

Sieć pęka w szwach od wartościowych danych — niezależnie od tego, czy działasz w sprzedaży, e-commerce czy badaniach rynku, web scraping to tajna broń do generowania leadów, monitorowania cen i analizy konkurencji. Jest jednak haczyk: im więcej firm korzysta ze scrapingu, tym ostrzej strony internetowe zaczynają się bronić. Zmiana jest wyraźna: analiza ppc.land z 2024 roku wykazała, że ponad jedna trzecia z 1000 najpopularniejszych serwisów blokuje już sam crawler OpenAI — a szerszy zestaw narzędzi, takich jak blokady IP, CAPTCHA i fingerprinting przeglądarki, stał się dziś normą, a nie wyjątkiem.
Jeśli kiedykolwiek patrzyłeś, jak Twój skrypt w Pythonie działa bez problemu przez 20 minut, a potem nagle wpada na ścianę błędów 403, dobrze wiesz, jak frustrujące potrafi to być.
Od lat pracuję w SaaS i automatyzacji i widziałem na własne oczy, jak projekty scrapingowe potrafią w mgnieniu oka przejść drogę od „wow, to jest proste” do „dlaczego jestem blokowany wszędzie?”. Dlatego przejdźmy do konkretów: pokażę Ci, jak robić web scraping w Pythonie bez blokad, omówię najlepsze techniki i fragmenty kodu, a także podpowiem, kiedy warto rozważyć alternatywy oparte na AI, takie jak Thunderbit. Niezależnie od tego, czy jesteś Pythonowym prosem, czy tylko „skrobiesz” po powierzchni, wyjdziesz stąd z zestawem narzędzi do niezawodnego, wolnego od blokad pozyskiwania danych.
Czym jest web scraping w Pythonie bez blokad?
W swojej istocie web scraping bez blokad oznacza wyodrębnianie danych ze stron internetowych w sposób, który nie uruchamia ich mechanizmów antybotowych. W świecie Pythona chodzi o coś więcej niż samo napisanie pętli requests.get() — to umiejętność wtopienia się w tłum, naśladowania prawdziwych użytkowników i bycia o krok przed systemami wykrywania.
Dlaczego właśnie Python? Python jest najpopularniejszym językiem do web scrapingu — dzięki prostej składni, ogromnemu ekosystemowi (np. requests, BeautifulSoup, Scrapy, Selenium) i elastyczności, która sprawdza się zarówno w szybkim skrypcie, jak i w rozproszonym crawlerze. Ale popularność ma swoją cenę: wiele systemów antybotowych jest dziś dostrojonych do wykrywania wzorców scrapingu opartych na Pythonie.
Jeśli chcesz scrapować niezawodnie, musisz wyjść poza podstawy. Oznacza to zrozumienie, jak strony wykrywają boty i jak można je przechytrzyć — bez przekraczania granic etycznych ani prawnych.
Dlaczego unikanie blokad ma znaczenie w projektach web scrapingu w Pythonie
Blokada to nie tylko drobna przeszkoda techniczna — może rozsypać całe procesy biznesowe. Rozbijmy to na części:
| Przypadek użycia | Skutek blokady |
|---|---|
| Generowanie leadów | Niepełne lub nieaktualne listy potencjalnych klientów, utracona sprzedaż |
| Monitorowanie cen | Przegapione zmiany cen konkurencji, słabe decyzje cenowe |
| Agregacja treści | Luki w danych z wiadomości, recenzji lub badań |
| Analiza rynku | Martwe pola w śledzeniu konkurencji lub branży |
| Oferty nieruchomości | Niedokładne lub przestarzałe dane o nieruchomościach, utracone okazje |
Gdy scraper zostaje zablokowany, nie tylko tracisz dane — marnujesz zasoby, ryzykujesz problemy z compliance i możesz podejmować złe decyzje biznesowe na podstawie niepełnych informacji. W świecie, w którym 79% firm korzysta z web scrapingu do generowania leadów, niezawodność jest kluczowa.
Jak strony wykrywają i blokują web scrapery w Pythonie
Strony internetowe stały się naprawdę sprytne w wykrywaniu botów. Oto najczęstsze mechanizmy antyscrapingowe, z którymi możesz się spotkać (Medium, Bright Data):
- Biała lista / czarna lista adresów IP: Za dużo żądań z jednego IP? Blokada.
- Sprawdzanie User-Agent i nagłówków: Żądania bez nagłówków albo z generycznymi nagłówkami (np. domyślnym
python-requests/2.25.1) od razu rzucają się w oczy. - Rate limiting: Zbyt wiele żądań w krótkim czasie uruchamia ograniczanie ruchu lub ban.
- CAPTCHA: Zadania typu „udowodnij, że jesteś człowiekiem”, których boty nie potrafią łatwo rozwiązać.
- Analiza zachowania: Serwisy obserwują robotyczne wzorce — na przykład klikanie tego samego przycisku w równych odstępach.
- Honeypoty: Ukryte linki lub pola, z którymi interakcji podejmują tylko boty.
- Fingerprinting przeglądarki: Zbieranie szczegółów o przeglądarce i urządzeniu, by wykryć automatyzację.
- Śledzenie plików cookie i sesji: Boty, które nie obsługują poprawnie ciasteczek lub sesji, są oznaczane jako podejrzane.
Pomyśl o tym jak o kontroli bezpieczeństwa na lotnisku: jeśli wyglądasz, zachowujesz się i poruszasz jak wszyscy inni, przechodzisz gładko. Jeśli pojawisz się w trenczu i okularach przeciwsłonecznych, spodziewaj się dodatkowych pytań.
Niezbędne techniki Pythona do web scrapingu bez blokad
Przejdźmy do konkretów: jak faktycznie unikać blokad podczas scrapingu w Pythonie. Oto podstawowe strategie, które powinien znać każdy scraper:

Rotacja proxy i adresów IP
Dlaczego to ważne: Jeśli wszystkie żądania pochodzą z tego samego IP, jesteś łatwym celem dla blokad IP. Rotujące proxy pozwalają rozłożyć ruch na wiele adresów IP, przez co znacznie trudniej Cię zablokować.
Jak to zrobić w Pythonie:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...więcej proxy
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# przetwórz odpowiedź
Możesz korzystać z płatnych usług proxy (np. residential lub rotujących proxy), aby zwiększyć niezawodność (ScrapingBee).
Ustawianie User-Agent i własnych nagłówków
Dlaczego to ważne: Domyślne nagłówki Pythona krzyczą „bot”. Naśladuj prawdziwe przeglądarki, ustawiając user-agent i inne nagłówki.
Przykładowy kod:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
Rotuj user-agent dla większej dyskrecji (ZenRows).
Losowanie czasu i wzorców żądań
Dlaczego to ważne: Boty są szybkie i przewidywalne; ludzie są wolniejsi i bardziej losowi. Dodawaj opóźnienia i zmieniaj sposób poruszania się po stronie.
Wskazówka w Pythonie:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # poczekaj 2–7 sekund
Jeśli używasz Selenium, możesz też losować ścieżki kliknięć i wzorce przewijania.
Zarządzanie cookies i sesjami
Dlaczego to ważne: Wiele stron wymaga cookies lub tokenów sesji, aby uzyskać dostęp do treści. Boty, które to ignorują, są blokowane.
Jak to obsłużyć w Pythonie:
import requests
session = requests.Session()
response = session.get(url)
# sesja automatycznie obsłuży cookies
W bardziej złożonych przepływach użyj Selenium, aby przechwycić i ponownie wykorzystać cookies.
Symulowanie ludzkiego zachowania za pomocą headless browserów
Dlaczego to ważne: Niektóre strony wykorzystują JavaScript, ruch myszy lub przewijanie jako sygnały, że po drugiej stronie jest prawdziwy użytkownik. Headless browsery, takie jak Selenium czy Playwright, potrafią naśladować takie działania.
Przykład z Selenium:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
To pomaga ominąć analizę zachowania i dynamiczną treść (ScrapingBee).
Zaawansowane strategie: omijanie CAPTCHA i honeypotów w Pythonie
CAPTCHA została zaprojektowana po to, by zatrzymać boty w miejscu. Choć niektóre biblioteki Pythona potrafią rozwiązywać proste CAPTCHA, większość poważnych scraperów korzysta z zewnętrznych usług (np. 2Captcha lub Anti-Captcha), które rozwiązują je odpłatnie (Medium).
Przykładowa integracja:
# Pseudokod użycia API 2Captcha
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Poczekaj na rozwiązanie, a potem wyślij je razem z żądaniem
Honeypoty to ukryte pola lub linki, z którymi interakcję podejmą tylko boty. Unikaj klikania lub wysyłania czegokolwiek, co nie jest widoczne w prawdziwej przeglądarce (ZenRows).
Projektowanie solidnych nagłówków żądań z użyciem bibliotek Pythona
Poza user-agentem możesz rotować i losować także inne nagłówki, takie jak Referer, Accept, Origin itd., by jeszcze lepiej wtopić się w ruch.
Ze Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# więcej nagłówków
}
}
Z Selenium: użyj profili przeglądarki lub rozszerzeń do ustawiania nagłówków albo wstrzykuj je przez JavaScript.
Aktualizuj listę nagłówków — skopiuj rzeczywiste żądania przeglądarki z DevTools jako punkt odniesienia.
Kiedy tradycyjny scraping w Pythonie to za mało: rozwój technologii antybotowych
Taka jest rzeczywistość: im popularniejszy staje się scraping, tym szybciej rozwijają się mechanizmy antybotowe. Duże serwisy blokują dziś nie tylko oczywiste boty, ale nawet zaawansowane headless browsery i rotujące proxy. Wykrywanie oparte na AI, dynamiczne progi żądań i fingerprinting przeglądarki sprawiają, że nawet zaawansowanym skryptom w Pythonie coraz trudniej pozostać niewykrytymi (Medium).
Czasem, niezależnie od tego, jak sprytny jest Twój kod, trafiasz na ścianę. Wtedy warto rozważyć inne podejście.
Thunderbit: alternatywa AI Web Scraper dla scrapingu w Pythonie
Gdy Python dochodzi do swoich granic, z pomocą przychodzi Thunderbit — bezkodowy, oparty na AI web scraper stworzony z myślą o użytkownikach biznesowych, a nie tylko deweloperach. Zamiast walczyć z proxy, nagłówkami i CAPTCHA, agent AI Thunderbit czyta stronę, podpowiada najlepsze pola do wyodrębnienia i ogarnia wszystko — od nawigacji po podstronach po eksport danych.
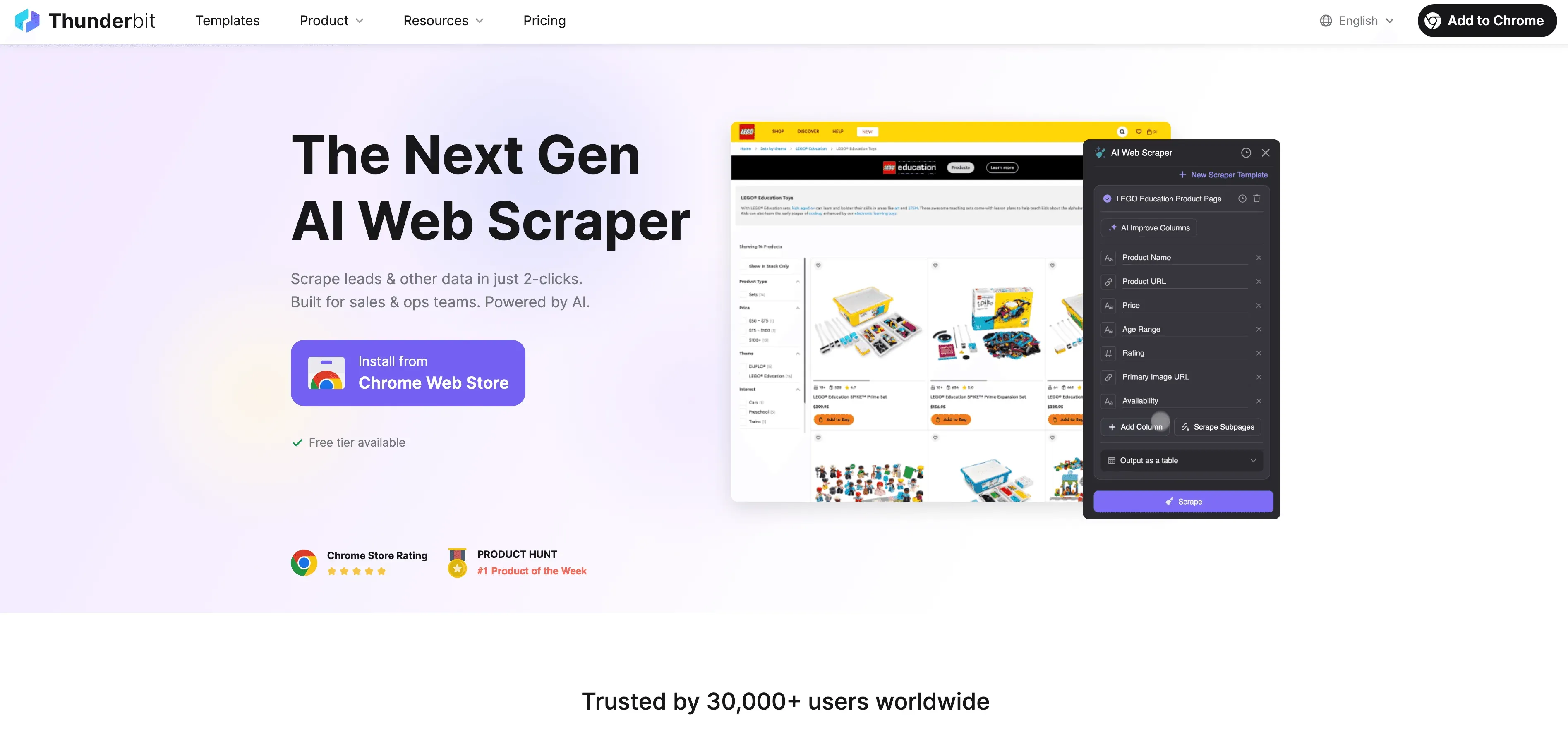
Co wyróżnia Thunderbit?
- Sugestie pól AI: Kliknij „AI Suggest Fields”, a Thunderbit przeskanuje stronę, zaproponuje kolumny, a nawet wygeneruje instrukcje ekstrakcji.
- Scraping podstron: Thunderbit może odwiedzać każdą podstronę (np. karty produktów lub profile LinkedIn) i automatycznie wzbogacać tabelę.
- Scraping w chmurze lub w przeglądarce: Wybierz najszybszą opcję — chmurę dla publicznych stron lub przeglądarkę dla stron chronionych logowaniem.
- Planowany scraping: Ustaw i zapomnij — Thunderbit może scrapować według harmonogramu, dzięki czemu Twoje dane są zawsze aktualne.
- Gotowe szablony: Dla popularnych serwisów (Amazon, Zillow, Shopify itd.) Thunderbit oferuje szablony 1‑kliknięciem — bez konfiguracji.
- Bezpłatny eksport danych: Eksportuj do Excela, Google Sheets, Airtable lub Notion — bez dodatkowych opłat.
Thunderbit zaufało ponad 100 000 użytkowników na całym świecie, a Ty nie musisz napisać ani jednej linijki kodu.
Wyodrębniaj dane z dowolnej strony za pomocą AI Get Started Free
Jak Thunderbit pomaga użytkownikom unikać blokad i automatyzować ekstrakcję danych
AI w Thunderbit nie tylko naśladuje ludzkie zachowanie — dostosowuje się do każdej strony w czasie rzeczywistym, zmniejszając ryzyko blokady. Oto jak:
- AI dostosowuje się do zmian układu: Mniej poprawek, gdy strona zmieni wygląd — nie musisz co tydzień ponownie stroić selektorów.
- Obsługa podstron i paginacji: Thunderbit sam przechodzi przez linki i listy stronicowane, tak jak zrobiłby to człowiek klikający kolejne strony.
- Scraping w chmurze partiami: Uruchamiaj zadania z chmury Thunderbit zamiast z laptopa, z rozmiarem partii ustawianym zgodnie z planem (aktualne limity znajdziesz na stronie cennika).
- Mniej kodu do utrzymania: Nie Ty gonisz zepsute selektory o północy, gdy strona się zmienia; AI po prostu ponownie odczytuje stronę.
Jeśli chcesz zgłębić temat, zajrzyj do artykułu Jak scrapować dowolną stronę internetową z użyciem AI.
Python vs Thunderbit: które rozwiązanie wybrać?
Zestawmy je obok siebie:
| Cecha | Scraping w Pythonie | Thunderbit |
|---|---|---|
| Czas wdrożenia | Średni–wysoki (skrypty, proxy itd.) | Niski (2 kliknięcia, resztą zajmuje się AI) |
| Umiejętności techniczne | Wymaga kodowania | Bez kodowania |
| Niezawodność | Zmienna (łatwo się psuje) | Wysoka (AI dostosowuje się do zmian) |
| Ryzyko blokad | Średnie–wysokie | Niskie (AI naśladuje użytkownika, dostosowuje się) |
| Skalowalność | Wymaga własnego kodu i konfiguracji chmury | Wbudowany scraping w chmurze i partiami |
| Utrzymanie | Częste (zmiany stron, blokady) | Minimalne (AI automatycznie się dostosowuje) |
| Opcje eksportu | Ręczne (CSV, baza danych) | Bezpośrednio do Sheets, Notion, Airtable, CSV |
| Koszt | Darmowy (ale czasochłonny) | Darmowy plan, płatne plany do większej skali |
Kiedy używać Pythona:
- Potrzebujesz pełnej kontroli, własnej logiki lub integracji z innymi procesami w Pythonie.
- Scrape’ujesz strony z minimalną ochroną antybotową.
Kiedy używać Thunderbit:
- Chcesz szybkości, niezawodności i zerowej konfiguracji.
- Scrape’ujesz złożone lub często zmieniające się strony.
- Nie chcesz zajmować się proxy, CAPTCHA ani kodem.
Wypróbuj za darmo Thunderbit AI Web Scraper
Przewodnik krok po kroku: konfiguracja web scrapingu w Pythonie bez blokad
Przejdźmy przez praktyczny przykład: scrapowanie danych produktowych z przykładowej strony z zastosowaniem najlepszych praktyk antyblokadowych.
1. Zainstaluj wymagane biblioteki
pip install requests beautifulsoup4 fake-useragent
2. Przygotuj skrypt
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Podmień na własne adresy URL
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Tutaj wyodrębnij dane
print(soup.title.text)
else:
print(f"Blokada lub błąd dla {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Losowe opóźnienie
3. Dodaj rotację proxy (opcjonalnie)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# Więcej proxy
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...reszta kodu
4. Obsłuż cookies i sesje
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...reszta kodu
5. Wskazówki diagnostyczne
- Jeśli widzisz dużo błędów 403/429, zwolnij tempo żądań albo spróbuj nowych proxy.
- Jeśli trafisz na CAPTCHA, rozważ użycie Selenium lub usługi rozwiązującej CAPTCHA.
- Zawsze sprawdzaj
robots.txtoraz regulamin strony.
Podsumowanie i najważniejsze wnioski
Web scraping w Pythonie jest potężny — ale wraz z rozwojem technologii antybotowych ryzyko blokady stale rośnie. Najlepszy sposób na unikanie blokad? Połączyć dobre praktyki techniczne (rotujące proxy, sprytne nagłówki, losowe opóźnienia, obsługę sesji i headless browsery) ze zdrowym szacunkiem dla zasad i etyki strony.
Ale czasem nawet najlepsze sztuczki w Pythonie to za mało. Właśnie wtedy przydają się narzędzia AI, takie jak Thunderbit — bez kodu, zaprojektowane do radzenia sobie ze zmianami układu i paginacją, które wykładają sztywne skrypty, i skierowane do użytkowników biznesowych, którzy woleliby nie spędzać wieczorów na pilnowaniu zadania Selenium.
Chcesz zobaczyć, jak łatwy może być scraping? Pobierz rozszerzenie Thunderbit do Chrome i wypróbuj je sam — albo zajrzyj na naszego bloga, aby znaleźć więcej porad i tutoriali o scrapingu.
Najczęstsze pytania
1. Dlaczego strony internetowe blokują Pythonowe scrapery?
Strony blokują scrapery, aby chronić swoje dane, zapobiegać przeciążeniu serwerów i powstrzymywać zautomatyzowane boty przed nadużywaniem usług. Skrypty w Pythonie łatwo wykryć, jeśli używają domyślnych nagłówków, nie obsługują cookies albo wysyłają zbyt wiele żądań w zbyt krótkim czasie.
2. Jakie są najskuteczniejsze sposoby na uniknięcie blokady podczas scrapingu w Pythonie?
Korzystaj z rotujących proxy, ustaw realistyczny user-agent i nagłówki, losuj czas żądań, zarządzaj cookies/sesjami oraz symuluj ludzkie zachowanie za pomocą narzędzi takich jak Selenium lub Playwright.
3. Jak Thunderbit pomaga unikać blokad w porównaniu ze skryptami w Pythonie?
Thunderbit używa AI, by dostosowywać się do układu strony, naśladować ludzkie przeglądanie i automatycznie obsługiwać podstrony oraz paginację. Zmniejsza ryzyko blokad, wtapiając się w ruch i aktualizując swoje podejście w czasie rzeczywistym — bez kodu i bez proxy.
4. Kiedy powinienem używać scrapingu w Pythonie, a kiedy narzędzia AI, takiego jak Thunderbit?
Używaj Pythona, gdy potrzebujesz własnej logiki, integracji z innym kodem w Pythonie lub scrapujesz proste strony. Thunderbit wybierz wtedy, gdy potrzebujesz szybkiego, niezawodnego i skalowalnego scrapingu — zwłaszcza gdy strony są złożone, często się zmieniają albo agresywnie blokują skrypty.
5. Czy web scraping jest legalny?
Web scraping jest legalny w przypadku publicznie dostępnych danych, ale musisz respektować warunki korzystania ze strony, polityki prywatności i odpowiednie przepisy prawa. Nigdy nie scrapuj danych wrażliwych ani prywatnych i zawsze działaj etycznie oraz odpowiedzialnie.
Gotowy, by scrapować mądrzej, a nie ciężej? Wypróbuj Thunderbit i zostaw blokady za sobą.
Dowiedz się więcej:
- Scraping Google News w Pythonie: przewodnik krok po kroku
- Zbuduj narzędzie do śledzenia cen Best Buy w Pythonie
- 14 sposobów na web scraping bez blokad
- 10 najlepszych wskazówek, jak nie dać się zablokować podczas web scrapingu
Wypróbuj AI Web Scraper Get Started Free




