

Sieć jest dziś większa, bardziej chaotyczna i pełna szans niż kiedykolwiek wcześniej — a jeśli pracujesz w sprzedaży lub marketingu w 2026 roku, dobrze wiesz, że prawdziwe „złoto” nie leży tylko na Twojej stronie, ale także w danych, które możesz pozyskać z innych źródeł. Widziałem na własne oczy, jak właściwe dane, zdobyte w odpowiednim momencie, mogą przesądzić o zamknięciu transakcji albo utracie okazji. Ale bądźmy szczerzy: nikt nie chce godzinami kopiować leadów czy cen z dziesiątek serwisów. Dlatego automatyzacja rośnie w siłę, a hasło „Zapier web scraping” stało się gorącym tematem dla zespołów, które chcą pracować mądrzej, a nie ciężej.
Jest jednak pewien haczyk: choć Zapier stał się domyślnym narzędziem do automatyzacji no-code dla milionów użytkowników, jego możliwości web scrapingu nie są tak magiczne, jak wielu mogłoby oczekiwać. Dobra wiadomość? Dzięki rozwojowi narzędzi opartych na AI, takich jak Thunderbit, możesz dziś połączyć to, co najlepsze z obu światów — inteligentne pobieranie danych i płynną automatyzację procesów. W tym przewodniku pokażę dokładnie, jak używać Zapier do web scrapingu w 2026 roku, gdzie leżą jego ograniczenia i jak wzmocnić automatyzacje, integrując Thunderbit. Niezależnie od tego, czy jesteś handlowcem, marketerem, czy po prostu masz dość ręcznego wprowadzania danych — zaczynajmy.
Czym jest Zapier web scraping i dlaczego ma znaczenie w 2026 roku?
Zacznijmy od podstaw. Zapier web scraping oznacza wykorzystanie Zapier — wiodącej na świecie platformy automatyzacji no-code — do automatycznego zbierania i przekazywania danych z internetu do narzędzi biznesowych. Zapier integruje ponad 7 000 aplikacji (takich jak Google Sheets, HubSpot, Slack, Salesforce i wiele innych), pozwalając tworzyć „Zapy”, które uruchamiają się po spełnieniu określonego warunku (np. pojawieniu się nowego wiersza w arkuszu), a następnie wykonują akcje (np. wysyłkę maila lub aktualizację CRM).
Ale jest tu ważne zastrzeżenie: Zapier sam w sobie nie wykonuje scrapingu stron internetowych. Działa raczej jak spoiwo łączące dane pobrane z sieci — zwykle za pomocą narzędzi zewnętrznych lub API — z miejscem, w którym ich potrzebujesz. Na przykład możesz użyć rozszerzenia do Chrome albo scrapera opartego na AI, aby pobrać leady z katalogu, wyeksportować je do Google Sheets, a następnie pozwolić Zapierowi automatycznie dodać je do CRM.
Dlaczego to takie ważne w 2026 roku? Bo zapotrzebowanie na automatyczne pozyskiwanie danych rośnie błyskawicznie. Globalny rynek web scrapingu ma osiągnąć 1,17 mld USD w 2026 roku, a sam segment scrapingu opartego na AI ma dojść do 10,2 mld USD. Zespoły sprzedażowe i marketingowe są pod presją, by robić więcej mniejszym kosztem, a ręczne wprowadzanie danych jest zabójcą produktywności — kosztując firmy nawet 28 500 USD rocznie na pracownika i pochłaniając ponad 9 godzin tygodniowo na powtarzalne zadania.
 Zapier web scraping ma znaczenie, bo pozwala osobom nietechnicznym automatyzować takie przepływy pracy, uwalniając czas na faktyczną sprzedaż i marketing. W praktyce zespoły sprzedaży, które automatyzują ręczne zadania, oszczędzają średnio 6 godzin tygodniowo na osobę, a automatyzacja marketingu zapewnia 544% zwrotu z inwestycji w ciągu trzech lat.
Zapier web scraping ma znaczenie, bo pozwala osobom nietechnicznym automatyzować takie przepływy pracy, uwalniając czas na faktyczną sprzedaż i marketing. W praktyce zespoły sprzedaży, które automatyzują ręczne zadania, oszczędzają średnio 6 godzin tygodniowo na osobę, a automatyzacja marketingu zapewnia 544% zwrotu z inwestycji w ciągu trzech lat.
Jak Zapier web scraping wspiera automatyzację: proces krok po kroku
Pobieraj dane z sieci z AI w 2 kliknięcia Get Started Free
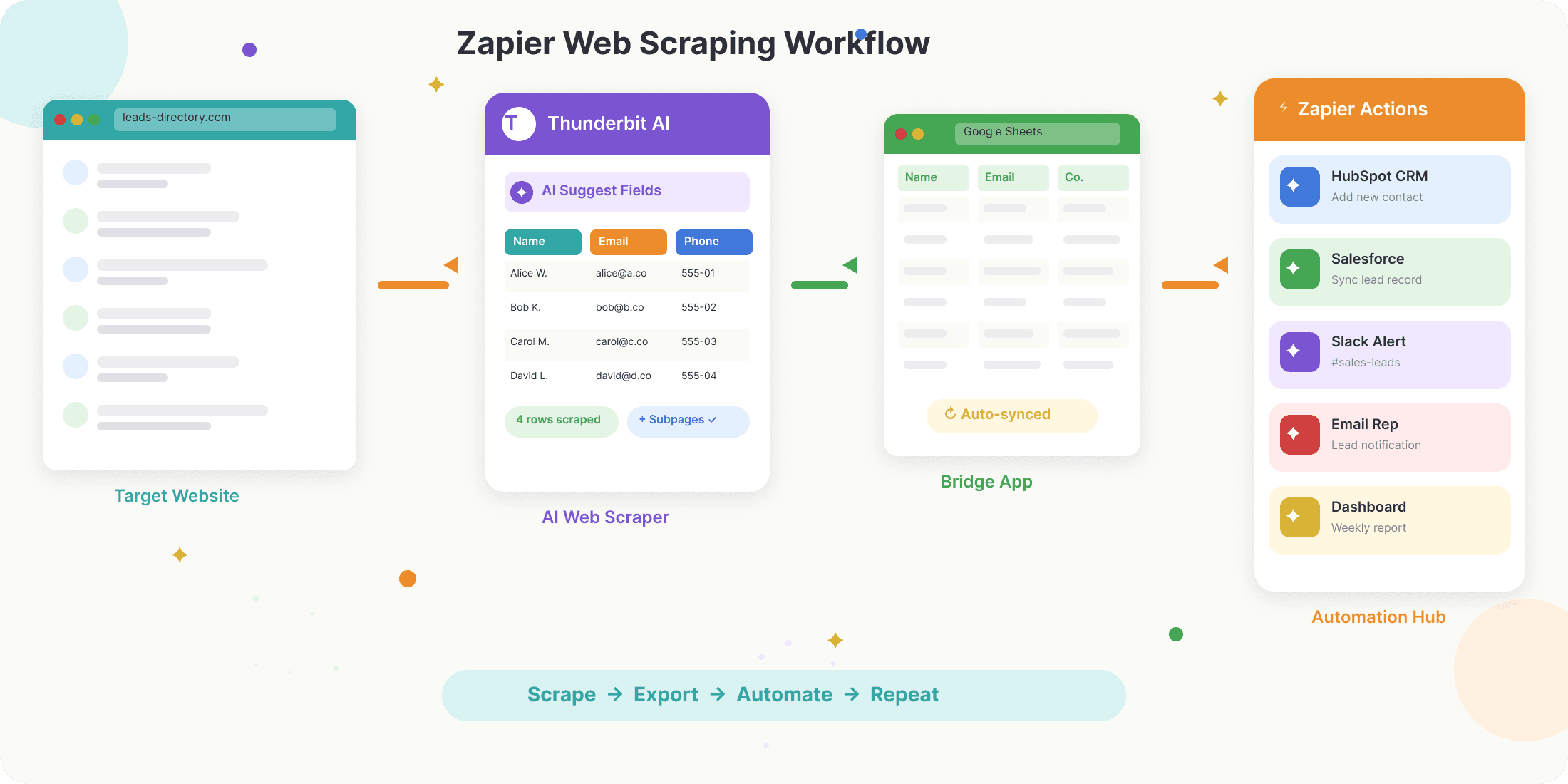
Jak więc wygląda typowy workflow Zapier web scraping w praktyce? Oto ogólny schemat:
- Pobierz dane ze strony: Użyj rozszerzenia do Chrome (np. Thunderbit), API (np. Apify lub Browse AI) albo narzędzia zewnętrznego, aby wyciągnąć dane z docelowej witryny.
- Wyeksportuj dane do aplikacji „pośredniej”: Najczęściej dane trafiają do Google Sheets, Airtable lub Notion — platform, które Zapier może łatwo monitorować pod kątem zmian.
- Skonfiguruj wyzwalacz w Zapier: W Zapier utwórz nowego Zapa, który uruchomi się po dodaniu nowego wiersza do arkusza.
- Zautomatyzuj dalsze działania: Dodaj kolejne kroki, aby wysyłać dane do CRM, e-maila, Slacka lub dowolnej z ponad 7 000 aplikacji.
Poniżej tabela pokazująca typowe scenariusze automatyzacji dla zespołów sprzedaży i marketingu:
| Przypadek użycia | Narzędzie do scrapingu | Aplikacja pośrednia | Wyzwalacz Zapier | Akcja |
|---|---|---|---|---|
| Generowanie leadów | Thunderbit | Google Sheets | Nowy wiersz w arkuszu | Dodanie do HubSpot CRM |
| Monitorowanie cen | Apify | Airtable | Nowy rekord | Wysłanie alertu do Slacka |
| Agregacja treści | Browse AI | Notion | Nowy element bazy danych | Newsletter e-mailowy |
| Śledzenie konkurencji | ScrapingBee | Google Sheets | Nowy wiersz | Aktualizacja Salesforce |
Ten schemat „scrape → eksport → automatyzacja” stanowi fundament nowoczesnych no-code przepływów danych.
Kluczowe ograniczenia Zapier web scraping w 2026 roku
Zanim jednak zbyt mocno się podekscytujesz, porozmawiajmy o najważniejszym: wbudowany web scraping w Zapier ma ograniczenia. Oto, co warto wiedzieć:
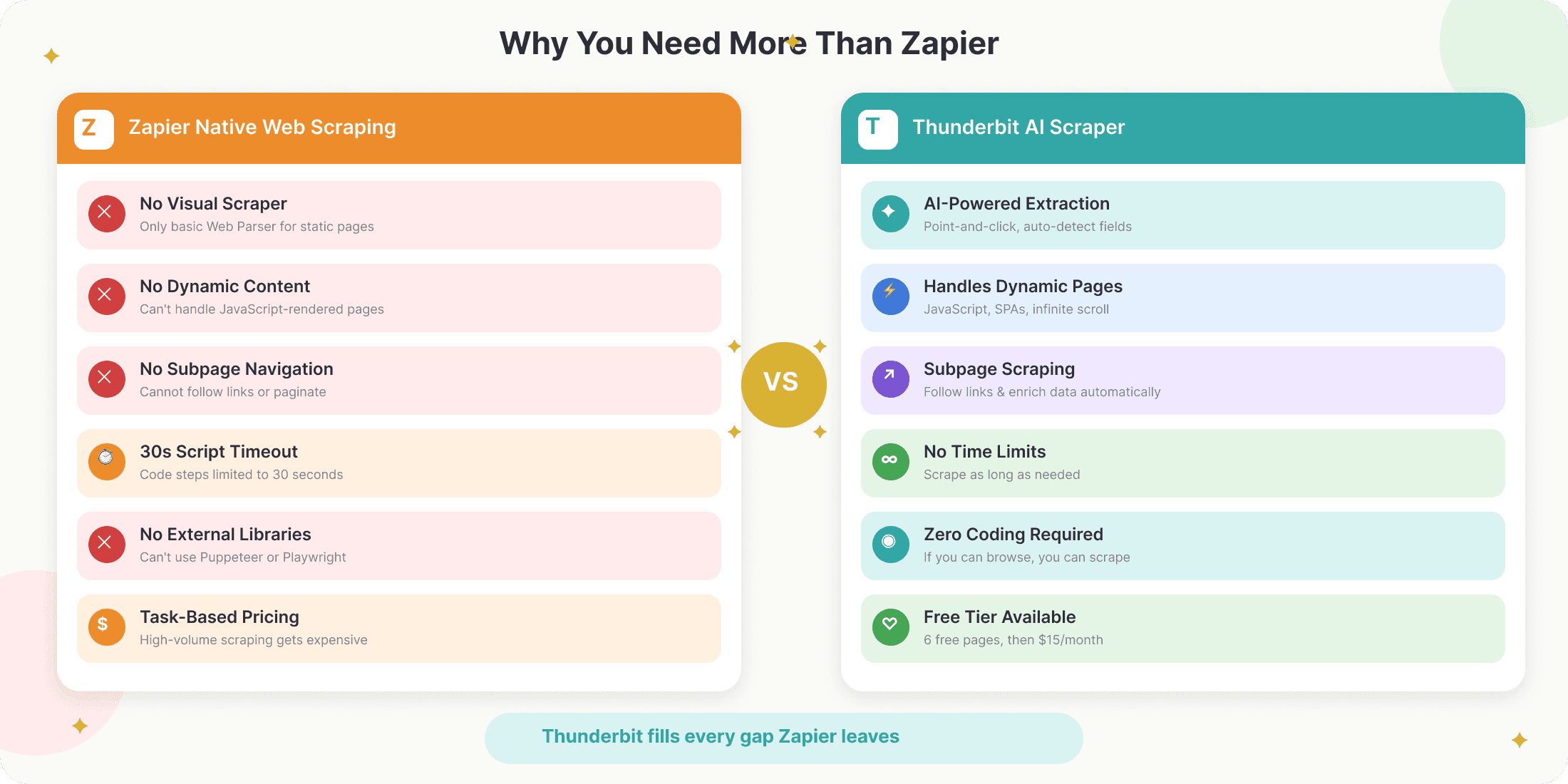
- Brak wizualnego scrapera: Natywny „Web Parser” w Zapier potrafi wyciągnąć tylko główną treść ze statycznych stron internetowych (np. artykułów blogowych). Nie radzi sobie ze strukturalnymi danymi, tabelami ani listingami produktów.
- Nie obsługuje treści dynamicznych: Jeśli strona ładuje dane przez JavaScript (np. infinite scroll, wyskakujące okna czy interaktywne tabele), parser Zapier ich nie zobaczy.
- Ograniczenia kroku kodu: Choć Zapier pozwala uruchamiać Python lub JavaScript, nie można importować zewnętrznych bibliotek, a skrypty są ograniczone do 30 sekund i 512 MB RAM — co wyklucza przeglądarki headless, takie jak Puppeteer czy Playwright.
- Brak obsługi podstron i paginacji: Zapier nie potrafi natywnie przechodzić po linkach do podstron ani obsługiwać scrapingu wielostronicowego.
- Cennik oparty na zadaniach: Każda akcja w Zapie liczy się jako „task”, więc przy dużej skali koszty szybko rosną.
- Liniowy model workflow: Zapy działają sekwencyjnie — rozbudowane rozgałęzienia i logika warunkowa są mocno ograniczone w porównaniu z narzędziami takimi jak Make czy n8n.
Krótko mówiąc: Zapier świetnie sprawdza się w automatyzacji tego, co dzieje się po zdobyciu danych, ale nie jest stworzony do ciężkiej pracy związanej z samym web scrapingiem. Do czegokolwiek wykraczającego poza podstawową ekstrakcję artykułów potrzebujesz dedykowanego scrapera.
Jak wzmocnić Zapier web scraping dzięki Thunderbit: siła integracji
I właśnie tutaj wchodzi Thunderbit. Thunderbit to oparty na AI web scraper w formie rozszerzenia do Chrome, stworzony dla użytkowników biznesowych — bez kodowania, bez szablonów, wystarczą dwa kliknięcia, aby wyciągnąć uporządkowane dane z dowolnej strony.
Oto, jak Thunderbit uzupełnia brakujące elementy:
- Ekstrakcja wspierana przez AI: Kliknij „AI Suggest Fields”, a Thunderbit odczyta stronę, zaproponuje kolumny (np. Nazwa, E-mail, Cena itp.) i wyciągnie dane — bez żadnej konfiguracji.
- Radzi sobie z dynamicznymi i złożonymi stronami: AI Thunderbit potrafi pobierać dane ze stron mocno opartych na JavaScript, obsługiwać paginację, a nawet odwiedzać podstrony, aby wzbogacić zestaw danych.
- Bez kodowania: Wszystko działa na zasadzie kliknij i wybierz. Jeśli umiesz korzystać z przeglądarki, poradzisz sobie też z Thunderbit.
- Eksport gdzie chcesz: Natychmiast wyślesz dane do Google Sheets, Airtable, Notion, Excel albo CSV — dzięki czemu są gotowe do użycia z Zapier.
- Zaplanowany scraping: Ustaw cykliczne pobieranie danych (co godzinę, codziennie, co tydzień) prostym językiem, aby dane pozostawały aktualne bez ręcznej pracy.
Magia dzieje się wtedy, gdy połączysz moc scrapingu Thunderbit z automatyzacją Zapier. Thunderbit pobiera dane, a Zapier przenosi je tam, gdzie ich potrzebujesz.
Przewodnik krok po kroku: automatyzacja pozyskiwania danych z sieci za pomocą Zapier i Thunderbit
Przejdźmy przez rzeczywisty workflow — bez technicznego żargonu, za to z konkretnymi krokami.
1. Pobierz dane za pomocą Thunderbit
- Zainstaluj rozszerzenie Thunderbit do Chrome (na start jest darmowe).
- Wejdź na stronę docelową (np. katalog potencjalnych leadów).
- Kliknij ikonę Thunderbit, a następnie wybierz „AI Suggest Fields”, aby AI rozpoznało zawartość strony.
- W razie potrzeby dopasuj kolumny, po czym kliknij „Scrape”. Thunderbit wyciągnie dane i pokaże je w tabeli.
- Jeśli chcesz więcej szczegółów, użyj opcji „Scrape Subpages”, aby odwiedzić każdą podstronę i wzbogacić dane (np. pobrać e-maile ze stron firmowych).
2. Wyeksportuj dane do Google Sheets
- W Thunderbit kliknij „Export” i wybierz Google Sheets.
- Zaloguj się i wskaż docelowy arkusz.
- Thunderbit wypełni arkusz danymi ze scrapingu — gotowymi do przejęcia przez Zapier.
3. Utwórz Zapa w Zapier
- Zaloguj się do Zapier.
- Utwórz nowego Zapa z wyzwalaczem „New Spreadsheet Row in Google Sheets”.
- Połącz konto Google i wybierz arkusz aktualizowany przez Thunderbit.
4. Dodaj akcje automatyzujące Twój workflow
- Dodaj kroki wysyłające dane do CRM (np. HubSpot, Salesforce), e-maila, Slacka lub gdziekolwiek ich potrzebujesz.
- Skorzystaj z kroków Formatter lub Filter w Zapier, aby oczyścić albo zweryfikować dane przed dalszym przekazaniem.
- Przetestuj Zapa, aby upewnić się, że wszystko przebiega zgodnie z planem.

5. Zaplanuj i monitoruj
- Jeśli chcesz regularnie otrzymywać świeże dane, ustaw harmonogram scrapingu w Thunderbit (np. „codziennie o 9:00”).
- Zapier będzie automatycznie przetwarzał nowe wiersze, gdy tylko się pojawią — bez żadnej ręcznej obsługi.
Wskazówki pro:
- Grupuj pobieranie danych wsadowo, aby nie przekroczyć limitów tasków w Zapier.
- Dodaj powiadomienia o błędach w Zapier (Slack lub e-mail), aby szybciej wychwytywać problemy.
- Przy procesach o dużej skali rozważ wyższy plan Zapier albo przetwarzanie wsadowe.
Przykład z życia: jak użyć Zapier web scraping do usprawnienia śledzenia leadów sprzedażowych
Przenieśmy to do realnego scenariusza biznesowego. Załóżmy, że jesteś menedżerem sprzedaży w firmie SaaS i chcesz śledzić nowe leady z niszowego katalogu branżowego, który nie oferuje API.
Stary sposób: Ty (albo Twój zespół) spędzacie co tydzień godziny na kopiowaniu nazw, e-maili i informacji o firmach do arkusza, a potem ręcznie aktualizujecie CRM.
Nowy sposób z Thunderbit + Zapier:
- Thunderbit scrapuje katalog — włącznie z podstronami z bezpośrednimi e-mailami i profilami LinkedIn.
- Dane trafiają do Google Sheets — uporządkowane, czyste i aktualne.
- Zapier obserwuje nowe wiersze — każdy nowy lead uruchamia workflow.
- Leady są automatycznie dodawane do HubSpot CRM, przypisywane do handlowca, a zespół dostaje powiadomienie na Slacku.
- Cotygodniowe podsumowania e-mailowe trafiają do zarządu, a leady o wysokiej wartości są oznaczane do dalszego kontaktu.
Efekt? Zespoły raportują oszczędność ponad 6 godzin tygodniowo na osobę, pozyskanie o 40% więcej wysokiej jakości leadów i wzrost współczynników konwersji o 15–25%. Jedna firma z sektora usług finansowych odnotowała 70% zwrotu z inwestycji i 40% wzrost konwersji leadów po zautomatyzowaniu swojego lejka sprzedażowego (browsercat.com).
Porównanie Zapier, Thunderbit i innych rozwiązań do web scrapingu w automatyzacji
 Tak prezentują się wiodące narzędzia do automatyzacji biznesowej w 2026 roku:
Tak prezentują się wiodące narzędzia do automatyzacji biznesowej w 2026 roku:
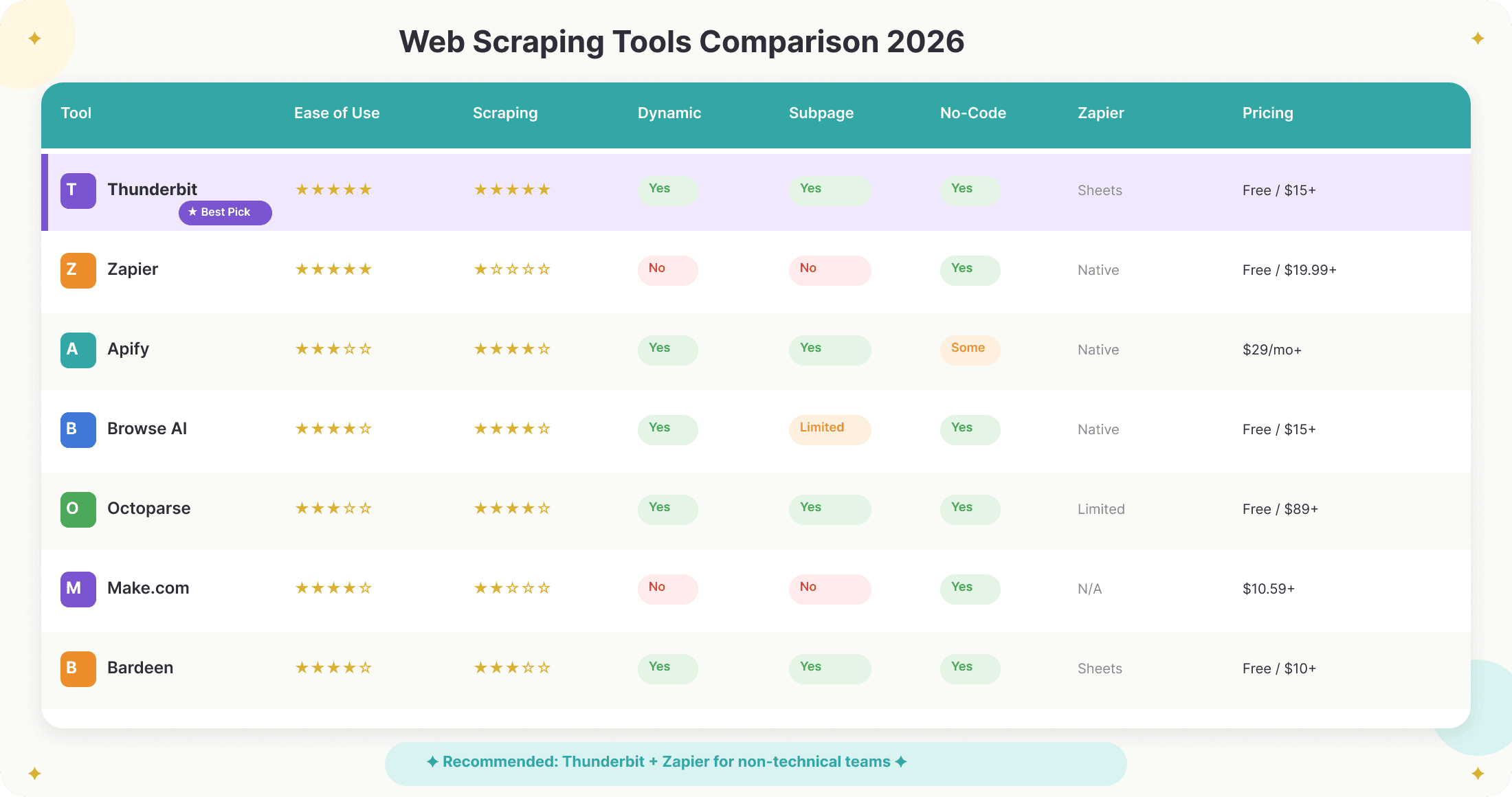
| Narzędzie | Łatwość użycia | Moc scrapingu | Obsługa stron dynamicznych | Scraping podstron | No-code | Integracja z Zapier | Cena |
|---|---|---|---|---|---|---|---|
| Thunderbit | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Tak | Tak | Tak | Przez Sheets/Airtable | Darmowy (6 stron), od 15 USD/mies. |
| Zapier (native) | ⭐⭐⭐⭐⭐ | ⭐ | Nie | Nie | Tak | — | Darmowy (100 tasków), od 19,99 USD/mies. |
| Apify | ⭐⭐⭐ | ⭐⭐⭐⭐ | Tak | Tak | Częściowo | Natywna | od 29 USD/mies. |
| Browse AI | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Tak | Ograniczona | Tak | Natywna | Darmowy (50 kredytów), od 15 USD/mies. |
| Octoparse | ⭐⭐⭐ | ⭐⭐⭐⭐ | Tak | Tak | Tak | Ograniczona | Darmowy, od 89 USD/mies. |
| Make.com | ⭐⭐⭐⭐ | ⭐⭐ | Nie | Nie | Tak | Natywna | od 10,59 USD/mies. |
| Bardeen | ⭐⭐⭐⭐ | ⭐⭐⭐ | Tak | Tak | Tak | Przez Sheets | Darmowy, od 10 USD/mies. |
Rekomendacja:
- Dla użytkowników nietechnicznych, którzy chcą szybkiego, niezawodnego i elastycznego scrapingu z łatwą automatyzacją, Thunderbit + Zapier to najlepszy wybór.
- Dla zespołów mocno technicznych albo złożonych projektów o dużej skali lepsze mogą być Apify lub Octoparse — ale wymagają więcej konfiguracji.
- Do scrapingu i automatyzacji opartej na przeglądarce Bardeen jest mocną alternatywą, choć często nadal korzysta z Zapier jako warstwy dalszych procesów.
Przyszłość Zapier web scraping: no-code, AI i trendy automatyzacji w 2026 roku
Nadchodząca fala automatyzacji kręci się wokół agentów AI i orkiestracji no-code. Do końca 2026 roku 40% aplikacji enterprise będzie zawierać wyspecjalizowanych agentów AI, podczas gdy w 2025 roku było to mniej niż 5%. Zapier już szybko rozwija ofertę, wprowadzając AI Actions, Copilot i autonomicznych Agentów, dzięki którym użytkownicy mogą opisywać workflow prostym językiem, a platforma zbuduje je automatycznie.
Jednocześnie scraperom opartym na AI, takim jak Thunderbit, udaje się uczynić pobieranie danych bardziej odpornym i bardziej dostępnym. Koniec z kruchymi selektorami CSS — wystarczy powiedzieć AI, czego potrzebujesz, a resztą zajmie się ono samo. Samonaprawiające się scrapery, ekstrakcja oparta na wizji i zaplanowane automatyzacje stają się nowym standardem.
Co to oznacza dla użytkowników biznesowych?
- 80% produktów technologicznych będzie tworzonych przez osoby nietechniczne do 2026 roku (Gartner).
- Zespoły oparte na danych mają 23 razy większą szansę na pozyskanie klientów i są 19 razy bardziej rentowne.
- Połączenie scrapingu AI i automatyzacji no-code otwiera nowe możliwości biznesowe — od dynamicznego ustalania cen, przez generowanie leadów w czasie rzeczywistym, po badania rynku na dużą skalę.
Wniosek jest prosty: jeśli nie automatyzujesz przepływów danych z sieci, zostawiasz pieniądze i czas na stole.
Podsumowanie i najważniejsze wnioski
Zapier web scraping zmienia sposób pracy zespołów sprzedaży i marketingu w 2026 roku — ale tylko wtedy, gdy współgra z odpowiednimi narzędziami. Zapier świetnie automatyzuje to, co dzieje się po zdobyciu danych, ale sam nie udźwignie ciężaru scrapingu stron. Właśnie dlatego Thunderbit ma tak duże znaczenie, oferując scrapowanie no-code z wykorzystaniem AI, dostępne dla każdego.
Najważniejsze wnioski:
- Zapier jest fundamentem automatyzacji dla ponad 3,4 mln firm, ale jego web scraping ogranicza się do podstawowego parsowania lub integracji z narzędziami zewnętrznymi.
- Thunderbit uzupełnia tę lukę dzięki scrapowaniu opartemu na AI, działającemu w 2 kliknięciach — z obsługą stron dynamicznych, podstron i harmonogramów, bez kodowania.
- Najlepszy workflow: scrape w Thunderbit → eksport do Google Sheets/Airtable → automatyzacja w Zapier.
- Efekty: zespoły oszczędzają godziny, zwiększają jakość leadów i osiągają wymierny ROI — w niektórych branżach nawet do 70%.
- Przyszłość to AI + no-code: do 2026 roku większość automatyzacji biznesowych będzie tworzona przez osoby nietechniczne, przy wsparciu inteligentnych agentów i odpornych scraperów AI.
Gotowy, by pożegnać ręczne wprowadzanie danych i wykorzystać moc automatycznych przepływów danych z sieci? Pobierz Thunderbit, skonfiguruj swojego pierwszego Zapa i zobacz, jak łatwa może być automatyzacja. Po więcej porad zajrzyj też na blog Thunderbit.
Wypróbuj AI Web Scraper Get Started Free
FAQ
1. Czy Zapier może samodzielnie scrapować dowolną stronę?
Nie, Zapier nie ma wbudowanego wizualnego scrapera stron. Potrafi jedynie parsować podstawową statyczną treść za pomocą Web Parsera albo łączyć się z zewnętrznymi narzędziami do scrapingu. Do danych strukturalnych lub dynamicznych użyj dedykowanego narzędzia, takiego jak Thunderbit, a następnie wyeksportuj dane do Google Sheets, aby Zapier mógł je automatyzować.
2. Jakie są główne ograniczenia Zapier web scraping?
Zapier nie radzi sobie ze stronami renderowanymi przez JavaScript, nawigacją po podstronach ani złożoną ekstrakcją danych. Kroki kodu są ograniczone do 30 sekund i 512 MB RAM, a zewnętrzne biblioteki nie są obsługiwane. Przy dużej skali koszty mogą też szybko wzrosnąć przez cennik oparty na taskach.
3. Jak Thunderbit integruje się z Zapier?
Thunderbit pobiera dane z dowolnej strony i eksportuje je bezpośrednio do Google Sheets, Airtable lub Notion. Zapier reaguje potem na nowe wiersze w tych narzędziach, automatyzując dalsze działania, takie jak dodawanie leadów do CRM, wysyłanie alertów czy aktualizacja dashboardów.
4. Jaki jest najlepszy sposób na automatyzację śledzenia leadów sprzedażowych z użyciem Zapier i web scrapingu?
Użyj Thunderbit do pobierania leadów z wybranych stron, wyeksportuj je do Google Sheets i skonfiguruj Zapa, który doda nowe leady do CRM oraz powiadomi zespół. Zaplanuj cykliczne scrapowanie w Thunderbit, aby dane zawsze były świeże.
5. Jakie trendy warto obserwować w automatyzacji web scrapingu w 2026 roku?
Warto śledzić scrapery oparte na AI i samonaprawiające się rozwiązania, no-code builders do workflow oraz agentic AI, które potrafią koordynować złożone automatyzacje wieloetapowe. Przyszłość to odporność, dostępność i płynne łączenie scrapingu z procesami biznesowymi.
Dowiedz się więcej
- Top 10 najlepszych narzędzi do web scrapingu w 2026 roku
- Jak rozpocząć tutorial pozyskiwania danych z sieci z użyciem Thunderbit
- Top 10 narzędzi AI do web scrapingu, które zwiększą efektywność w 2026 roku
- Top 9 no-code web scraperów do zautomatyzowanych rozwiązań
- Jak opanować automatyczne scrapowanie danych z użyciem Thunderbit
Gotowy, by zautomatyzować swoje procesy danych z sieci? Wypróbuj Thunderbit za darmo i zobacz, jak łatwo połączyć scraping z automatyzacją w 2026 roku.




