IDCrawl Scraper
Zaufali nam specjaliści z czołowych firm














Dane z Idcrawl, które pozostają użyteczne
Wykorzystaj IDCrawl do szybszego, czystszego i masowego pozyskiwania danych z Thunderbit.
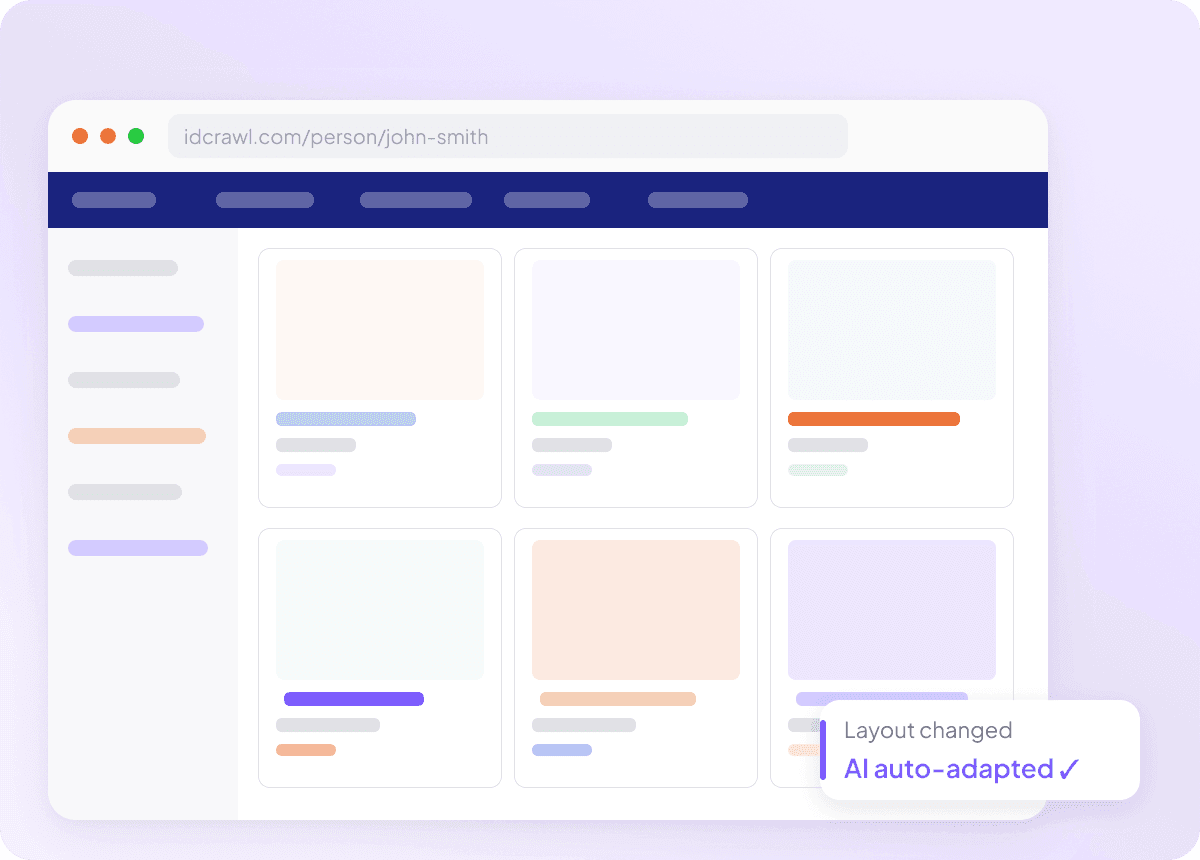
Dostosowuje się, gdy Idcrawl się zmienia
Scrapery, które psują się po każdej aktualizacji strony, są bezużyteczne — zwłaszcza gdy chcesz pobierać z IDCrawl pełne imię i nazwisko, stanowisko, nazwę firmy, adres e-mail, numer telefonu i profil LinkedIn. Thunderbit odczytuje stronę po znaczeniu, a nie po stałych selektorach, dzięki czemu potrafi dostosować się do zmian układu. Poświęcasz mniej czasu na naprawianie scraperów, a więcej na zdobywanie potrzebnych danych.
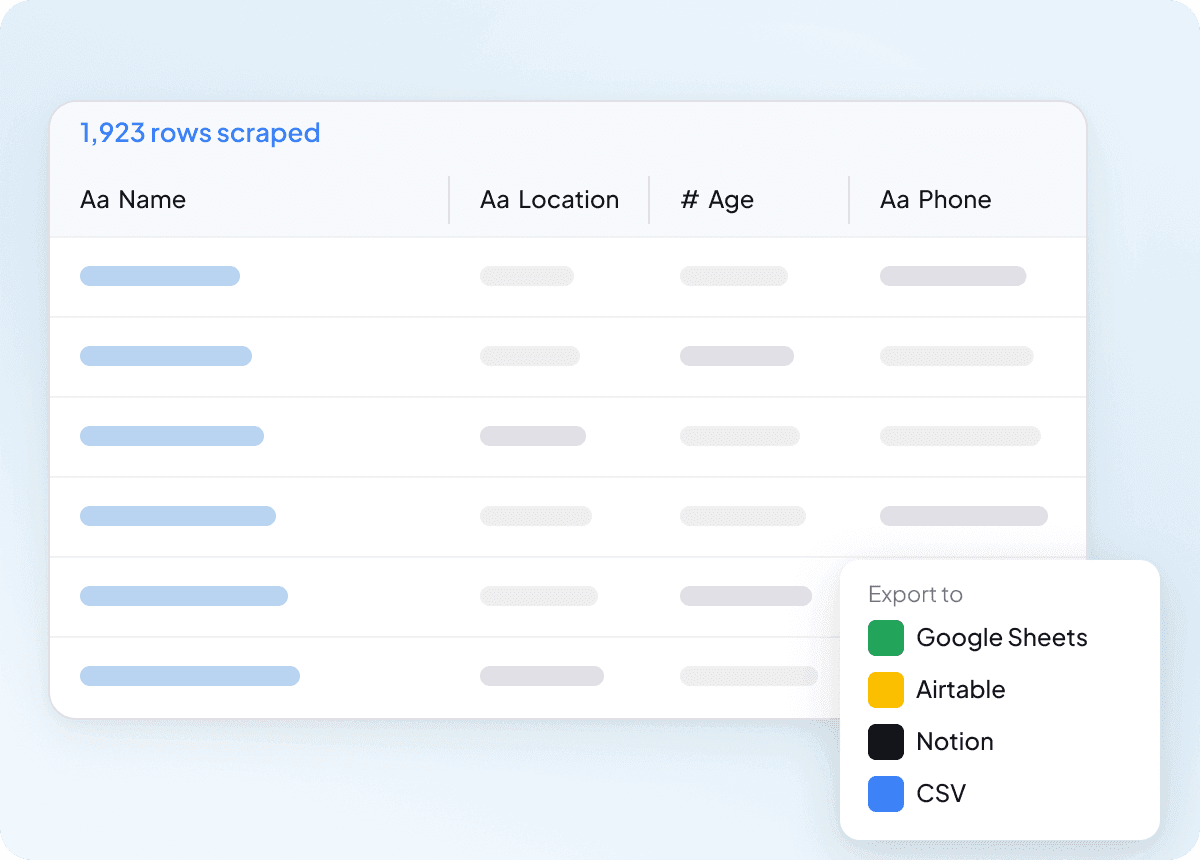
Czyste dane od samego początku
Surowe dane to dopiero początek prawdziwej pracy, a wyniki z IDCrawl często wymagają porządkowania, zanim staną się przydatne. Thunderbit strukturyzuje i formatuje dane podczas ekstrakcji, więc to, co eksportujesz, jest już czyste i gotowe do użycia. Oznacza to mniej sortowania, mniej poprawek i płynniejsze przekazanie danych Twojemu zespołowi.
Masowe scrapowanie Idcrawl za jednym razem
Scrapowanie jednej strony IDCrawl naraz nie skaluje się dobrze, gdy potrzebujesz długiej listy kontaktów. Thunderbit może masowo scrapować setki stron za jednym razem, więc możesz podać mu listę adresów URL i wyciągnąć z nich pełne imię i nazwisko, stanowisko, nazwę firmy, adres e-mail, numer telefonu i profil LinkedIn. To znacznie prostszy sposób na przekształcenie dużej listy w użyteczne dane.

Czym Thunderbit różni się od tradycyjnych scraperów Idcrawl?
Prostszy sposób na pozyskiwanie danych z IDCrawl bez ciągłych poprawek.
Tradycyjne scrapery
Stare podejścieThunderbit AI
Bardziej inteligentne podejścieNie musisz wierzyć nam na słowo
Zobacz, co użytkownicy mówią o Thunderbit.





Często zadawane pytania
Powiązane zastosowania
Poznaj więcej zastosowań web scrapera Thunderbit.
Video Scraper
Video Scraper od Thunderbit pozwala w kilka kliknięć wyciągać z TikToka dane o filmach i twórcach z pomocą AI. Zbieraj listy filmów, metryki wyników i szczegóły profili, a następnie eksportuj do Excel, Google Sheets, Airtable lub Notion, aby prowadzić monitoring i research influencerów.
Dowiedz się więcej ->PeopleWhiz scraper
Thunderbit PeopleWhiz Scraper umożliwia wyodrębnianie danych z wyników wyszukiwania i profili PeopleWhiz dzięki sugestiom pól wspieranym przez AI. Zbieraj imiona i nazwiska, dane kontaktowe, lokalizacje i nie tylko — do badań, marketingu lub pozyskiwania leadów. Szybko i sprawnie zamieniaj dane z PeopleWhiz w uporządkowane zbiory danych.
Dowiedz się więcej ->Elgiganten Scraper
Zbierz nazwy produktów, ceny i informacje o dostępności z Elgiganten w zaledwie dwóch kliknięciach — całą ciężką pracę wykona za Ciebie AI Thunderbit.
Dowiedz się więcej ->Amazon price scraper
Przenieś ceny, oceny i ASIN-y z Amazon do Google Sheets dzięki scrapowaniu metodą wskaż i kliknij — bez skomplikowanej konfiguracji.
Dowiedz się więcej ->
Coupang scraper
Pobieraj nazwy produktów, ceny i stawki rabatów z Coupang w dwóch kliknięciach — bez kodowania.
Dowiedz się więcej ->
HKTVmall Scraper
Zbieraj nazwy produktów, ceny, a nawet oceny klientów z ofert HKTVmall kilkoma kliknięciami — bez żadnej skomplikowanej konfiguracji.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Dołącz do ponad 100 000 specjalistów, którzy już używają Thunderbit do automatyzacji web scrapingu.
Bezpłatny okres próbny daje nielimitowane kredyty na 8 stron.