
O Google processa algo acima de — algumas estimativas colocam esse número mais perto de — e ele não para de crescer. Todo esse dado de pesquisa é uma mina de ouro para equipes de SEO, operações de vendas, analistas de e-commerce e, cada vez mais, agentes de IA que precisam de evidências em tempo real da web. O problema? Escolher uma SERP API em 2026 parece menos uma decisão de ferramenta e mais decifrar um labirinto de páginas de preços, sistemas de créditos e promessas vagas sobre "JSON estruturado".
Passei as últimas semanas mergulhando em oito provedores de SERP API — testando tempos de resposta, normalizando preços entre modelos de cobrança confusos e verificando quais recursos de SERP cada um realmente converte em campos estruturados. O objetivo: entregar uma comparação honesta, lado a lado, que nenhum outro artigo oferece. Vamos falar de velocidade, custo real em escala, cobertura de parsing, prontidão para agentes de IA e confiabilidade em produção. Se você já se irritou com "você está comparando páginas de preços, não gasto real" (uma citação real de um que encontrei), este artigo é para você.
Por que você precisa de uma SERP API em 2026 (e por que escolher uma é difícil)
Uma SERP API é um serviço hospedado que envia uma consulta de busca para um mecanismo de pesquisa e devolve a página de resultados em formato legível por máquina — normalmente JSON. Em vez de montar sua própria rotação de proxies, lidar com CAPTCHA, renderização de navegador e parsers, você chama um endpoint e recebe dados estruturados de volta. Conceito simples, mercado complicado.
Os casos de uso se expandiram muito além do monitoramento de posições:
- Equipes de SEO precisam de rankings, posse de snippets, perguntas do People Also Ask e visibilidade dos concorrentes.
- Equipes de vendas e GTM usam SERPs para descobrir empresas, páginas de avaliação, diretórios e sinais de compra.
- Equipes de e-commerce monitoram Google Shopping, anúncios pagos e preços dos concorrentes.
- Desenvolvedores de IA alimentam dados de SERP em agentes LLM, pipelines de RAG e ferramentas de workflow como n8n e LangChain.
O deve chegar a , crescendo a cerca de 13,78% de CAGR. As SERP APIs representam uma fatia importante desse bolo.
A frustração central é esta: todo provedor promete "JSON estruturado", mas os elementos reais da SERP que cada um consegue interpretar — PAA, painéis de conhecimento, pacotes locais, anúncios de Shopping, featured snippets — variam muito. O preço também é uma bagunça. Alguns cobram por busca, outros por crédito, outros por resultado, e alguns aplicam tarifas diferentes conforme o nível de velocidade ou a geolocalização. Um usuário do Reddit resumiu bem: "SerpApi cobra por busca bem-sucedida, ScraperAPI embrulha tudo em créditos, e Serperdev parece barato até você mapear os créditos para sua carga de trabalho real."
Este artigo preenche as lacunas que eu não encontrei em nenhum lugar: uma matriz de parsing mostrando o que cada API realmente retorna, preços normalizados em 1 mil/10 mil/100 mil consultas, adequação para agentes de IA e dados de prontidão para produção.
Como testamos: critérios para escolher a melhor SERP API
Avaliei cada provedor em oito dimensões que se conectam diretamente ao que usuários de produção realmente se importam. A maioria dos artigos concorrentes cobre duas ou três delas de forma superficial. Eu quis as oito, com provas.
Velocidade e tempo de resposta. Consultei benchmarks de terceiros — sobretudo a — e a documentação dos provedores. A velocidade importa quando você está construindo painéis em tempo real ou agentes de IA com chamadas de ferramenta que não podem esperar 30 segundos por uma resposta.
Preço em escala (1 mil, 10 mil, 100 mil consultas). Normalizei o preço de cada provedor para custo por 1.000 consultas bem-sucedidas. É a única forma de comparar com justiça modelos baseados em créditos, pacotes por assinatura e pay-as-you-go.
Recursos de SERP interpretados (além dos resultados orgânicos). Conferi documentação e exemplos de resposta para verificar quais elementos de SERP cada API devolve como campos estruturados — não apenas HTML bruto.
Disponibilidade de plano gratuito e pay-as-you-go. Entradas com baixo compromisso importam. Se você não consegue testar um provedor com sua carga real antes de comprometer centenas de dólares, isso é um sinal de alerta.
Integração com IA e automação. Em 2026, mais equipes precisam que SERP APIs alimentem agentes de IA do que dashboards. Estabilidade de esquema, saída limpa e conversão para Markdown importam para o consumo downstream por LLMs.
Suporte a múltiplos mecanismos. A maioria dos artigos foca exclusivamente no Google. Verifiquei quais provedores dão suporte a Bing, Yandex, DuckDuckGo, Baidu e outros.
Limites de taxa e prontidão para produção. Nenhum artigo concorrente compara de forma sistemática rate limits, políticas de retry ou SLAs. Ainda assim, equipes que escalam para milhares de consultas por dia precisam dessa informação.
Facilidade para desenvolvedores. Qualidade da documentação, disponibilidade de SDK e tempo até o primeiro resultado.
1. Thunderbit
adota uma abordagem fundamentalmente diferente das SERP APIs tradicionais. Em vez de oferecer endpoints fixos que interpretam elementos de SERP previamente definidos, a Extract API do Thunderbit permite que você defina seu próprio JSON Schema — e a IA extrai exatamente os campos que você especificar de qualquer página de resultados de busca. A Distill API converte qualquer URL em Markdown limpo, pronto para LLM.
Isso significa que o Thunderbit funciona no Google, Bing, Yandex, DuckDuckGo ou qualquer outro mecanismo de busca — a IA lê a página do zero a cada vez, em vez de depender de seletores codificados. Os layouts de SERP mudam o tempo todo. Você não fica esperando um provedor atualizar um parser.
Principais recursos
- Extract API: defina um JSON Schema personalizado (resultados orgânicos, perguntas do PAA, empresas do local pack, produtos de Shopping — o que você precisar) e receba exatamente esses campos de volta como dados estruturados.
- Distill API: converte qualquer página de SERP em Markdown limpo — ideal para pipelines de RAG e sumarização por LLM.
- Multi-mecanismo por design: funciona em qualquer página de busca acessível, não só no Google.
- Processamento em lote: lide com várias URLs em paralelo.
- Tratamento anti-bot integrado: resolução de CAPTCHA, renderização com JS e rotação de proxies já estão incluídos.
- Limites por plano: Free (10 req/min, 2 simultâneas), Pro (100 req/min, 10 simultâneas), Enterprise (1.000 req/min, 50 simultâneas).
Preços
Modelo baseado em créditos. A Distill custa 1 crédito por página; a Extract custa 20 créditos por página. Há créditos grátis para testes. Usando a matemática do plano anual, o custo marginal da Distill pode cair para cerca de US$ 0,80 por 1 mil páginas, enquanto a Extract sai por volta de US$ 16 por 1 mil páginas em utilização total. O valor da Extract está em entregar exatamente o esquema que seu sistema downstream precisa — sem pós-processamento.
Confira os para ver os pacotes atuais.
Ideal para
Fluxos de trabalho com agentes de IA, pipelines de RAG, scraping multi-mecanismo, equipes que precisam de um esquema flexível em vez de uma saída fixa e qualquer pessoa cansada de esperar um provedor adicionar suporte a um novo recurso de SERP.
2. SerpApi
é a veterana da área — em operação desde 2016, com a maior variedade de endpoints específicos do Google. Cobre Google Search, Maps, Shopping, Scholar, News, Jobs, Trends, Images, Videos e mais.
Principais recursos
- Endpoints dedicados para diferentes produtos do Google, com geotargeting maduro (até o nível da cidade).
- Interpreta PAA, painéis de conhecimento, local pack, anúncios, resultados de Shopping, featured snippets, answer boxes e buscas relacionadas como campos estruturados.
- Documentação bem mantida e bibliotecas cliente em várias linguagens.
Preços
. Plano Starter: US$ 25/mês por 1.000 buscas (na prática, US$ 25 por 1 mil). Plano Popular: US$ 130/mês por 15.000 buscas (~US$ 8,67 por 1 mil). Big Data: US$ 2.750/mês por 500.000 buscas (~US$ 5,50 por 1 mil). Não há opção simples de pay-as-you-go — são pacotes por assinatura.
Velocidade e confiabilidade
O benchmark da HasData aponta cerca de 5,49 segundos de tempo médio de resposta — não é o mais rápido, mas é estável. A SerpApi anuncia SLA de uptime de 99,95% nos planos pagos, e os limites de requisições simultâneas variam conforme o plano.
Ideal para
Equipes que precisam da cobertura mais ampla de produtos do Google (Maps, Scholar, Shopping, Jobs) com alta precisão e esquemas estáveis. Projetos corporativos com orçamento para preços premium.
3. Serper
é a aposta em velocidade e custo. É um player mais novo, focado em scraping rápido de SERP do Google a preços extremamente competitivos, e se tornou popular nas comunidades de n8n e LangChain para integrações com agentes de IA.
Principais recursos
- Saída JSON limpa para Google Search, News, Scholar, Images, Shopping, Videos, Places, Patents e Autocomplete.
- Configuração mínima — em menos de um minuto você já pode começar a puxar resultados.
- Simples o bastante para que frameworks de agentes de IA o integrem nativamente.
Preços
2.500 consultas grátis no cadastro. Preço inicial em torno de US$ 0,001 por busca, caindo para cerca de US$ 0,00075 em alto volume. Bom para pay-as-you-go. Uma ressalva: pedir mais de 10 resultados por consulta pode custar 2 créditos (verifique o comportamento atual no seu painel).
Velocidade e confiabilidade
Está entre os mais rápidos nos benchmarks — a HasData registra cerca de 2,87 segundos em média. O suporte é apenas por e-mail, e a equipe mantém um perfil público relativamente discreto, o que deixa alguns usuários cautelosos. Em concorrência muito alta, alguns avaliadores apontam preocupações com confiabilidade. Para a maioria das cargas de trabalho, porém, ele é sólido.
Ideal para
Projetos sensíveis a orçamento, startups, integrações com agentes de IA que precisam de dados rápidos e baratos de SERP do Google. Rastreamento de posições em alto volume quando o custo por consulta é a principal restrição.
4. Scrapingdog
está no mercado há mais de 5 anos e aparece consistentemente como o mais rápido em benchmarks de terceiros. A HasData mediu cerca de , com taxa de sucesso de 100%.
Principais recursos
- A Google SERP API retorna resultados orgânicos, PAA, featured snippets, anúncios e resultados locais como JSON estruturado.
- Opções de HTML bruto e JSON analisado.
- Documentação em várias línguas com trechos de código para a maioria das linguagens de programação — começar leva minutos, não horas.
- Suporte 24/7.
Preços
. Os planos pagos começam em torno de US$ 40/mês. O preço por chamada começa por volta de US$ 0,001 e cai drasticamente em alto volume — algumas comparações citam tarifas tão baixas quanto US$ 0,000058 nos níveis mais altos.
Velocidade e confiabilidade
Os números de velocidade são realmente impressionantes. Se seu fluxo de trabalho é sensível à latência e você faz extração de SERP do Google em alto volume com esquema fixo, é difícil bater o Scrapingdog em tempo de resposta bruto.
Ideal para
Ferramentas de SEO e rastreadores de posição em alto volume que precisam de baixa latência e baixo custo. Equipes construindo sistemas de produção em que cada milissegundo de resposta da API importa.
5. DataForSEO
não é só uma SERP API — é uma suíte completa de APIs pensada para empresas que constroem produtos de SEO. Cobre SERP, palavras-chave, backlinks, dados de negócios, Google Ads, Trends e mais.
Principais recursos
- Parsing extremamente abrangente de recursos de SERP — orgânico, pago, local pack, knowledge graph, PAA, featured snippets, shopping, imagens, vídeos, top stories e mais.
- Dois modos: Live (sincrono) para dashboards em tempo real, e Standard (assíncrono) para fluxos em lote, onde você enfileira tarefas e busca os resultados depois.
- Multi-mecanismo: Google, Bing, Yahoo, Baidu, Naver, Seznam e outros.
Preços
Modelo pay-as-you-go, mas o custo varia por endpoint, mecanismo, dispositivo, prioridade e modo. O preço de SERP normalmente varia de cerca de US$ 0,0006 a US$ 0,002 por tarefa para o Google orgânico, dependendo de standard vs. live e das configurações de prioridade. A documentação é densa — reserve tempo para usar a calculadora de preços. .
Velocidade e confiabilidade
O modo assíncrono Standard pode ser mais lento (~10 segundos), porque as tarefas ficam em fila. Os modos Live/de alta velocidade custam mais, mas são adequados para dashboards em tempo real. Histórico longo, estabilidade comprovada e suporte corporativo disponível.
Ideal para
Empresas SaaS construindo plataformas de SEO, dashboards de rastreamento de posição e ferramentas de pesquisa de palavras-chave. Equipes confortáveis com documentação complexa e infraestrutura de nível enterprise.
6. Bright Data
é o peso-pesado corporativo. Sua SERP API é apenas um produto entre muitos — proxies, datasets, Web Unlocker e ferramentas de scraping. A proposta de valor é escala, confiabilidade e infraestrutura.
Principais recursos
- Endpoints dedicados para Google Maps, Shopping e busca geral — além de suporte multi-mecanismo via infraestrutura de proxy cobrindo Bing, Yahoo, Yandex e DuckDuckGo.
- Alega taxa de sucesso de 100% com tecnologia integrada de desbloqueio.
- Onde a Bright Data realmente se destaca: geotargeting, concorrência simultânea e desbloqueio em escala corporativa.
Preços
Voltado para empresas. Os preços públicos mostram opções de pay-as-you-go e assinatura, e muitas comparações citam compromissos iniciais em torno de US$ 499/mês. O custo por chamada começa perto de US$ 0,005, mas cai com volume. . Créditos de teste disponíveis (US$ 5).
Velocidade e confiabilidade
Benchmarks costumam mostrar entre 2 e 5,58 segundos. O motivo para comprar Bright Data não é a latência mediana bruta — é o SLA corporativo, suporte dedicado e uma infraestrutura que lida com milhões de requisições simultâneas sem degradação. A recomenda aumento gradual de volume.
Ideal para
Equipes enterprise coletando milhões de SERPs por mês. Organizações que precisam de dados de Google Maps/negócios locais em escala. Equipes que já usam os produtos de proxy da Bright Data.
7. ScraperAPI
é uma API de web scraping de uso geral que também oferece endpoints estruturados para SERP do Google. É a opção "uma ferramenta para tudo" — fácil de integrar, com uma rede proxy de mais de 40 milhões de IPs.
Principais recursos
- Endpoints de dados estruturados para Google Search, Shopping, News e Jobs.
- Anti-bloqueio baseado em machine learning e resolução de CAPTCHA, com renderização de JavaScript incluída sem custo extra.
- Suporte a geotargeting para resultados localizados.
Preços
Teste grátis de 7 dias com 5.000 créditos. Os planos pagos começam em cerca de US$ 49/mês. O detalhe importante: chamadas de SERP podem consumir créditos diferentes de requisições de scraping simples, então sempre normalize pelo número real de consultas SERP bem-sucedidas entregues. .
Velocidade e confiabilidade
Aqui está a parte honesta: o benchmark da HasData registra cerca de 33,66 segundos de resposta média para consultas SERP. Isso é significativamente mais lento do que SERP APIs dedicadas. A taxa de sucesso é alta (99,9%), mas a latência a torna menos adequada para aplicações em tempo real. Melhor para processamento em lote.
Ideal para
Equipes que precisam de uma solução geral de web scraping com SERP como complemento. Projetos em que a velocidade é menos crítica do que a confiabilidade e a facilidade de configuração. Desenvolvedores que já usam a ScraperAPI para outras tarefas de scraping e querem consolidar fornecedores.
8. Apify
não é uma SERP API pura. É uma plataforma de scraping e automação construída em torno de "Actors" — scripts reutilizáveis para tarefas como scraping de Google Search, extração de Maps e automação de workflows. Pense nela como um marketplace onde você escolhe (ou cria) o scraper que se encaixa exatamente na sua necessidade.
Principais recursos
- Marketplace de prontos, com cobertura variada de recursos.
- Altamente personalizável — crie fluxos de scraping sob medida, encadeie actors e agende execuções.
- Saída em JSON; flexibilidade para interpretar recursos específicos da SERP via configuração do actor.
- Forte para combinar extração de SERP com outras tarefas de scraping/automação.
Preços
Plano gratuito com créditos mensais da plataforma (~US$ 5, cerca de 1.400 resultados). Os planos pagos começam em cerca de US$ 49/mês. O custo no nível de actor varia — alguns cobram por resultado, outros por unidade de computação. Comparações de terceiros costumam colocar a Apify em torno de US$ 0,003 por busca em pequena escala. .
Velocidade e confiabilidade
A HasData registra cerca de 8,2 segundos em média. A arquitetura baseada em actors adiciona overhead em comparação com endpoints SERP dedicados. Melhor para fluxos agendados/em lote do que para consultas em tempo real.
Ideal para
Equipes que precisam de scraping personalizado + automação além dos dados de SERP. Projetos que combinam extração de SERP com outras tarefas de web scraping. Desenvolvedores que querem máxima flexibilidade em vez de endpoints prontos.
Matriz de parsing de recursos de SERP: o que cada API realmente retorna
Esta é a comparação que eu não consegui encontrar em nenhum outro lugar. Todo provedor diz "JSON estruturado", mas os elementos reais de SERP interpretados como campos de primeira classe variam bastante. Verifiquei a documentação e exemplos de resposta de cada um.
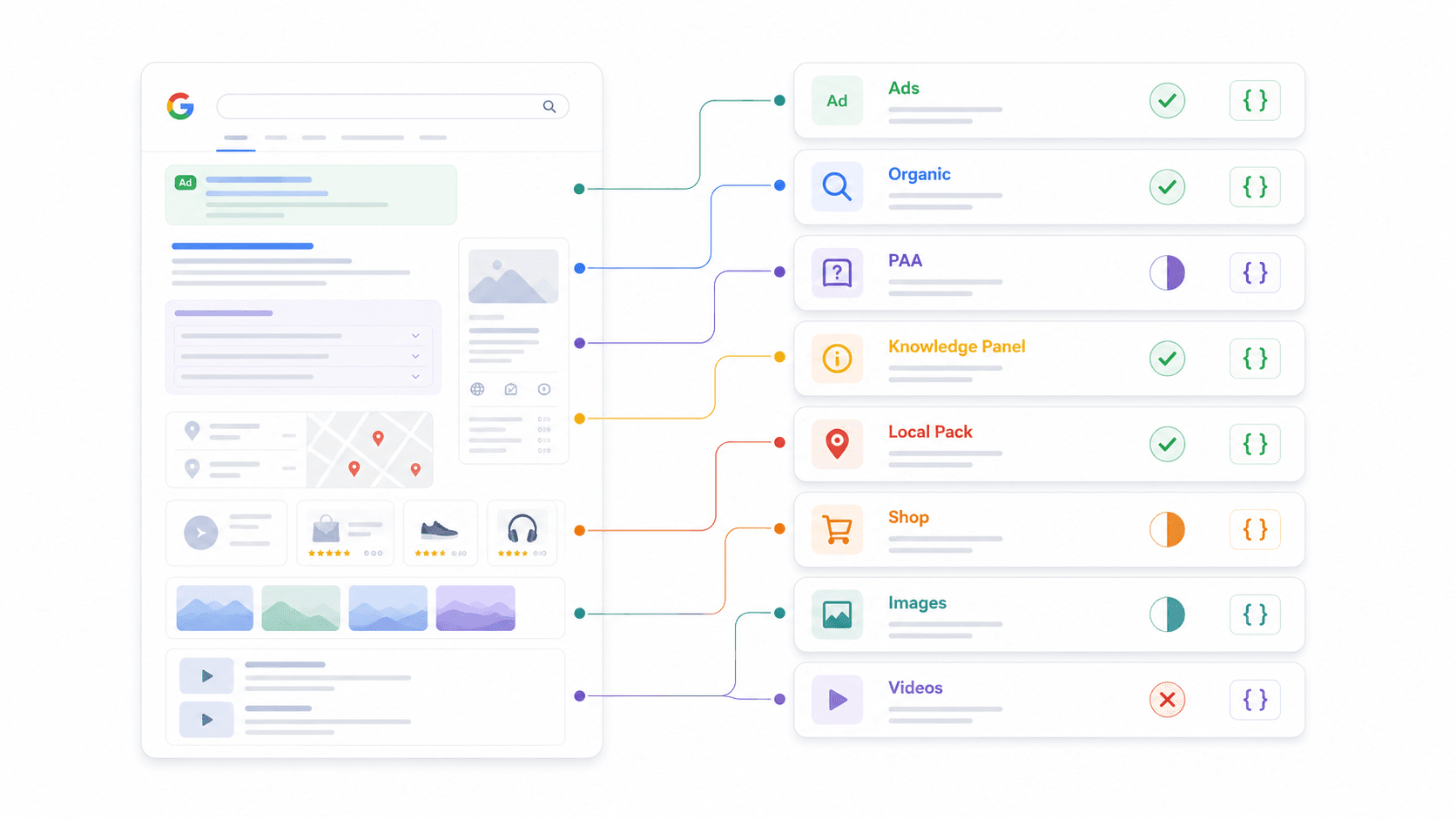
| Recurso de SERP | Thunderbit | SerpApi | Serper | Scrapingdog | DataForSEO | Bright Data | ScraperAPI | Apify |
|---|---|---|---|---|---|---|---|---|
| Resultados orgânicos | Esquema personalizado | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | Depende do actor |
| People Also Ask | Esquema personalizado | ✅ | ✅ | ✅ | ✅ | Parcial | Parcial | Depende do actor |
| Painel de conhecimento | Esquema personalizado | ✅ | Parcial | Parcial | ✅ | Parcial | Parcial | Depende do actor |
| Local Pack / Maps | Esquema personalizado | ✅ | ✅ | Parcial | ✅ | ✅ | Parcial | Depende do actor |
| Resultados de Shopping | Esquema personalizado | ✅ | ✅ | Parcial | ✅ | ✅ | ✅ | Depende do actor |
| Featured Snippets | Esquema personalizado | ✅ | Parcial | ✅ | ✅ | Parcial | Parcial | Depende do actor |
| Anúncios (topo/fundo) | Esquema personalizado | ✅ | Parcial | ✅ | ✅ | Parcial | Parcial | Depende do actor |
| Pacote de imagens | Esquema personalizado | ✅ | ✅ | ✅ | ✅ | Parcial | Parcial | Depende do actor |
| Resultados em vídeo | Esquema personalizado | ✅ | ✅ | Parcial | ✅ | Parcial | Parcial | Depende do actor |
O que "Esquema personalizado" significa no Thunderbit: em vez de pré-definir quais recursos da SERP ele interpreta, você define seu próprio JSON Schema para extrair exatamente os campos de que precisa. Quer perguntas do PAA junto com resumos de respostas e sinais de intenção comercial? Defina esse esquema e a IA entrega. Essa flexibilidade é o motivo de o Thunderbit funcionar em qualquer mecanismo de busca — não apenas no Google.
Por que isso importa para seu fluxo de trabalho: se você precisa de dados do PAA para estratégia de conteúdo, confirme se o provedor realmente os interpreta. Se você monitora anúncios de Shopping para e-commerce, verifique se existem campos estruturados de Shopping. Não assuma que "JSON estruturado" significa cobertura completa.
Custo real em escala: comparação de preço por consulta
Os preços listados nos sites não contam a história toda. Normalizei tudo para custo por 1.000 consultas bem-sucedidas em três faixas de volume.
| Provedor | Custo por 1 mil consultas | Custo por 10 mil consultas | Custo por 100 mil consultas | Pay-as-you-go? | Plano gratuito |
|---|---|---|---|---|---|
| Thunderbit (Distill) | ~US$ 0,80–3,20 | ~US$ 8–32 | ~US$ 80–320 | Pacote de créditos | Créditos grátis |
| Thunderbit (Extract) | ~US$ 16–64 | ~US$ 160–640 | ~US$ 1.600–6.400 | Pacote de créditos | Créditos grátis |
| SerpApi | US$ 25 (Starter) | ~US$ 87 (Popular) | ~US$ 550 (Big Data) | Não (assinatura) | 250/mês |
| Serper | ~US$ 1 | ~US$ 10 | ~US$ 75–100 | Sim | 2.500 consultas |
| Scrapingdog | ~US$ 1 | ~US$ 10 ou menos | Pode cair bem abaixo de US$ 10 | Plano/créditos | 1.000 créditos |
| DataForSEO | ~US$ 0,60–2 | ~US$ 6–20 | ~US$ 60–200 | Sim | Créditos de teste |
| Bright Data | ~US$ 0,50–5+ | Depende de cotação | Melhor em volume corporativo | Sim/plano | Créditos de teste (US$ 5) |
| ScraperAPI | Depende de créditos | Depende de créditos | Depende de créditos | Plano/créditos | 5.000 créditos de teste |
| Apify | ~US$ 3 (pequena escala) | Depende do actor | Depende do actor | Créditos da plataforma | Créditos gratuitos mensais |
Custos ocultos para observar:
- Possível cobrança de 2 créditos do Serper para mais de 10 resultados por consulta.
- Diferenças de preço da DataForSEO entre os modos standard e live/alta prioridade.
- Multiplicadores de crédito da ScraperAPI para SERP versus scraping simples.
- Compromissos mínimos corporativos da Bright Data.
Valor em cada faixa:
- Projetos paralelos (US$ 50/mês): Serper ou Scrapingdog para JSON fixo de SERP do Google.
- Equipes em crescimento (10 mil–50 mil consultas/mês): Serper, Scrapingdog ou DataForSEO, dependendo da profundidade de parsing.
- Enterprise (100 mil+ consultas/mês): DataForSEO, Bright Data ou SerpApi Big Data.
- Extração AI-first: Thunderbit, porque o esquema corresponde às expectativas do agente downstream sem pós-processamento.
Melhor SERP API para agentes de IA e fluxos com LLM em 2026
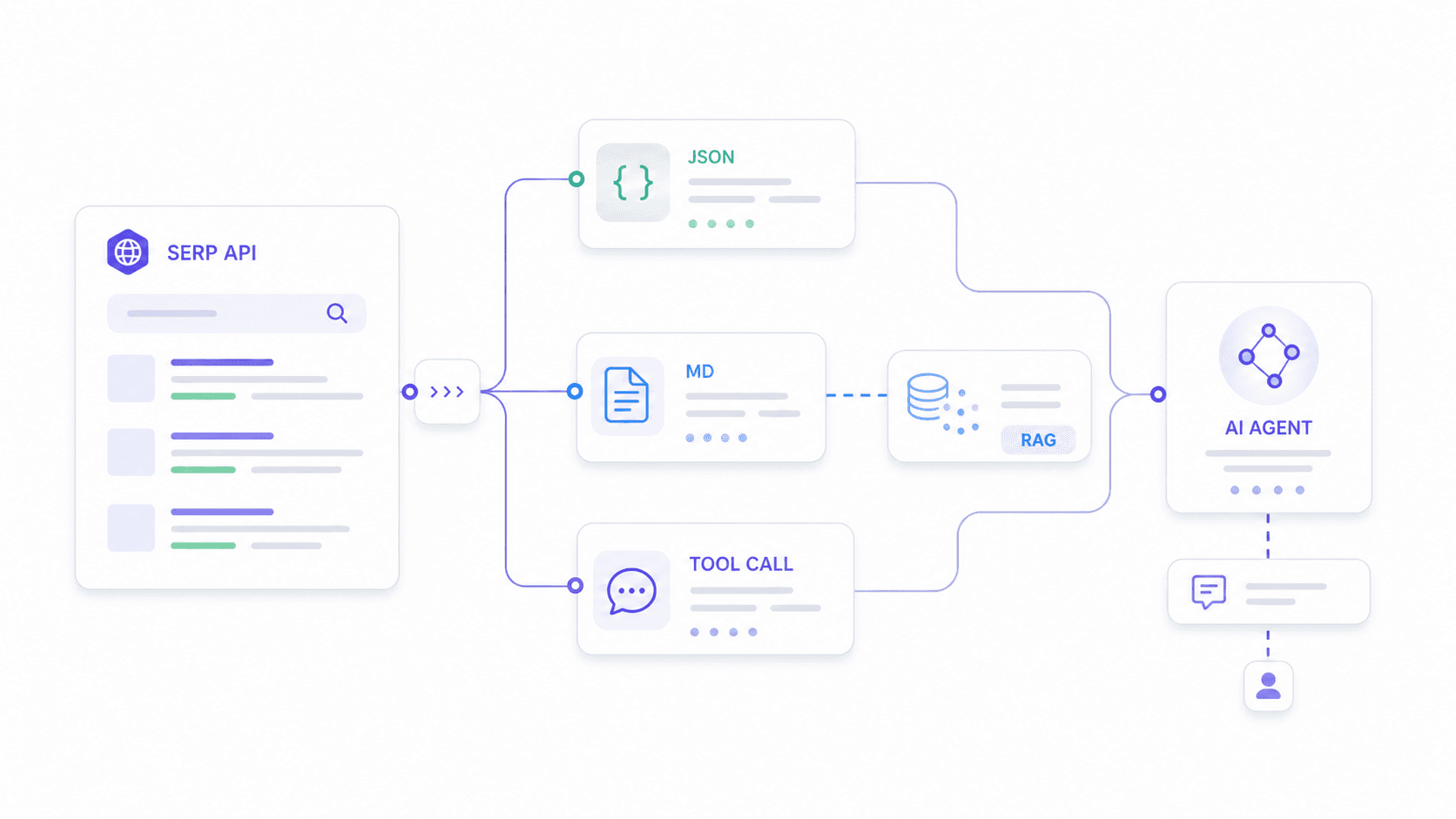
Este é o caso de uso que ninguém mais cobre bem. Encontrei pelo menos três em que usuários descrevem tentar integrar SERP APIs com fluxos do n8n e agentes de IA, com um deles afirmando explicitamente que "não descobriu como fazer funcionar direito com um agente de IA".
Agentes de IA precisam de coisas diferentes de dashboards de rastreamento de posição. Eles precisam de:
- JSON com esquema estável que não quebre a lógica de parsing quando um provedor alterar o formato de saída.
- Campos de saída personalizados que correspondam ao que o modelo downstream espera — não um dump genérico de tudo.
- Markdown ou texto limpo para pipelines de embedding em RAG.
- Latência baixa o suficiente para chamadas de ferramenta em tempo real.
Como cada provedor se encaixa em uma stack de agente de IA
| Provedor | Adequação para agente de IA | Por quê |
|---|---|---|
| Thunderbit | Excelente | JSON Schema personalizado (Extract API) + Markdown para RAG (Distill API). O mais flexível para extração específica para agentes. |
| Serper | Muito boa | JSON rápido e limpo, popular nas comunidades n8n/LangChain. Simples e barato para chamadas básicas de busca. |
| SerpApi | Boa | Esquema estável, documentação excelente. Funciona bem quando o agente precisa de verticais do Google (Maps, Scholar, Shopping). |
| DataForSEO | Boa | Melhor quando o agente faz parte de um pipeline maior de dados de SEO. |
| Scrapingdog | Boa | Rápido e barato; o esquema é estável para SERP do Google. |
| Bright Data | Boa | Coleta de dados frescos em escala corporativa, em vários mecanismos/regiões. |
| ScraperAPI | Moderada | Melhor quando o agente também precisa de crawling geral da web. |
| Apify | Moderada a boa | Flexível, mas mais lento; melhor para workflows em lote agendados. |
Exemplo prático com Thunderbit: imagine que seu agente de IA precisa analisar a intenção de busca para "melhor CRM para imobiliária". Você define um esquema pedindo resultados orgânicos (título, URL, snippet, posição), perguntas do People Also Ask com resumos de resposta e uma classificação de intenção comercial. A Extract API do Thunderbit devolve exatamente essa estrutura — nem mais, nem menos. Seu agente não desperdiça tokens analisando campos irrelevantes ou limpando artefatos de HTML.
Para pipelines de RAG, a Distill API do Thunderbit converte a página de SERP em Markdown limpo, pronto para embedding. A maioria das SERP APIs dedicadas retorna esquemas JSON fixos; a abordagem do Thunderbit permite que desenvolvedores adaptem a saída ao que o modelo downstream realmente espera.
Matriz de decisão por caso de uso: se você precisa de X, use Y
Usuários de fóruns continuam pedindo recomendações específicas mapeadas para seus fluxos reais — não conselhos genéricos do tipo "depende". Então montei isto.
| Seu caso de uso | Melhor escolha | Segunda opção | Por quê |
|---|---|---|---|
| Rastreamento de posição SEO (alto volume) | DataForSEO | Scrapingdog | Endpoints nativos de SEO, preço em lote, parsing abrangente |
| Dados de Google Maps / negócios locais | SerpApi | Bright Data | Endpoint de Maps maduro; a Bright Data se encaixa em scraping local em escala corporativa |
| Agente de IA / automação n8n | Thunderbit | Serper | Esquema personalizado + Markdown para RAG; Serper é rápido e barato para chamadas simples |
| MVP com orçamento / projeto paralelo (<US$ 50/mês) | Serper | Scrapingdog | Planos gratuitos generosos, pay-as-you-go, configuração mínima |
| Multi-mecanismo (Bing, Yandex, DuckDuckGo) | Thunderbit | DataForSEO | O Thunderbit funciona em qualquer mecanismo via extração por IA; a DataForSEO tem endpoints multi-mecanismo |
| Agregação de avaliações do Google | SerpApi | DataForSEO | Endpoints dedicados de parsing de avaliações |
| Monitoramento de e-commerce / shopping | SerpApi | DataForSEO | Forte cobertura de Google Shopping e campos estruturados |
| Fluxos de scraping personalizados | Apify | ScraperAPI | Flexibilidade de actor; a ScraperAPI é fácil para scraping geral + SERP |
Guia rápido por perfil:
- Equipe de SEO: comece com DataForSEO se estiver construindo dashboards; use SerpApi se a cobertura de verticais do Google e a documentação importarem mais do que o preço.
- Equipe de vendas: use Thunderbit quando o fluxo abranger SERPs, páginas de diretório e enrichment; use Serper para consultas simples de descoberta de leads.
- Desenvolvedor de ferramentas de IA: Thunderbit para esquemas personalizados/RAG, Serper para busca rápida e barata, SerpApi para verticais robustas do Google.
- Empreendedor solo: comece com os planos gratuitos do Serper, Scrapingdog, SerpApi e Thunderbit. Rode as mesmas 20 consultas parecidas com produção antes de fechar qualquer plano.
Limites de taxa, confiabilidade e prontidão para produção comparados
Gostaria que esta seção existisse quando eu estava avaliando provedores pela primeira vez para fluxos de produção. Equipes que escalam para milhares de consultas por dia precisam de limites previsíveis, retries automáticos e garantias de uptime — e nenhum outro artigo comparativo trata disso de forma sistemática.
| Provedor | Rate limit | Requisições simultâneas | Retry em falha | SLA / uptime |
|---|---|---|---|---|
| Thunderbit Free | 10 req/min | 2 | Integrado (anti-bot, CAPTCHA) | — |
| Thunderbit Pro | 100 req/min | 10 | Integrado | — |
| Thunderbit Enterprise | 1.000 req/min | 50 | Integrado | Termos personalizados |
| SerpApi | Baseado no plano (buscas/hora) | Baseado no plano | O provedor lida com proxies/CAPTCHA | SLA de 99,95% |
| Serper | Baseado na conta/plano | Não amplamente publicado | Retry manual no cliente recomendado | Sem SLA público |
| Scrapingdog | Baseado no plano | Verificar termos do plano | Anti-bloqueio tratado | Nem sempre público |
| DataForSEO | Documentado por endpoint/modo | Varia conforme o modo | O modo assíncrono suporta polling/retry | Suporte enterprise |
| Bright Data | Documentado, aumente gradualmente | Em escala corporativa | Desbloqueio integrado | SLA corporativo |
| ScraperAPI | Concorrência baseada no plano | Depende de créditos | Lida com retries/proxies | Opções de suporte pago |
| Apify | Depende de actor/memória/compute | Limites da plataforma | Configuração no nível do actor | Confiabilidade da plataforma |
Checklist de produção antes de contratar:
- Pergunte se o provedor cobra por requisições falhadas ou bloqueadas.
- Confirme concorrência exata, requisições por minuto e comportamento de burst.
- Verifique se geotargeting, mobile vs. desktop e renderização JS alteram o consumo de créditos.
- Salve respostas JSON de exemplo de 20 a 50 consultas reais e compare os nomes dos campos ao longo dos dias para validar a estabilidade do esquema.
- Adicione retries do lado do cliente e budgets de timeout se os dados de SERP forem críticos para a missão.
Resumo rápido: as 8 SERP APIs comparadas
| Provedor | Velocidade média | Custo por 1 mil | Plano gratuito | Cobertura de parsing | Ajuste para IA | Multi-mecanismo | Veredito |
|---|---|---|---|---|---|---|---|
| Thunderbit | Médio (extração por IA) | Baixo (Distill) a premium (Extract) | Sim | Personalizado (qualquer recurso) | Excelente | Excelente | Melhor para extração de SERP customizada nativa de IA e RAG |
| SerpApi | ~5,5 s | Premium | 250/mês | Excelente (fixa) | Boa | Verticais amplas do Google | Melhor cobertura madura do Google |
| Serper | ~2–3 s | Muito baixo | 2.500 consultas | Boa | Muito boa | Principalmente Google | Melhor API rápida e barata para IA/MVPs |
| Scrapingdog | ~1,25 s | Muito baixo em escala | 1.000 créditos | Boa | Boa | Verificar mecanismos | Melhor combinação de velocidade/custo |
| DataForSEO | Médio–lento (standard) | Baixo–moderado | Créditos de teste | Excelente | Boa | Excelente | Melhor infraestrutura para plataforma de SEO |
| Bright Data | ~2–5,5 s | Enterprise | Teste (US$ 5) | Boa (dependente do produto) | Boa | Excelente | Melhor coleta em escala corporativa |
| ScraperAPI | ~33 s | Depende de créditos | 5.000 de teste | Moderada | Moderada | Endpoints do Google | Melhor quando SERP é só uma parte de um scraping mais amplo |
| Apify | ~8 s | Depende do actor | Créditos mensais | Depende do actor | Moderada–boa | Depende do actor | Melhor para workflows personalizados de automação |
Como o Thunderbit se encaixa no seu fluxo de SERP
Um pouco mais de contexto sobre por que nossa equipe construiu a API do Thunderbit desse jeito. O modelo tradicional de SERP API — endpoints fixos, campos de saída pré-definidos, só Google — funciona bem para rastreamento de posição simples. Mas, no momento em que você precisa de algo um pouco diferente (respostas do PAA com sentimento, resultados do local pack com contagem de avaliações, ou dados de Shopping formatados para um esquema específico de banco de dados), você acaba preso em pós-processamento ou trocando de provedor.
A Extract API do Thunderbit inverte esse modelo. Você diz o que quer por meio de um JSON Schema, e a IA descobre como obter isso da página de busca que você indicar. Google hoje, Bing amanhã, um mecanismo vertical de nicho na semana que vem — mesma API, mesma abordagem.
A Distill API resolve um problema diferente: transformar páginas de SERP bagunçadas em Markdown limpo que os LLMs realmente conseguem consumir sem engasgar com artefatos de HTML, elementos de navegação e scripts de rastreamento. Se você está construindo um pipeline de RAG que precisa de evidência de busca fresca, este é o caminho mais rápido de "SERP ao vivo" para "conteúdo embutido".
Ambos os endpoints incluem tratamento anti-bot, resolução de CAPTCHA e renderização de JS prontos para uso. Você não paga extra por isso — tudo está embutido no custo em créditos.
Teste você mesmo: para extração no navegador, ou acesse a API diretamente para fluxos programáticos. Nosso tem tutoriais se você quiser ver tudo em ação antes de escrever código.
Uma nota sobre legalidade
Isso aparece em toda FAQ, então aqui vai a versão curta: a legalidade de scraping de SERP depende dos fatos e da jurisdição. O caso estabeleceu que raspar dados publicamente acessíveis não é necessariamente crime de computador, mas isso não concede permissão geral. O Google por scraping de SERP, o que sinaliza pressão comercial ativa em torno do acesso.
Conselho prático: use APIs de fornecedores de acordo com seus termos, evite coletar dados pessoais a menos que seja necessário e pergunte aos provedores como eles tratam conformidade. Não presuma que scraping de SERP é isento de risco.
Conclusão
Nenhum provedor vence em todas as dimensões — a escolha certa depende do seu caso de uso, orçamento e stack técnica. Depois de normalizar preços, testar velocidade, mapear cobertura de parsing e avaliar a prontidão para agentes de IA, meu framework de decisão é este:
- Precisa de flexibilidade + prontidão para agentes de IA? → Thunderbit
- Precisa de ampla cobertura de produtos do Google? → SerpApi
- Precisa de velocidade + menor custo? → Serper ou Scrapingdog
- Vai construir uma plataforma de SEO? → DataForSEO
- Escala corporativa com SLA? → Bright Data ou DataForSEO
- Scraping geral + SERP ocasional? → ScraperAPI ou Apify
Comece pelos planos gratuitos. Rode 20 a 50 consultas reais que correspondam à sua carga de produção. Compare as respostas JSON. Verifique o custo real depois de créditos e multiplicadores. Só então feche contrato.
Os preços mudam com frequência nesse mercado — esta comparação foi normalizada a partir das páginas públicas atuais em maio de 2026. Se você estiver lendo isso meses depois, confira novamente antes de comprar.
Para saber mais sobre abordagens de e como elas se comparam aos métodos tradicionais, escrevemos bastante sobre o tema. E se você estiver avaliando , a extensão Chrome do Thunderbit também resolve esse lado da questão.
FAQs
1. O que é uma SERP API e quem precisa de uma?
Uma SERP API é um serviço que envia consultas de busca para mecanismos como Google, Bing ou Yandex e devolve os resultados como dados estruturados (normalmente JSON). Profissionais de SEO usam para rastrear posições, equipes de vendas para descoberta de leads, equipes de e-commerce para monitoramento de preços e desenvolvedores de IA para alimentar agentes e pipelines de RAG com dados de busca em tempo real.
2. Quanto custa raspar 1.000 resultados de busca do Google via API?
O custo varia bastante — de cerca de US$ 0,60 por 1 mil (DataForSEO no nível standard) até cerca de US$ 25 por 1 mil (plano Starter da SerpApi). Os descontos em alto volume variam muito entre provedores. Sempre normalize pelo custo por 1.000 consultas bem-sucedidas, em vez de comparar apenas o preço destacado.
3. Posso usar uma SERP API com agentes de IA como LangChain ou n8n?
Sim. A Serper é popular na comunidade n8n para chamadas simples de busca. O Thunderbit é mais forte quando seu agente precisa de JSON Schemas personalizados ou Markdown para RAG. A SerpApi funciona bem para agentes que precisam de dados estáveis de verticais do Google (Maps, Scholar, Shopping).
4. Qual SERP API tem o melhor plano gratuito para testes?
A Serper oferece 2.500 consultas grátis no cadastro — a mais generosa em volume puro. A SerpApi dá 250/mês, a Scrapingdog oferece 1.000 créditos, a ScraperAPI fornece 5.000 créditos de teste (7 dias) e o Thunderbit inclui créditos grátis para prototipagem. A Apify tem créditos mensais da plataforma equivalentes a cerca de US$ 5.
5. Quais recursos de SERP devo verificar se um provedor interpreta antes de comprar?
Não assuma que "JSON estruturado" significa cobertura completa. Verifique se a API retorna campos estruturados para: People Also Ask, Knowledge Panel, Local Pack/Maps, resultados de Shopping, Featured Snippets, anúncios (topo e base), pacote de imagens e resultados em vídeo. Use a matriz de parsing deste artigo como checklist inicial e teste com consultas reais antes de contratar um plano.
Saiba mais