Flickr 爬虫
Zaufali nam specjaliści z czołowych firm














Wyodrębniaj dane z Flickr w dwa kliknięcia
Thunderbit upraszcza pobieranie danych z Flickr — bez kodowania.
Dwa kliknięcia do danych z Flickr
Ręczne kopiowanie tytułów zdjęć, nazw użytkowników autorów czy dat przesłania z Flickr jest żmudne. Thunderbit pozwala pominąć kopiowanie i wklejanie. Wystarczy wskazać interesujące Cię dane — na przykład opis zdjęcia lub typ licencji — a nasza AI zajmie się resztą. Dwa kliknięcia i wyodrębniasz dane bez napisania choćby jednej linijki kodu.
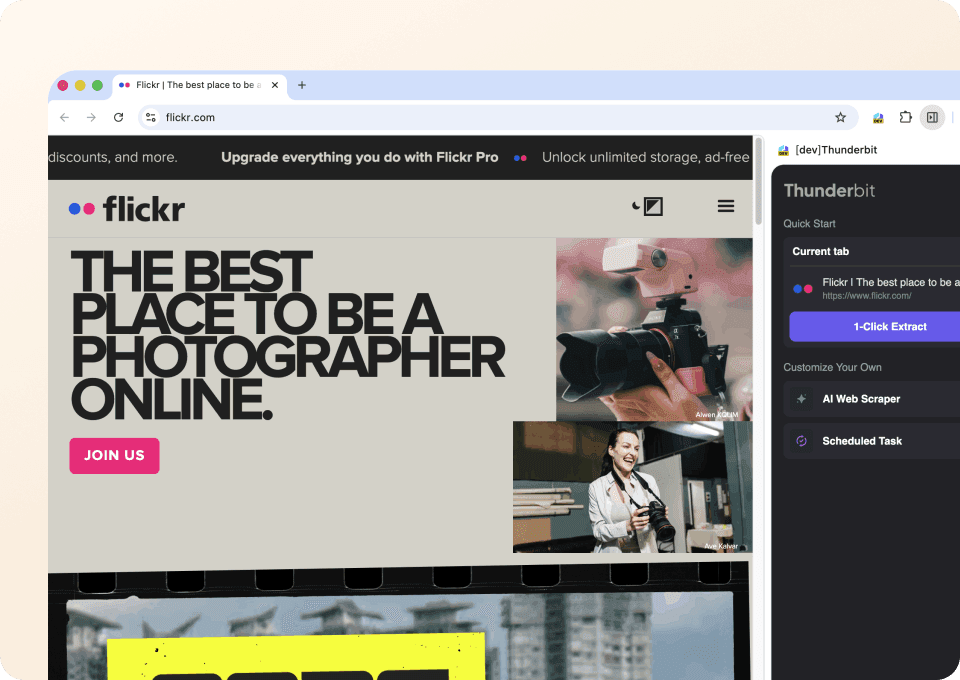
Pobierz pełne szczegóły zdjęć z Flickr
Strony wyszukiwania lub galerie Flickr pokazują tylko podstawowe informacje. Aby zobaczyć pełny obraz, potrzebujesz danych z indywidualnej strony każdego zdjęcia. Thunderbit może automatycznie odwiedzać każdą powiązaną podstronę, pobierać opis, tagi i inne szczegóły, a następnie dopisywać je jako nowe kolumny w eksporcie danych. Koniec z ręcznym klikaniem i kopiowaniem z każdej strony.
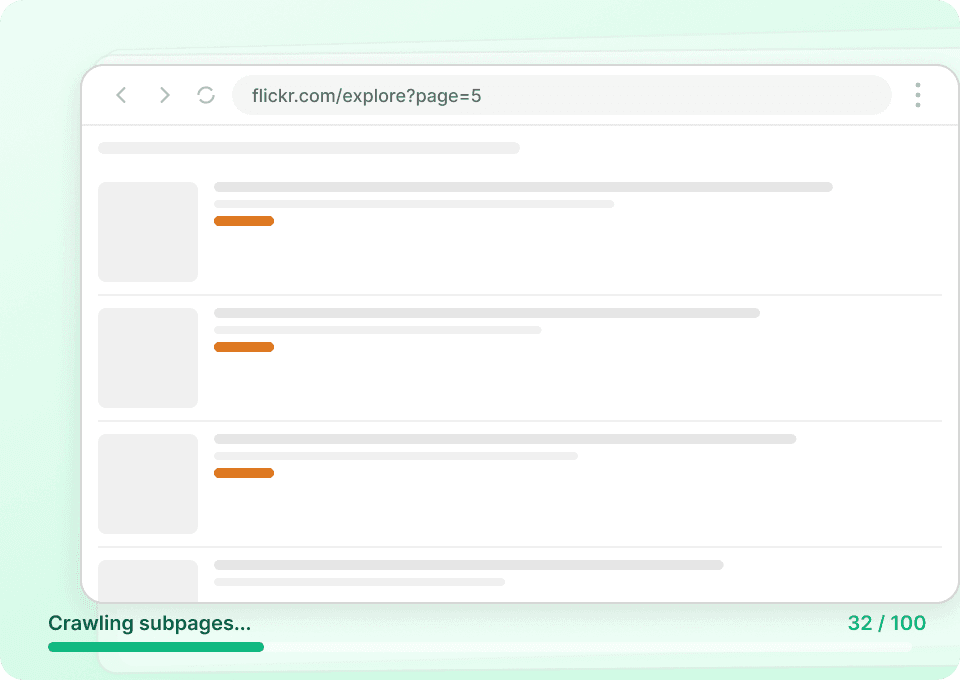
Hurtowe pobieranie danych z Flickr
Scrapowanie Flickr zdjęcie po zdjęciu jest wolne i niepraktyczne. Zamiast ręcznie przechodzić przez kolejne strony i wyodrębniać dane z pojedynczych wpisów, Thunderbit pozwala wprowadzić wiele adresów URL z Flickr. Następnie odwiedza każdą stronę, pobiera tytuł zdjęcia, nazwę użytkownika autora i inne dane, po czym scala wszystko w jeden gotowy zestaw.

Dlaczego Thunderbit różni się od tradycyjnych flickr scrapers?
Wyodrębniaj dane z Flickr bez problemów typowych dla tradycyjnego scrapowania.
Tradycyjne scrapery
Stare podejścieThunderbit AI
Bardziej inteligentne podejścieNie musisz wierzyć nam na słowo
Zobacz, co użytkownicy mówią o Thunderbit.






Najczęściej zadawane pytania
Powiązane zastosowania
Poznaj więcej zastosowań web scrapera Thunderbit.
PeopleWhiz scraper
Thunderbit PeopleWhiz Scraper umożliwia wyodrębnianie danych z wyników wyszukiwania i profili PeopleWhiz dzięki sugestiom pól wspieranym przez AI. Zbieraj imiona i nazwiska, dane kontaktowe, lokalizacje i nie tylko — do badań, marketingu lub pozyskiwania leadów. Szybko i sprawnie zamieniaj dane z PeopleWhiz w uporządkowane zbiory danych.
Dowiedz się więcej ->
Scraper numerów telefonów z Craigslist
Scraper numerów telefonów z Craigslist od Thunderbit pomaga z pomocą AI wyciągać numery telefonów i szczegóły ogłoszeń z wyników wyszukiwania Craigslist. Zbieraj oferty, przechodź do każdego wpisu, aby pozyskać dane kontaktowe i dodatkowe pola, a następnie eksportuj do Excel, Google Sheets, Airtable, Notion, CSV lub JSON.
Dowiedz się więcej ->
United Airlines Scraper
Wystarczy wskazać i kliknąć, aby zebrać dane lotów United Airlines, takie jak numer lotu, czas przylotu i lotnisko wylotu — resztą zajmuje się AI Thunderbit.
Dowiedz się więcej ->
Coupang scraper
Pobieraj nazwy produktów, ceny i stawki rabatów z Coupang w dwóch kliknięciach — bez kodowania.
Dowiedz się więcej ->
Spokeo Scraper
Zrezygnuj z ręcznego kopiowania danych ze Spokeo — użyj Thunderbit, aby pobrać imiona i nazwiska, wiek, adresy i więcej w zaledwie kilka kliknięć.
Dowiedz się więcej ->
Trustpilot scraper
Przekształć strony Trustpilot w przejrzysty arkusz z opiniami, ocenami i nazwami recenzentów. Czytamy każdą stronę za Ciebie, więc nie trzeba kodu ani kopiowania i wklejania.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Bezpłatny okres próbny daje nielimitowane kredyty na 8 stron.