News Scraper














Dane newsowe — szybciej zebrane
Pobieraj uporządkowane dane z artykułów, listingów i źródeł bez ręcznej żmudnej pracy.
Pobierz pełne szczegóły artykułu
Strony listingowe newsów pokazują tylko zajawkę. Thunderbit odwiedza pełną stronę każdego artykułu i wyciąga wszystko, co ważne — nagłówek, streszczenie, autora, datę publikacji, źródło wiadomości i sekcję. Przejdź od zwykłej listy linków do kompletnego, uporządkowanego zestawu danych bez mozolnej ręcznej pracy.
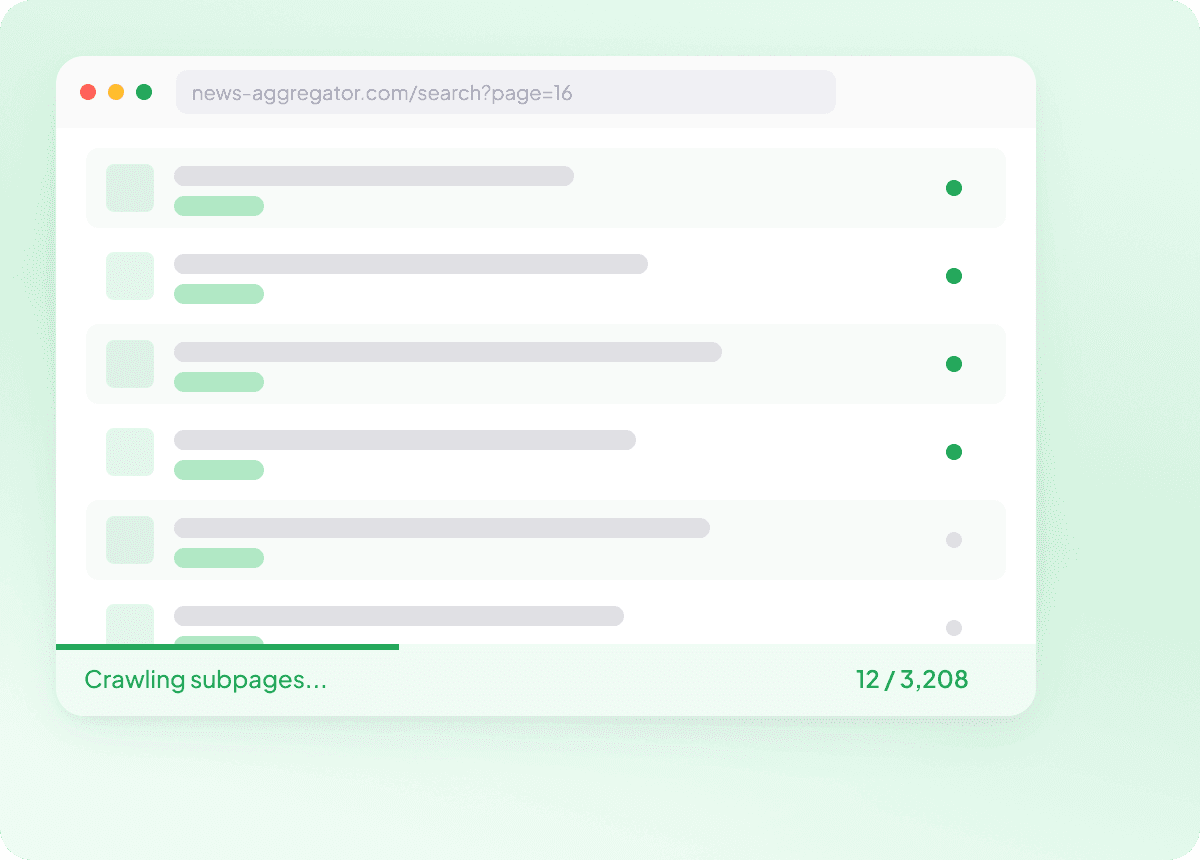
Masowo scrapuj listy URL-i News
Scrapowanie jednego artykułu naraz to nie workflow — to uciążliwa czynność. Wklej listę adresów URL artykułów, a Thunderbit masowo pobierze setki stron w jednym uruchomieniu, zbierając wszystkie potrzebne pola z każdej publikacji. Gromadzenie dużych zbiorów danych newsowych nigdy nie było tak proste.

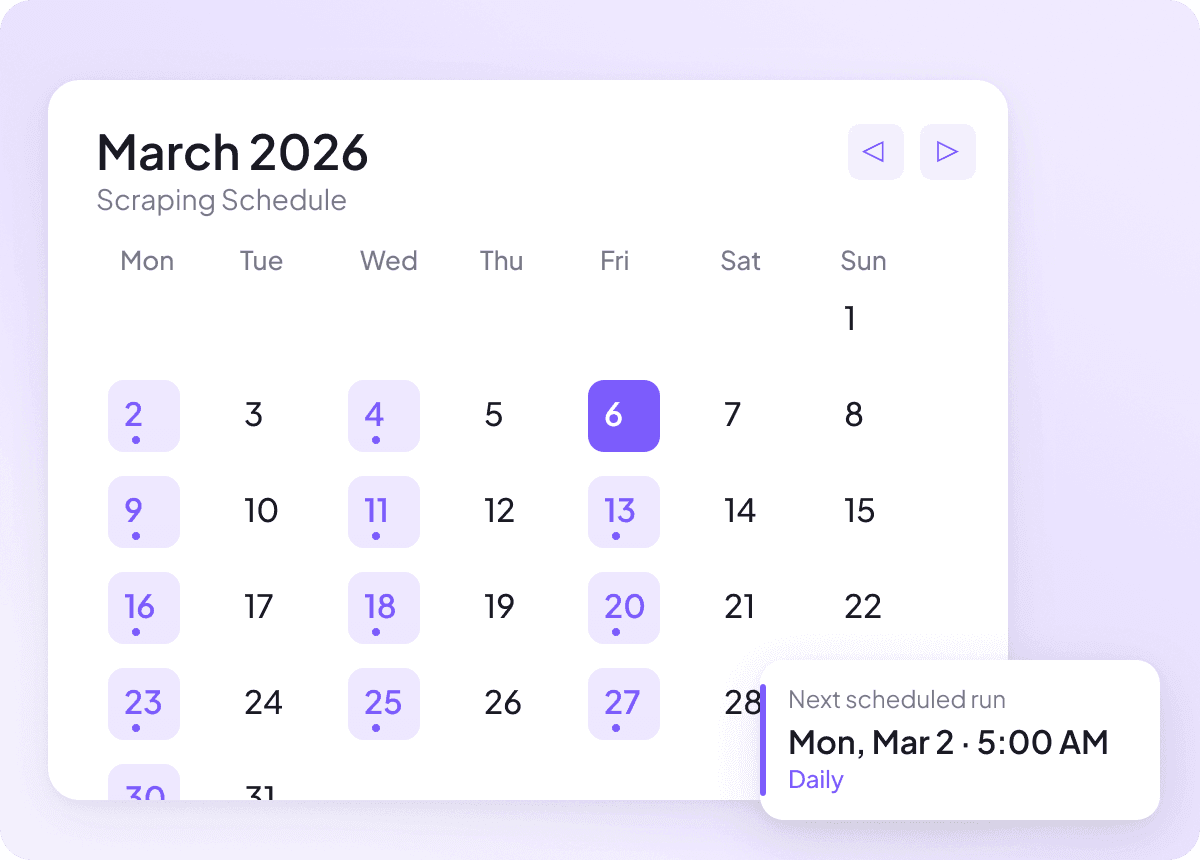
Utrzymuj dane News zawsze aktualne
News zmienia się błyskawicznie, a wczorajsze dane szybko tracą wartość. Zaplanuj scrapowanie, a Thunderbit będzie działać automatycznie — uzupełniając arkusz świeżymi nagłówkami, streszczeniami, autorami, datami publikacji, źródłami i sekcjami w wybranym przez Ciebie rytmie. Regularne aktualizacje, zero ręcznej pracy.
Dlaczego Thunderbit różni się od tradycyjnych scraperów newsowych?
Szybszy sposób na zbieranie chaotycznych danych newsowych bez ciągłych awarii.
Tradycyjne scrapery
Stary sposób działaniaThunderbit AI
Mądrzejsze podejścieNie musisz wierzyć nam na słowo
Zobacz, co użytkownicy mówią o Thunderbit.








Najczęściej zadawane pytania
Powiązane zastosowania
Poznaj więcej zastosowań web scrapera Thunderbit.
PeopleWhiz scraper
Thunderbit PeopleWhiz Scraper umożliwia wyodrębnianie danych z wyników wyszukiwania i profili PeopleWhiz dzięki sugestiom pól wspieranym przez AI. Zbieraj imiona i nazwiska, dane kontaktowe, lokalizacje i nie tylko — do badań, marketingu lub pozyskiwania leadów. Szybko i sprawnie zamieniaj dane z PeopleWhiz w uporządkowane zbiory danych.
Dowiedz się więcej ->
Coupang scraper
Wyodrębnij nazwy produktów, ceny i poziomy rabatów z Coupang w 2 kliknięcia — a następnie błyskawicznie eksportuj dane do Excel, Google Sheets lub Notion. Bez kodowania.
Dowiedz się więcej ->Substack scraper
Wyciągaj liczbę subskrybentów Substack, tytuły artykułów i opisy publikacji w 2 kliknięcia — a potem eksportuj dane do Excela, Google Sheets lub Notion. Bez kodowania; AI Thunderbit zajmuje się strukturyzacją za Ciebie.
Dowiedz się więcej ->
Scraper Priceline
Wyodrębniaj nazwy hoteli, ceny, oceny i udogodnienia z Priceline w 2 kliknięciach dzięki AI Thunderbit — a następnie błyskawicznie eksportuj czyste, uporządkowane dane do Excela, Google Sheets lub Notion.
Dowiedz się więcej ->Elgiganten Scraper
Wyciągaj nazwy produktów, ceny i dostępność z Elgiganten w 2 kliknięcia — a potem eksportuj dane bezpośrednio do Excel, Google Sheets lub Notion. AI w Thunderbit wykonuje całą ciężką pracę, dzięki czemu Ty możesz skupić się na analizie.
Dowiedz się więcej ->
HKTVmall Scraper
Wyodrębniaj nazwy produktów, ceny, oceny i więcej z ofert HKTVmall w 2 kliknięcia — bez kodowania. Eksportuj dane bezpośrednio do Excela, Google Sheets lub Notion i zamieniaj je w praktyczne wnioski.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Darmowy okres próbny daje nielimitowane kredyty dla 8 stron.



