
Wszyscy dziś mówią o podejmowaniu decyzji opartych na danych, ale często umyka im to, jak czasochłonne i żmudne bywa samo zbieranie informacji. Jeśli kiedykolwiek próbowałeś gromadzić dane ręcznie, wiesz dobrze, że to prawdziwa mordęga. Widziałem wiele firm, które miały świetne strategie data-driven, ale utknęły już na starcie przez nieefektywne pozyskiwanie informacji. Jeśli jesteś w podobnym miejscu, ten artykuł pokaże Ci kilka świeżych rozwiązań.
💡 W tym artykule zaglądamy głębiej w świat data scraping i sprawdzamy, jak zmienia się on wraz z technologią. Przyjrzymy się ograniczeniom starych metod, pokażemy zalety scrapingu danych opartego na AI i podpowiemy praktyczne wskazówki, które da się wykorzystać w realnych projektach.
Czym jest Data Scraping?
Data scraping, czyli web scraping, polega na pobieraniu uporządkowanych informacji ze stron internetowych za pomocą narzędzi — często w formie tabel. To bardzo skuteczny sposób na szybkie zbieranie dużych ilości danych. Na przykład możesz pobrać publiczne dane z Google Maps do pozyskiwania leadów, zeskrobać SKU produktów e-commerce z Amazon do odsprzedaży albo analizy rynku, albo wyciągnąć opinie z mediów społecznościowych i Yelp, żeby lepiej zrozumieć swoich klientów.
Technologiczna zmiana w data scraping
Jeszcze niedawno zbieranie danych wydawało się czymś, z czym poradzą sobie tylko techniczni specjaliści — albo wymagało mnóstwa ręcznego kopiowania i wklejania. Ale dziś, w 2025 roku, do gry wchodzi AI. Data scraping nie jest już domeną wyłącznie programistów ani prostych automatyzacji.
Tradycyjne metody zawodzą
Nowoczesne strony internetowe stawiają przed nami coraz większe wyzwania: dynamiczne ładowanie treści (np. w oparciu o React/Vue), rosnącą popularność danych multimodalnych (tekst, wideo, obrazy) oraz niestandardowe struktury danych (kilka szablonów na jednej stronie). Najnowsze badania wskazują na trzy główne problemy związane z tradycyjnymi metodami web scrapingu:
-
Studnia bez dna pod względem kosztów utrzymania Tradycyjne web scrapery wymagają stałej, ręcznej opieki (około 3–5 godzin miesięcznie na jedną stronę). Gdy serwis się aktualizuje albo zmienia framework front-endu, 60% selektorów XPath przestaje działać. Narzędzia AI, dzięki modelom językowym i „rozumieniu” kodu, potrafią automatycznie dostosować się do 90% zmian strukturalnych, obniżając koszty utrzymania o 60–80%. W przypadku nowoczesnych witryn opartych na React/Vue narzędzia AI utrzymują stabilność data scraping dzięki rozumieniu semantycznemu, nawet gdy zmieniają się nazwy klas.
-
Ograniczona liczba wymiarów danych Tradycyjne metody potrafią pobierać tylko dane ustrukturyzowane, pomijając cenne informacje, takie jak:
- dane ukryte w obrazach
- treść tekstową w artykułach
- dane nieustrukturyzowane bez znaczników HTML
-
Problemy z jakością danych Tradycyjne metody mają trudność z treściami dynamicznymi, co prowadzi do niepełnych lub błędnych wyników:
- w przypadku danych stronicowanych (np. list produktów e-commerce) tradycyjne scrapery pobierają tylko 30–50% treści widocznej na pierwszym ekranie
- strony z nieskończonym przewijaniem (np. feedy społecznościowe) tracą ponad 60% kluczowych danych
- wysoki poziom błędów przy dopasowywaniu danych nieustrukturyzowanych (np. źle wyrównane elementy listy)
Właśnie tutaj do gry wchodzą narzędzia oparte na AI, takie jak Thunderbit. Ich zalety omówię poniżej.
Rozwój AI w data scraping
Pobieraj dane z dowolnej strony internetowej z użyciem AI Get Started Free
Do 2025 roku AI, a zwłaszcza duże modele językowe (LLM), pokazały naprawdę duży potencjał. Potrafią rozumieć i generować język naturalny, radzić sobie ze złożoną analizą danych i dostarczać znacznie wydajniejsze rozwiązania. Wiele narzędzi do scrapingu danych korzysta dziś z LLM, aby ominąć ograniczenia tradycyjnych metod. Po sprawdzeniu 13 narzędzi do data scraping w ostatnich miesiącach polecam Thunderbit AI Web Scraper.
Oto, co wyróżnia Thunderbit:
-
Rewolucyjny sposób interakcji: Użytkownik wpisuje proste polecenia w języku naturalnym, a system automatycznie tworzy plan scrapingu, skracając czas konfiguracji o 87% w porównaniu z tradycyjnymi narzędziami.
-
Duże zalety scrapingu lokalnego: Jako rozszerzenie przeglądarki Thunderbit oferuje:
- natychmiastowe pobieranie danych
- scraping stron dynamicznych i z nieskończonym przewijaniem
- scraping stron wymagających logowania
-
Zaawansowane przetwarzanie danych multimodalnych: Thunderbit obsługuje różne typy danych, takie jak:
- wyodrębnianie danych tekstowych z artykułów
- pobieranie tabel z danymi finansowymi z plików PDF
- rozpoznawanie danych z wielu obrazów i zamienianie ich w tabelę
- pobieranie napisów z filmów i ich podsumowywanie
Dzięki Thunderbit możesz z łatwością ogarnąć różne scenariusze zbierania danych. Zobaczmy, jak z niego korzystać.
Jak robić data scraping z użyciem AI
Wykonaj te cztery kroki, aby skorzystać z potężnych możliwości AI web scrapingu w Thunderbit:
-
Zainstaluj rozszerzenie do przeglądarki Wejdź na stronę Thunderbit i pobierz rozszerzenie Thunderbit z Chrome Web Store. Po instalacji przypnij je do paska narzędzi przeglądarki.
-
Zarejestruj się i odbierz darmowe kredyty Załóż konto w rozszerzeniu, aby otrzymać kredyty próbne. Pozwalają one przetestować podstawowe funkcje, takie jak AI web scraping, automatyczne wypełnianie formularzy i inteligentne podsumowania. Najlepiej najpierw pobawić się narzędziem w trybie testowym za darmo, zanim wykorzystasz kredyty — wtedy sprawdzisz, jak dobrze działa.
-
Uruchom inteligentne pobieranie danych Otwórz szablon z panelu bocznego Thunderbit. Opisz słowami, jakie dane chcesz zebrać i w jakim formacie, ustaw konkretny sposób ekstrakcji albo doprecyzuj inne szczegóły. Następnie kliknij przycisk scrapowania, aby rozpocząć data scraping.
Zaawansowane funkcje scrapingu (plan Pro)
Wykupując plan Pro Thunderbit (lub rozpoczynając bezpłatny okres próbny), odblokujesz następujące funkcje:
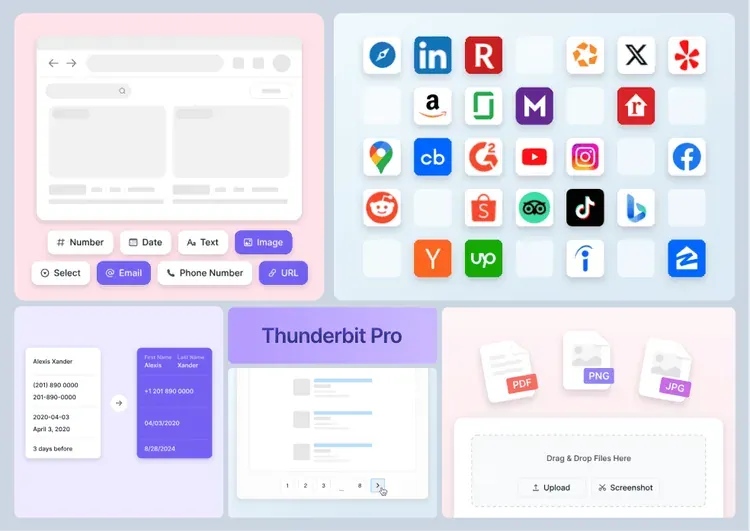
-
Przetwarzanie danych multimodalnych Obsługuje złożone scenariusze, takie jak analiza dokumentów PDF (raporty finansowe/instrukcje produktów), ekstrakcja danych z obrazów (metki cenowe/specyfikacje) oraz pobieranie napisów z wideo. System automatycznie standaryzuje dane nieustrukturyzowane.
-
Głębokie scrapowanie podstron Może opcjonalnie przechodzić do wszystkich podlinkowanych podstron na stronie (np. kart produktów/stron opinii użytkowników), inteligentnie rozpoznawać powiązane dane i automatycznie łączyć je z główną tabelą danych. Idealne do katalogów e-commerce, ofert nieruchomości i wielu innych zastosowań.
-
Gotowa biblioteka szablonów Błyskawicznie korzystaj z zoptymalizowanych szablonów scrapingu dla ponad 30 platform, takich jak TikTok, Amazon czy Zillow, z automatycznym dostosowaniem do zmian struktury strony. Nowi użytkownicy oszczędzają średnio 83% czasu konfiguracji.
-
Masowe zadania scrapingu Uruchamiaj wiele zadań scrapingu jednocześnie, z obsługą importu list URL-i do przetwarzania wsadowego.
-
Inteligentna obsługa paginacji Automatycznie rozpoznaje i pobiera treści podzielone na strony, w tym przyciski „pokaż więcej” i nawigację między stronami, a także obsługuje strony z nieskończonym przewijaniem. Testy wykazały pełne pobieranie ponad 200 stron list produktów e-commerce.
Praktyczny przewodnik po Thunderbit
Scenariusz 1: Zbieranie danych o nieruchomościach
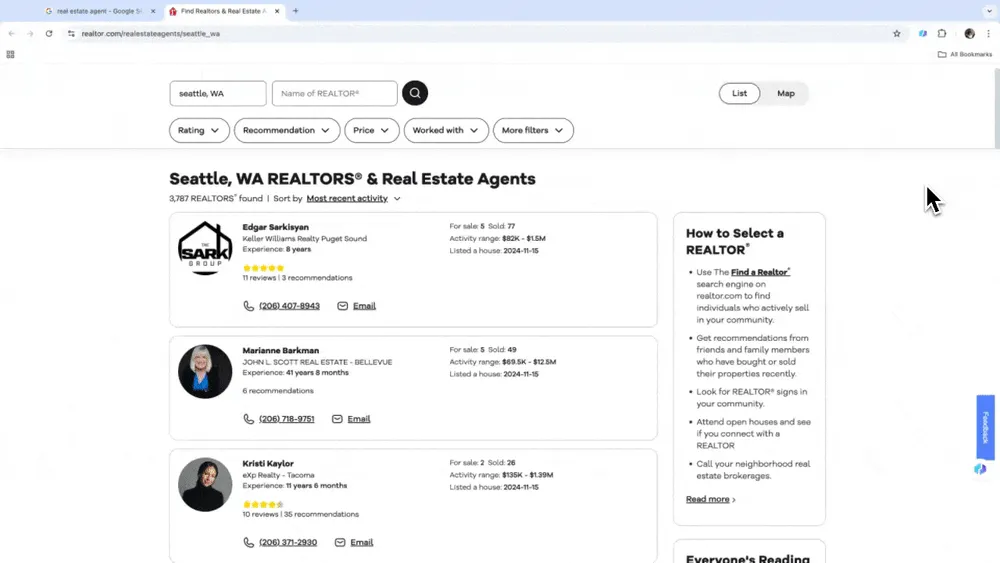
Jeśli jesteś agentem nieruchomości i chcesz pozyskiwać dane o ofertach z Zillow, albo inwestorem szukającym okazji, niezawodny web scraper może być Twoim najlepszym wsparciem. AI web scraper Thunderbit pozwala łatwo wyciągać kluczowe informacje o nieruchomościach z Zillow, dzięki czemu pozostajesz na bieżąco i utrzymujesz przewagę. Zobacz materiał wideo pokazujący, jak scrapować Zillow za pomocą Thunderbit.
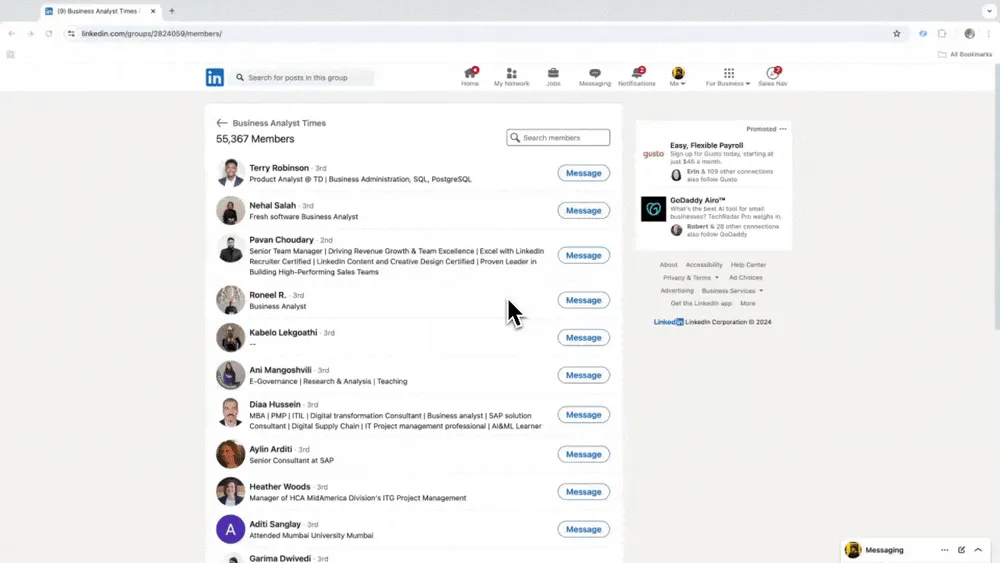
Scenariusz 2: Pozyskiwanie talentów i klientów
Jeśli pracujesz w HR i szukasz kandydatów albo jesteś handlowcem i potrzebujesz nowych leadów, niezawodny web scraper może być bardzo pomocny. Thunderbit umożliwia wyciąganie przydatnych danych kontaktowych i firmowych z publicznych stron, katalogów i profili, pomagając usprawnić rekrutację i zarządzanie leadami. Po pracy z tym narzędziem szybko zauważysz, że czasochłonne ręczne wyszukiwanie oraz kopiowanie i wklejanie odchodzą do przeszłości. Gotowy przepływ pracy znajdziesz w szablonie Website Contact Scraper.
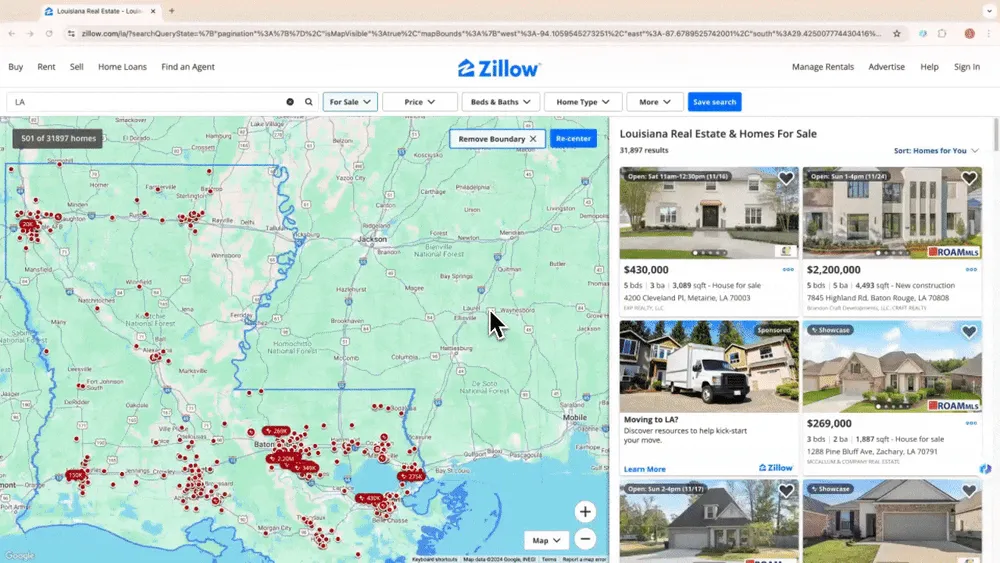
Scenariusz 3: Analiza rynku i targetowanie klientów
Jeśli prowadzisz firmę i zbierasz dane lokalizacyjne do analizy rynku albo pracujesz w sprzedaży i szukasz lokalnych leadów biznesowych, niezawodny web scraper może całkowicie zmienić zasady gry. Thunderbit pozwala łatwo pobierać kluczowe dane z Google Maps, pomagając podejmować lepsze decyzje i skuteczniej prowadzić działania sprzedażowe.
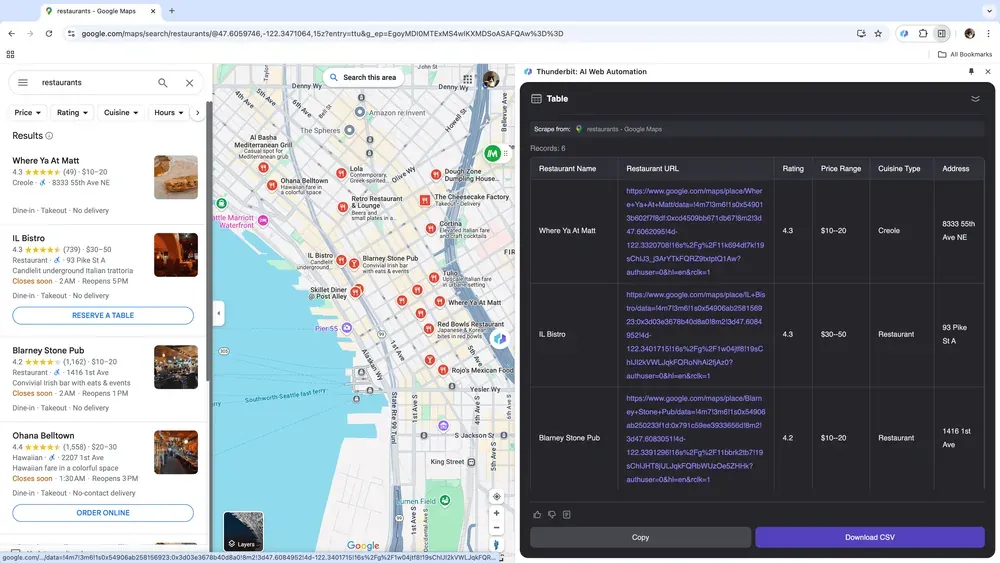
Scenariusz 4: Analiza danych e-commerce
Jeśli sprzedajesz online i chcesz lepiej rozumieć konkurencję albo jako przedsiębiorca śledzisz trendy rynkowe, Thunderbit będzie idealnym narzędziem! Potrafi łatwo zbierać różne dane produktowe z Amazon, w tym szczegółowe opisy, ceny i opinie użytkowników.
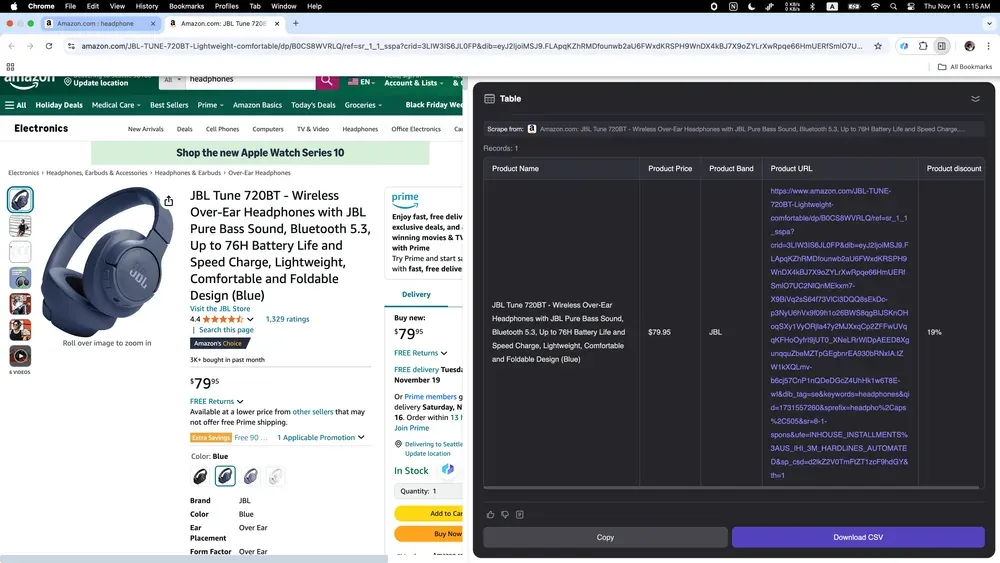
Thunderbit AI web scraper na nowo definiuje sposób, w jaki użytkownicy biznesowi zbierają dane — sprawia, że jest to szybsze, prostsze i bardziej efektywne niż kiedykolwiek. Niezależnie od tego, czy szukasz nieruchomości, potencjalnych klientów, czy analizujesz trendy w e-commerce, AI web scrapery potrafią oszczędzić Ci mnóstwo czasu i nerwów. Wykorzystaj potencjał AI w web scrapingu i zobacz, jak rośnie Twoja produktywność. Gotowy, by zacząć? Wypróbuj Thunderbit i zrób pierwszy krok w stronę mądrzejszego scrapowania stron.
Wypróbuj AI Web Scraper Thunderbit
Ekskluzywne wskazówki dotyczące czyszczenia danych
W przypadku tradycyjnych scraperów prawdziwe wyzwanie zaczyna się dopiero po scrapingu — przy czyszczeniu danych. AI Thunderbit może wykonywać czyszczenie danych już w trakcie scrapingu, wykorzystując LLM, co zmniejsza nakład pracy związany z obróbką danych o 83% dzięki następującym innowacyjnym funkcjom:
Wskazówka 1: Inteligentne dopasowanie pól
Gdy pracujesz z wieloma źródłami i różnorodnymi danymi (np. jednocześnie scrapujesz LinkedIn i Zillow), AI Thunderbit automatycznie tworzy semantyczne mapowanie:
- automatycznie rozpoznaje odpowiedniki pól w różnych źródłach danych (np. „price” ↔ „售价” ↔ „Price”)
- inteligentnie łączy podobne pola (np. „area” i „square feet”)
- standaryzuje dane między platformami (np. „current position” z LinkedIn i „property status” z Zillow są ujednolicone jako dane tagowe)
Wskazówka 2: Uzupełnianie z uwzględnieniem kontekstu
Dzięki zdolnościom rozumienia kontekstu przez duże modele językowe Thunderbit osiąga 99% skuteczności uzupełniania danych — to wynik lidera branży:
- uzupełnianie adresów: automatycznie dopisuje miasto i stan na podstawie kodu pocztowego (np. wpisanie 10001 → New York City, NY)
- wnioskowanie o ścieżce kariery: przewiduje możliwe doświadczenie zawodowe na podstawie wykształcenia z LinkedIn
Wskazówka 3: Optymalizacja danych
- tłumaczenie wielojęzyczne (obsługa tłumaczenia w czasie rzeczywistym w 12 językach, w tym angielskim, chińskim i japońskim)
- inteligentne podsumowanie (skrócenie 500-słowowego opisu produktu do trzech kluczowych argumentów sprzedażowych)
- ujednolicanie jednostek (automatyczna konwersja square feet ↔ square meters, Fahrenheit ↔ Celsius)
- standaryzacja formatu (daty w formacie YYYY-MM-DD, waluty jako USD)
Wskazówka 4: Weryfikacja jakości
- inteligentna korekta błędów: automatycznie poprawia błędy formatowania (np. numer telefonu +01 138-1234-5678 → +113812345678)
- walidacja logiczna: sprawdza, czy „year built” jest wcześniejszy niż „last renovation time”
Wskazówka 5: Tagowanie AI
Automatycznie generuje inteligentne tagi dzięki przetwarzaniu języka naturalnego:
- tagi analizy sentymentu (automatycznie oznacza opinie klientów jako pozytywne/negatywne/neutralne)
- tagi wartości biznesowej (automatycznie oznacza „high-potential clients” / „properties to follow up on”)
- tagi klasyfikacji branżowej (automatycznie oznacza profile LinkedIn tagami „tech|finance|healthcare”)
Wady data scraping
Choć data scraping daje ogromną wartość, warto też pamiętać o wyzwaniach, z którymi mogą mierzyć się firmy. Na pierwszym planie stoją kwestie prawne — regulacje takie jak RODO i CCPA nakładają surowe wymagania na praktyki zbierania danych, dlatego zgodność z przepisami o prywatności jest absolutnie kluczowa. Strony internetowe często stosują zaawansowane zabezpieczenia, takie jak Cloudflare, aby wykrywać i blokować scraping poprzez ograniczenia IP.
Przyszłość data scraping w erze AI
Rozwój AI przekształca web scraping w intuicyjne narzędzie dla biznesu. Wyobraź sobie, że wpisujesz jedynie domenę (np. zillow.com) i swoją prośbę (np. „zeskrob wszystkie oferty nieruchomości w New York City”), a AI samo mapuje wszystkie istotne punkty danych — od szczegółów nieruchomości po trendy cenowe — bez ręcznej konfiguracji. Takie inteligentne systemy będą też płynnie integrować pobrane dane z procesami biznesowymi, automatycznie przesyłając informacje o leadach z LinkedIn do CRM-ów albo wpuszczając metryki e-commerce do paneli analitycznych. Zaawansowane rozpoznawanie wzorców umożliwi predictive scraping, które będzie proaktywnie monitorować zmiany stanów magazynowych i pojawiające się trendy rynkowe. Co ważne, AI będzie też dynamicznie obsługiwać zgodność z przepisami, dostosowując parametry scrapingu w czasie rzeczywistym do zmieniających się regulacji, przy zachowaniu przejrzystych śladów audytowych.
Ta zmiana paradygmatu napędzana przez AI nie tylko demokratyzuje dostęp do kluczowych informacji biznesowych, ale też fundamentalnie zmienia sposób, w jaki organizacje pracują z danymi z internetu. Wraz z dojrzewaniem tych technologii przewagę zyskają ci, którzy wcześnie wdrożą rozwiązania do scrapingu oparte na AI, takie jak Thunderbit — i przełożą to na konkretną przewagę konkurencyjną w decyzjach opartych na danych.
FAQ
-
Czym jest Thunderbit? Thunderbit to inteligentne rozszerzenie do przeglądarki oparte na dużych modelach językowych (LLM), stworzone z myślą o nowoczesnym pozyskiwaniu danych. Oferuje nie tylko AI web scraping, ale także integruje przetwarzanie danych multimodalnych, wspierając kompleksową ekstrakcję danych z dynamicznych stron, dokumentów PDF, obrazów i filmów. Jako lokalne rozwiązanie przeglądarkowe potrafi bezpośrednio obsługiwać strony wymagające logowania (np. LinkedIn) i automatycznie dostosowywać się do zmian w nowoczesnych frameworkach front-endowych.
-
Jak działa AI web scraper Thunderbit? AI web scraper Thunderbit wykorzystuje AI do wyciągania ustrukturyzowanych danych ze stron internetowych. Użytkownik może kliknąć „AI Suggest Columns”, aby AI podpowiedziało, jak zeskrobać bieżącą stronę, a następnie kliknąć „Scrape”, by pobrać dane. Potrafi przetwarzać dane z dowolnej strony, pliku PDF lub obrazu w zaledwie dwóch kliknięciach.
-
Jaka jest różnica między scrapowaniem list a scrapowaniem podstron? Scrapowanie list jest zoptymalizowane pod scenariusze stronicowane (np. listy produktów e-commerce) i automatycznie rozpoznaje logikę paginacji, pobierając tysiące rekordów. Scrapowanie podstron działa w trybie drzewa (np. listy ofert na Zillow → strony szczegółów → układy mieszkań), automatycznie budując relacje między tabelą główną i podrzędną dzięki powiązaniom semantycznym.
-
Czy osoby nietechniczne mogą korzystać z Thunderbit? Thunderbit został zaprojektowany z myślą o interakcji w języku naturalnym: użytkownik po prostu opisuje swoje potrzeby, np. „imię, e-mail, telefon”, a system automatycznie tworzy plan scrapingu. Nasze dane testowe pokazują, że 85% użytkowników kończy pierwsze zbieranie danych w ciągu 10 minut, bez znajomości programowania webowego.
-
Z jakimi typami danych radzi sobie Thunderbit? Thunderbit obsługuje inteligentne rozpoznawanie wielu typów danych:
- dane ustrukturyzowane: tabele, listy (np. specyfikacje produktów Amazon)
- dane nieustrukturyzowane: tekst recenzji, dokumenty PDF (automatyczne rozpoznawanie)
- dane multimodalne: metki cenowe na obrazach, ekstrakcja napisów z wideo
- dane dynamiczne: treści z nieskończonym przewijaniem, obrazy ładowane leniwie
- dane powiązane: mapowanie relacji między stronami (np. kontakty z LinkedIn → informacje o firmie)
-
Jak zacząć korzystać z Thunderbit? Dowiedz się więcej o naszych możliwościach scrapingu albo przejrzyj naszą bibliotekę szablonów, aby od razu zacząć.
Dowiedz się więcej:
- Najlepsze narzędzia i oprogramowanie do web scrapingu w 2025 roku
- Jak zeskrobać dowolną stronę internetową z użyciem AI
- Jak skonfigurować Thunderbit
Wypróbuj AI Web Scraper Get Started Free




