Article Scraper
Zaufali nam specjaliści z czołowych firm














Łatwy dostęp do danych z Article
Wyodrębniaj kluczowe informacje z artykułów bez znajomości programowania.
Automatycznie nadąża za zmianami
Masz dość sytuacji, gdy scraper przestaje działać za każdym razem, gdy strona zmieni układ? Thunderbit rozumie znaczenie strony, a nie tylko stałe pozycje elementów. Niezawodnie pobieraj tytuł, autora i treść artykułu, nawet gdy serwis się zmienia.

Zautomatyzuj zbieranie danych z Article
Dane o artykułach, takie jak data publikacji, słowa kluczowe i kategoria, zmieniają się stale. Ustaw Thunderbit tak, aby pobierał je automatycznie, a świeże informacje trafiały bezpośrednio do Google Sheets, Notion lub Airtable — bez ręcznej pracy.
Pobieraj dane z dowolnej strony
Po co używać innego scrapera do każdej witryny? Thunderbit działa od razu na dowolnej stronie. Dzięki ponad 50 gotowym szablonom pobieranie danych z Article, niezależnie od źródła, staje się banalnie proste.
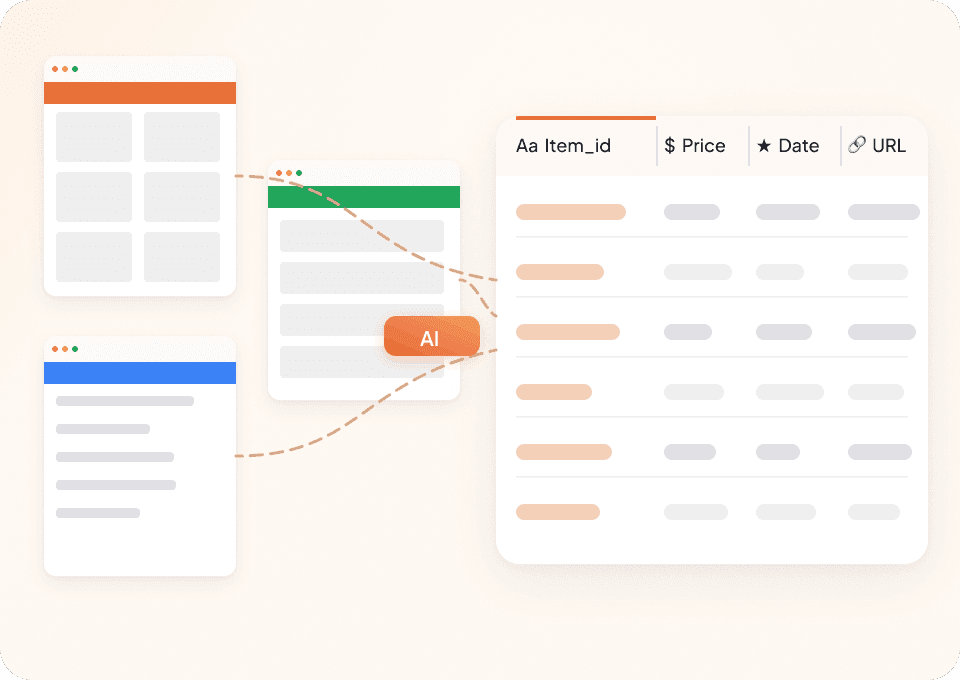
Czym Thunderbit różni się od tradycyjnych scraperów artykułów?
Thunderbit używa AI, aby szybko i niezawodnie wyodrębniać dane z artykułów.
Tradycyjne scrapery
Stare podejście do tego zadaniaThunderbit AI
Sprytniejsze podejścieNie musisz wierzyć nam na słowo
Zobacz, co użytkownicy mówią o Thunderbit.







Najczęściej zadawane pytania
Powiązane zastosowania
Poznaj więcej zastosowań web scrapera Thunderbit.

PubMed Scraper
PubMed Scraper od Thunderbit pozwala z pomocą AI wyciągać uporządkowane dane z wyników wyszukiwania PubMed oraz stron artykułów. Zbieraj popularne publikacje medyczne, dowody z badań klinicznych, streszczenia, autorów, afiliacje, daty publikacji i linki, a następnie eksportuj do Excel, Google Sheets, Airtable lub Notion.
Dowiedz się więcej ->Video Scraper
Video Scraper od Thunderbit pozwala w kilka kliknięć wyciągać z TikToka dane o filmach i twórcach z pomocą AI. Zbieraj listy filmów, metryki wyników i szczegóły profili, a następnie eksportuj do Excel, Google Sheets, Airtable lub Notion, aby prowadzić monitoring i research influencerów.
Dowiedz się więcej ->Elgiganten Scraper
Zbierz nazwy produktów, ceny i informacje o dostępności z Elgiganten w zaledwie dwóch kliknięciach — całą ciężką pracę wykona za Ciebie AI Thunderbit.
Dowiedz się więcej ->
Coupang scraper
Pobieraj nazwy produktów, ceny i stawki rabatów z Coupang w dwóch kliknięciach — bez kodowania.
Dowiedz się więcej ->
United Airlines Scraper
Wystarczy wskazać i kliknąć, aby zebrać dane lotów United Airlines, takie jak numer lotu, czas przylotu i lotnisko wylotu — resztą zajmuje się AI Thunderbit.
Dowiedz się więcej ->
Scraper Priceline
Zbieraj nazwy hoteli, ceny i oceny z Priceline w zaledwie kilka kliknięć dzięki AI od Thunderbit.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Dołącz do ponad 100 000 specjalistów, którzy już używają Thunderbit do automatyzacji web scrapingu.
Bezpłatny okres próbny daje nielimitowane kredyty na 8 stron.