

Sieć rozwija się w tempie, które naprawdę trudno ogarnąć. Każdego dnia pojawiają się miliardy nowych stron, produktów, opinii i zestawów danych — napędzając wszystko: od badań rynku, przez trening AI, po Twoje kolejne zakupy na Amazonie. Jako ktoś, kto od lat działa w obszarze SaaS i automatyzacji, widziałem na własne oczy, jak odpowiednie dane mogą zadecydować o sukcesie albo porażce decyzji biznesowej. Problem w tym, że zbieranie, aktualizowanie i wyciąganie sensu z tych wszystkich danych z internetu staje się coraz trudniejsze, a nie łatwiejsze. Tradycyjne web scrapery nie nadążają, a firmy szukają inteligentniejszego i szybszego sposobu, by zamieniać internet w konkretne wnioski. I właśnie tutaj wchodzi cloud crawler — narzędzie, które po cichu zmienia sposób, w jaki organizacje odkrywają i wykorzystują dane z sieci na dużą skalę.
Czym więc dokładnie jest cloud crawler? Czym różni się od scraperów, które być może już znasz? I dlaczego zespoły od sprzedaży po operacje stawiają na tę technologię, by utrzymać przewagę w świecie opartym na danych? Rozłóżmy to na czynniki pierwsze, odczarujmy branżowe hasła i zobaczmy, jak cloud crawlery (zwłaszcza rozwiązanie Thunderbit) zmieniają zasady gry dla nowoczesnych firm.
Czym jest cloud crawler? Kolejny etap odkrywania danych
Wyciągaj dane z dowolnej strony internetowej z pomocą AI Get Started Free
Wyjaśnijmy to prosto: cloud crawler to nie tylko web scraper działający w chmurze. To bardziej inteligentny silnik do odkrywania danych — chmurowy system zaprojektowany do automatycznego wyszukiwania, pobierania i analizowania ogromnych zbiorów danych z całego internetu. Tradycyjny web scraper pobiera informacje z kilku stron (często po jednej, zwykle z jednego urządzenia), natomiast cloud crawler działa na zupełnie innym poziomie. Uruchamia się w wydajnych chmurowych centrach danych, przeszukując jednocześnie tysiące, a nawet miliony stron, i potrafi przetwarzać wszystko: od tekstu, przez obrazy, po PDF-y — niezależnie od tego, jak złożona lub rozbudowana jest dana witryna.
Pomyśl o tym tak: jeśli web scraper jest jak jeden bibliotekarz przepisujący fragmenty z książki, to cloud crawler przypomina zespół superkomputerów, które skanują całą bibliotekę naraz, jednocześnie oznaczając, porządkując i analizując treści. Efekt? Firmy dostają bogatsze, świeższe i bardziej użyteczne dane — bez ograniczeń lokalnego sprzętu i bez ręcznej harówki (Sitebulb, Octoparse).
Cloud crawler a tradycyjny web scraper: jaka jest realna różnica?
Jeśli kiedykolwiek korzystałeś z web scrapera, znasz podstawy: wskazujesz stronę, określasz, czego chcesz, i pozwalasz mu pobrać dane. Ale wraz ze wzrostem internetu i jego złożoności stary model zaczyna pokazywać swoje ograniczenia. Oto porównanie cloud crawlerów i tradycyjnych web scraperów:
| Cecha/aspekt | Tradycyjny web scraper | Cloud crawler |
|---|---|---|
| Uruchomienie | Działa na lokalnym urządzeniu lub serwerze | Działa w chmurze (zdalne centra danych) |
| Skala | Ograniczona mocą komputera | Masowo równoległe przetwarzanie — tysiące stron jednocześnie |
| Szybkość | Wolniejszy, szczególnie przy dużych zadaniach | Wysokowydajne przetwarzanie wsadowe |
| Utrzymanie | Wymaga częstych aktualizacji, psuje się przy zmianach na stronie | Chmurowy, sam się aktualizuje, mniej podatny na awarie |
| Rodzaje danych | Zwykle tekst, czasem obrazy | Tekst, obrazy, PDF-y, złożone układy |
| Dostęp | Powiązany z Twoim urządzeniem i siecią | Dostępny z dowolnego miejsca i urządzenia |
| Planowanie | Ręczne lub podstawowa automatyzacja | Zaawansowane harmonogramy, zadania cykliczne |
| Najlepszy do | Małych projektów, prostych stron | Dużych, częstych lub złożonych potrzeb danych |
Cloud crawlery są zbudowane pod współczesny internet — taki, w którym dane są wszędzie, a szybkość i skala to nie luksus, tylko konieczność (GPTBots, Octoparse).
Jak cloud crawlery zwiększają efektywność pozyskiwania danych
I tu robi się naprawdę ciekawie. Cloud crawlery wykorzystują moc chmury, aby równolegle przetwarzać tysiące stron. Oznacza to, że możesz zeskrobać cały katalog e-commerce, monitorować ceny konkurencji na dziesiątkach stron albo zebrać oferty nieruchomości z wszystkich największych portali — i to w ułamku czasu potrzebnego tradycyjnemu scraperowi.
Dlaczego to ważne? Bo w e-commerce, finansach i nieruchomościach świeżość danych jest kluczowa. Ceny, stany magazynowe i trendy rynkowe zmieniają się z minuty na minutę. Czekanie godzinami, a nawet dniami, aż lokalny scraper zakończy pracę, zwyczajnie nie wchodzi w grę. Cloud crawlery nie są ograniczone pamięcią RAM laptopa ani biurowym Wi‑Fi — skalują się wtedy, gdy trzeba, więc możesz obsługiwać ogromne zadania bez najmniejszego wysiłku (Zyte, Octoparse).
Branże, które najbardziej korzystają z tej efektywności, to między innymi:
- E-commerce: monitoring cen, agregacja katalogów produktów, analiza opinii
- Nieruchomości: zbieranie ofert, śledzenie trendów rynkowych, porównywanie nieruchomości
- Finanse: analiza wiadomości i sentymentu, monitoring akcji/kryptowalut, śledzenie regulacji
- Sprzedaż i marketing: pozyskiwanie leadów, analiza konkurencji, wyłapywanie trendów
Szczerze? To dopiero początek. Jeśli potrzebujesz danych z internetu na dużą skalę, cloud crawler to Twój nowy najlepszy pomocnik.
Rozwiązanie Thunderbit Cloud Crawler: szybkie, elastyczne i skuteczne
Na chwilę założę czapkę Thunderbit (choć właściwie nigdy jej nie zdejmuję). Thunderbit w trybie cloud scraping to nasza odpowiedź na współczesne wyzwania związane z danymi — cloud crawler stworzony dla użytkowników biznesowych, którzy chcą rezultatów, a nie problemów.
Co wyróżnia cloud crawler Thunderbit?
- Błyskawiczne scrapowanie wsadowe: pobieraj do 50 stron jednocześnie, korzystając z serwerów w USA, UE i Azji, by działać globalnie. Koniec z czekaniem, aż laptop „przemieli” długą listę.
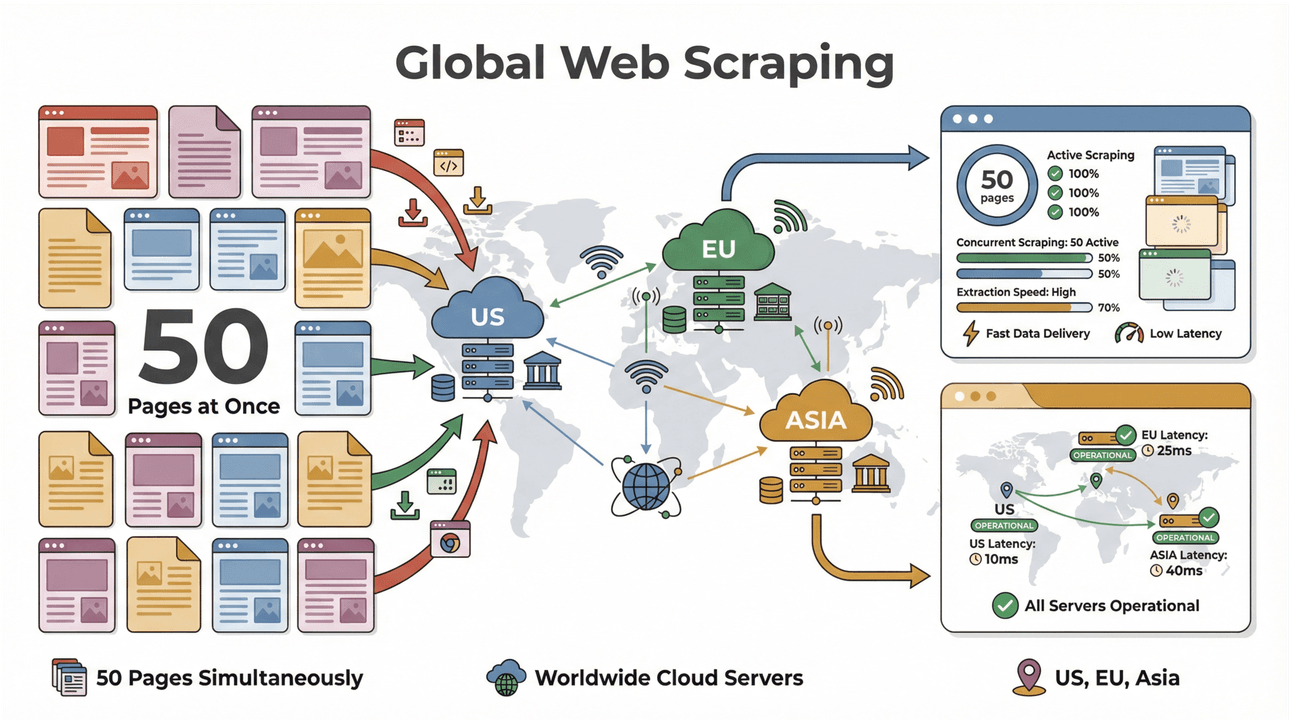
- Obsługa złożonych stron: AI Thunderbit radzi sobie zarówno z dynamicznymi sklepami internetowymi, jak i trudnymi PDF-ami czy ekstrakcją obrazów. Jeśli coś jest w sieci, Thunderbit najpewniej potrafi to pobrać (Thunderbit).
- Crawlowanie podstron: Potrzebujesz wzbogacić dane o informacje z podstron, np. specyfikacje produktów lub bio autorów? AI Thunderbit może odwiedzić każdą podstronę i połączyć wyniki z głównym zbiorem danych (Thunderbit).
- Inteligentne strukturujący danych: Skorzystaj z „AI Suggest Fields”, aby Thunderbit sam przeanalizował stronę i zaproponował najlepsze kolumny — bez kodowania i bez budowania szablonów.
- Eksport gdzie chcesz: Wyślij dane bezpośrednio do Excel, Google Sheets, Airtable lub Notion. Albo po prostu pobierz je jako CSV/JSON — tak, jak pasuje do Twojego procesu (Thunderbit).
- Bez konieczności utrzymania: AI Thunderbit dostosowuje się do zmian na stronie, więc nie musisz ciągle naprawiać zepsutych scraperów (Thunderbit).
I tak — możesz przetestować to wszystko w ramach darmowego planu, więc nie musisz wierzyć mi na słowo.
Wypróbuj Thunderbit Cloud Scraper za darmo
Wdrażanie cloud crawlera: chmura czy lokalnie — co wybrać?
Jedną z największych zalet cloud crawlerów jest elastyczność wdrożenia. W przypadku tradycyjnego, lokalnego crawlera jesteś przywiązany do konkretnego urządzenia, sieci i często także do wielu technicznych komplikacji. Jeśli komputer przejdzie w uśpienie albo padnie internet, scrapowanie się zatrzyma. Skalowanie oznacza zakup kolejnego sprzętu lub uruchamianie wielu skryptów.
Cloud crawlery odwracają ten model do góry nogami:
- Bez specjalistycznego sprzętu: Cała ciężka praca odbywa się w chmurze. Możesz uruchamiać duże zadania nawet z Chromebooka, Maca czy telefonu.
- Dostęp z dowolnego miejsca: Jesteś w podróży? Pracujesz zdalnie? Nie ma problemu — cloud crawler jest zawsze dostępny.
- Łatwe skalowanie: Musisz zeskrobać 10 000 stron zamiast 100? Po prostu zwiększasz zakres zadania — bez udziału IT.
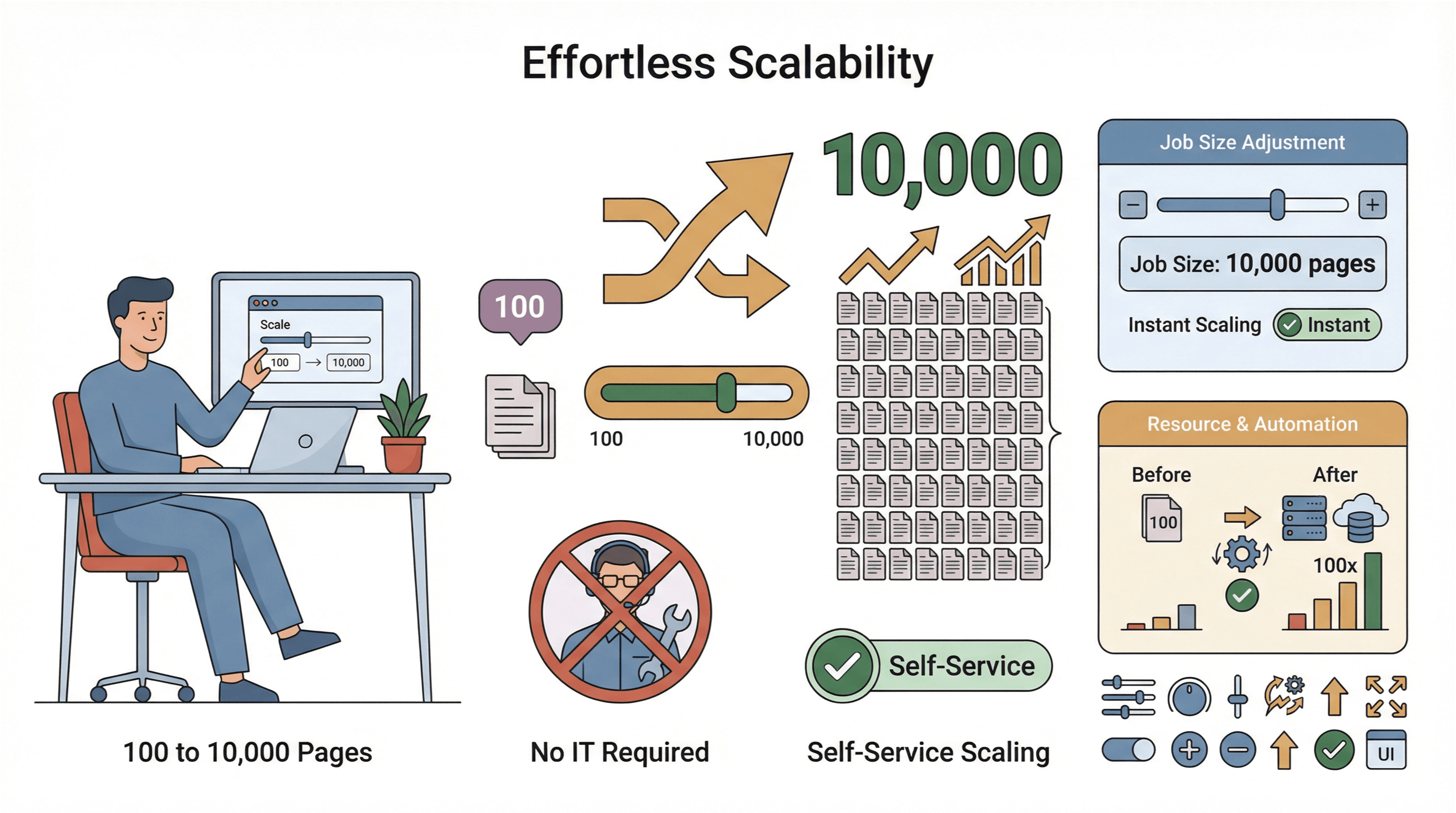
- Globalne pozyskiwanie danych: Dzięki serwerom w wielu regionach możesz łatwiej uzyskiwać dostęp do treści objętych ograniczeniami geograficznymi i lepiej zarządzać zgodnością z przepisami (PromptCloud).
Oczywiście bezpieczeństwo i zgodność z przepisami zawsze są najważniejsze. Najlepsze cloud crawlery — w tym Thunderbit — korzystają z szyfrowanych połączeń, respektują zasady serwisów i oferują funkcje pomagające odpowiedzialnie zarządzać wrażliwymi danymi.
Realny wpływ: jak cloud crawlery zmieniają strategie oparte na danych
Przejdźmy do konkretów. Dlaczego firmy przechodzą na cloud crawlery? Bo widzą realne, mierzalne efekty:
- Analiza rynku w czasie rzeczywistym: Detaliści używają cloud crawlerów do monitorowania cen i stanów magazynowych konkurencji na bieżąco, co umożliwia dynamiczne ustalanie cen i szybszą reakcję na zmiany rynkowe (Zyte).
- Prognozowanie trendów konsumenckich: Marki agregują opinie, wpisy z mediów społecznościowych i dyskusje na forach, aby wyłapywać nowe trendy i na bieżąco dostosowywać kampanie.
- Sprzedaż i generowanie leadów: Zespoły sprzedażowe tworzą aktualne listy kontaktów z katalogów, stron wydarzeń, a nawet PDF-ów — zasilając CRM świeżymi, wartościowymi kontaktami (Thunderbit).
- Operacje i zgodność: Firmy finansowe używają cloud crawlerów do monitorowania zmian regulacyjnych, wiadomości i zgłoszeń w wielu jurysdykcjach — ograniczając ryzyko i wyprzedzając zmiany.
Wspólny mianownik? Cloud crawlery pozwalają zespołom działać szybciej, podejmować mądrzejsze decyzje i wyprzedzać konkurencję, która nadal jedzie na zwolnionym pasie.
Najważniejsze cechy cloud crawlera, na które warto zwrócić uwagę
Sprawdź ceny i funkcje Thunderbit Get Started Free
Nie każdy cloud crawler działa tak samo. Jeśli porównujesz opcje, oto cechy, które naprawdę mają znaczenie (i w których Thunderbit błyszczy):
- Skalowalność: Czy poradzi sobie z tysiącami stron naraz? Czy zwalnia wraz ze wzrostem zadania?
- Łatwość obsługi: Czy interfejs jest przyjazny dla osób nietechnicznych? Czy można skonfigurować scrapowanie kilkoma kliknięciami?
- Obsługa wielu typów danych: Tekst, obrazy, PDF-y, podstrony — czy ogarnia wszystko?
- Integracje: Czy eksportuje dane do Twoich ulubionych narzędzi (Excel, Sheets, Notion, Airtable)?
- Harmonogramowanie: Czy można ustawić zadania cykliczne, aby dane były zawsze świeże?
- Wsparcie AI: Czy oferuje inteligentne propozycje pól, wzbogacanie danych i automatyczne dostosowanie do zmian na stronie?
- Bezpieczeństwo i zgodność: Czy Twoje dane i dane logowania są chronione? Czy pomaga spełniać wymagania przepisów o prywatności?
Thunderbit spełnia wszystkie te kryteria, dlatego jest świetnym wyborem dla zespołów, które chcą mocy bez bólu głowy.
Jak zacząć: korzystanie z cloud crawlera w firmie
Gotowy, żeby zacząć? Oto jak przeciętny użytkownik biznesowy może ruszyć z cloud crawlerem takim jak Thunderbit:
- Zainstaluj rozszerzenie Thunderbit do Chrome: szybka konfiguracja, bez udziału IT.
- Wybierz źródło: Otwórz stronę, listę lub dokument, z którego chcesz pobrać dane.
- Kliknij „AI Suggest Fields”: Pozwól AI Thunderbit przeanalizować stronę i zaproponować najlepsze kolumny do pobrania.
- Dostosuj ustawienia: Dodaj, usuń lub zmień nazwy pól zgodnie z potrzebami.
- Wybierz tryb cloud scraping: Przy dużych zadaniach lub złożonych stronach przełącz się na tryb chmurowy, by uzyskać maksymalną szybkość.
- Uruchom zadanie: Thunderbit przetworzy w chmurze do 50 stron jednocześnie.
- Sprawdź i wyeksportuj: Podejrzyj wyniki, a potem wyślij je do Excel, Google Sheets, Notion lub Airtable.
- Ustaw zadania cykliczne: Jeśli potrzebujesz stałych aktualizacji, zaplanuj regularne scrapowanie — dane będą odświeżane automatycznie (Thunderbit Docs).
Wskazówka: Zacznij od małego zadania, żeby oswoić się z narzędziem, a potem zwiększaj skalę, gdy poczujesz się pewniej. I nie wahaj się korzystać ze wsparcia Thunderbit lub dokumentacji — są po to, żeby Ci pomóc.
Zacznij cloud crawling z Thunderbit
Przyszłość pozyskiwania danych: co dalej z cloud crawlerami?
Rewolucja cloud crawlerów dopiero się zaczyna. Oto, na co zwracam uwagę w najbliższych latach:
- Inteligentniejsze wyodrębnianie danych przez AI: Cloud crawlery coraz lepiej rozumieją kontekst, relacje, a nawet sentyment — dzięki czemu zbierane dane stają się cenniejsze (GPTBots).
- Obsługa nowych typów danych: Można spodziewać się lepszego przetwarzania wideo, audio i treści interaktywnych — nie tylko statycznego tekstu i obrazów.
- Głębsza automatyzacja: Od automatycznego planowania po alerty w czasie rzeczywistym — cloud crawlery staną się jeszcze bardziej bezobsługowe.
- Lepsza zgodność z przepisami: Wraz z rozwojem prawa prywatności pojawi się więcej narzędzi pomagających zespołom działać zgodnie z regulacjami.
- Integracja z narzędziami BI i AI: Bezpośrednie pipeline’y z cloud crawlerów do platform analitycznych, dashboardów i systemów uczenia maszynowego.
Krótko mówiąc, cloud crawlery mają szansę stać się fundamentem cyfrowej strategii biznesowej — napędzając wszystko: od premier produktów po prognozowanie wspierane AI (Thunderbit Blog).
Podsumowanie: dlaczego cloud crawlery są niezbędne w nowoczesnym biznesie
Podsumowując: internet zalewa nas danymi, a stare metody ich zbierania po prostu nie nadążają. Cloud crawlery to kolejny etap rozwoju — oferują szybkość, skalę i inteligencję, których tradycyjne scrapery nie są w stanie dorównać. Narzędzia takie jak Thunderbit sprawiają, że każdy zespół — techniczny czy nietechniczny — może wykorzystać pełen potencjał danych z sieci, podejmować lepsze decyzje, reagować szybciej i budować realną przewagę nad konkurencją.
Jeśli masz dość ręcznego scrapowania i powolnego zbierania danych, teraz jest najlepszy moment, by sprawdzić, co cloud crawler może zrobić dla Twojej firmy. Wypróbuj tryb cloud scraping w Thunderbit i zobacz, jak proste — i potężne — może być nowoczesne odkrywanie danych. A jeśli chcesz zgłębić temat, zajrzyj na Thunderbit Blog, gdzie znajdziesz więcej poradników, wskazówek i przykładów z praktyki.
FAQ
1. Czym jest cloud crawler w prostych słowach?
Cloud crawler to chmurowe narzędzie, które automatycznie wyszukuje, pobiera i analizuje duże ilości danych z internetu. W przeciwieństwie do tradycyjnych scraperów działających lokalnie, cloud crawlery pracują w wydajnych centrach danych, co daje ogromną skalę i szybkość.
2. Czym cloud crawler różni się od zwykłego web scrapera?
Cloud crawlery działają w chmurze, obsługują tysiące stron naraz, radzą sobie ze złożonymi typami danych (takimi jak obrazy i PDF-y) i nie wymagają utrzymania ani lokalnego sprzętu. Tradycyjne scrapery są ograniczone mocą urządzenia i najlepiej sprawdzają się przy mniejszych, prostszych zadaniach.
3. Jakie są główne zalety korzystania z cloud crawlera?
Cloud crawlery zapewniają szybkie, masowe pozyskiwanie danych, obsługę złożonych stron, łatwy dostęp z dowolnego miejsca oraz zaawansowane funkcje, takie jak harmonogramowanie i ekstrakcja wspierana AI. To idealne rozwiązanie dla firm, które potrzebują świeżych i konkretnych danych szybko.
4. Jak działa cloud crawler Thunderbit dla użytkowników biznesowych?
Cloud crawler Thunderbit pozwala skonfigurować scrapowanie w kilku kliknięciach — bez kodowania. Możesz pobierać dane ze stron, PDF-ów i obrazów, wzbogacać je za pomocą AI i eksportować bezpośrednio do Excel, Google Sheets, Notion lub Airtable. To rozwiązanie stworzone dla osób nietechnicznych, które chcą efektów, a nie złożoności.
5. Czy cloud crawling jest bezpieczny i zgodny z przepisami o prywatności danych?
Tak, wiodące cloud crawlery, takie jak Thunderbit, korzystają z szyfrowanych połączeń i dobrych praktyk w zakresie bezpieczeństwa danych. Zawsze pamiętaj, by pobierać wyłącznie publicznie dostępne dane oraz przestrzegać regulaminów stron i przepisów o prywatności.
Gotowy, żeby sprawdzić, co potrafi cloud crawler? Pobierz Thunderbit i zacznij dziś odkrywać świat wielkoskalowego pozyskiwania danych w chmurze.
Wypróbuj Thunderbit Cloud Crawler już dziś Get Started Free
Dowiedz się więcej
- Top 15 AI Web Crawlerów, które warto znać w 2025 roku
- Crawlowanie stron na żywo z AI: krótki przewodnik
- 10 najlepszych darmowych opcji internetowego crawlera stron w 2025 roku
- Jak wyciągać dane ze strony internetowej za pomocą Thunderbit
- Jak opanować automatyczne scrapowanie danych z pomocą Thunderbit




