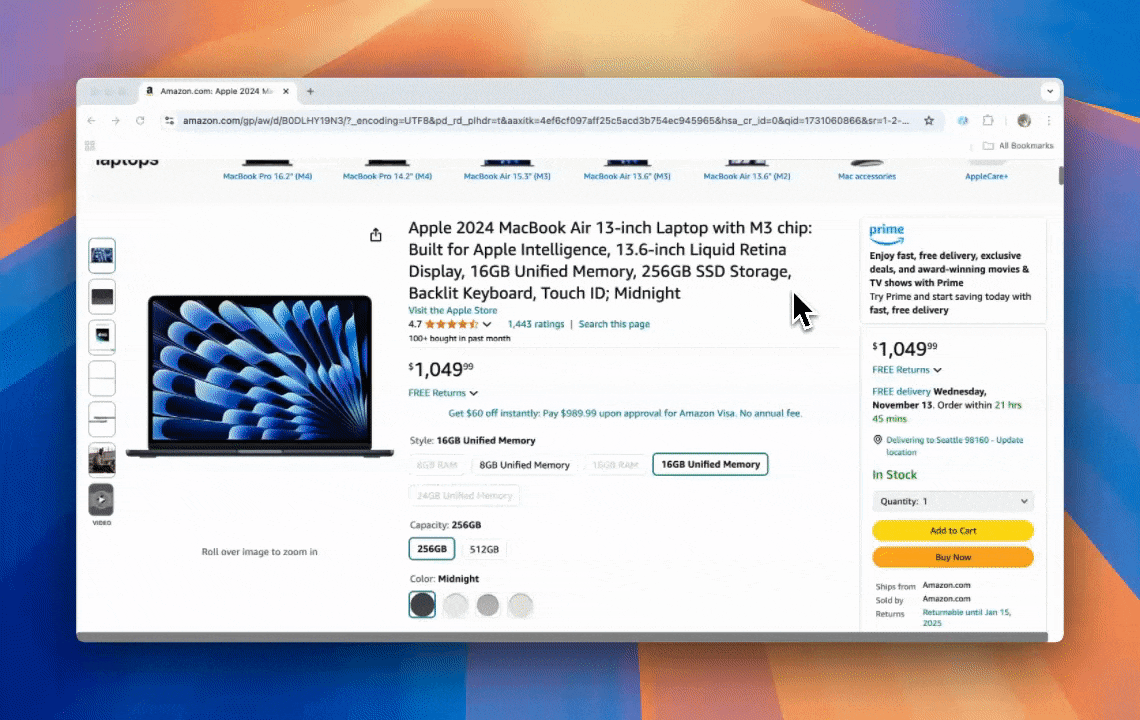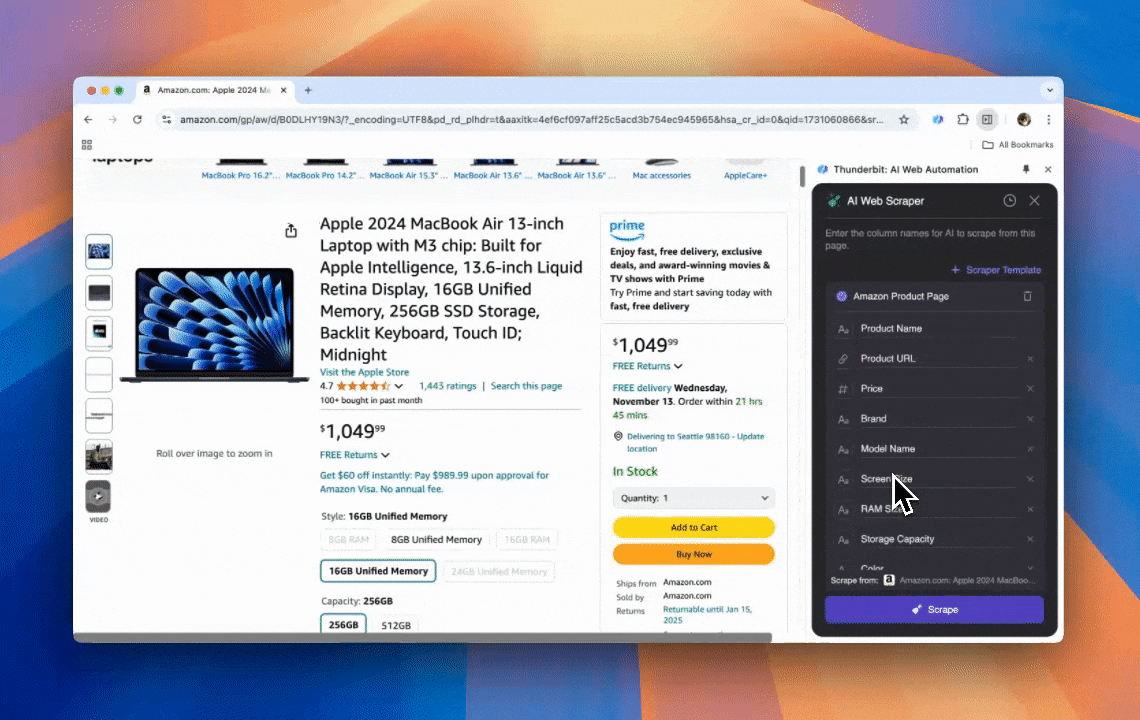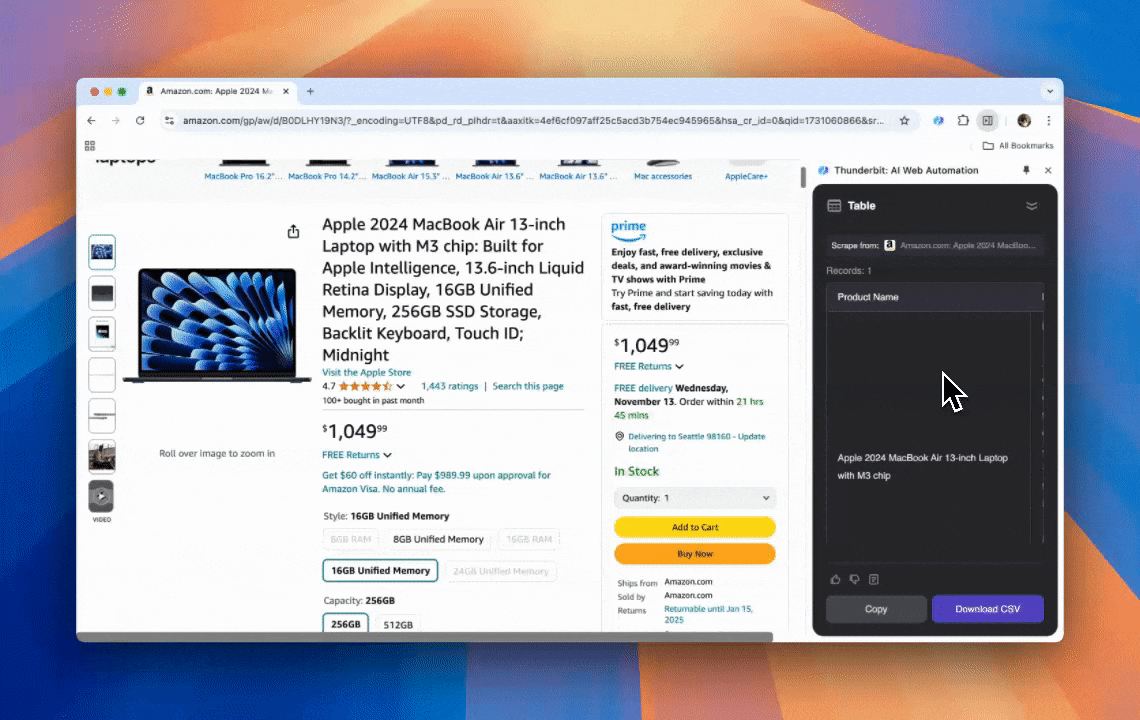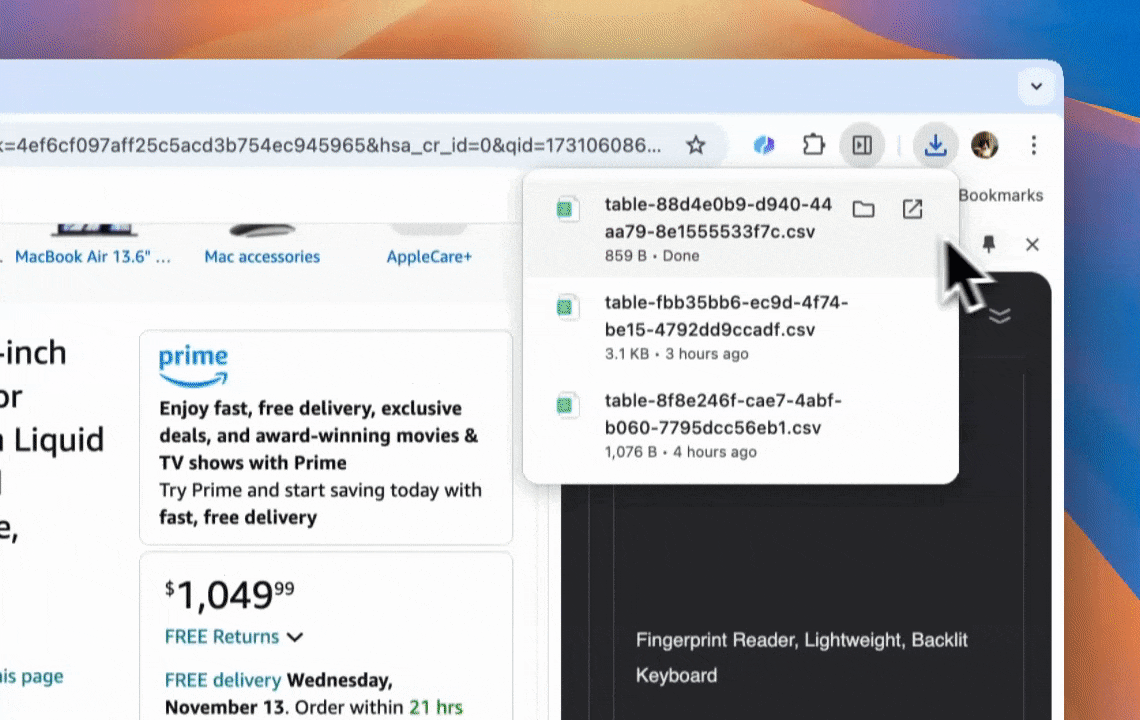
Thunderbit é uma ferramenta parruda e, ao mesmo tempo, bem tranquila de usar para automação web com IA, deixando que pessoas sem habilidades de programação extraiam e organizem dados numa boa. Com a , o do Thunderbit simplifica a raspagem: você puxa dados rápido sem precisar ficar clicando em elementos da página manualmente nem criar raspadores diferentes para cada variação de layout.
Principais recursos
- Flexibilidade com IA: o Raspador Web IA do Thunderbit detecta e formata dados automaticamente, sem necessidade de seletores CSS.
- A experiência mais simples de raspagem: é só clicar em “AI suggest column” e depois em “Scrape” na página que você quer extrair. Fechou.
- Suporte a vários formatos de dados: o Thunderbit pode capturar URLs, imagens e exibir os dados em diferentes formatos.
- Processamento automático de dados: a IA do Thunderbit pode reformatar dados em tempo real — incluindo resumir, categorizar e traduzir para o formato necessário.
- Exportação fácil: exporte para Google Sheets, Airtable ou Notion com um clique.
- Interface amigável: design intuitivo, acessível para qualquer nível de experiência.
Preços
O Thunderbit oferece planos em camadas, começando em US$ 9/mês para 5.000 créditos e indo até US$ 199 para 240.000 créditos. No plano anual, você recebe todos os créditos de uma vez.
Vantagens:
- IA forte que simplifica extração e processamento.
- Sem código, acessível para todos os níveis.
- Ideal para raspagem leve (diretórios, e-commerce etc.).
- Ótimas integrações para exportar direto para apps populares.
Desvantagens:
- Em raspagens muito grandes, pode levar mais tempo para garantir precisão.
- Alguns recursos avançados exigem assinatura paga.
Quer saber mais? Comece ou veja com o Thunderbit.
Melhor Web Scraper para monitoramento de dados e extração em massa
Browse AI
Browse AI é uma ferramenta robusta de raspagem no-code feita para ajudar usuários a extrair e monitorar dados sem escrever código. Ela tem alguns recursos de IA, mas não chega a ser uma raspagem totalmente baseada em IA. Mesmo assim, já dá uma baita força para quem está começando.
Principais recursos
- Interface no-code: permite criar fluxos personalizados só com cliques.
- Monitoramento em tempo real: usa bots para acompanhar mudanças na página e entregar informações atualizadas.
- Extração em massa: consegue lidar com até 50.000 registros de uma vez.
- Integração de fluxos: conecta múltiplos bots para processos mais complexos.
Preços
A partir de US$ 48,75/mês, incluindo 2.000 créditos. Há um plano grátis com 50 créditos por mês para testar recursos básicos.
Vantagens:
- Integra com Google Sheets e Zapier.
- Bots prontos aceleram tarefas comuns de extração.
Desvantagens:
- Páginas complexas podem exigir configuração adicional.
- A velocidade em massa varia e pode gerar timeouts.
Melhor Web Scraper para integração com fluxos de trabalho
Bardeen AI
Bardeen AI é uma ferramenta de automação no-code pensada para simplificar fluxos conectando vários apps. Embora use IA para criar automações personalizadas, não tem a mesma adaptabilidade de uma ferramenta completa de raspagem com IA.
Principais recursos
- Automação no-code: permite configurar fluxos com cliques.
- MagicBox: você descreve a tarefa em linguagem simples e o Bardeen AI transforma isso em um fluxo.
- Muitas integrações: integra com mais de 130 apps, incluindo Google Sheets, Slack e LinkedIn.
Preços
A partir de US$ 60/mês, com 1.500 créditos (aprox. 1.500 linhas de dados). O plano grátis oferece 100 créditos mensais para testar.
Vantagens:
- Grande variedade de integrações para diferentes necessidades.
- Flexível e escalável para empresas de qualquer porte.
Desvantagens:
- Iniciantes podem precisar de tempo para pegar o jeito da plataforma.
- A configuração inicial pode demorar.
Melhor Web Scraper visual para quem já tem experiência
Web Scraper
Sim, é isso mesmo: a ferramenta se chama “Web Scraper”. Web Scraper é uma extensão bem conhecida para Chrome e Firefox que permite extrair dados sem programar, usando uma abordagem visual para montar tarefas de raspagem. Mas, para dominar de verdade, provavelmente você vai precisar passar alguns dias assistindo e aprendendo com os tutoriais acima. Se você quer algo mais leve e direto ao ponto, vai de Raspador Web IA.
Principais recursos
- Criação visual: permite configurar tarefas clicando em elementos da página.
- Suporte a sites dinâmicos: lida com AJAX e JavaScript.
- Raspagem na nuvem: agende tarefas pelo Web Scraper Cloud para raspagens periódicas.
Preços
Grátis para uso local; planos pagos começam em US$ 50/mês para recursos na nuvem.
Vantagens:
- Funciona bem em sites dinâmicos.
- Grátis para uso local.
Desvantagens:
- Exige conhecimento técnico para uma configuração ideal.
- Mudanças no site pedem testes e ajustes mais chatinhos.
Melhor Web Scraper para evitar bloqueio de IP e detecção de bots
Octoparse
Octoparse é um software versátil mais voltado para quem já tem um perfil um pouco mais técnico e precisa coletar e monitorar dados específicos sem programar — ótimo para demandas em grande escala. Ele não depende do navegador do usuário para rodar; em vez disso, usa servidores na nuvem para fazer a raspagem. Assim, consegue oferecer estratégias diferentes para driblar bloqueios de IP e alguns mecanismos de detecção de bots.
Principais recursos
- Operação no-code: cria tarefas sem escrever código, atendendo diferentes níveis técnicos.
- Detecção inteligente automática: identifica dados e elementos da página rapidamente, facilitando a configuração.
- Raspagem na nuvem: suporta raspagem 24/7 com agendamento para coleta flexível.
- Biblioteca ampla de templates: centenas de modelos prontos para sites populares, reduzindo a necessidade de configuração complexa.
Preços
Os planos do Octoparse começam em US$ 119/mês, incluindo 100 tarefas. Há um plano grátis com 10 tarefas por mês para testar.
Vantagens:
- Recursos potentes para sites dinâmicos, com boa adaptabilidade.
- Ajuda a lidar com restrições e desafios de conteúdo dinâmico.
Desvantagens:
- Estruturas complexas podem exigir mais tempo de configuração.
- Iniciantes podem precisar de tempo para aprender as melhores práticas.
Melhor Web Scraper para API avançada de extração com IA
Diffbot
Diffbot é uma ferramenta avançada de extração de dados web que usa IA para transformar conteúdo não estruturado em dados estruturados. Com APIs poderosas e um knowledge graph, o Diffbot ajuda a extrair, analisar e gerenciar informações da web — útil para diferentes setores e aplicações.
Principais recursos
- API de extração de dados: oferece uma API “sem regras”, em que você só fornece a URL e a extração acontece automaticamente, sem criar regras específicas para cada site.
- API de processamento de linguagem natural: extrai entidades, relações e sentimento de textos não estruturados, ajudando a construir knowledge graphs próprios.
- Knowledge Graph: um dos maiores knowledge graphs, conectando um grande volume de entidades, incluindo dados sobre pessoas e organizações.
Preços
Os planos do Diffbot começam em US$ 299/mês, incluindo 250.000 créditos (aprox. 250.000 extrações de páginas via API).
Vantagens:
- Extração “sem regras” muito forte e adaptável.
- Muitas opções de integração via API com sistemas existentes.
- Suporta raspagem em grande escala, adequada para uso corporativo.
Desvantagens:
- A configuração inicial pode exigir aprendizado para quem não é técnico.
- Para usar, é necessário escrever um programa que chame a API.
Para que você pode usar scrapers?
Se você está começando em web scraping, aqui vão alguns casos de uso bem comuns para ajudar a destravar o primeiro passo. Muita gente usa scrapers para coletar listagens de produtos da Amazon, puxar dados imobiliários do Zillow ou reunir informações de empresas no Google Maps. Mas isso é só a pontinha do iceberg — com o do Thunderbit, você consegue coletar dados de praticamente qualquer site, automatizando tarefas e economizando um tempão no dia a dia. Seja para pesquisa, monitoramento de preços ou criação de bases de dados, web scraping abre um monte de caminhos para transformar dados da internet em vantagem prática.
Perguntas frequentes (FAQs)
-
Web scraping é legal?
No geral, web scraping é legal, mas depende dos termos de uso do site e do tipo de dado acessado. Sempre revise as políticas aplicáveis e siga as orientações legais.
-
Preciso saber programar para usar ferramentas de web scraping?
A maioria das ferramentas citadas aqui não exige programação. Porém, ferramentas como Octoparse e Web Scraper podem render melhor quando o usuário tem noções básicas de estrutura web e um raciocínio mais “técnico”.
-
Existem ferramentas gratuitas de web scraping?
Sim. Existem opções gratuitas como BeautifulSoup, Scrapy e Web Scraper, e algumas ferramentas também oferecem planos grátis com recursos limitados.
-
Quais são os desafios mais comuns em web scraping?
Entre os desafios mais frequentes estão conteúdo dinâmico, CAPTCHAs, bloqueio de IP e estruturas HTML complexas. Ferramentas e técnicas mais avançadas ajudam a contornar esses problemas.
Saiba mais:
-
Use IA para trabalhar sem esforço.