
Let’s be honest: the web is a wild, wild place. Every day, I feel like I’m standing in front of a digital firehose—news, reviews, product listings, tweets, real estate deals, you name it—all pouring out in a messy, unstructured stream. And if you’re running a business, trying to make sense of this chaos can feel like searching for a needle in a haystack… while the haystack is on fire. (Been there. Not fun.)
But here’s the thing: buried in all that online clutter is pure gold—insights that can drive sales, outsmart competitors, and automate the boring stuff nobody wants to do. That’s where web scraping comes in. With the right tools, you can turn that mountain of unstructured web data into neat, actionable spreadsheets, ready for your next big move. And as someone who’s spent years in SaaS and automation, I can tell you: web scraping isn’t just for coders anymore. It’s for anyone who wants to work smarter, not harder.
Web Scraping Meaning: Turning Online Chaos into Usable Data
So, what exactly is web scraping? Let’s skip the jargon and keep it real: web scraping is the process of using software to extract specific information from websites and convert it into structured formats—think Excel, Google Sheets, or a database. Imagine having a digital assistant who tirelessly copies the exact info you need from thousands of web pages and organizes it for you. That’s web scraping in a nutshell.
Now, you might hear “data scraping” thrown around, too. Here’s the difference: data scraping is a broad term for pulling data from any source (websites, PDFs, images, you name it). Web scraping is specifically about extracting data from websites on the internet. In other words, all web scraping is data scraping, but not all data scraping is web scraping. (Kind of like how all squares are rectangles, but not all rectangles are squares.)
If you want a more formal definition, web scraping is “data scraping used for extracting data from websites” (Wikipedia). But in practice, it’s just automation for online research—no more copy-pasting until your fingers fall off.
Why Web Scraping Matters for Modern Businesses
What Is Data Scraping and How to Do It in 2025 Get Started Free
Let’s talk business. Why does web scraping matter so much right now? Because the internet is drowning in unstructured data—about 80%–90% of all new data is unstructured, from social posts to product listings. IDC predicts the global data volume will hit 175 zettabytes by 2025—that’s a lot of zeroes.
Here’s the kicker: 60–80% of employees’ time is wasted just finding and prepping data, not analyzing it. That’s like hiring a chef to peel potatoes all day instead of cooking. As Michael Shulman, Head of Machine Learning at Kensho, put it: “Since most of the world’s data is unstructured, an ability to analyze and act on it presents a big opportunity.”
Web scraping flips the script. Instead of slogging through websites by hand, you automate the process—gathering live data, in real time, from anywhere on the web. No wonder 71% of financial services companies and over half of retail/e-commerce firms already use web scraping for external data. Data isn’t just the new oil—it’s the new currency, and web scraping is how you cash in.
Common Web Scraping Use Cases Across Industries
Web scraping isn’t a one-trick pony. It’s used everywhere—from sales teams to real estate analysts. Here are some real-world examples:
- Sales Leads & B2B Prospecting: Scrape job boards or business directories to build fresh, targeted lead lists. One SaaS company saw a 40% jump in qualified leads by automating this process.
- E-Commerce Pricing & Product Monitoring: Retailers scrape competitor sites for prices and stock, adjusting their own pricing in near real time. The result? More sales and loyal customers.
- Real Estate Listings: Aggregators and investors scrape property sites for listings, prices, and trends—helping them spot undervalued properties and hot neighborhoods (case study).
- Travel & Hospitality: Scrape airline and hotel sites for fares, availability, and reviews—fueling price comparison tools and sentiment analysis.
- Finance & Investment: Hedge funds scrape everything from SEC filings to product reviews, hunting for alternative data signals. 71% of financial firms now use web scraping in their operations.
The bottom line: if there’s valuable data on the web, there’s a way to scrape it and turn it into business value.
How Web Scraping Works: From Website to Spreadsheet
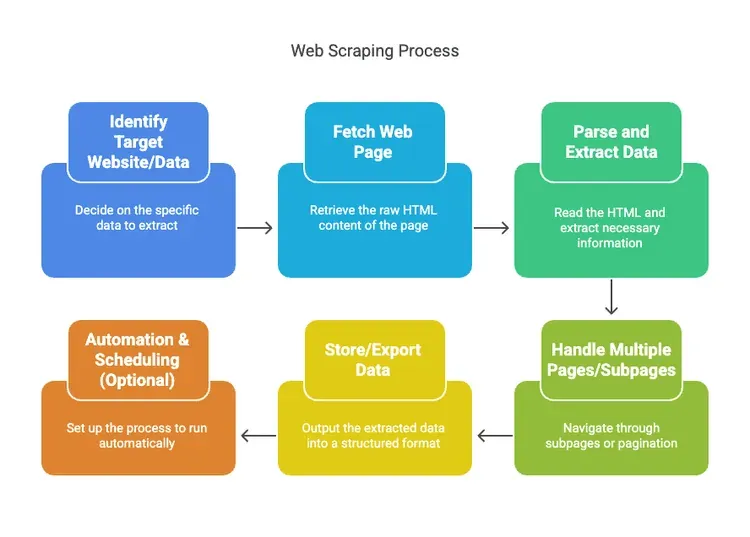
Let’s demystify the process. Web scraping isn’t magic—it’s a pipeline. Here’s how it usually goes:
- Identify the Target Website/Data: Decide what you want (e.g., product names and prices from xyz).
- Fetch the Web Page: The scraper retrieves the raw HTML, just like your browser does.
- Parse and Extract Data: The tool reads the HTML and pulls out the info you need (like prices, names, reviews).
- Handle Multiple Pages/Subpages: Scrapers can follow links to subpages or click through pagination automatically.
- Store/Export the Data: Output everything into a structured format—CSV, Excel, Google Sheets, or a database.
- Automation & Scheduling (Optional): Set it up to run on a schedule, so your data stays fresh without lifting a finger.
Doing this by hand would take ages (and a lot of coffee). With web scraping, you automate the whole process—turning hours of grunt work into minutes.
The Role of Scraping Tools and Web Scraping Services
Now, let’s talk tools. There’s a buffet of options out there, from browser extensions to cloud-based platforms and desktop software. Here’s a quick rundown:
- Browser Extensions: Lightweight, point-and-click tools that live in your browser. Great for quick, simple jobs.
- Desktop Software: Full-featured apps with visual interfaces—handle logins, infinite scroll, and more.
- Cloud-Based Platforms: Run scrapers on remote servers—ideal for large-scale, always-on jobs.
- Custom Code: For the techies—write your own scripts for maximum control (but also maximum headaches).
Why use these tools instead of copy-paste? Three reasons: speed, scale, and reliability. A good scraper can process thousands of pages in the time it takes you to microwave lunch. Plus, you get clean, structured data—no typos, no missed details.
Structured vs. Unstructured Data: Why Web Scraping Is Essential
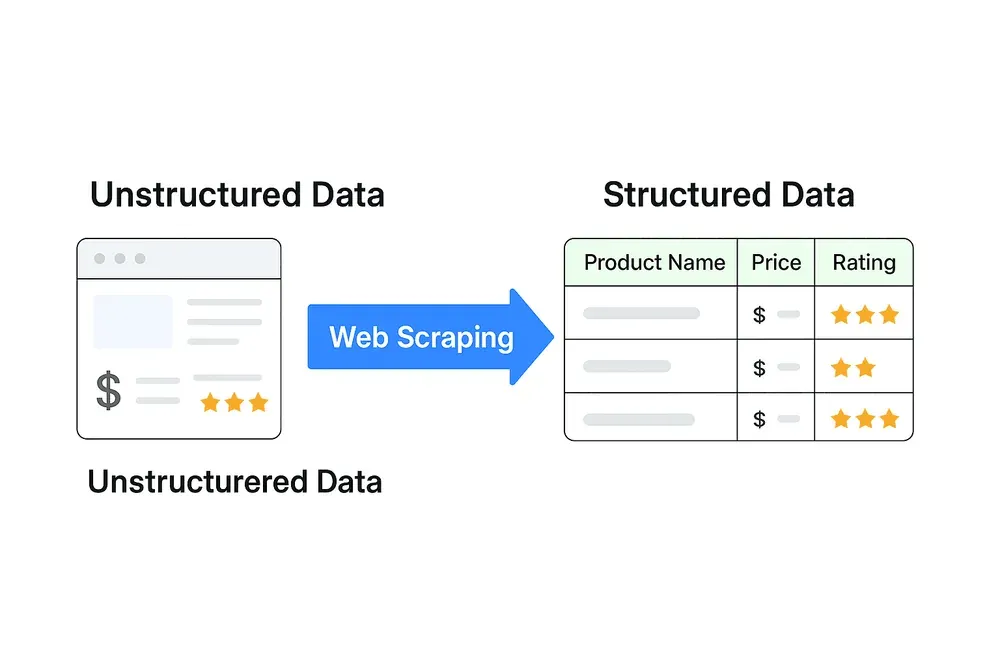
Here’s the heart of the matter: most web data is unstructured. It’s designed for humans, not machines. Think of a product page with images, reviews, and prices all jumbled together. You can’t just plug that into Excel and start analyzing.
Structured data—like a spreadsheet with columns for “Product Name,” “Price,” and “Rating”—is what powers analytics, dashboards, and decision-making. Web scraping is the bridge that turns messy web content into clean, actionable information.
And here’s a wild stat: only about 50% of an organization’s unstructured data is even analyzed. The rest? Wasted potential. Web scraping helps you unlock that value.
Types of Web Scraping Solutions: Code, No-Code, and AI-Powered Tools
Let’s break down your options:
- Code-Based Solutions: Write scripts in Python (using libraries like BeautifulSoup or Scrapy), JavaScript, or R. Maximum flexibility, but you’ll need some coding chops—and patience for when websites change and your script breaks.
- No-Code Solutions: Visual tools (browser extensions, desktop apps, cloud platforms) that let you set up scrapes with clicks, not code. Perfect for business users who just want results.
- AI-Powered Scrapers: The new kids on the block. These tools use AI to automatically detect what to scrape, adapt to website changes, and even extract data from PDFs or images. Thunderbit is a prime example here.
As someone who’s seen both sides—writing code and using no-code tools—I can say: for most business users, no-code or AI-powered scrapers are the way to go. Why wrestle with code when you can get the same results in two clicks?
Key Features to Look for in a Scraping Tool
Scrape data from any website using AI Get Started Free
Not all scrapers are created equal. Here’s what I look for (and what I recommend to every business team):
- Ease of Use: Can you get started without reading a novel-length manual?
- AI Field Detection: Does it suggest what to scrape automatically?
- Subpage & Pagination Support: Can it handle multi-page lists and drill into detail pages?
- Export Options: Can you send data straight to Excel, Google Sheets, Airtable, or Notion?
- Scheduling: Can you set it and forget it—automatically scraping on your schedule?
- Data Type Recognition: Does it recognize emails, phone numbers, images, and more?
- Templates for Popular Sites: 1-click scraping for Amazon, Zillow, Instagram, etc.
For sales, ecommerce, and operations teams, these features mean less manual work, fewer errors, and a lot more time spent on what actually matters.
Thunderbit: The Simplest AI Web Scraper for Everyone
Okay, shameless plug time—but only because I genuinely believe in what we’re building at Thunderbit.
Thunderbit is an AI-powered web scraper Chrome Extension designed for business users, not just developers. Here’s what makes it different:
- AI Suggest Fields: Just click “AI Suggest Fields” and Thunderbit reads the page, recommends the best columns, and sets everything up for you. No more guessing or fiddling with selectors.
- 2-Click Scraping: Open the page, let AI suggest fields, click “Scrape.” Done. It’s that simple.
- Subpage & Pagination: Thunderbit’s AI automatically detects and scrapes subpages and paginated lists—no extra setup.
- Scheduled Scraper: Want to monitor prices or leads daily? Just describe the schedule (“every morning at 9am”), add URLs, and Thunderbit takes care of the rest.
- Instant Export: Send your data straight to Excel, Google Sheets, Airtable, or Notion—no hidden fees, no hoops to jump through.
- Specialized Extractors: 1-click extraction for emails, phone numbers, and images—completely free.
- AI Autofill: Use AI to fill out online forms and automate workflows, not just scrape data.
- Document & Image Parsing: Upload PDFs, Word, Excel files, or images—Thunderbit’s AI will extract tables and structure the data for you.
And yes, there’s a free tier (scrape up to 6 pages), so you can try it out with zero risk. If you need more, paid plans start at $15/month for 500 rows—way more affordable than most enterprise tools.
Don’t just take my word for it. Users have told us things like, “Thunderbit is hands-down the easiest web scraper I’ve ever used. I went from spending hours writing scripts to scraping entire websites in minutes—with just a few clicks.” That’s the kind of feedback that makes all the late-night coding sessions worth it.
Want to see Thunderbit in action? Check out our YouTube Channel or read more on the Thunderbit Blog.
Try Thunderbit Chrome Extension for Free
Web Scraping Best Practices for Non-Technical Teams
Web scraping is powerful, but a little caution goes a long way. Here are my top tips for getting started:
- Respect Website Policies: Always check the site’s terms of service and robots.txt. Stick to public data and use it responsibly.
- Don’t Overload Servers: Be polite—don’t hammer a site with requests. Most tools let you set crawl rates or delays.
- Start Small: Test your scraper on a few pages first. Make sure you’re getting the data you want before scaling up.
- Handle Pagination: Don’t forget to scrape all pages, not just the first one.
- Validate Your Data: Clean and check your results—remove duplicates, fix formatting, and make sure nothing’s missing.
- Stay Organized: Document what you scraped, when, and from where. It’ll save you headaches later.
- Check for APIs: Sometimes, there’s an official API that gives you data more easily and reliably than scraping HTML.
- Monitor for Changes: Websites change. If your scraper stops working, it might be time to update your setup (or let AI handle it).
- Use the Right Tool: If one tool isn’t working, try another. Don’t be afraid to experiment.
- Stay Ethical: Just because you can scrape something doesn’t always mean you should. Respect privacy and data ownership.
For a deeper dive, check out our guide: What Is Data Scraping and How to Do It in 2025.
Conclusion: Unlocking Business Value with Web Scraping

Let’s wrap it up. The web is overflowing with valuable data, but most of it’s locked away in unstructured formats. Web scraping is the key that unlocks that data—turning chaos into clarity, and grunt work into growth.
Whether you’re in sales, ecommerce, real estate, or operations, web scraping can help you:
- Generate fresher, higher-quality leads
- Monitor competitors and markets in real time
- Automate tedious workflows and save hours every week
- Make smarter, faster, data-driven decisions
And thanks to modern tools—especially AI-powered solutions like Thunderbit—you don’t need to be a coder or data scientist to get started. Just pick a project, try out a tool (our Chrome Extension is a great place to start), and see how much more you can accomplish when you let automation do the heavy lifting.
In a world where “data is the new oil,” web scraping is your pump. So go ahead—turn that firehose of online data into a steady stream of insights, and watch your business thrive.
Happy scraping! And if you ever get stuck, you know where to find me (or at least, where to find Thunderbit).
Start Scraping with Thunderbit AI
Frequently Asked Questions
1. What is web scraping, in plain English?
Web scraping is using software to automatically pull specific data from websites—like prices, reviews, or job listings—and turn it into something useful, like a spreadsheet. Think of it as hiring a robot intern to do all the boring copy-paste work for you, 24/7.
2. Do I need to know how to code to use it?
Not anymore. Thanks to no-code and AI-powered tools like Thunderbit, you can scrape websites with a couple of clicks—no Python, no debugging, no problem. If you can browse the web, you can scrape the web.
3. What kind of data can I scrape?
Just about anything that's public online:
- Product listings and prices
- Real estate properties
- Job postings
- Business directories
- Social media bios
- PDF tables and images (yes, even those)
If it’s online and visible, there’s a way to scrape it.
4. Is web scraping legal?
Generally yes—as long as you're scraping public data responsibly. Don’t overload servers, respect terms of service, and avoid scraping login-protected or personal info. When in doubt, be ethical and keep it clean.
Read More
- 3 Ways Web Scraping Fuels Business Growth
- Case Study: How a Retailer Used Scraping to Boost Sales
- Why External Data Is the Future of Competitive Strategy
Try AI Web Scraper Get Started Free




